前言
事情是这样的,一位读者看了我的一篇文章,不认同我文章里面的观点,于是有了下面的交流。
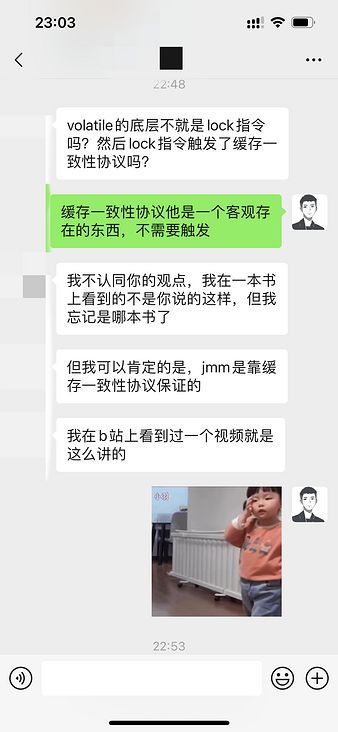
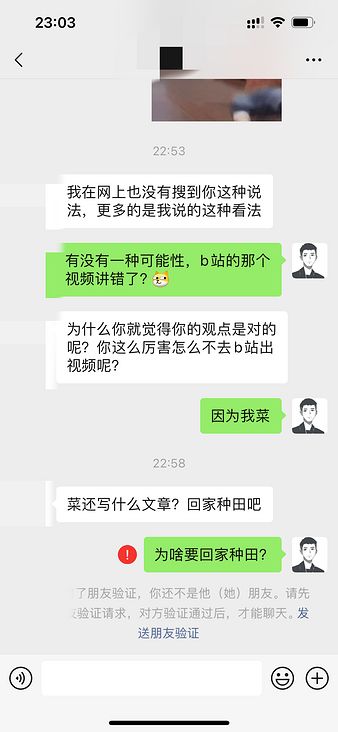
可能是我发的那个狗头的表情,让这位读者认为我不尊重他。于是,这位读者一气之下把我删掉了,在删好友之前,还叫我回家种田。

说实话,你说我菜我是承认的,但你要我回家种田,我不理解。为什么要回家种田呢?养猪不比种田赚钱吗?
我想了很久没有想明白,突然,我看到了这个新闻,瞬间明白了读者的用心良苦。

于是,我决定写下这篇文章,好好地分析一下读者提出的几个问题。
读者的观点
针对这位读者的几个观点:
- volatile 关键字的底层实现就是 lock 指令
- lock 指令触发了缓存一致性协议
- JMM 靠缓存一致性协议保证
我先给出我的看法:
- 第一点我认为是对的,这个我在 volatile 那篇文章也说过,volatile 的底层实现就是 lock 前缀指令
- 第二点我认为是错的
- 第三点我认为是错的
至于为什么我会这么认为,我会说出我的理由,毕竟,我们都是是讲道理的人,对不对?

读者的观点围绕“缓存一致性协议”,OK,那我们就从缓存一致性协议讲起!
从字面意思来看,缓存一致性协议就是“用来解决 CPU 的缓存不一致问题的协议”。将这句话拆开,就会有几个问题:
- 为什么 CPU 运行过程中需要缓存呢?
- 为什么缓存会出现不一致呢?
- 有哪些方法去解决缓存不一致的问题呢?
