jetson nano opencv 打开 CSI摄像头_使用 python3+OpenCV+TensorFlow 做手势识別
本人大三小白,第一次写文章,如有不足,请各位大佬指出并见谅。写这篇文章一方面是为了记录过程,另一方面是为了分享大家一些干货,大家也可以在评论里相互交流遇到的问题。力行而后知之真!
环境配置:
本文是在Windows10+python3.6的环境下实现的,使用的编译器是pycharm-professional-2018.3.3。(Python官方主页 Welcome to Python.org)
tensorflow安装与模块导入:
使用win+R打开 运行 窗口,然后输出cmd,回车

在cmd输出
python -m pip install tensorflow
安装tensorflow模块的时候,可能会很慢。如果网络不稳定,安装回中断,这个时候不用担心,可以通过上下键重新找到那个命令,回车安装就好;或者用
python -m pip install --upgrade tensorflow等待tensorflow安装完毕就好。
安装Git
git 官方主页: Git for Windows
点击download即可下载,安装完成以后,右键→Git Bash Here→
git clone https://github.com/tensorflow/models.git D:/tensorflow/models(注意:D:/tensorflow/models 为下载到的路径,该路径可以更改,但路径不可出现中文或空格)


下载完成后,可以得到如下内容,此时object detection API 下载完成。
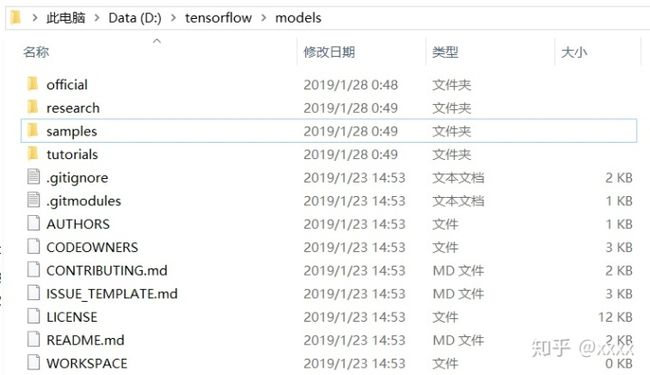
下载protoc
protoc我放在云盘里了,可以通过以下链接直接下载。链接:https://pan.baidu.com/s/19xzP6_x5Ru5y_qra3wtakA 提取码:nf6n
下载完成后,把protoc 解压放到D:TOOLS目录下。
使用protoc生成python文件
然后win+R→cmd→
C:Usersyuhang>cd
C:>cd /d D:tensorflowmodelsresearch
D:tensorflowmodelsresearch>D:/TOOLS/protoc-3.4.0-win32/bin/protoc object_detection/protos/*.proto --python_out=.
运行结果只要没有报错就算成功运行,具体的可以在以下目录看到刚刚得到的python文件,日期也是刚刚运行的时间。

