BP神经网络(反向传播算法原理、推导过程、计算步骤)
BP神经网络
- 1、反向传播算法的原理
- 2、反向传播算法参数学习的推导
- 3、反向传播算法参数更新案例
-
- 3.1 反向传播的具体计算步骤
-
- 3.1.1 计算输出层的误差
- 3.1.2 计算隐藏层误差
- 3.1.3 根据神经元误差,更新神经元间偏置和神经元间的连接权重。
- 3.1.4 进一步后向传播
- 4、实战:神经网络分类器
1、反向传播算法的原理
反向传播算法的核心思想是将输出误差以某种形式通过隐藏层向输入层逐层反转,如下图所示。

反向传播算法在整个神经网络训练过程中发挥着重要的作用,它调整神经元之间的参数来学习样本中的规则,事实上权重存储了数据中存在的特征。在训练过程中,前向传播和后向传播相辅相成,如下图所示。

反向传播算法由Hinton于1986年在Nature的论文中提出。简单来说,反向传播主要解决神经网络在训练模型时的参数更新问题。假设神经网络如下图所示,为了简化推到过程,输入层只用了一个特征。同样,输出层也只有一个节点,隐藏层使用了两个节点。注意,在实际的神经网络中,唱吧 z 1 z_1 z1和 h 1 h_1 h1当作一个节点来画图(其中 z 1 = x w 1 , h 1 = s i g m o i d ( z 1 ) z_1=xw_1,h_1=sigmoid(z_1) z1=xw1,h1=sigmoid(z1),注意也可以是其他激活函数),这里为了方便推到才把两者分开。
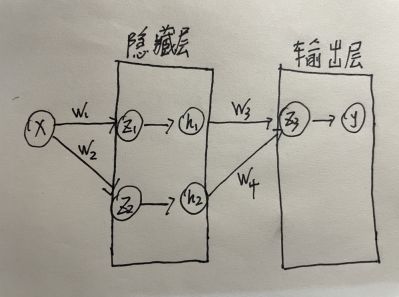
反向传播算法需要解决每条边对应的权值如何更新才能使得整个输出的损失函数最小。在反向传播算法中,对于每个输出节点,给定一个输入样例,会得到一个预测值,而这个预测值和真实值之间的差距可以定义为误差(类比“欠的钱”),是谁影响了欠钱的多少?很明显,在神经网络模型中,只有待求的参数 w 1 , w 2 , . . . , w n {w_1,w_2,...,w_n} w1,w2,...,wn了。
如何衡量每个参数对误差的影响?我们定义一个敏感度:当参数 w i w_i wi在某个很小的范围内变动时,误差变动了多少,数学表示为 Δ L Δ w i \frac{\Delta L }{\Delta w_i} ΔwiΔL。考虑一般情况,即微分 ∂ L ∂ w i \frac{\partial L}{\partial w_i} ∂wi∂L,其中L表示损失函数(即误差), Δ L , ∂ L \Delta L,\partial L ΔL,∂L均表示因为参数变化而引起的损失函数的微小变化。
这样我们就有了基础的微分表达式,也是反向传播所有推导公式的基础,其实 Δ L Δ w i \frac{\Delta L }{\Delta w_i} ΔwiΔL很有意思,因为不管最终L(w)是什么样子, Δ L Δ w i \frac{\Delta L }{\Delta w_i} ΔwiΔL=定值。所以,假设 Δ w i \Delta w_i Δwi>0,那么该定值为负数的情况下, w i w_i wi增大的方向上, L ( w i ) L(w_i) L(wi)将减少,而该定值为正数时, w i w_i wi增大的方向上, L ( w i ) L(w_i) L(wi)将增大。
