NLP学习—13.Seq2eq在机器翻译中的实战(bleu指标的代码实现)
文章目录
-
-
- 引言
- 一、Seq2eq+Attention于机器翻译中的原理以及及attention的计算
- 二、评价指标bleu
-
- 1.bleu指标实现
- 2.nltk中的bleu
- 三、基于Seq2eq+Attention的机器翻译实战
-
引言
利用PyTorch实现Seq2eq+Attention的模型,并且利用bleu评价指标评价语言生成的好坏。
一、Seq2eq+Attention于机器翻译中的原理以及及attention的计算
在机器翻译中,输入是A语言,输出是B语言,A语言是Encoder的输入,B语言是Decoder的输入。A语言通过Encoder获得的表征得到每个时间步隐变量,利用Attention机制对每个时间步的隐变量进行权重分配得到总的隐变量,总的隐变量与Encoder层最后一个时刻的隐变量拼接,Decoder(解码器)将拼接后的变量进行解码。
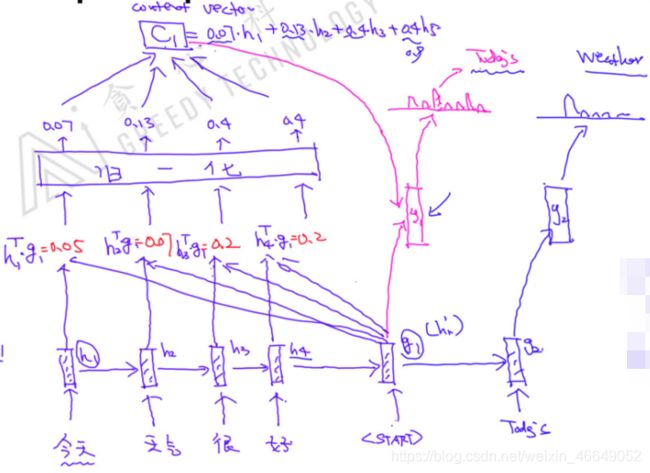
机器翻译模型训练过程与预测过程的模型输入是不同。在训练过程是有标准答案的,标准答案为训练目标,它会将标准答案作为输入,而不会将预测结果作为输入,意思就是在Decoder过程中,虽然可能预测结果是错误的,但是下一个时间步的输入仍然是标准答案。因此,可以将标准答案一起输入到模型中,不需要等上一个时间预测完。而在预测过程中,显然是没有标准答案的,因此,将预测的结果作为下一时间步的input。
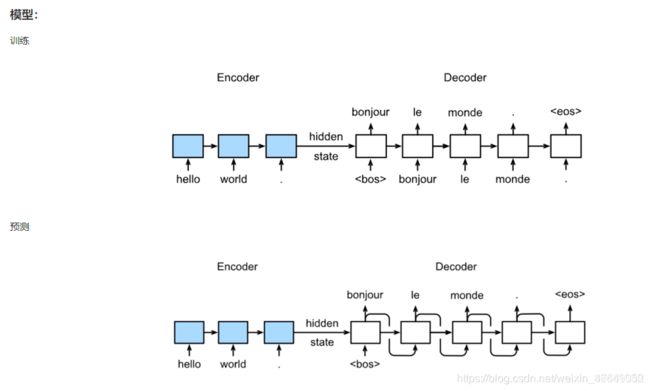
在训练过程中,实际上还涉及teacher forcing优化策略,即在开始学习标准答案来辅导你,训练的不错时,会以 ϵ \epsilon ϵ的概率来选择是利用标准答案还是预测结果? ϵ \epsilon ϵ随着训练epoch的增大,概率逐渐增大,基于概率来选择。
在机器翻译中,需要维护两个word2id与id2word。比如:Encoder层适用于A语言的word2id,Decoder层适用于B语言的word2id。这两个层会自动学习不同的index输入的embedding的差距。
总结重点:
- 训练过程有标准答案,标准答案作为输入
- 预测过程没有标准答案,需要将预测结果作为下一个时间步的输入
- 机器翻译中需要维护两个word2id与id2word
Encoder Output( h t h_t ht)在Decoder中有不同的使用:
- 只作为Decoder的初始化
- 可以在每一个时间步中使用

- 如果涉及到Attention,Decoder层的每一个输入涉及到Encoder里的每一个隐变量



二、评价指标bleu
语言生成实际上是多个time-step的分类问题,Precision、Recall、F1都可以作为评价指标。下面介绍新的评价指标bleu
考虑句子的Precision,
reference:
The cat is on the mat
There is a cat on the mat
candidate:
the the the the the the
从1-gram角度来看,Precision=1,这显然是不对的;从2-gram角度来看,Precision=0;从3-gram角度来看,Precision=0;所以对Precision进行改造,得到modify Precision。
![]()
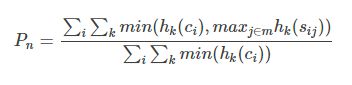
i i i表示第几个candidate
