CS224n自然语言处理(二)——语言模型、机器翻译和CNN
文章目录
- 一、语言模型及RNN
-
- 1.n-gram语言模型
- 2.Window-based DNN
- 3.循环神经网络
-
- (一)梯度消失和梯度爆炸
- (二)LSTM
- (三)GRU
- 4.评估语言模型
- 5.预处理
- 二、机器翻译和Seq2Seq
-
- 1.统计机器翻译
- 2.神经机器翻译和Seq2Seq
- 3.评估方法——BLEU
- 4.注意力机制
- 三、自然语言处理中的CNN
-
- 1.用于文本分类的单层CNN
- 2.用于文本分类的深度卷积网络
- 3.Q-RNN
- 4.模型的对比
一、语言模型及RNN
语言模型(Language Modelling)研究的是根据已知序列推测下一个单词的问题,根据条件概率的链式法则,我们也可以将其看做一系列词出现的概率问题 。

1.n-gram语言模型
较为经典的语言模型是n-gram模型。n-gram的定义就是连续的n个单词。该模型的核心思想是收集关于不同n-gram出现频率的统计数据,并使用这些数据预测下一个单词,并且假设需要预测的单词出现的概率仅仅依赖于它之前的n-1个单词,即

其中count是通过处理大量文本对相应的n-gram出现次数计数得到的。
n-gram模型主要有两大问题:
- 稀疏问题 Sparsity Problem。在我们之前的大量文本中,可能分子的组合没有出现过,即计数为零,解决办法是为每个可能添加极小数使词表中的每个单词至少有很小的概率;另一种可能是分母的组合没有出现过,此时可以减小n进行计算。随着n的增大,稀疏性更严重。
- 我们必须存储所有的n-gram对应的计数,随着n的增大,模型存储量也会增大。
这些限制了n的大小,但如果n过小,则我们无法体现稍微远一些的词语对当前词语的影响,这会极大的限制处理语言问题中很多需要依赖相对长程的上文来推测当前单词的任务的能力。
2.Window-based DNN
之前应用与命名实体识别问题时建立的神经网络模型也可以对语言模型进行建模,即将定长窗口中的word embedding连在一起,将其经过神经网络做对下一个单词的分类预测,其类的个数为语裤中的词汇量,如下图所示
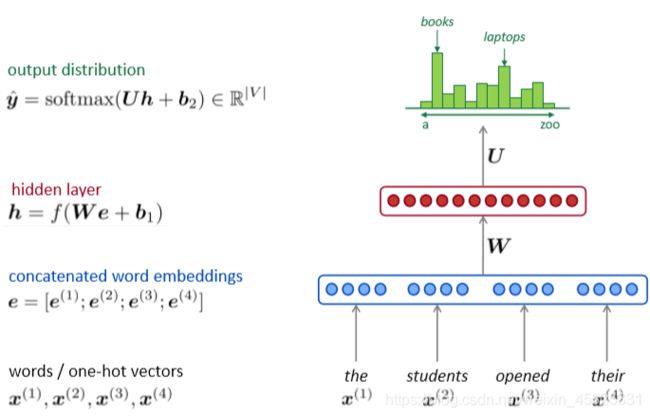
与n-gram模型相比较,它解决了稀疏问题与存储问题,但它仍然存在一些问题:窗口大小固定,扩大窗口会使矩阵W变大;没有任何可共享的参数。
3.循环神经网络
RNN(Recurrent Neural Network)结构通过不断的应用同一个矩阵W可实现参数的有效共享,并且没有固定窗口的限制。其基本结构如下图所示:

训练RNN的步骤:
-
获取一个较大的文本语料库,该语料库是一个单词序列,初始化每个单词,可以使随机初始化,也可以应用词向量方法进行初始化
-
RNN的前向传播,得到每个步骤的输出
-
得到步骤t的损失函数,即预测结果和真实结果的交叉熵
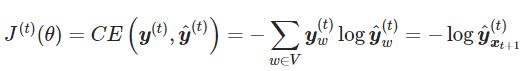