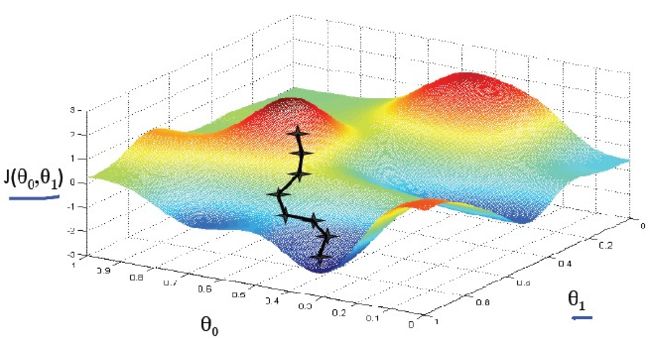
梯度下降的更新算法有: w : = w − η ∂ L ∂ w i w:=w-\eta \frac{\partial L}{\partial w_i} w:=w−η∂wi∂L,可以结合下图进行理解。所谓梯度,其本意是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)。下图中, J ( θ 0 , θ 1 ) J(\theta _0,\theta _1) J(θ0,θ1)表示损失函数, θ 0 和 θ 1 \theta_0和\theta_1 θ0和θ1表示两个参数,利用梯度下降法对 J ( θ 0 , θ 1 ) J(\theta _0,\theta _1) J(θ0,θ1)优化取最小值相当于从起始点开始总是沿着梯度最大的反方向(反方向用负号表示)移动一定的距离,移动距离的大小由学习率决定,正如图中黑色折线代表的路径,一步一步达到 J ( θ 0 , θ 1 ) J(\theta _0,\theta _1) J(θ0,θ1)的最小值或局部最小值。
2、反向传播算法参数学习的推导
这里依然使用如下图所示的神经网络进行计算和推到。这个简单的神经网络图有助于理解反向传播算法的构建过程。虽然与真实的神经网络有一定的差距,但分析过程是大同小异的。
由图可知:
z 1 = w 1 x z 2 = w 2 x h 1 = 1 1 + e − z 1 h 2 = 1 1 + e − z 2 z 3 = w 3 h 1 + w 4 h 2 y = 1 1 + e − z 3 z_1=w_1x\\ z_2=w_2x\\ h_1=\frac{1}{1+e^{-z_1}}\\ h_2=\frac{1}{1+e^{-z_2}}\\ z_3=w_3h_1+w_4h_2\\ y=\frac{1}{1+e^{-z_3}} z1=w1xz2=w2xh1=1+e−z11h2=1+e−z21z3=w3h1+w4h2y=1+e−z31
假设已知输入x,我们就能根据这一系列公式求得y。接下来,我们需要定义损失函数,使用平方误差函数(只针对一次输入):
L = 1 2 ( y − t ) 2 L=\frac{1}{2}(y-t)^2 L=21(y−t)2
式中,t表示真实值,y表示预测值,根据前面的介绍,模型训练实际上是更新 w i w_i wi,既然要更新 w i w_i wi,就需要求解 ∂ L ∂ w i \frac{\partial L}{\partial w_i} ∂wi∂L。于是,对于 w i w_i wi,根据链式求导法则,可以求得:
∂ L ∂ w 1 = ∂ L ∂ y ∂ y ∂ z 3 ∂ z 3 ∂ h 1 ∂ h 1 ∂ z 1 ∂ z 1 ∂ w 1 \frac{\partial L}{\partial w_1} =\frac{\partial L}{\partial y} \frac{\partial y}{\partial z_3} \frac{\partial z_3}{\partial h_1} \frac{\partial h_1}{\partial z_1} \frac{\partial z_1}{\partial w_1} ∂w1∂L=∂y∂L∂z3∂y∂h1∂z3∂z1∂h1∂w1∂z1