有了以上文件,接下来测试API是否可以运行。
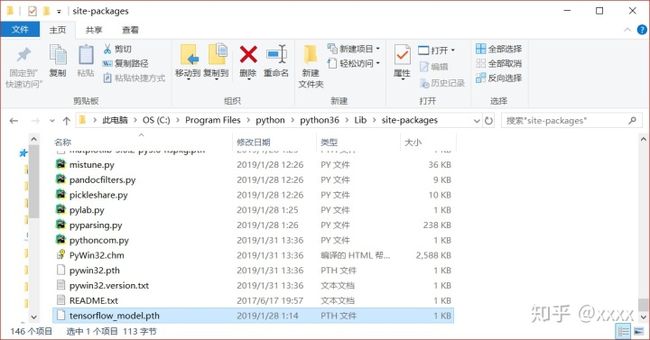
找到python的安装路径,我的路径在C:Program Filespythonpython36Libsite-packages,在该文件夹下新建一个txt文件,打开该txt文件,输入以下三条路径
D:tensorflowmodelsresearch
D:tensorflowmodelsresearchslim
D:tensorflowmodelsresearchobject_detection将该文件命名为tensorflow_model.pth储存即可。
回到cmd,输入
python object_detection/builders/model_builder_test.py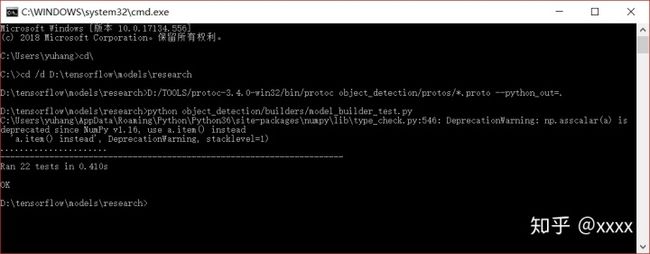
得到ok,测试成功!此时tensorflow object detection API 框架搭建完成。
手势数据的收集与标注
数据收集
提前工作
在D盘创建一个文件夹,命名为hand_data;在hand_data里创建一个文件夹,命名为VOC2012(注意:该名称必须为VOC2012);在VOC2012文件夹下创建3个文件夹,分别命名为Annotations,ImageSets,JPEGImages(注意:该名称必须为Annotations,ImageSets,JPEGImages);在ImageSets文件夹内创建Main文件夹。
模块安装
首先把需要使用的模块安装好
python -m pip install opencv-python
python -m pip install Cython
python -m pip install contextlib2
python -m pip install pillow
python -m pip install lxml
python -m pip install jupyter
python -m pip install matplotlib使用摄像头+opencv收集数据
以下代码设定的为每5帧保存一次,可以修改,保存地址为VOC2012文件夹下的JPEGImages文件夹内,每种手势收集1000张图片最佳。
import cv2 as cv
import numpy as np
capture = cv.VideoCapture(0)
index = 1
while True:
ret, frame = capture.read()
if ret is True:
cv.imshow("frame", frame)
index += 1
if index % 5 == 0:
cv.imwrite("D:/tensorflow/hand_data/VOC2012/JPEGImages/" + str(index) + ".jpg", frame)
c = cv.waitKey(50)
if c == 27: # ESC
break
else:
break
cv.destroyAllWindows()首先删除不清晰的图片,因为收集到的图片的序号不是按照顺序排的,因此需要排好序再标注。在JPEGImages文件夹内新建一个txt文件,把以下代码copy进去,命名为.bat文件,保存好,再运行一下,图片名就会按照顺序排列好了。
@echo off
set a=0
setlocal EnableDelayedExpansion
dir /b .*.jpg | find /c /v "" >> .tmp.txt
set /p c=<.tmp.txt
del /a /f /q .tmp.txt
for %%i in (*.jpg) do (
set /a a+=1
if !a! gtr %c% (goto aa)
echo !a!
echo %%i
ren "%%i" "!a!.jpg"
)
:aa
pause数据标注
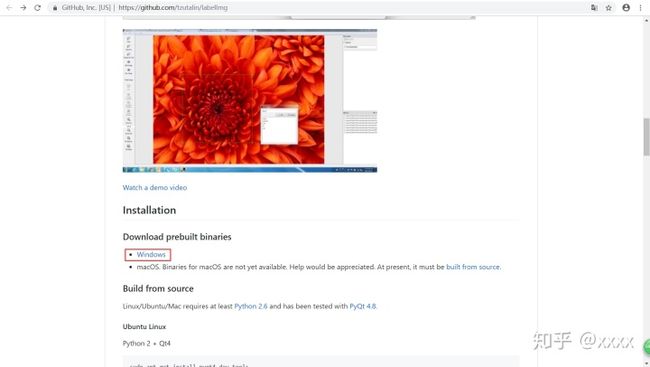
labelImg下载
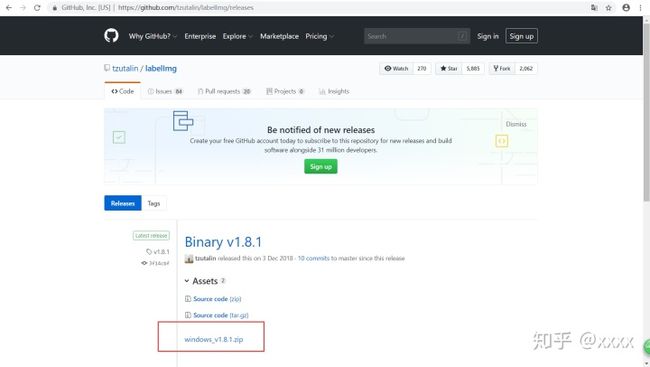
本文使用labelImg实现数据标注,下载地址为tzutalin/labelImg,依次点击红色方框即可。
因为这个东西在外网,为了方便下载,给出百度云盘链接:https://pan.baidu.com/s/1Ros4T5c-m401urzt_NdVNw 提取码:xdiz
添加标签
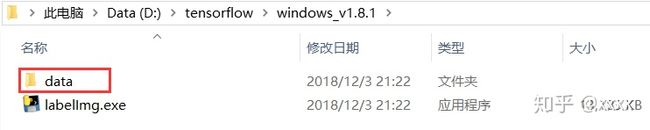
下载解压完成后打开