-
对于文本量为T的总的损失即为所有交叉熵损失的平均值
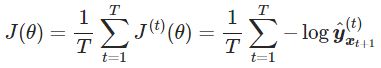
-
计算梯度和更新权重。
-
不断重复上述操作
RNN的优点
- 可以处理任意长度 的输入
- 每个步骤可以包含许多前面步骤的信息
- 模型大小不会随着输入的增加而增加
- 在每个时间步上应用相同的权重,因此在处理输入时具有对称性
RNN的缺点
- 递归计算速度 慢
- 在实践中,很难从许多步骤前返回信息
(一)梯度消失和梯度爆炸
梯度消失:对于两个时间步 t 和 k,假设梯度小于1,,当t-k很大即其相距很远的时候,其梯度会呈指数级衰减,这一问题被称作梯度消失。它导致我们无法分辨t时刻与k时刻究竟是数据本身毫无关联还是由于梯度消失而导致我们无法捕捉到这一关联。这就导致了我们只能学习到近程的关系而不能学习到远程的关系,会影响很多语言处理问题的准确度。
梯度爆炸:与梯度消失类似,对于两个时间步 t 和 k,假设梯度大于1,则随着时间越远该梯度指数级增大,这一问题被称作梯度爆炸,这就会造成当我们步进更新时,步进过大而越过了极值点。一个简单的解决方案是gradient clipping,即如果梯度大于某一阈值,则在SGD新一步更新时按比例缩小梯度值,即我们仍然向梯度下降的方向行进但是其步长缩小。
梯度爆炸问题我们可以通过简单的gradient clipping来解决,那对于梯度消失问题呢?其基本思路是我们设置一些存储单元来更有效的进行长程信息的存储,LSTM与GRU都是基于此基本思想设计的。
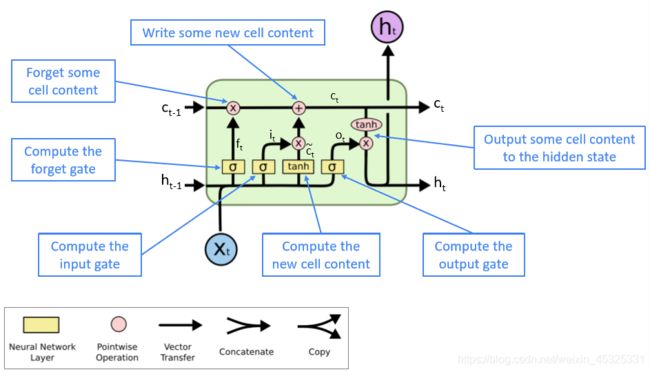
(二)LSTM
长短期记忆网络(Long Short Term Memory)。其基本思路是除了hidden state之外,引入cell state 来存储长程信息,LSTM可以通过控制gate来擦除,存储或写入cell state。
LSTM的公式如下:
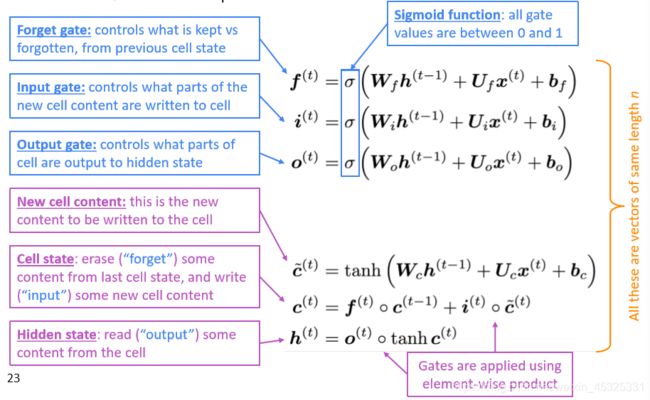
- 遗忘门:控制上一个单元状态的保存与遗忘
- 输入门:控制写入单元格的新单元内容的哪些部分
- 输出门:控制单元的哪些内容输出到隐藏状态
- 新单元内容:这是要写入单元的新内容
- 单元状态:删除(“忘记”)上次单元状态中的一些内容,并写入(“输入”)一些新的单元内容
- 隐藏状态:从单元中读取(“output”)一些内容
- Sigmoid函数:所有的门的值都在0到1之间
- 通过逐元素的乘积来应用门
- 这些是长度相同的向量
一个LSTM单元如下图所示:
(三)GRU
GRU(gated recurrent unit)可以看做是将LSTM中的forget gate和input gate合并成了一个update gate,同时将cell state也合并到hidden state中。
GRU的公式如下:
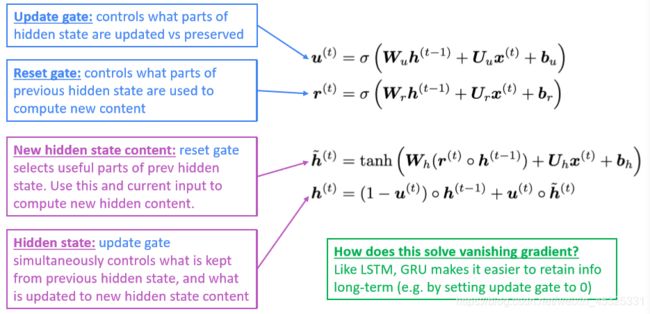