k k k表示第几个n-gram
P n P_n Pn是n-gram的Precision。
h k ( c i ) h_k(c_i) hk(ci)是在candidate中某一个n-gram的次数
h k ( s i j ) h_k(s_{ij}) hk(sij)是在第 j j j个reference中某一个n-gram的次数。
假设candidate为the cat the cat on the mat,统计 h k ( c i ) h_k(c_i) hk(ci)、 h k ( s i j ) h_k(s_{ij}) hk(sij)
| 2-gram | h k ( c i ) h_k(c_i) hk(ci) | h k ( s i 1 ) h_k(s_{i1}) hk(si1) | h k ( s i 2 ) h_k(s_{i2}) hk(si2) | m a x ( h k ) max(h_k) max(hk) | C o u n t c l i p Count_{clip} Countclip |
|---|---|---|---|---|---|
| the cat | 2 | 1 | 0 | 1 | 1 |
| cat the | 1 | 0 | 0 | 0 | 1 |
| cat on | 1 | 0 | 1 | 1 | 1 |
| on the | 1 | 1 | 1 | 1 | 1 |
| the mat | 1 | 1 | 1 | 1 | 1 |

W n W_n Wn是针对n-gram的权重。
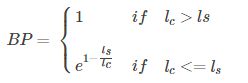
由于candidate预测很短的句子, P n P_n Pn会很高,所以,需要对长度进行惩罚。
1.bleu指标实现
import sys
import codecs
import os
import math
import operator
import json
from functools import reduce
from nltk import bleu
def fetch_data(cand, ref):
"""
将每个reference和candidate存储为一个列表
:param cand: 候选文件名
:param ref: 参考文件名
:return:
"""
references = []
# 如果参考文件名的后缀为'.txt',则将参考文件中每一行添加到references列表中
if '.txt' in ref:
reference_file = codecs.open(ref, 'r', 'utf-8')
references.append(reference_file.readlines())
# 如果参考文件名的后缀不为'.txt',即在一个文件夹下,则先找到文件再添加
else:
# 返回的是一个三元组(root,dirs,files),遍历每一个file
for root, dirs, files in os.walk(ref):
for f in files:
reference_file = codecs.open(os.path.join(root, f), 'r', 'utf-8')
references.append(reference_file.readlines())
# 返回由候选文件中每一行构成的列表
candidate_file = codecs.open(cand, 'r', 'utf-8')
candidate = candidate_file.readlines()
