重新思考语义分割范式——SETR
关注"Smarter",加"星标"置顶
及时获取最优质的CV内容
![]()
一、论文信息
标题:《Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspectivewith Transformers》
作者:Sixiao Zheng et al.(复旦大学 & 牛津大学 & 萨里大学 & 腾讯优图 & 脸书)
文章:arxiv.org/abs/2012.1584
源码:官方 & 第三方复现(Pytorch)
二、论文解读
2.1 动机
自全卷积神经网络(FCN)提出以来,现有的语义分割框架大都是基于编码器-解码器(Encoder-Decoder)范式,其中:
编码器用于压缩原始输入图像的空间分辨率并逐步地提取更加高级的抽象语义特征;
解码器则用于将编码器所提取到的高级特征上采样到原始输入分辨率以进行像素级的预测;
上下文(context)信息是提升语义分割性能最关键的因素,而感受野(respect-field)则大致决定了网络能够利用到多少的信息。通常,在编码器中,我们会在下采样的过程中逐层的降低空间分辨率,以减少计算资源的消耗同时有效的扩大了网络的感受野。如此一来,CNN中不仅由于卷积的参数共享使得网络具有平移等变性(translation equivalence),而且还因为引入池化操作在一定程度上为网络引入了平移不变性(translation invariant),使网络对目标位置不那么敏感,间接地增强了网络对未知数据的推理能力,同时又通过共享卷积核来达到控制模型的复杂度。理论上,通过堆叠足够深的卷积层网络的感受野能够覆盖到输入图像的全局区域,然而:
(1)相关研究表明,网络的实际感受野远小于其理论感受野;
(2)考虑到参数量激增和计算量消耗与性能之间的平衡;
(3)过多的下采样操作会导致小目标的细节信息被严重损失甚至完全丢失;
因此,由于网络中的有效感受野是有限的(limited),这将会严重制约模型的表示能力。
其实,对于语义分割乃至分类、检测等几大主流的视觉任务来说,近几年的工作大都是基于一个核心点出发,即如何在保证效率的同时尽可能的捕获有效的上下文信息。主流方法主要有两种——改造原始的卷积操作或者在网络中引入注意力机制。
对于改造原始的卷积操作方式主要是通过扩大感受野从而来捕获局部的上下文信息:
large kernel sizes,e.g., Inception block;
atrous/dialted convolution, e.g., DeepLab series;
image/feature pyramid, e.g., PSPNet;
deformable convolution;
...
而注意力方法则更倾向于从不同维度建立长距离的依赖从而来捕获全局的上下文信息:
channel attention, e.g., SENet;
spatial attention, e.g., DANet;
self-attention, e.g., NonLocalNet;
...
作者认为,上述的方法均是基于FCN架构,均无法摆脱编码器需要 对输入特征图进行降采样的操作。而我们知道,Transformer 的一个特性便是能够保持输入和输出的空间分辨率不变,同时还能够有效的捕获全局的上下文信息。因此,作者这里便采用了类似ViT的结构来进行特征提取同时结合Decoder来恢复分辨率。在一定程度上可以避免审稿人质问:(1)Transformer和其它的自注意力的方法有啥区别?(2)利用Transformer进行特征提取相比于CNN有何优势?——写论文就是要会讲故事,让reviewer挑不出你的毛病。当然,这只是其中一关,除了故事本身的逻辑性,实验设置得是否合理以及充分也是个可以挑刺的地方。除此之外,我们知道TF的一个显著缺陷便是对计算和存储的要求特别高,如果没有进行底层优化,很难在GPU端飞起来。作者也是很巧妙,避开刷精度的路子,题目起了个"Rethinking",意在告诉审稿人我这只是一种尝试,我告诉后来人这条路走得通,可以往这走,至于效率优化方面就留点工作给别人,你也不要死揪着我这点不放哈哈。如果TF在分割这条路能一直火下去的话,ViT、DETR和SETR这三篇文章的引用量估计会获得爆发式的增长。关于TF的底层GPU优化,可以参考快手异构团队的工作。
为了避免给审稿人造成一种这就是一篇“ViT+Decoder”堆积木文章的错觉,作者还特地在引言末尾强调,话虽如此,但:
However, extending a pure transformer from image classification to a spatial location sensitive tasks of semantic segmentation is non-trivial.
话说这句话我还是挺认同作者的。因此笔者在此之前基于Pytorch框架随手复现了下这个结构,基于ViT进行特征提取,然后把中间层间隔抽出来并结合Decoder进行输出,在利用多卡训练的过程种发现性能只不过跟UNet差不多,但是效率方面,额(⊙﹏⊙),而且会出现学习率稍微大点loss就nan等问题。本以为能一飞冲天,结果没两个epoch一言不合就给你搞到自闭。当然笔者也不是专门在研究这个只是跑着玩玩,没去了解过这方面的训练技巧和一些注意事项,可能我实现的姿势不对,说不定这家伙很好train呢?继续往下读读,看看有没有惊喜╰(*°▽°*)╯,毕竟作者在ADE20K这个数据集上过榜首,至少说明是能work的吧???