- 更新门:控制隐藏状态的哪些部分被更新,哪些部分被保留
- 重置门:控制之前隐藏状态的哪些部分被用于计算新内容
- 新的隐藏状态内容:重置门选择之前隐藏状态的有用部分。使用这一部分和当前输入来计算新的隐藏状态内容
- 隐藏状态:更新门同时控制从以前的隐藏状态保留的内容,以及更新到新的隐藏状态内容的内容
LSTM与RNN是最广泛应用的,两者最大的区别就是GRU有更少的参数,更便于计算,对于模型效果方面,两者类似。通常我们可以从LSTM开始,如果需要提升效率的话再准换成GRU。一些RNN的很多其他变种包括双向RNN、多层RNN等。
4.评估语言模型
语言模型的评估指标是perplexity,即我们文本库的概率的倒数

也可以表示为损失函数的指数形式

所以perplexity越小表示我们的语言模型越好
5.预处理
对于NLP的应用,我们通常将停用词、出现频率很低的词、标点符号过滤掉
词的标准化,将不同时态,不同词性同一意思的单词合并成一个单词。有两种方法,Stem(基于规则将单词转换为某种形式,结果不一定是有效单词)和Lemmazation(可以确保生成结果为有效单词)
二、机器翻译和Seq2Seq
机器翻译就是将源语言中的文字转换成对应的目标语言中的文字的任务。早期的机器翻译很多是人为基于规则的,随后逐渐发展出依赖于统计信息的Statistical Machine Translation(简称SMT),之后又发展出利用神经网络使得准确度大幅改善的Neural Machine Translation(NMT),它依赖于Sequence-to-Sequence的模型架构,以及进一步将其改善的Attention机制。
1.统计机器翻译
SMT的核心思想是从数据中学习出概率模型。假设我们想要从法语翻译成英语,我们希望给定输入的法语句子x ,找到对应最好的英语句子 y ,即 argmaxP(y|x),根据贝叶斯规则可以将其分解为两个组件从而分别学习,即 argmaxP(x|y)P(y)。
P(y)是语言模型,即如何挑选这些单词或词组组成合理的目标语言中的句子。语言模型从单词数据中进行学习,具体方法参见上文。
P(x|y)为翻译模型,用来分析单词和短语应该如何翻译,学习翻译模型需要大量的并行数据,例如成对的人工翻译的法语/英语句子。更进一步的,学习P(x|y)相当于学习P(x, a|y),a是对齐,即法语句子 x 和英语句子 y 之间的单词级对应。对齐有几种情况:
- 有些词没有对应词
- 对齐可以是多个词对应一个词
- 对齐可以是一个词对应多个词
- 对齐可以是多个词对应对个词
SMT的解码过程,即计算argmax的过程。我们可以列举所有的可能并计算概率(开销过大),也可以使用启发式搜索算法搜索最佳翻译,丢弃概率过低的假设来进行计算。
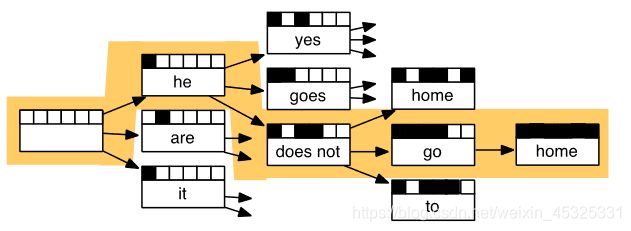
SMT是一个巨大的研究领域,系统非常复杂,系统有许多分别设计子组件工程,需要编译和维护额外的资源,需要大量的人力来维护。
2.神经机器翻译和Seq2Seq