# 返回参考列表和候选列表
return candidate, references
# candidate = [["word peace],['make china great again !']]
# reference [["world war"],['make USA great again']]
def count_ngram(candidate, references, n):
"""
计算n-gram的P_n
:param candidate: 候选列表
:param references: 参考列表
:param n: n-gram
:return:
"""
# 初始化
clipped_count = 0
# 统计候选集中n-gram的数量
count = 0
# 用来记录reference长度
r = 0
# 用来记录 candidates的长度
c = 0
# 遍历每一个CANDIDATES
for si in range(len(candidate)):
# Calculate precision for each sentence
# 统计ref中的每个n-gram 的数目
ref_counts = []
# 统计 REF 的长度,length
ref_lengths = []
# 遍历每一个REFERENCE
# Build dictionary of ngram counts-构建字典统计在references中n-gram的次数
for reference in references:
# 对应的参考集
ref_sentence = reference[si]
# ngram统计
ngram_d = {}
# 将参考集以空格分割
words = ref_sentence.strip().split()
# 记录每一个参考集的单词数
ref_lengths.append(len(words))
# 参考集中有多少组n-gram
limits = len(words) - n + 1 # [1,2,3,4,5,6,7]
# 遍历每组n-gram
for i in range(limits):
# 构造n-gram
ngram = ' '.join(words[i:i + n]).lower()
# ref中n-gram计数
if ngram in ngram_d.keys():
ngram_d[ngram] += 1
else:
ngram_d[ngram] = 1
# 将统计参考集n-gram数目的字典添加到列表中
ref_counts.append(ngram_d)
# 遍历 CANDIDATE
cand_sentence = candidate[si]
# 统计cand中的每个n-gram 的数目
cand_dict = {}
# 将候选集以空格进行分割
words = cand_sentence.strip().split()
# 候选集对应n-gram的数量
limits = len(words) - n + 1
# 遍历n-gram
for i in range(0, limits):
ngram = ' '.join(words[i:i + n]).lower()
# cand中n-gram计数
if ngram in cand_dict:
cand_dict[ngram] += 1
else:
cand_dict[ngram] = 1
# 遍历每一个CANDIDATES,累加Count_clip值
clipped_count += clip_count(cand_dict, ref_counts)
# 统计候选集中n-gram的数量
count += limits
# 计算参考集的句长
r += best_length_match(ref_lengths, len(words))
# 计算候选集的句长
c += len(words)
# 得到P_n
if clipped_count == 0:
pr = 0
else:
pr = float(clipped_count) / count
# 计算BP值
bp = brevity_penalty(c, r)
# 返回BP与P_n
return pr, bp
def clip_count(cand_d, ref_ds):
"""
Count the clip count for each ngram considering all references
:param cand_d: 候选集中n-gram字典
:param ref_ds: 多个参考集中n-gram字典
:return:返回Count_clip值
"""
# 基于Count_clip公式计算
count = 0
for m in cand_d.keys():
# 候选集中某一个n-gram的次数
m_w = cand_d[m]
m_max = 0
for ref in ref_ds:
if m in ref:
m_max = max(m_max, ref[m])
m_w = min(m_w, m_max)
count += m_w
return count
def best_length_match(ref_l, cand_l):
"""
Find the closest length of reference to that of candidate
:param ref_l: 多个参考集的单词数
:param cand_l: 候选集的单词数
:return:返回参考集的句长
"""
# 初始一个差值
least_diff = abs(cand_l - ref_l[0])
best = ref_l[0]
# 遍历每一个参考集的单词数
for ref in ref_l:
# 如果比least_diff小,那么重新赋值
if abs(cand_l - ref) < least_diff:
least_diff = abs(cand_l - ref)
best = ref
return best
def brevity_penalty(c, r):
"""
对长度进行惩罚
:param c: 候选集的句长
:param r: 参考集的句长
:return:
"""
if c > r:
bp = 1
else:
bp = math.exp(1 - (float(r) / c))
return bp
def geometric_mean(precisions):
"""
基于BP与P_n计算bleu
:param precisions: 精确率
:return: 返回bleu
"""
# reduce函数:用传给 reduce 中的函数 function(有两个参数)
# 先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。
# operator.mul
# exp(\sum W_n log(P_n))
return (reduce(operator.mul, precisions)) ** (1.0 / len(precisions))