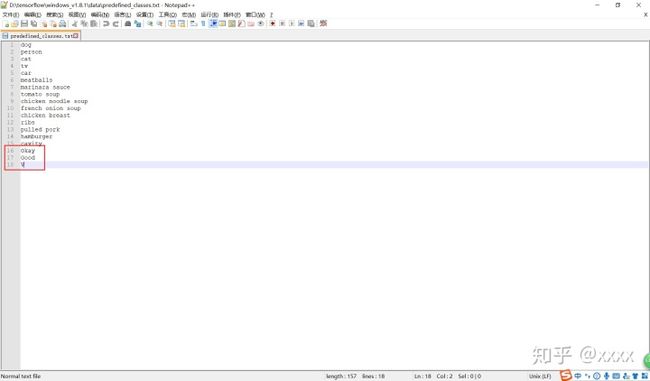
本文对三个手势进行标注,在该txt文件中添加了三个标签。
把储存照片的JPEGImages文件夹路径设置好:


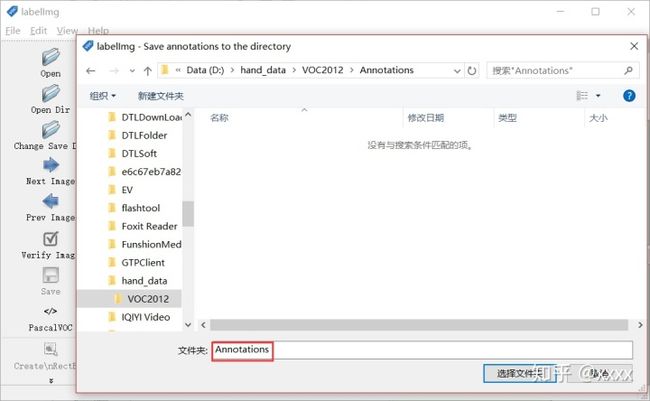
再把需要保存的.xml的Annotations文件夹路径设置好:
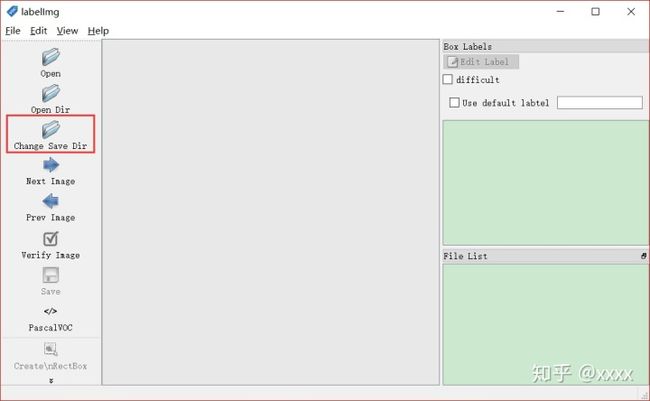
路径都设置好以后,再按下W即可对图片标注。