我们再求 w 3 w_3 w3:
∂ L ∂ w 3 = ∂ L ∂ y ∂ y ∂ z 3 ∂ z 3 ∂ w 3 \frac{\partial L}{\partial w_3} =\frac{\partial L}{\partial y} \frac{\partial y}{\partial z_3} \frac{\partial z_3}{\partial w_3} ∂w3∂L=∂y∂L∂z3∂y∂w3∂z3
从中我们可以看到一些模式(规律)。实际上,对于 w 1 w_1 w1的更新,在它相关的路径上,每条边的后继和前继节点对应的就是偏导的分子和分母。 w 3 w_3 w3同样如此,它的相关边有三条(最后y指向L的关系边没有画出来),对应的链式法则也恰好有三个偏导。
继续细化上述公式,目前来看,这与反向传播似乎没有什么关系。的确,根据这些性质还不足以引出反向传播,让我们继续往下看。
因为偏导数中的每个函数映射都是确定的(函数已经确定),所以我们可以求出所有偏导数,于是有:
∂ L ∂ w 1 = ( y − t ) ⋅ y ⋅ ( 1 − y ) ⋅ w 3 ⋅ h 1 ⋅ ( 1 − h 1 ) ⋅ x \frac{\partial L}{\partial w_1} =(y-t)\cdot y\cdot(1-y)\cdot w_3\cdot h_1\cdot (1-h_1)\cdot x ∂w1∂L=(y−t)⋅y⋅(1−y)⋅w3⋅h1⋅(1−h1)⋅x
式中,x,t由样本给定,而 y , h 1 , w 3 y,h_1,w_3 y,h1,w3都在计算y时能够得到,这就意味着所有变量都是已知的,可以直接求出 ∂ L ∂ w 1 \frac{\partial L}{\partial w_1} ∂w1∂L。那怎么会有前向和反向“传播”呢?
宏观上,可以考虑一个非常大型的神经网络,它的参数 w i w_i wi可能有成千上万个,对于每个参数我们都要列处一个偏导公式吗?这显然不现实。因此,我们需要进一步挖掘它们共同的模式。
继续看下图:
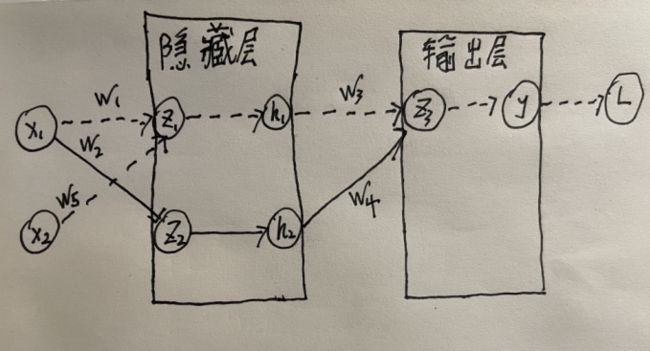
假设我们加入第二个特征 x 2 x_2 x2,那么对应的 w 5 w_5 w5的更新,我们有如下公式:
∂ L ∂ w 5 = ∂ L ∂ y ∂ y ∂ z 3 ∂ z 3 ∂ h 1 ∂ h 1 ∂ z 1 ∂ z 1 ∂ w 5 \frac{\partial L}{\partial w_5} =\frac{\partial L}{\partial y} \frac{\partial y}{\partial z_3} \frac{\partial z_3}{\partial h_1} \frac{\partial h_1}{\partial z_1} \frac{\partial z_1}{\partial w_5} ∂w5∂L=∂y∂L∂z3∂y∂h1∂z3∂z1∂h1∂w5∂z1
对比一下 w 1 w_1 w1:
∂ L ∂ w 1 = ∂ L ∂ y ∂ y ∂ z 3 ∂ z 3 ∂ h 1 ∂ h 1 ∂ z 1 ∂ z 1 ∂ w 1 \frac{\partial L}{\partial w_1} =\frac{\partial L}{\partial y} \frac{\partial y}{\partial z_3} \frac{\partial z_3}{\partial h_1} \frac{\partial h_1}{\partial z_1} \frac{\partial z_1}{\partial w_1} ∂w1∂L=∂y∂L∂z3∂y∂h1∂z3∂z1∂h1∂w1∂z1
实际上,只有最后一个分母发生了变化。我们刚才也总结出了一个重要结论,每个偏导代表一条边,所以对于 w 5 w_5 w5的更新,前面四个偏导值都需要重新计算一遍,也就是虚线指出的部分,为了计算 w 5 w_5 w5,需要重新走过 w 1 w_1 w1的部分路径。
即使我们用输入 ( x 1 , x 2 ) (x_1,x_2) (x1,x2)求出了每个节点(如 z 1 , h 1 , z 2 , h 2 , z 3 , y z_1,h_1,z_2,h_2,z_3,y z1,h1,z2,h2,z3,y)的值,为了求出每个 w i w_i wi的偏导,需要多次代入这些变量,于是产生了大量的冗余。
另外,对于每个 w i w_i wi搜使用手工求偏导实在是太复杂了。事实上,在上面例子计算偏导的过程中,如果有中间变量
δ j = ∂ L ∂ y ∂ y ∂ z 3 ∂ z 3 ∂ h 1 ∂ h 1 ∂ z 1 \delta _j=\frac{\partial L}{\partial y} \frac{\partial y}{\partial z_3} \frac{\partial z_3}{\partial h_1} \frac{\partial h_1}{\partial z_1} δj=∂y∂L∂z3∂y∂h1∂z3∂z1∂h1
那么计算 w 1 w_1 w1和 w 5 w_5 w5时,只要有对应的 δ j ⋅ ∂ z 1 ∂ w 1 \delta _j\cdot \frac{\partial z_1}{\partial w_1} δj⋅∂w1∂z1和 δ j ⋅ ∂ z 1 ∂ w 5 \delta _j\cdot \frac{\partial z_1}{\partial w_5} δj⋅∂w5∂z1,对于中间的子状态只需要计算一次,而不是指数型增长。这大大减少了重复计算,降低了计算的成本。
这和递归记忆化搜索(自顶向下)以及动态规划(自底向上)的两种对偶形式很像,为了解决重复子问题,我们可以采用反向传播。如果能够定义出合适的子状态,且得出递推式,那么工作就完成了。
再来对比下 w 1 w_1 w1和 w 3 w_3 w3的偏导,继续寻找规律:
∂ L ∂ w 1 = ∂ L ∂ y ∂ y ∂ z 3 ∂ z 3 ∂ h 1 ∂ h 1 ∂ z 1 ∂ z 1 ∂ w 1 ∂ L ∂ w 3 = ∂ L ∂ y ∂ y ∂ z 3 ∂ z 3 ∂ w 3 \frac{\partial L}{\partial w_1} =\frac{\partial L}{\partial y} \frac{\partial y}{\partial z_3} \frac{\partial z_3}{\partial h_1} \frac{\partial h_1}{\partial z_1} \frac{\partial z_1}{\partial w_1}\\ \frac{\partial L}{\partial w_3} =\frac{\partial L}{\partial y} \frac{\partial y}{\partial z_3} \frac{\partial z_3}{\partial w_3} ∂w1∂L=∂y∂L∂z3∂y∂h1∂z3∂z1∂h1∂w1∂z1∂w3∂L=∂y∂L∂z3∂y∂w3∂z3