def BLEU(candidate, references):
"""
计算bleu
:param candidate:候选列表
:param references:参考列表
:return:返回bleu
"""
precisions = []
# 从1-gram遍历到4-gram
for i in range(4):
# 得到P_n,BP
pr, bp = count_ngram(candidate, references, i + 1)
precisions.append(pr)
print('P' + str(i + 1), ' = ', round(pr, 2))
print('BP = ', round(bp, 2))
# 基于BP与P_n计算bleu
bleu = geometric_mean(precisions) * bp
return bleu
if __name__ == "__main__":
# 获取data,返回参考列表和候选列表
# sys.argv是获取运行python文件的时候命令行参数
candidate, references = fetch_data(sys.argv[1], sys.argv[2])
# 计算评价指标bleu
bleu = BLEU(candidate, references)
# 将计算得到的bleu写入'bleu_out.txt'文件中
print('BLEU = ', round(bleu, 4))
out = open('bleu_out.txt', 'w')
out.write(str(bleu))
out.close()
2.nltk中的bleu
from nltk.translate.bleu_score import sentence_bleu
reference = [['this', 'is', 'a', 'test'], ['this', 'is' 'test']]
candidate = ['this', 'is', 'a', 'test']
score = sentence_bleu(reference, candidate)
print(score)
1.0
1.0
三、基于Seq2eq+Attention的机器翻译实战
- 数据
Multi30k
德语转英语的数据,英语与德语是一一对应的
英语
德语A man in an orange hat starring at something. A Boston Terrier is running on lush green grass in front of a white fence. A girl in karate uniform breaking a stick with a front kick. Five people wearing winter jackets and helmets stand in the snow, with snowmobiles in the background. People are fixing the roof of a house. ...Ein Mann mit einem orangefarbenen Hut, der etwas anstarrt. Ein Boston Terrier läuft über saftig-grünes Gras vor einem weißen Zaun. Ein Mädchen in einem Karateanzug bricht ein Brett mit einem Tritt. Fünf Leute in Winterjacken und mit Helmen stehen im Schnee mit Schneemobilen im Hintergrund. Leute Reparieren das Dach eines Hauses. Ein hell gekleideter Mann fotografiert eine Gruppe von Männern in dunklen Anzügen und mit Hüten, die um eine Frau in einem trägerlosen Kleid herum stehen. Eine Gruppe von Menschen steht vor einem Iglu. ...
数据处理部分:utils.py
"""
数据处理部分
"""
import re
import spacy
from torchtext.data import Field, BucketIterator
from torchtext.datasets import Multi30k
# manual create date ( token 2 index , index to token)
# dataset dataloader PADDING BATCH SHUFFLE
# torchtext
# ALLENNLP (Field)
# ["" 3 ,"word"1 ,"peace" 2,"" 4 ]
def load_dataset(batch_size):
# 分别加载英语与德语库,在底层建立词典
# https://spacy.io/models 需要安装de_core_news_sm与en_core_web_sm
spacy_de = spacy.load('de_core_news_sm')
spacy_en = spacy.load('en_core_web_sm')
# 匹配搜索模式
url = re.compile('(.* )')
# 通过tokenizer将词变成id
def tokenize_de(text):
return [tok.text for tok in spacy_de.tokenizer(url.sub('@URL@', text))]
def tokenize_en(text):
return [tok.text for tok in spacy_en.tokenizer(url.sub('@URL@', text))]
# 处理方式
DE = Field(tokenize=tokenize_de, include_lengths=True,
init_token='' , eos_token='' )
EN = Field(tokenize=tokenize_en, include_lengths=True,
init_token='' , eos_token='' )
# 将Multi30k分成训练、验证、测试
train, val, test = Multi30k.splits(exts=('.de', '.en'), fields=(DE, EN))
# 分别建立词表
DE.build_vocab(train.src, min_freq=2)
EN.build_vocab(train.trg, max_size=10000)