2.2 相关工作
主要介绍了下语义分割和Transformer这两大板块的内容。最后着重分析了与Axial-DeepLab的不同之处:
Axial有对输入图像进行下采样,而SETR则全程利用序列到序列的模式并没有降低分辨率;
Axial采用了专门的设计的轴向注意力(见下),这对于标准计算设备来说可扩展性差,而SETR则始终坚持使用纯正的TF模块,可以简化易用性;
说实话,这里给出的区别点有点牵强,不明白作者为何要在这里特别强调这个,可能是审稿人提出跟Axial的区别吧?要不然这里贸然的对比意义并不大。
Axial-DeepLab是发表于ECCV 2020的一篇spotlight文章《Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation》,其核心思想是利用轴向注意力,即通过将2D的自注意力分解为两个1D的自注意力来消除卷积操作种局部感受野的限制,在降低计算复杂度的同时建立远距离的依赖捕获全局的上下文信息。除此之外,作者还提出了一个对位置敏感的自注意力设计,两者共同结合开发出一个position-sensitive axial-attention layer。额,不仔细看还以为是CCNet的翻版,这操作明显跟CCNet很类似啊,作者并没比较,而是往Non-Local方向上去进行横向比较了。
2.3 方法
SETR主要由三部分组成:输入→转换→输出。
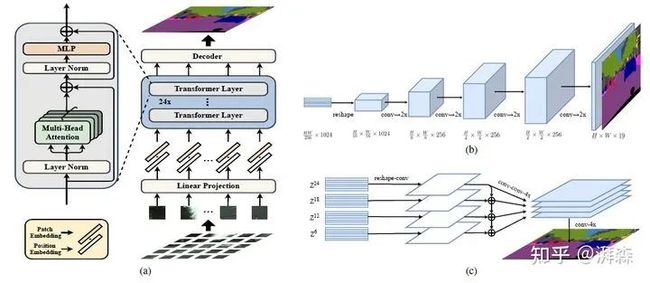 Schematic illustration of the proposed SEgmentation TRansformer (SETR) 。(a) 输入预处理及特征提取;(b)渐进式上采样;(c)多层级特征聚合。
Schematic illustration of the proposed SEgmentation TRansformer (SETR) 。(a) 输入预处理及特征提取;(b)渐进式上采样;(c)多层级特征聚合。
2.3.1 Image to sequence
首先,需要将原始的输入图片处理成Transformer能够支持的格式,这里作者参考了ViT的做法,即对输入图像进行切片处理,将每一个2D的图像切片(patch)视为一个“1D”的序列作为整体输入到网络当中。通常来说,Transformer接收的输入是一个1维的特征嵌入序列 ,其中 为序列的长度, 为隐藏层的通道尺寸。因此,对于图像序列而言,我们也需要将输入 转换为 .
一种最直接的做法便是将输入展平为一个列向量,这样暴力的做法无疑会造成计算量的爆炸。因此,作者这里采用切片的方式,每个切片大小为16*16,那么对于一张256*256大小的图片来说就可以切成256块( )。为了对每个切片的空间信息进行编码,可以为每个局部位置 都学习一个特定的嵌入 ,并将其添加到一个线性的投影函数 中来形成最终的输入序列 。如此一来,进行Transofomer是无序的,我们也仍然可以保留相对应的空间位置信息,因为我们对原始的位置信息进行了关联。
2.3.2 Transformer