这两个式子中,只有前两部分是一样的,所以可以令 δ 1 = ∂ L ∂ y ∂ y ∂ z 3 \delta ^1=\frac{\partial L}{\partial y} \frac{\partial y}{\partial z_3} δ1=∂y∂L∂z3∂y,这样处理的好处在于,求 w 3 w_3 w3时,可以有:
∂ L ∂ w 3 = δ 1 ∂ z 3 ∂ w 3 \frac{\partial L}{\partial w_3}=\delta ^1\frac{\partial z_3}{\partial w_3} ∂w3∂L=δ1∂w3∂z3
求 w 1 w_1 w1时,可以有:
∂ L ∂ w 1 = δ 1 ∂ z 3 ∂ h 1 ∂ h 1 ∂ z 1 ∂ z 1 ∂ w 1 \frac{\partial L}{\partial w_1} = \delta ^1\frac{\partial z_3}{\partial h_1} \frac{\partial h_1}{\partial z_1} \frac{\partial z_1}{\partial w_1} ∂w1∂L=δ1∂h1∂z3∂z1∂h1∂w1∂z1
综合图来理解, δ 1 \delta ^1 δ1表示聚集在 z 3 z_3 z3的误差,为什么是 z 3 z_3 z3?因为在这里刚好可以求出 w 3 w_3 w3的偏导;结合公式理解,就是公式中的公共部分(重复子问题)。
我们可以同样定义第二层的误差 δ 1 2 \delta_1^2 δ12表示聚集在 z 1 z_1 z1的误差, δ 2 2 \delta_2^2 δ22表示聚集在 z 2 z_2 z2的误差。所以有:
δ 1 2 = δ 1 ∂ z 3 ∂ h 1 ∂ h 1 ∂ z 1 = δ 1 ⋅ w 3 ⋅ h 1 z 1 \delta_1^2=\delta^1\frac{\partial z_3}{\partial h_1} \frac{\partial h_1}{\partial z_1}=\delta^1\cdot w_3\cdot \frac{h_1}{z_1} δ12=δ1∂h1∂z3∂z1∂h1=δ1⋅w3⋅z1h1
对应地, w 1 w_1 w1的偏导公式可以有:
∂ L ∂ w 1 = δ 1 2 ∂ z 1 ∂ w 1 \frac{\partial L}{\partial w_1}=\delta_1^2\frac{\partial z_1}{\partial w_1} ∂w1∂L=δ12∂w1∂z1
对比 w 1 , w 5 , w 3 w_1,w_5,w_3 w1,w5,w3,可以得到:
∂ L ∂ w 1 = δ 1 2 ∂ z 1 ∂ w 1 ∂ L ∂ w 5 = δ 1 2 ∂ z 1 ∂ w 5 ∂ L ∂ w 3 = δ 1 ∂ z 3 ∂ w 3 \frac{\partial L}{\partial w_1}=\delta_1^2\frac{\partial z_1}{\partial w_1}\\ \frac{\partial L}{\partial w_5}=\delta_1^2\frac{\partial z_1}{\partial w_5}\\ \frac{\partial L}{\partial w_3}=\delta_1\frac{\partial z_3}{\partial w_3} ∂w1∂L=δ12∂w1∂z1∂w5∂L=δ12∂w5∂z1∂w3∂L=δ1∂w3∂z3
它们都属于同一种形式,而 δ 2 \delta^2 δ2是由 δ 1 \delta^1 δ1加上对应的 w i w_i wi求得,所以我们首要的目标是求出最后一层的 δ 1 \delta ^1 δ1,接着就能根据前一层的权值 w i w_i wi求出前一层每个节点的 δ 2 \delta^2 δ2。更新公式都一样,用 δ 2 \delta^2 δ2乘以上一层的输出值而已,因为 y 1 = h 1 w 1 + h 2 w 2 y_1=h_1w_1+h_2w_2 y1=h1w1+h2w2是线性的,求偏导 h 1 h_1 h1得到 w 1 w_1 w1,求偏导 w 1 w_1 w1得到 h 1 h_1 h1。
至此,离真正的反向传播推导出的公式还差一点,继续看下图:
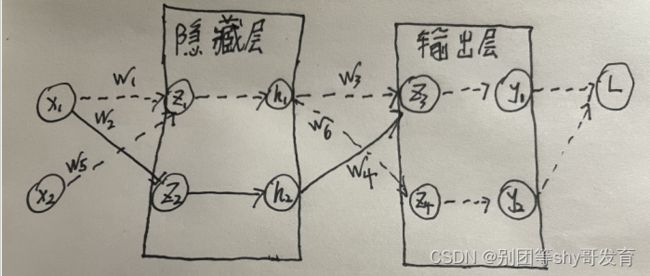
我们按照关系边的概念,可以知道 w 5 w_5 w5的关系边应该由虚线的边组成。所以 δ 2 \delta^2 δ2的更新不止和 z 3 z_3 z3有关系,还和 z 4 z_4 z4有关。此时损失函数由两部分组成,对应一个输入样例 ( x 1 , x 2 ) (x_1,x_2) (x1,x2),有:
L = 1 2 ( y 1 − t 1 ) 2 + 1 2 ( y 2 − t 2 ) 2 L=\frac{1}{2}(y_1-t_1)^2+ \frac{1}{2}(y_2-t_2)^2 L=21(y1−t1)2+21(y2−t2)2
所以对L求偏导,由加法法则可以得到 ∂ L ∂ w 5 = ∂ L ∂ y 1 + ∂ L ∂ y 2 \frac{\partial L}{\partial w_5}= \frac{\partial L}{\partial y_1}+ \frac{\partial L}{\partial y_2} ∂w5∂L=∂y1∂L+∂y2∂L,即多个节点指向同一个节点时,把它们的偏导值加起来即可(损失函数就这么定义)。故
δ j 2 = ∂ h j ∂ z j ∑ w i j ⋅ δ i 1 \delta _j^2=\frac{\partial h_j}{\partial z_j} \sum w_{ij}\cdot \delta ^1_i δj2=∂zj∂hj∑wij⋅δi1
3、反向传播算法参数更新案例
如下图所示的三层神经网络,其激活函数为sigmoid函数,下面以这个简单的三层神经元为例,计算反向传播算法。
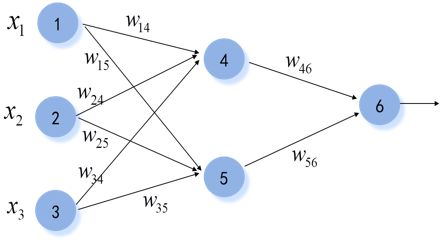
神经网络输入、权重及偏置项初始值

神经元前向传播(这个比较简单,这里不过多介绍了,就是每个节点加权求和,在带入激活函数)