# 基于BucketIterator构建iterition,返回与dataloader同样的结果
train_iter, val_iter, test_iter = BucketIterator.splits(
(train, val, test), batch_size=batch_size, repeat=False)
return train_iter, val_iter, test_iter, DE, EN
if __name__ == '__main__':
load_dataset(8)
模型部分代码:model.py
import math
import torch
import random
from torch import nn
from torch.autograd import Variable
import torch.nn.functional as F
class Encoder(nn.Module):
# 参数初始化
def __init__(self, input_size, embed_size, hidden_size,
n_layers=1, dropout=0.5):
super(Encoder, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.embed_size = embed_size
self.embed = nn.Embedding(input_size, embed_size)
# 双向GRU
self.gru = nn.GRU(embed_size, hidden_size, n_layers,
dropout=dropout, bidirectional=True)
def forward(self, src, hidden=None): #A ---> B
embedded = self.embed(src)
# outputs是每一个时间步的hidden state
# hidden是最后一个时间步的hidden state
outputs, hidden = self.gru(embedded, hidden)
# sum bidirectional outputs
outputs = (outputs[:, :, :self.hidden_size] +
outputs[:, :, self.hidden_size:])
return outputs, hidden
class Attention(nn.Module):
def __init__(self, hidden_size):
super(Attention, self).__init__()
self.hidden_size = hidden_size
self.attn = nn.Linear(self.hidden_size * 2, hidden_size)
# 定义一个可求导的向量
self.v = nn.Parameter(torch.rand(hidden_size))
stdv = 1. / math.sqrt(self.v.size(0))
# 初始化self.v
self.v.data.uniform_(-stdv, stdv)
def forward(self, hidden, encoder_outputs):
"""
:param hidden: 最后一个时间步的输出
:param encoder_outputs: 所有时间步的输出
:return:
"""
# 时间步
timestep = encoder_outputs.size(0)
# 连续复制10步
h = hidden.repeat(timestep, 1, 1).transpose(0, 1)
encoder_outputs = encoder_outputs.transpose(0, 1) # [B*T*H]
# 计算权重
attn_energies = self.score(h, encoder_outputs)
return F.softmax(attn_energies, dim=1).unsqueeze(1)
def score(self, hidden, encoder_outputs):
# [B*T*2H]->[B*T*H]
energy = F.relu(self.attn(torch.cat([hidden, encoder_outputs], 2)))
energy = energy.transpose(1, 2) # [B*H*T]
# [B*1*H]
v = self.v.repeat(encoder_outputs.size(0), 1).unsqueeze(1)
# 做矩阵乘法,得到[B*1*T]
energy = torch.bmm(v, energy)
# 得到每一个时间步的权重
return energy.squeeze(1) # [B*T]
class Decoder(nn.Module):
# 参数初始化
def __init__(self, embed_size, hidden_size, output_size,
n_layers=1, dropout=0.2):
super(Decoder, self).__init__()
self.embed_size = embed_size
self.hidden_size = hidden_size
self.output_size = output_size
self.n_layers = n_layers
self.embed = nn.Embedding(output_size, embed_size)
self.dropout = nn.Dropout(dropout, inplace=True)
# attention层
self.attention = Attention(hidden_size)
# 单向GRU
self.gru = nn.GRU(hidden_size + embed_size, hidden_size,
n_layers, dropout=dropout)
# 线性层
self.out = nn.Linear(hidden_size * 2, output_size)
def forward(self, input, last_hidden, encoder_outputs):
# Get the embedding of the current input word (last output word)
embedded = self.embed(input).unsqueeze(0) # (1,B,N)
# dropout
embedded = self.dropout(embedded)
# Calculate attention weights and apply to encoder outputs
attn_weights = self.attention(last_hidden[-1], encoder_outputs)