标注好位置后,点击save进行保存。(快捷方式为两次空格键)(也可以按一次空格键,全部标注完以后,检查时再按一次空格键方便检查,会有绿色和白色的背景色提醒,白色为最终确认的颜色)

然后点击Next Image 对下一张图片进行数据标注。(快捷方式为D)
想返回上一张查看的话,可以点击Prev Image。(快捷方式为A)
重复上述工作至全部标注完成即可。数据标注工作枯燥无味,如果一次未能全部标注完,关闭后下一次可以继续标注。
.xml文件的修改
之前标注好的数据会保存在.xml文件中,但是格式并不完全正确。下面红色方框内的内容必须要改成如下形式即可。

上千个.xml文件,手动改是不可能手动改的。用下面的python代码可以遍历全部文件进行更改,并且在Main文件夹内保存对应的txt文件。
import cv2 as cv
import os
from xml.dom import minidom
import xml.etree.ElementTree as ET
root_dir = "D:/hand_data/VOC2012/JPEGImages/"
def xml_modification():
ann_dir = "D:/hand_data/VOC2012/Annotations/"
files = os.listdir(ann_dir)
for xml_file in files:
if os.path.isfile(os.path.join(ann_dir, xml_file)):
xml_path = os.path.join(ann_dir, xml_file)
tree = ET.parse(xml_path)
root = tree.getroot()
# changing a field text
for elem in root.iter('folder'):
elem.text = 'voc2012'
for elem in root.iter('name'):
name = elem.text
elem.text = name.replace(" ", "")
tree.write(xml_path)
print("processed xml : %s" % (xml_path))
def generate_classes_text():
print("start to generate classes text...")
ann_dir = "D:/hand_data/VOC2012/Annotations/"
okay_train = open("D:/hand_data/VOC2012/ImageSets/Main/Okay_train.txt", 'w')
okay_val = open("D:/hand_data/VOC2012/ImageSets/Main/Okay_val.txt", 'w')
good_train = open("D:/hand_data/VOC2012/ImageSets/Main/Good_train.txt", 'w')
good_val = open("D:/hand_data/VOC2012/ImageSets/Main/Good_val.txt", 'w')
v_train = open("D:/hand_data/VOC2012/ImageSets/Main/V_train.txt", 'w')
v_val = open("D:/hand_data/VOC2012/ImageSets/Main/V_val.txt", 'w')
files = os.listdir(ann_dir)
for xml_file in files:
if os.path.isfile(os.path.join(ann_dir, xml_file)):
xml_path = os.path.join(ann_dir, xml_file)
tree = ET.parse(xml_path)
root = tree.getroot()
for elem in root.iter('filename'):
filename = elem.text
for elem in root.iter('name'):
name = elem.text
if name == "Okay":
okay_train.write(filename.replace(".jpg", " ") + str(1) + "n")
okay_val.write(filename.replace(".jpg", " ") + str(1) + "n")
good_train.write(filename.replace(".jpg", " ") + str(-1) + "n")
good_val.write(filename.replace(".jpg", " ") + str(-1) + "n")
v_train.write(filename.replace(".jpg", " ") + str(-1) + "n")
v_val.write(filename.replace(".jpg", " ") + str(-1) + "n")
if name == "V":
okay_train.write(filename.replace(".jpg", " ") + str(-1) + "n")
okay_val.write(filename.replace(".jpg", " ") + str(-1) + "n")
good_train.write(filename.replace(".jpg", " ") + str(-1) + "n")
good_val.write(filename.replace(".jpg", " ") + str(-1) + "n")
v_train.write(filename.replace(".jpg", " ") + str(1) + "n")
v_val.write(filename.replace(".jpg", " ") + str(1) + "n")
if name == "Good":
okay_train.write(filename.replace(".jpg", " ") + str(-1) + "n")
okay_val.write(filename.replace(".jpg", " ") + str(-1) + "n")
good_train.write(filename.replace(".jpg", " ") + str(1) + "n")
good_val.write(filename.replace(".jpg", " ") + str(1) + "n")
v_train.write(filename.replace(".jpg", " ") + str(-1) + "n")
v_val.write(filename.replace(".jpg", " ") + str(-1) + "n")
okay_train.close()
okay_val.close()
v_train.close()
v_val.close()
good_train.close()
good_val.close()
xml_modification()
#generate_classes_text()成功运行上面python代码后,得到以下txt文件。
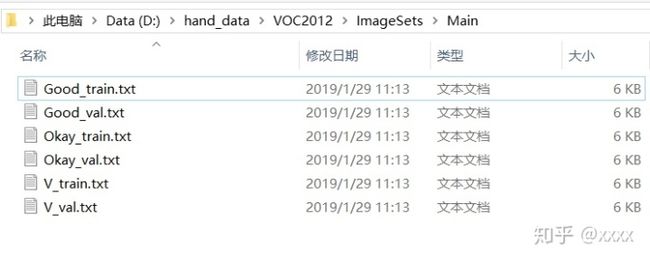
对得到的txt文件进行说明:第一列为图片的名称,第二列为图片的结果,-1代表不是,1代表是。