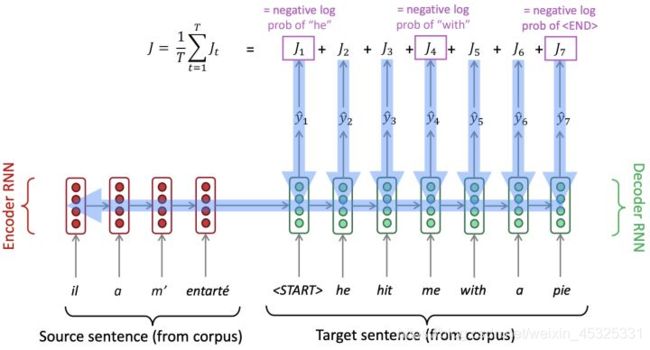
神经机器翻译是利用单个神经网络进行机器翻译的一种方法,神经网络架构称为sequence-to-sequence (又名seq2seq),它包含两个RNNs,一个RNN作为encoder将输入的源语言转化为固定大小的上下文向量,再通过另一个RNN作为decoder将编码器生成的上下文向量转化为目标语言中的句子。我们可以将decoder看做预测目标句子 y 的下一个单词的语言模型,同时其概率依赖于源句子的encoding,一个将法语翻译成英语的Seq2Seq模型如下图所示。
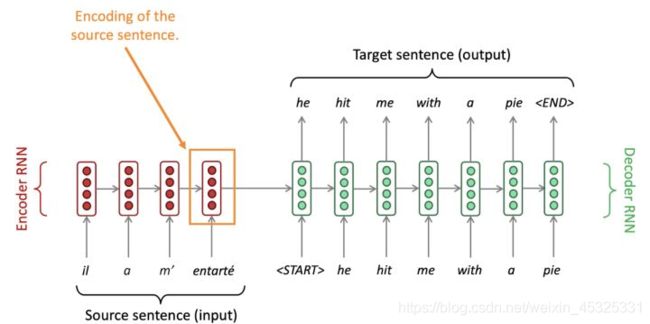
NMT直接计算 P(y|x),展开后最后一项为,给定到目前为止的目标词和源句 x ,下一个目标词的概率,即
![]()
NMT的训练过程和语言模型类似,其损失函数为各步中目标单词的log probability的相反数的平均值。损失函数的梯度可以一直反向传播到encoder,模型可以整体优化,所以Seq2Seq也被看做是end2end模型
对于神经机器翻译的解码过程,我们可以选择greedy decoding即每一步均选取概率最大的单词并将其作为下一步的decoder input。但是greedy decoding的问题是可能当前的最大概率的单词对于翻译整个句子来讲不一定是最优的选择,但由于每次我们都做greedy的选择我们没机会选择另一条整体最优的路径。
另一种方法是穷举法,即尝试计算所有可能的序列,这种方法的计算开销过大。
为解决这一问题,一个常用的方法是集束搜索(beam search) ,其基本思想是在decoder的每一步,我们不仅仅是取概率最大的单词,而是保存k个当前最有可能的翻译假设,其中k称作beam size,通常在5到10之间。下图为k=2的一个场景。集束搜索的结束条件是产生了 END 结束符或者达到预定的时间步。
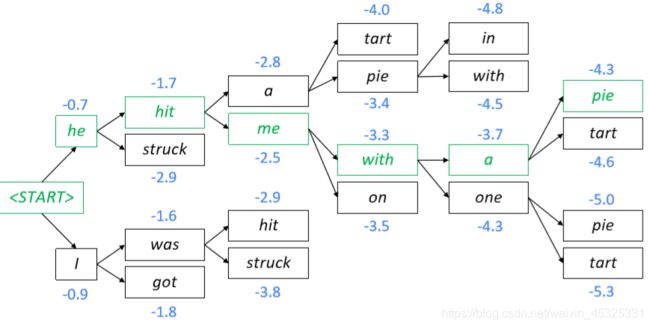
对于 y1、y2、y3… 的翻译,它的分数是
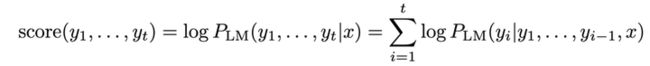
分数越高越好,但求和中的每一项都是负数,这会导致长的翻译分数更低,所以最后在选取整句概率最大的翻译时,要对分数做归一化

集束搜索不一定能找到最优解,但是比穷举法的效率要高很多。
与SMT相较,NMT的优势是我们可以整体的优化模型,而不是需要分开若干个模型各自优化,并且需要feature engineering较少,且模型更灵活,准确度也更高。其缺点是更难理解也更纠错,且很难设定一些人为的规则来进行控制。
3.评估方法——BLEU
BLEU (Bilingual Evaluation Understudy)的基本思想是将机器翻译和人工翻译(一个或多个),并计算一个相似的分数。BLEU score可以表示为(其中k通常选为4)
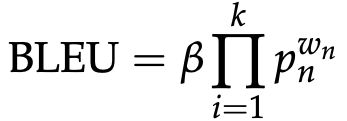