# 权重与encoder_outputs做加权,得到总的隐状态
context = attn_weights.bmm(encoder_outputs.transpose(0, 1)) # (B,1,N)
context = context.transpose(0, 1) # (1,B,N)
# Combine embedded input word and attended context, run through RNN
rnn_input = torch.cat([embedded, context], 2)
# output是每一个时间步的hidde state
# hidden是最后一个时间步的hidden state
output, hidden = self.gru(rnn_input, last_hidden)
output = output.squeeze(0) # (1,B,N) -> (B,N)
context = context.squeeze(0) # (1,B,N) -> (B,N)
# 经过线性层
output = self.out(torch.cat([output, context], 1))
# log + softmax
output = F.log_softmax(output, dim=1)
return output, hidden, attn_weights
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder):
super(Seq2Seq, self).__init__()
# 编码器
self.encoder = encoder
# 解码器
self.decoder = decoder
def forward(self, src, trg, teacher_forcing_ratio=0.5):
"""
前向传播
:param src:每个batch然后具有src和trg属性
:param trg:
:param teacher_forcing_ratio:
:return:
"""
# batch
batch_size = src.size(1)
# max_len
max_len = trg.size(0)
# vocab_size
vocab_size = self.decoder.output_size
# 初始化输出
outputs = Variable(torch.zeros(max_len, batch_size, vocab_size))
# outputs是每一个时间步的hidde state
# hidden是最后一个时间步的hidden state
encoder_output, hidden = self.encoder(src)
# 利用hidden states
hidden = hidden[:self.decoder.n_layers]
# 输出
output = Variable(trg.data[0, :]) # sos
# 迭代
for t in range(1, max_len):
# 解码层
# 当前的hidden state用于产生下一步的hidden state
output, hidden, attn_weights = self.decoder(
output, hidden, encoder_output)
# 记录输出
outputs[t] = output
# teacher forcing
is_teacher = random.random() < teacher_forcing_ratio
# 预测
top1 = output.data.max(1)[1]
# 基于is_teacher确定输出
output = Variable(trg.data[t] if is_teacher else top1)
return outputs
模型训练与评估:train.py
import os
import math
import argparse
import torch
from torch import optim
from torch.autograd import Variable
from torch.nn.utils import clip_grad_norm
from torch.nn import functional as F
from model import Encoder, Decoder, Seq2Seq
from utils import load_dataset
def parse_arguments():
"""
统一配置参数管理,在命令行运行这些文件并输入对应参数,文件即可运行
"""
p = argparse.ArgumentParser(description='Hyperparams')
p.add_argument('-epochs', type=int, default=100,
help='number of epochs for train')
p.add_argument('-batch_size', type=int, default=32,
help='number of epochs for train')
p.add_argument('-lr', type=float, default=0.0001,
help='initial learning rate')
p.add_argument('-grad_clip', type=float, default=10.0,
help='in case of gradient explosion')
# p.add_argument('-hidden_size',type=int,default=10,help=" the size of hidden tensor")
return p.parse_args()
def evaluate(model, val_iter, vocab_size, DE, EN):
# 模式为测试模式
model.eval()
# 得到英文字典中''对应的值
pad = EN.vocab.stoi['' ]
total_loss = 0
# 遍历每一个batch
for b, batch in enumerate(val_iter):
# src是处理后的英文输入
# trg是处理后的德语结果
src, len_src = batch.src
trg, len_trg = batch.trg
src = Variable(src.data, volatile=True)
trg = Variable(trg.data, volatile=True)
# 前向传播
output = model(src, trg, teacher_forcing_ratio=0.0)