至此,VOC2012数据集制作完成。
tf.record数据的生成
在tensorflow文件夹下新建一个文件夹,命名为hand_set,在hand_set文件夹下新建三个文件夹,分别命名为data,export,model。

在model文件夹下新建eval和train文件夹。
在hand_data文件夹里新建一个txt文件,命名为hand_label_map.pbtxt,

在D:tensorflowmodelsresearchobject_detectiondata中找打一个叫pet_label_map.pbtxt的文件打开,
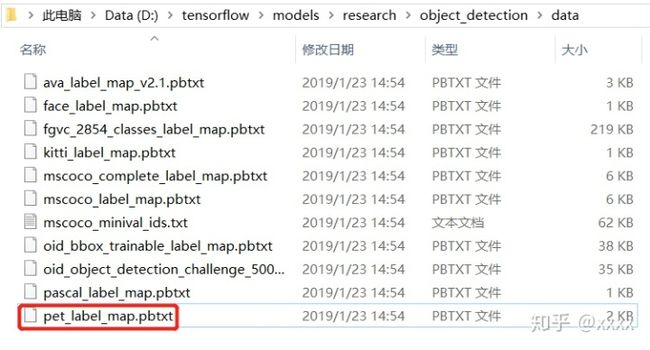
复制全部内容后,粘贴到hand_label_map.pbtxt中,并把name: ' ' 内的内容修改为需要修改的内容,
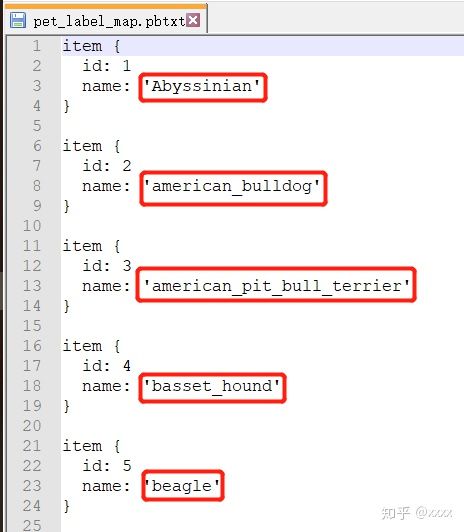