我们一一分析。
为什么需要缓存
CPU 是个运算器,主要负责运算;
内存是个存储介质,负责存储数据和指令;
在没有缓存的年代,CPU 和内存是这样配合工作的:
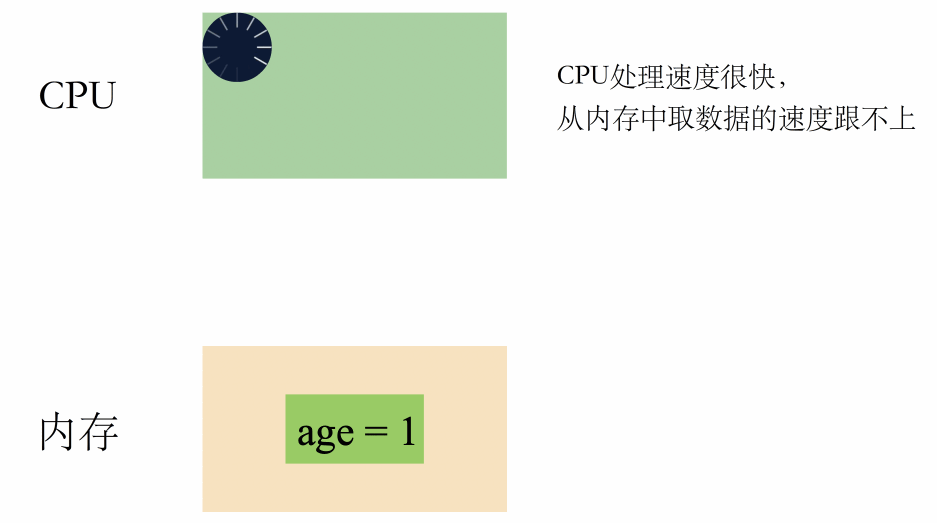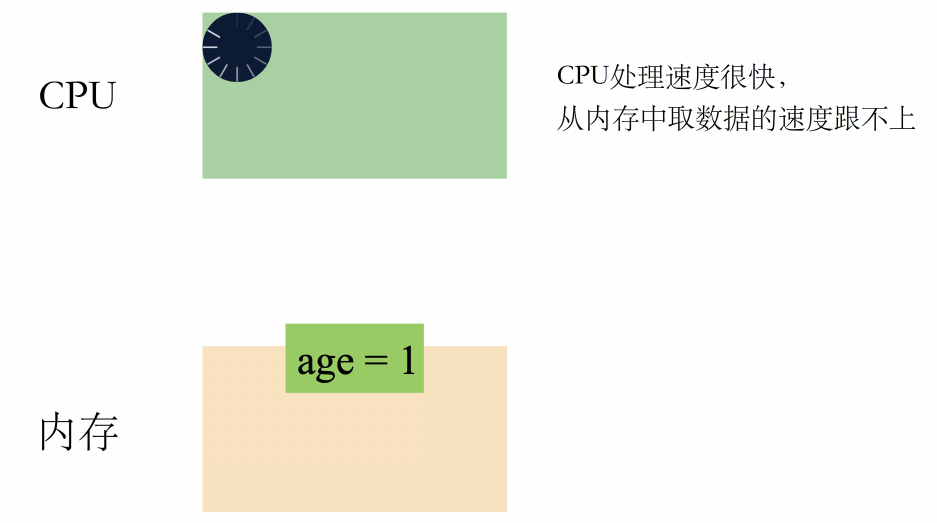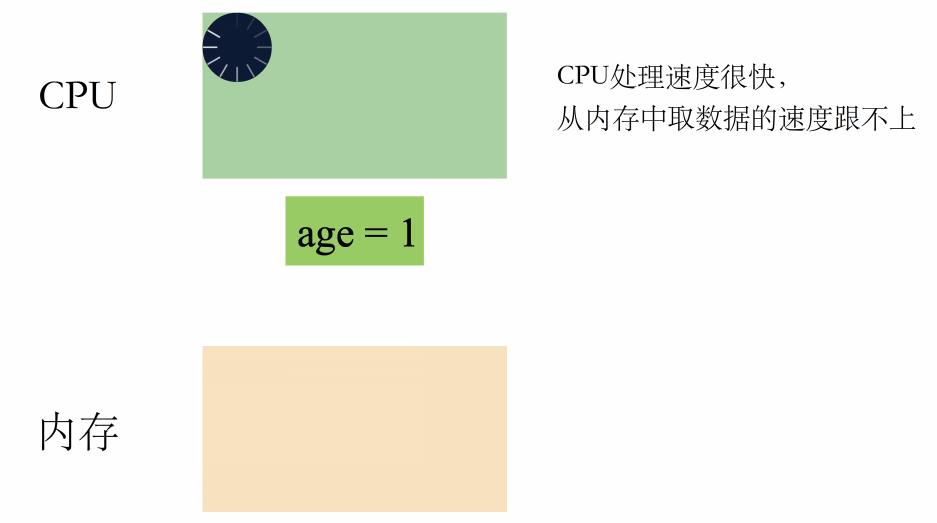