通过将序列输入到Transformer架构可进行特征的提取,其主要包含两个部分Multi-head Self-Attention (MSA) and Multilayer Perceptron (MLP) blocks。具体的没啥好讲,自注意力核心就是QKV操作,而多头只不过是将它分组进行计算而已,稍微看下应该挺好理解的。
这里linear projection layers一般是指全连接层,用于改变通道维度。
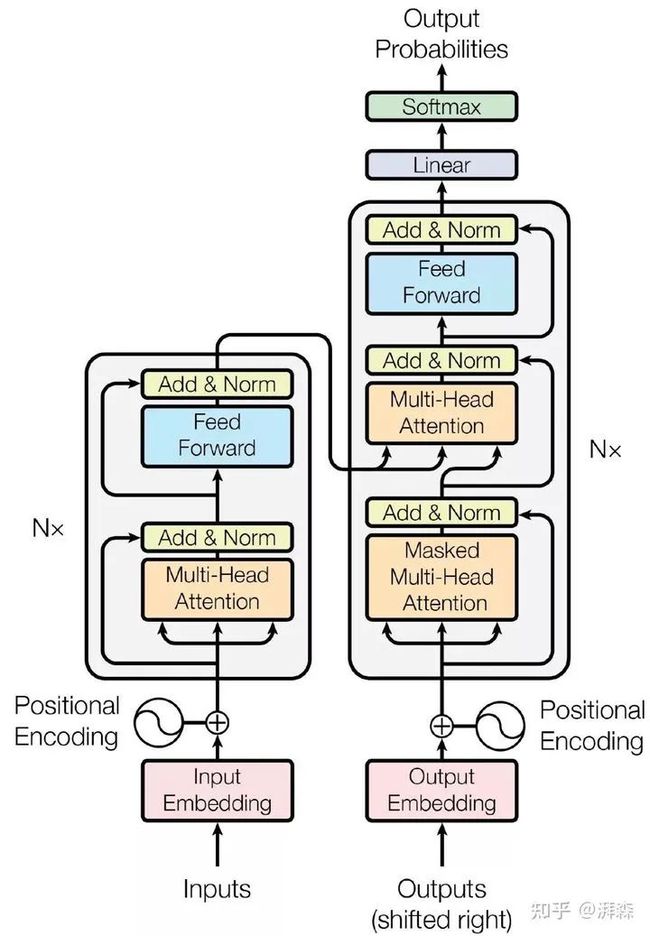 标准的Transformer结构
标准的Transformer结构
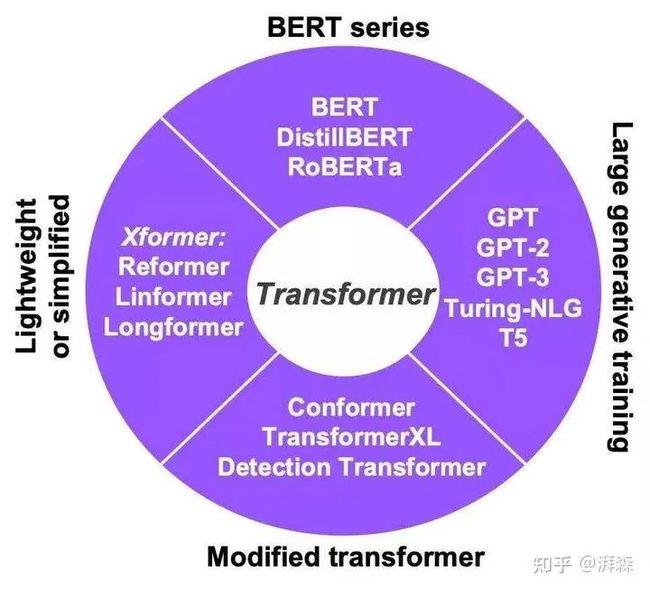
关于Transformer家族,可参考下图:
2.3.3 Decoder
关于解码器,作者这里给出了三种结构。值得注意的是,经过TF所提取出的特征其输入和输出的维度是一致的,为了进行最终的像素级分割,我们需要将其reshape成原始的空间分辨率。
Naive upsampling:第一种上采样方法比较朴素,作者这里给出的是利用一个2层的网络,即“1*1卷积+sync BN+ReLU+1*1卷积”,然后直接双线性上采样回原图分辨率;
Progressive UPsampling:第二种方式是采用渐进式上采样。为了避免引入过度的噪声,同时避免adversarial的影响(其实就是边缘会出现锯齿状),作者避免一步上采样,而是逐步的2倍上采样回去,类似于U-Net的操作;
Multi-Level feature Aggregation:第三种上采样方式是采用基于金字塔特征融合策略的多层级特征聚合。当然,这里并非严格的金字塔融合,毕竟TF每一层的输出特征图分辨率都是相同的。具体地,每隔6层抽取一个输出特征,将将其reshape成 ,然后分别经过一个3层(1×1+3×3+3×3)的网络,其中第1层和第3层的特征图通道数将为原始的一半,即输出维度是 ,随后对其进行4倍的双线性上采样操作,因此输出维度为 。为了增强不同层特征之间的交互,采用了自顶向下逐层融合(element-wise addtion)的策略,同时在每一层的融合后面外接一个3×3的卷积操作。最后,再将顶层特征图以及三层融合后的输出层特征分别按通道维度进行拼接级联,然后直接4倍双线性上采样回去,最终的输出维度为 ,这里还需要接个根据类别数进行转换输出。
2.4 实验
数据集
在Cityscapes[1]、ADE20K[2]以及PASCAL Context[3]这三个数据集上进行实验评估;
实现细节
基于mmsegmentation框架里面默认的设置(如数据增强和训练策略):
(1) 先以0.5或2的比例随机resize原图,然后随机裁剪成768、512和480分别应用于上述三个数据集,紧接着执行随机的水平翻转;
(2) 对于Cityscapes数据集,采用的batch size为8;而两外两个数据集ADE20K和PASCAL 则分别采用batch size为8和16的大小迭代训练160k和80k次;
(3) 采用多项式的学习率衰减策略并基于SGD进行训练和优化,其中Momentum和Weight decay分别设置为0.9和0;
(4) 最后,对于上述三个数据集的初始学习率分别设置为0.01、0.001以及0.01.