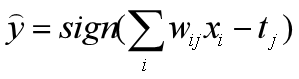

根据前面关于反向传播算法的简单推到,结合实例,可以进一步推出这个神经网络的反向传播公式如下:
E r r o = O j ( 1 − O j ) ( T j − O j ) E r r j = O j ( 1 − O j ) ∑ k E r r k w j k Err_o=O_j(1-O_j)(T_j-O_j)\\ Err_j=O_j(1-O_j)\sum_{k}^{}Err_kw_{jk} Erro=Oj(1−Oj)(Tj−Oj)Errj=Oj(1−Oj)k∑Errkwjk
其中 E r r O Err_O ErrO表示输出层的误差, E r r j Err_j Errj表示中间隐藏层的误差, O j O_j Oj表示当前神经元的输出值, T j T_j Tj表示该数据样本的真实值(即标签)。应当明确,反向传播的目的是调整神经网络的权重和偏置,让模型学习到数据中的规律,因此,计算误差只是中间环节,最重要的是权重的更新,如下式所示:
w i j = w i j + λ E r r j O i t j = t j + λ E r r j w_{ij}=w_{ij}+\lambda Err_jO_i\\ t_j=t_j+\lambda Err_j wij=wij+λErrjOitj=tj+λErrj
其中, w i j w_{ij} wij为权重, t j t_j tj为偏置, λ \lambda λ为学习率。
3.1 反向传播的具体计算步骤
3.1.1 计算输出层的误差
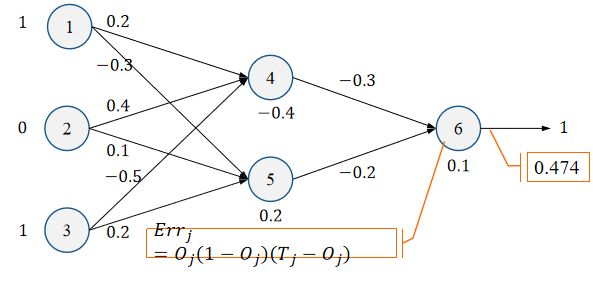
E r r 6 = O 6 ( 1 − O 6 ) ( T j − O 6 ) = 0.474 ∗ ( 1 − 0.474 ) ∗ ( 1 − 0.474 ) = 0.1311 Err_6=O_6(1-O_6)(T_j-O_6)=0.474*(1-0.474)*(1-0.474)=0.1311 Err6=O6(1−O6)(Tj−O6)=0.474∗(1−0.474)∗(1−0.474)=0.1311
3.1.2 计算隐藏层误差
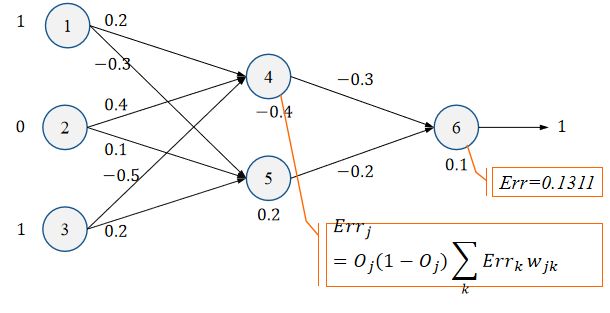
E r r 4 = O 4 ( 1 − O 4 ) E r r 6 w 46 = 0.332 ∗ ( 1 − 0.332 ) ∗ 0.1311 ∗ ( − 0.3 ) = − 0.0087 Err_4=O_4(1-O_4)Err_6w_{46}=0.332*(1-0.332)*0.1311*(-0.3)=-0.0087 Err4=O4(1−O4)Err6w46=0.332∗(1−0.332)∗0.1311∗(−0.3)=−0.0087
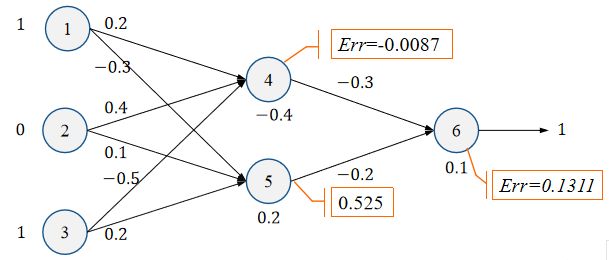
E r r 5 = O 5 ( 1 − O 5 ) E r r 6 w 56 = 0.525 ∗ ( 1 − 0.525 ) ∗ 0.1311 ∗ ( − 0.2 ) = − 0.0065 Err_5=O_5(1-O_5)Err_6w_{56}=0.525*(1-0.525)*0.1311*(-0.2)=-0.0065 Err5=O5(1−O5)Err6w56=0.525∗(1−0.525)∗0.1311∗(−0.2)=−0.0065