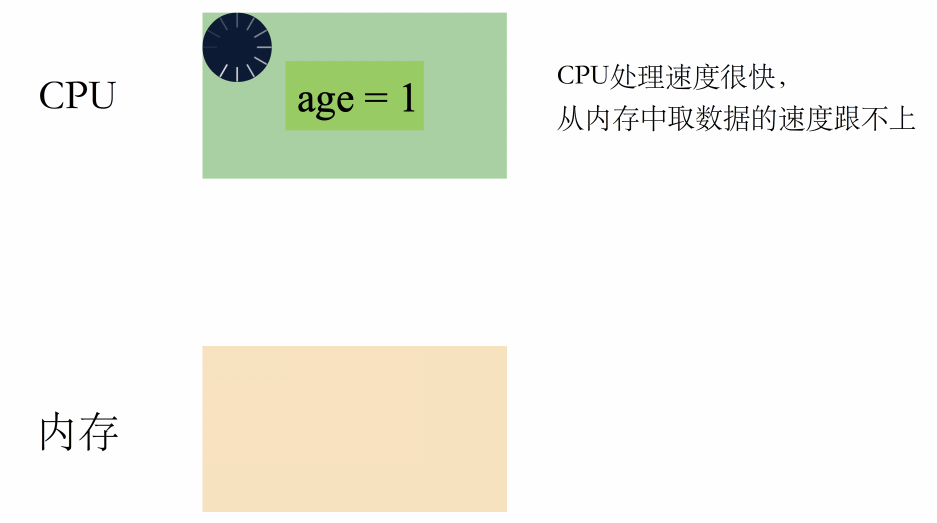
一句话总结就是:CPU 高速运转,但取数据的速度非常慢,严重浪费了 CPU 的性能。
那怎么办呢?
在工程学上,解决速度不匹配的方式主要有两种,分别是物理适配和空间缓冲。
物理适配很容易理解,多级机械齿轮就是物理适配的典型例子。

至于空间缓冲,更多的被运用在软硬件上,CPU 多级缓存就是经典的代表。
什么是 CPU 多级缓存?