# 交叉熵损失
loss = F.nll_loss(output[1:].view(-1, vocab_size),
trg[1:].contiguous().view(-1),
ignore_index=pad)
# 损失累加
total_loss += loss.data.item()
return total_loss / len(val_iter)
def train(e, model, optimizer, train_iter, vocab_size, grad_clip, DE, EN):
# 训练模式,模型权重更新
model.train()
total_loss = 0
# 得到英文字典中''对应的值
pad = EN.vocab.stoi['' ]
# 遍历每一个batch
for b, batch in enumerate(train_iter):
# src是处理后的英文输入
# trg是处理后的德语结果
src, len_src = batch.src
trg, len_trg = batch.trg
src, trg = src, trg
# 梯度清零
optimizer.zero_grad()
# 前向传播
output = model(src, trg)
# 交叉熵损失函数
loss = F.nll_loss(output[1:].view(-1, vocab_size),
trg[1:].contiguous().view(-1),
ignore_index=pad)
# 反向传播
loss.backward()
# 梯度截断
clip_grad_norm(model.parameters(), grad_clip)
# 梯度更新
optimizer.step()
# loss累加
total_loss += loss.data.item()
if b % 100 == 0 and b != 0:
total_loss = total_loss / 100
print("[%d][loss:%5.2f][pp:%5.2f]" %
(b, total_loss, math.exp(total_loss)))
total_loss = 0
def main():
# 统一配置参数
args = parse_arguments()
hidden_size = 512
embed_size = 256
# assert torch.cuda.is_available()
print("[!] preparing dataset...")
# 得到训练、验证、预测用的iterations
train_iter, val_iter, test_iter, DE, EN = load_dataset(args.batch_size)
# 词表长度
de_size, en_size = len(DE.vocab), len(EN.vocab)
print("[TRAIN]:%d (dataset:%d)\t[TEST]:%d (dataset:%d)"
% (len(train_iter), len(train_iter.dataset),
len(test_iter), len(test_iter.dataset)))
print("[DE_vocab]:%d [en_vocab]:%d" % (de_size, en_size))
print("[!] Instantiating models...")
# 初始化编码
encoder = Encoder(de_size, embed_size, hidden_size,
n_layers=2, dropout=0.5)
# 初始化解码
decoder = Decoder(embed_size, hidden_size, en_size,
n_layers=1, dropout=0.5)
# 初始化 seq2seq
seq2seq = Seq2Seq(encoder, decoder)
# 优化器
optimizer = optim.Adam(seq2seq.parameters(), lr=args.lr)
print(seq2seq)
best_val_loss = None
# 遍历每一个epoch
for e in range(1, args.epochs+1):
# 训练
train(e, seq2seq, optimizer, train_iter,
en_size, args.grad_clip, DE, EN)
# 验证
val_loss = evaluate(seq2seq, val_iter, en_size, DE, EN)
print("[Epoch:%d] val_loss:%5.3f | val_pp:%5.2fS"
% (e, val_loss, math.exp(val_loss)))
# Save the model if the validation loss is the best we've seen so far.
if not best_val_loss or val_loss < best_val_loss:
print("[!] saving model...")
if not os.path.isdir(".save"):
os.makedirs(".save")
torch.save(seq2seq.state_dict(), './.save/seq2seq_%d.pt' % (e))
best_val_loss = val_loss
# 预测
test_loss = evaluate(seq2seq, test_iter, en_size, DE, EN)
print("[TEST] loss:%5.2f" % test_loss)
if __name__ == "__main__":
try:
main()
except KeyboardInterrupt as e:
print("[STOP]", e)
模型结构为:
Seq2Seq(
(encoder): Encoder(
(embed): Embedding(8014, 256)
(gru): GRU(256, 512, num_layers=2, dropout=0.5, bidirectional=True)
)
(decoder): Decoder(
(embed): Embedding(10004, 256)
(dropout): Dropout(p=0.5, inplace=True)
(attention): Attention(
(attn): Linear(in_features=1024, out_features=512, bias=True)
)
(gru): GRU(768, 512, dropout=0.5)
(out): Linear(in_features=1024, out_features=10004, bias=True)
)
)
如果对您有帮助,麻烦点赞关注,这真的对我很重要!!!如果需要互关,请评论或者私信!