保存好,.pbtxt文件制作完成。
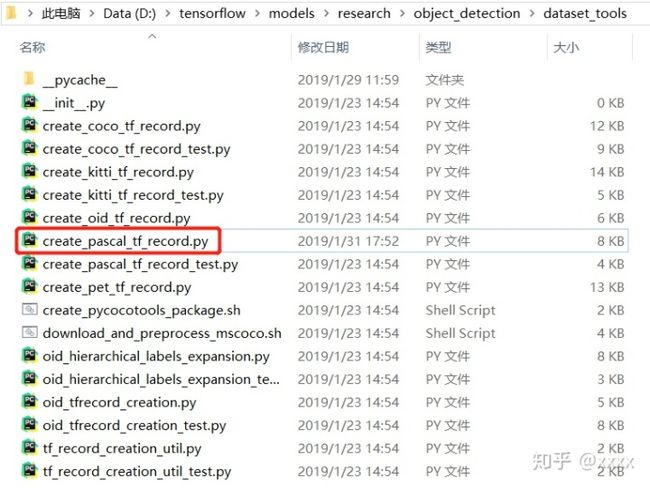
在D:tensorflowmodelsresearchobject_detectiondataset_tools中找到create_pascal_tf_record.py文件并打开,在165行更改成如下形式,和D:hand_dataVOC2012ImageSetsMain中的一个txt文件保持一致即可。

接下来,win+R→cmd→
C:Usersyuhang>cd /d D:tensorflowmodelsresearch
D:tensorflowmodelsresearch>python object_detection/dataset_tools/create_pascal_tf_record.py --label_map_path=D:/hand_data/hand_label_map.pbtxt --data_dir=D:hand_data --year=VOC2012 --set=train --output_path=D:tensorflowhandsetdatapascal_train.record
运行生成record文件,并把之前做好的hand_label_map.pbtxt文件一并放到该文件夹下。

预训练模型的选择
打开tensorflow/models,找到model zoo,在这里面有各种各样的模型。
我们选择下面这个模型,从Speed中可以看到模型的速度。有兴趣的也可以尝试其他的模型。点击下载到D:tensorflow。

config文件的配置
在D:tensorflowmodelsresearchobject_detectionsamplesconfigs中找到ssd_mobilenet_v1_pets.config文件。复制粘贴到D:tensorflowhandsetmodel中。


打开ssd_mobilenet_v1_pets.config,把第9行的数字修改为需要分类的类别数
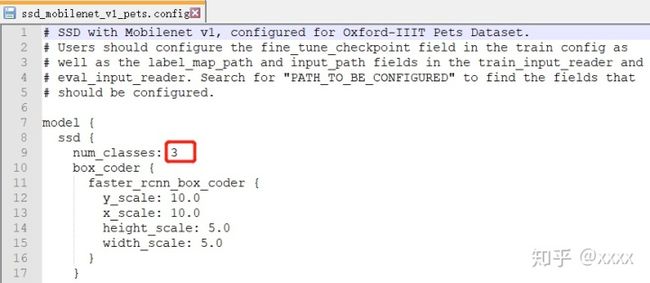
路径修改(注意反斜杠和斜杆的问题):
fine_tune_checkpoint 后的路径改为 ssd_mobilenet_v1_pets.config 的路径;
train_input_reader下的 input_path 后的路径改为 pascal_train.record 的路径,label_map_path后的路径改为 hand_label_map.pbtxt 的路径;
eval_input_reader下的路径同上。

模型训练
首先在cmd中执行下面的命令
pip install git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI然后在cmd中执行
C:Usersyuhang>cd /d D:tensorflowmodelsresearch
D:tensorflowmodelsresearch>python object_detection/model_main.py --pipeline_config_path=D:/tensorflow/handset/model/ssd_mobilenet_v1_pets.config --model_dir=D:tensorflowhandsetmodeltrain --num_train_steps=200 --num_eval_steps=5 --alsologtostderr即可开始训练,因为tensorflow是CPU版本的,所以训练时间比较长。
训练过程查看
C:Usersyuhang>cd
C:>tensorboard --logdir=D:tensorflowhandsetmodeltrain --host=127.0.0.1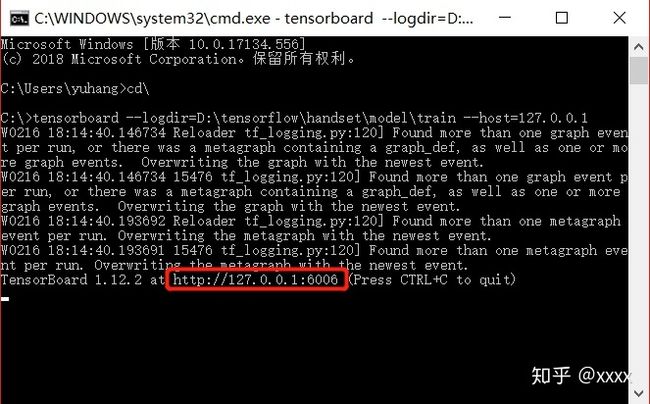
得到http://127.0.0.1:6006,在浏览器中打开,即可看到过程参数,识别图像等,都可以自己尝试点击看看。