其中p来表示n-gram的precision score
![]()
β表示对过短翻译的惩罚
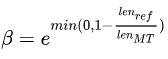
w作为权重,通常为
![]()
BLEU可以较好的反应翻译的准确度,当然它也不是完美的,也有许多关于如何改进机器翻译evaluation metric方面的研究。
4.注意力机制
Seq2Seq存在信息瓶颈的问题,即对于较长的句子,我们很难寄希望于将输入的序列转化为定长的向量而保存所有的有效信息,所以随着所需翻译句子的长度的增加,这种结构的效果会显著下降。为解决这个问题提出了注意力机制。注意力机制的核心理念 :在解码器的每一步,使用与编码器的直接连接来专注于源序列的特定部分。注意力机制可由下图仅表示:
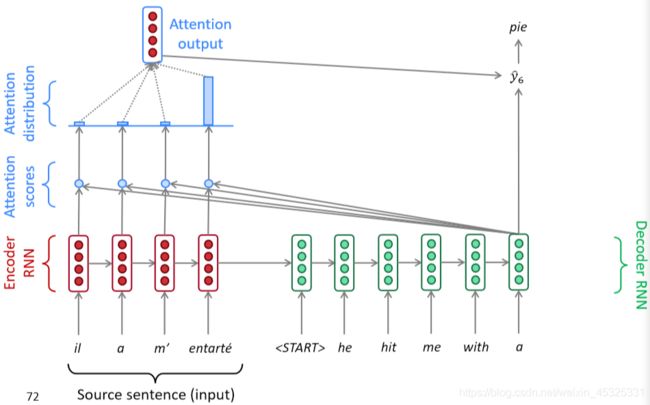
注意力机制的计算步骤如下:
-
将解码器要计算的时间步的隐藏状态与源语句中的每一个时间步的隐藏状态 h 进行点乘得到每一时间步的分数
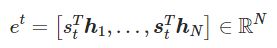
-
通过softmax将分数转化为概率分布

-
利用注意力分布对编码器的隐藏状态进行加权求和
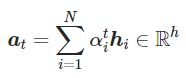
-
最后,我们将注意输出 at 与解码器隐藏状态连接起来,并按照非注意seq2seq模型继续进行
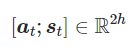
注意力机制的优点包括显著提高了NMT性能、解决瓶颈问题、帮助解决消失梯度问题、提供了一些可解释性。在计算注意力机制的步骤中,第一步计算注意力分数可以有多种方法,包括
- 基本的点乘注意力
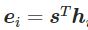
- 乘法注意力,W为权重矩阵
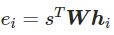
- 加法注意力,W1、W2为权重矩阵,v为权重向量
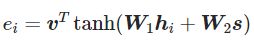
三、自然语言处理中的CNN
循环神经网络不能捕获没有前缀上下文的短语,经常在最终向量中捕获太多的最后单词。因此考虑用卷积神经网络对句子进行处理,为每个可能的子序列计算一定长度的向量。CNN中的步长、padding、池化等概念不详述。
1.用于文本分类的单层CNN
句子分类主要是区分句子的积极或者消极情绪,也可判断问题是关于什么实体的。下图为使用单层CNN进行句子分类的一个例子。

步骤如下:
- 输入长度为 7 的一句话,每个词的维度是 5 ,即输入矩阵是 7×5
- 使用不同的卷积核大小 : (2,3,4),并且每个大小都是用两个卷积核,获得两个通道的特征,即共计6个卷积核
- 对每个卷积核的特征进行最大池化后,拼接得到 6 维的向量,并使用softmax后再获得二分类结果
一些超参数选择和技巧:
- 使用预先训练的单词向量初始化(word2vec或Glove)