简单来说就是基于 时间 = 距离 / 速度 这个公式,通过在 CPU 和内存之间设置多层缓存来减少取数据的距离,让 CPU 和内存的速度能够更好的适配。
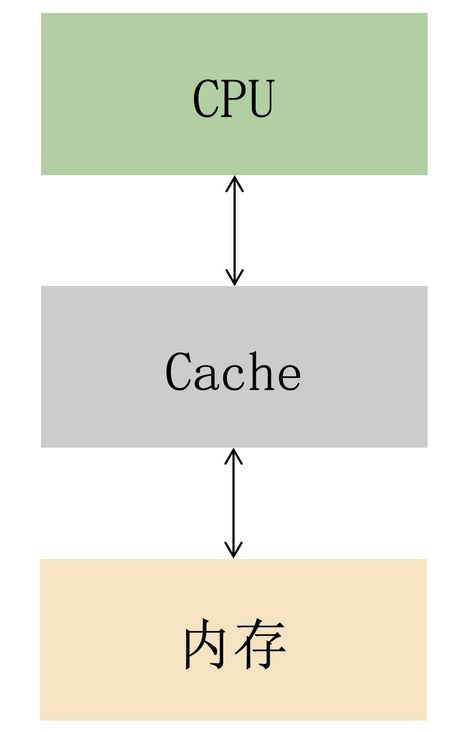
因为缓存离 CPU 近,而且结构更加合理,CPU 取数据的速度就缩短了,从而提高了 CPU 的利用率。
同时,因为 CPU 取数据和指令满足时间局部性和空间局部性,有了缓存之后,对同一数据进行多次操作时,中间过程可以用缓存暂存数据,进一步分摊时间 = 距离 / 速度 中的距离,更好地提高了 CPU 利用率。
时间局部性:如果一个信息项正在被访问,那么在近期它很可能还会被再次访问
空间局部性:如果一个存储器的位置被引用,那么将来他附近的位置也会被引用
缓存为什么会不一致
缓存的出现让 CPU 的利用率得到了大幅地提高。
在单核时代,CPU 既享受到了缓存带来的便利,又不用担心数据会出现不一致。但这一切的前提建立在“单核”。
多核时代的到来打破了这种平衡。
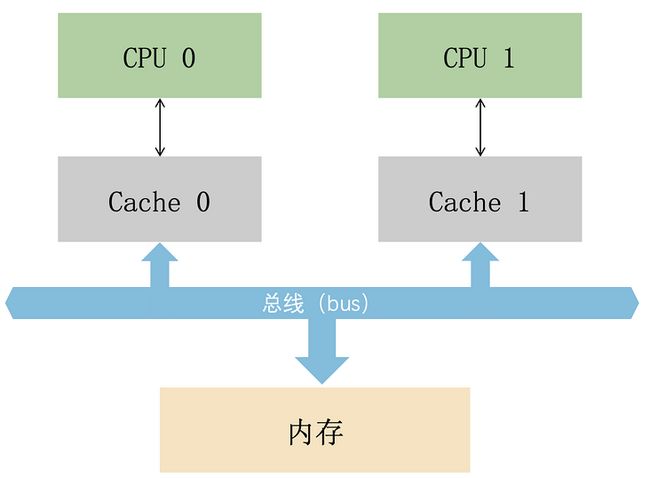
进入多核时候之后,需要面临的第一个问题就是:多个 CPU 是共享一组缓存还是各自拥有一组缓存呢?
答案是“各自拥有一组缓存”。
为什么呢?
我们不妨做个假设,假设多个 CPU 共享一组缓存,会出现什么情况呢?
如果共享一组缓存,由于低级缓存(离 CPU 近的缓存)的空间非常小,多个 CPU 的时间会都花在等待使用低级缓存上面,这意味着多个 CPU 变成了串行工作,如果变成串行,那就失去了多核的本质意义——并行。
我们用反证证明了多个 CPU 共享一组缓存是行不通的,所以只能让多个 CPU 各自拥有一组私有缓存。
于是,多个 CPU 的缓存结构就成了这样(简化了多级缓存):
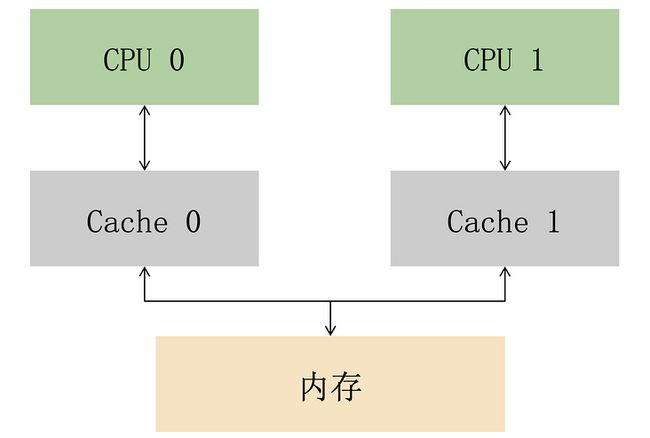
这样的设计虽然解决了多个处理器抢占缓存的问题,但也带来了一个新的问题,那就是令人头疼的数据一致性问题:
具体来说,就是如果多个 CPU 同时用到某份数据,由于多组缓存的存在,数据可能会出现不一致。
我们可以看下面这个例子:
- 假设内存里面存着 age=1
- CPU0 执行 age+1 操作
- CPU1 也执行 age+1 操作
如果有多组缓存,在并发场景下,可能会出现如下情况:
可以看到,两个 CPU 同时对 age=1 进行加一操作,因为多组缓存的原因,CPU 之间无法感知对方的修改,数据出现了不一致,导致最后的结果不是预期的值。