3.1.3 根据神经元误差,更新神经元间偏置和神经元间的连接权重。
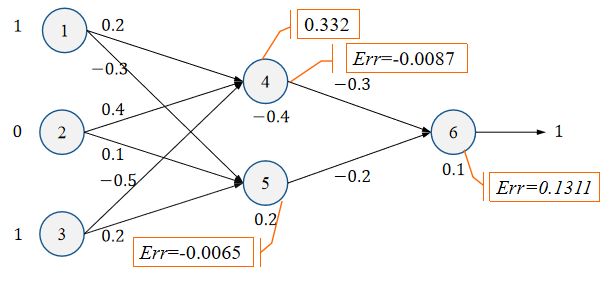
w 46 = w 46 + λ E r r 6 O 4 = − 0.3 + 0.9 ∗ 0.1311 ∗ 0.332 = − 0.261 w_{46}=w_{46}+\lambda Err_6O_4=-0.3+0.9*0.1311*0.332=-0.261 w46=w46+λErr6O4=−0.3+0.9∗0.1311∗0.332=−0.261
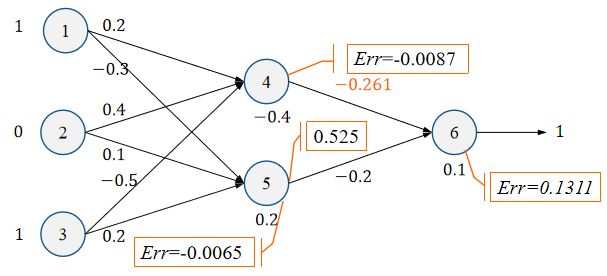
w 56 = w 56 + λ E r r 6 O 5 = − 0.2 + 0.9 ∗ 0.1311 ∗ 0.525 = − 0.138 w_{56}=w_{56}+\lambda Err_6O_5=-0.2+0.9*0.1311*0.525=-0.138 w56=w56+λErr6O5=−0.2+0.9∗0.1311∗0.525=−0.138
3.1.4 进一步后向传播
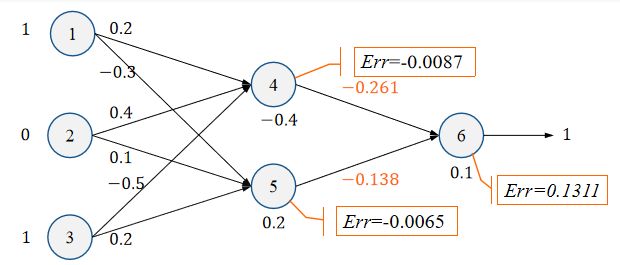
w 35 = w 35 + λ E r r 5 O 3 = 0.2 + 0.9 ∗ ( − 0.0065 ) ∗ 1 = 0.194 w_{35}=w_{35}+\lambda Err_5O_3=0.2+0.9*(-0.0065)*1=0.194 w35=w35+λErr5O3=0.2+0.9∗(−0.0065)∗1=0.194
按照相同的方法进一步计算其他参数更新后的值,如下表所示:
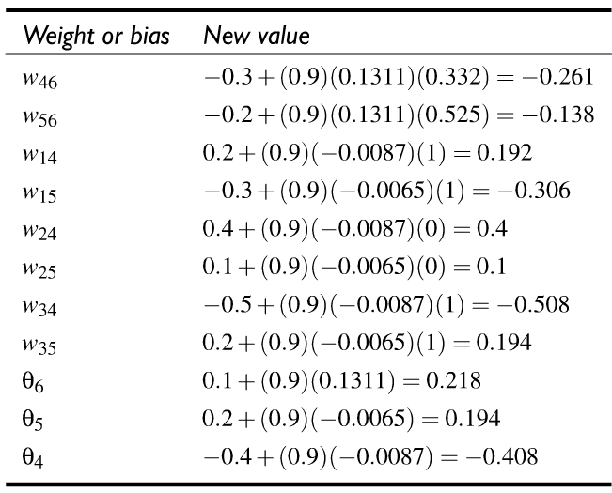
上述就是反向传播算法的实例。该三层神经网络虽然简单,但是反向传播的原理同样适用于更复杂的网络。
4、实战:神经网络分类器
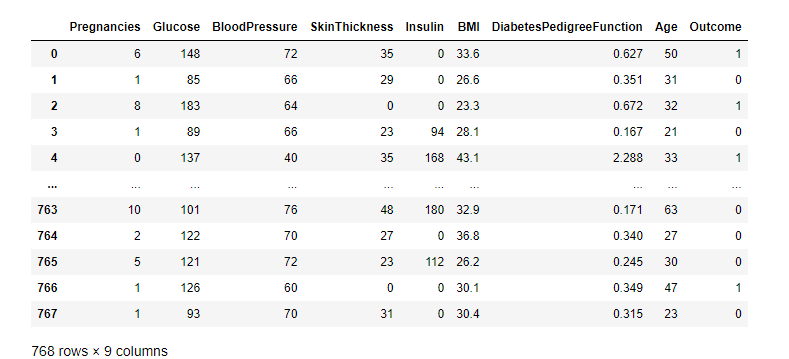
数据集是印第安人糖尿病数据集,利用MLPClassifier函数制作神经网络,实现糖尿病数据集分类
# 神经网络分类器
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import pandas as pd
data_url="pima-indians-diabetes.csv"
df=pd.read_csv(data_url)
display(df)
X=df.iloc[:,0:8]
y=df.iloc[:,8]
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=0)
clf=MLPClassifier(solver='sgd',alpha=1e-5,hidden_layer_sizes=(5,2),random_state=1)
clf.fit(X_train,y_train)
print('训练集准确率:',accuracy_score(y_train,clf.predict(X_train)))
print('测试集准确率:',accuracy_score(y_test,clf.predict(X_test)))

只是简单演示算法,并没有过多的输出模型评估指标。