- 使用 Dropout ,Dropout提供了2 - 4%的精度改进
- L2正则化
- Batch Normalization
- 1 x 1 Convolutions
2.用于文本分类的深度卷积网络
下图是VD-CNN的架构图,VD-CNN的结构类似于视觉系统中的卷积神经网络结构如ResNet、VGGNet。系统从字符级开始工作,经过多个卷积-池化层后最终进行k-max池化,然后送入三个全连接层得到最终的结果。
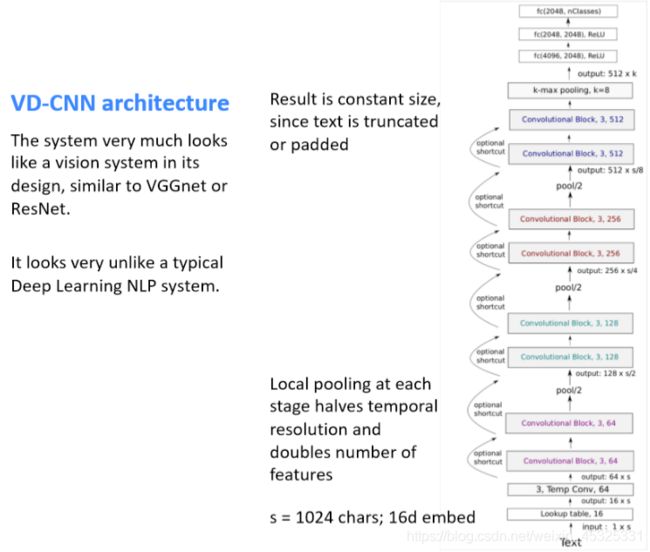
每个卷积块的结构如下:
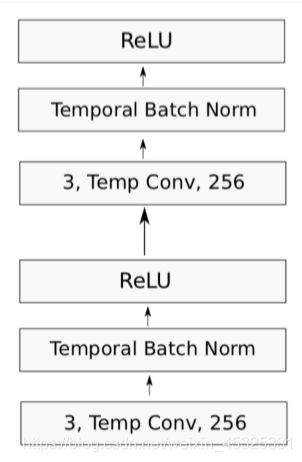
- 每个卷积块是两个卷积层,每个卷积层后面是BatchNorm和一个ReLU
- 卷积大小为3
- padding 以保持(或在局部池化时减半)维数
结论:
- 深度网络会取得更好的结果,残差层取得很好的结果,但是深度再深时并未取得效果提升
- 实验表明使用 MaxPooling 比 KMaxPooling 和 使用stride的卷积 的两种其他池化方法要更好
- ConvNets可以帮助我们建立很好的文本分类系统
3.Q-RNN
我们能够将RNN的对上下文信息的利用与CNN的并行计算快速的优点结合起来就会得到Q-RNN(Quasi-Recurrent Neural Networks)。下图为三种结构对比:
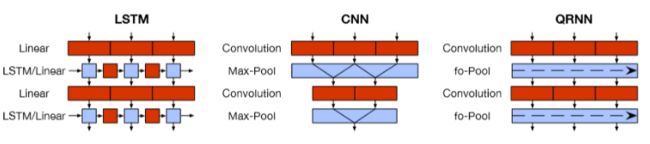
其基本思路是在RNN中,特征提取用LSTM,t时刻的计算需要依赖于t-1时刻的值所以无法并行计算,在QRNN中,我们将特征提取用convolution操作代替,即candidate vector, forget gate, output gate均用卷积来代替:

为了利用上下文信息,QRNN将CNN中的pooling layer用dynamic average pooling来替换:
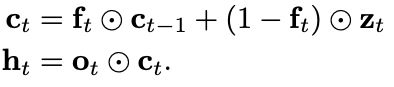
Q-CNN的优点:通常比LSTMs更好更快、更加的可解释
Q-CNN的缺点:对于字符级的LMs并不像LSTMs那样有效、通常需要更深入的网络来获得与LSTM一样好的性能
4.模型的对比
目前为止,一共接触到了四种模型,分别是词向量、基于窗口的模型、RNN、CNN,它们的使用场景如下:
- Bag of words:对于分类问题可以提供一个很好的基础模型,可以在其后添加若干层deep layer进一步改善效果。
- Window model:对于不需要有很长的上下文的分类问题适用,如POS(Part of speech), NER(Named Entity Recognition)等问题。
- CNN:对于分类问题效果较好,且适合并行计算。
- RNN:由于仅利用最后一个特征向量,对于分类问题不一定效果很好,且无法并行计算。但是对于语言模型更为适用,因为包含更多的顺序信息,而且与Attention机制结合效果会更好。