模型导出
在cmd中输入
C:Usersyuhang>cd /d D:tensorflowmodelsresearch
D:tensorflowmodelsresearch>python object_detection/export_inference_graph.py --input_type=image_tensor --pipeline_config_path=D:tensorflowhandsetmodelssd_mobilenet_v1_pets.config --trained_checkpoint_prefix=D:tensorflowhandsetmodeltrainmodel.ckpt-200 --output_directory=D:tensorflowhandsetexport即可导出数据,在D:tensorflowhandsetexport中可以看到导出的模型。

实时手势识别
import os
import sys
import tarfile
import cv2 as cv
import numpy as np
import tensorflow as tf
from utils import label_map_util
from utils import visualization_utils as vis_util
# Path to frozen detection graph. This is the actual model that is used for the object detection.
PATH_TO_FROZEN_GRAPH = 'D:/tensorflow/handset/export/frozen_inference_graph.pb'
# List of the strings that is used to add correct label for each box.
PATH_TO_LABELS = os.path.join('D:/tensorflow/handset/data', 'hand_label_map.pbtxt')
NUM_CLASSES = 3
detection_graph = tf.Graph()
capture = cv.VideoCapture(0)
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_FROZEN_GRAPH, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categorys = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True)
category_index = label_map_util.create_category_index(categorys)
with detection_graph.as_default():
with tf.Session(graph=detection_graph) as sess:
while True:
ret, image = capture.read()
if ret is True:
image_np_expanded = np.expand_dims(image, axis=0)
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
scores = detection_graph.get_tensor_by_name('detection_scores:0')
classes = detection_graph.get_tensor_by_name('detection_classes:0')
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
(boxes,scores,classes,num_detections)=sess.run([boxes, scores, classes, num_detections],
feed_dict={image_tensor: image_np_expanded})
vis_util.visualize_boxes_and_labels_on_image_array(
image,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
min_score_thresh=0.5, #置信度,默认为0.5
use_normalized_coordinates=True,
line_thickness=4
)
c = cv.waitKey(5)
if c == 27: # ESC
break
cv.imshow("Hand Gesture Demo", image)
else:
break
cv.waitKey(0)
cv.destoryAllWindows()
注意要把路径写对。
大功告成!
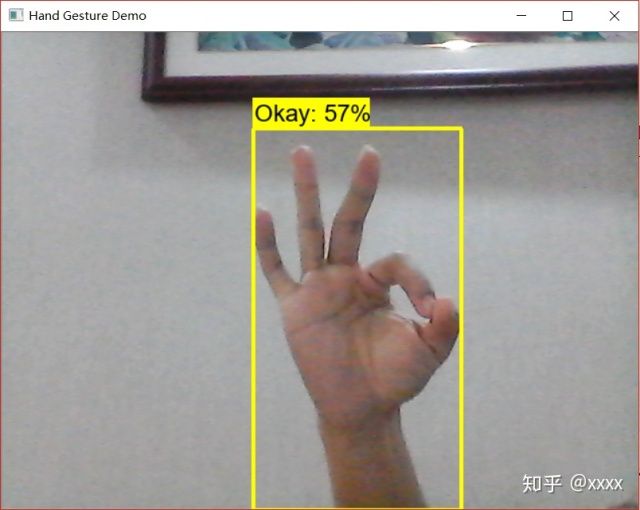


更新:做了提升