辅助损失
同PSPNet一样,作者在这里也引入了辅助损失。即监督不同的的层级输出:
(1) Naive upsampling——(Z10; Z15; Z20);
(2) Progressive UPsampling——(Z10; Z15; Z20; Z24);
(3) Multi-Level feature Aggregation——(Z6; Z12; Z18; Z24);
在PSPNet中最终的损失是 ,这里没有说加权应该是全部直接相加然后计算了。这里采用的是一个2层的(3×3 conv + Synchronized BN + 1×1 conv)网络进行中间层的输出。
多尺度测试
首先将输入图像缩放到一个统一的尺寸,然后执行多尺度的缩放以及随机的水平翻转,尺度缩放因子分别为(0.5,0.75,1.0,1.25,1.5,1.75),紧接着采用滑动窗口的方式进行重叠的切片预测,最后再合并测试结果。如果移动的步长不足以得到一张完整的切片,那么以短边为例保持同等的aspect ratio。其中,由于采用的是多卡的分布式训练,因此Synchronized BN也被用于解码器和辅助损失头的训练过程中。为了简化训练过程,作者这里并没采用在线困难样本挖掘(OHEM)[4]之类的trick用于模型的训练。
基准模型
采用mmsegmentation中自带的dilated FCN和Semantic FPN。注意到,考虑到计算的瓶颈,最终的FCN是8倍上采样回去,而本文所提出的SETF是进行16倍上采样。
SETR变体
SETR-Naive, SETR-PUP和SETR-MLA对应上述三种解码器。另外,对于编码器来说,采用的是M层的Transformer,这里根据M的大小划分为"T-Small"和"T-Large",分别对应12和24层。除非特别说明,本文默认采用的是24层的TF(这样一来就有3*2=6种组合)。初次之外,作者还涉及了一种结合CNN+TF的混合模型,即采用ResNet-50作为预编码器用于初步的特征提取,然后将所提取特征喂入SETR进行进一步的特征提取。为了降低GPU的计算开销,这里ResNet-50将原始输入图像下采样16倍,同时采用SETR-Naive-S的组合。
预训练
作者将ViT训练出来的权重用于SETR的编码器进行权重初始化。额,说白了就是把它照搬过来微调了下(白嫖?)。值得注意,这里非常关键的一点是随机初始化和带ViT的预训练权重效果差别这么大:

可视化

可以看出,在第1层的时候便可以捕获到全局的特征,越往后所提取到的特征越抽象。这足以证明Transformer建立长距离依赖的能力。
三、总结
总的来说,本文将Pure Transformer在自然图像的语义分割任务上进行了首次尝试,整体来说取得的效果是相当不错的。知乎貌似有许多人对其开炮,质疑其创新点不足或者没有放出参数量计算量等亦或是没跟基于自注意力的方法如CC-Net和EMA-Net等比较。然而,我个人的观点的是论文本身可以分为两种,一种是精度型,一种是探索型。大家纠结的原因就是将其归纳为前者,当然这里与作者反复强调在ADE-20k数据集上取得xx成绩也有关,很容易把节奏带进去。为了弥补,作者在题目又强调时Rethinking,即本文只是尝试可以这样做。且不论这个创新性有多强,这其实更应该被当成一篇实验性论文,告诉大家这条路可以走得通。其实,当看到这篇文章的时候,我最关注的地方并不是整体的结构,而是作者是如何将其训练到work的?毕竟这种结构我想绝大多数人都试到吐了,通过整篇文章读下来,才发现要训好这个网络步骤原来这么繁琐,难道笔者基于同样的结构训练一轮下来被直接摁在地下摩擦。最后,很好奇SETF是基于什么样的硬件设施下进行实验的?
@lzai
Reference
[1] The cityscapes dataset for semantic urban scene understanding.
[2] Semantic understanding of scenes through the ade20k dataset.
[3] The role of context for object detection and semantic segmentation in the wild.
[4] Ocnet: Object context network for scene parsing
![]()

请长按或扫描二维码关注本公众号
喜欢的话,请给我个在看吧!