没有缓存也会出现数据一致性问题,只是有缓存会变得尤其严重。
数据不一致的问题对于程序来说是致命的。所以需要有一种协议,能够让多组缓存看起来就像只有一组缓存那样。
于是,缓存一致性协议就诞生了。
缓存一致性协议
缓存一致性协议就是为了解决缓存一致性问题而诞生,它旨在通过维护多个缓存空间中缓存行的一致视图来管理数据一致性。
这里先补充一下缓存行的概念:
缓存行(cache line)是缓存读取的最小单元,缓存行是 2 的整数幂个连续字节,一般为 32-256 个字节,最常见的缓存行大小是 64 个字节。
Linux 系统可以通过cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size命令查看缓存行大小。
Mac 系统可以通过sysctl hw.cachelinesize查看缓存行的大小。

缓存行也是缓存一致性协议管理的最小单位。
实现缓存一致性协议的机制主要有两种,分别是基于目录和总线嗅探。
基于目录
什么是基于目录?
说直白一点就是用一个目录去记录缓存行的使用情况,然后 CPU 要使用某个缓存行的时候,先通过查目录获取此缓存行的使用情况,用这样的方式保证数据一致性。
目录的格式有六种:
- 全位向量格式(Full bit vector format)
- 粗位向量格式(Coarse bit vector format)
- 稀疏目录格式(Sparse directory format)
- 数字平衡二叉树格式(Number-balanced binary tree format)
- 链式目录格式(Chained directory format)
- 有限的指针格式(Limited pointer format)
这些目录的名字花里胡哨的,实际上并没有那么复杂,只是数据结构和优化方式不一样罢了。
比如全位向量格式就是用比特位(bit)去记录每个缓存行是否被某个 CPU 缓存。
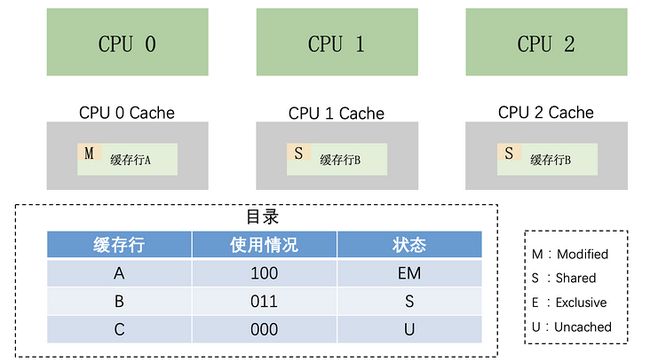
后面几种格式的目录,无非是在存储和可扩展等方面做了一些优化。
记目录相对于直接消息通信来说是比较耗时的,所以基于目录这种机制实现的缓存一致性协议延迟相对来说会偏高。但也有一个好处,第三方目录的存在让通信过程变得简单,通信对总线带宽的占用也会相对偏少。
所以,基于目录适用于 CPU 核心数量多的大型系统。
总线嗅探
基于目录依赖实现的缓存一致性协议虽然带宽占用小,但是延迟高,并不适合作为小型的系统的缓存一致性解决方案,小型系统更多的是用基于总线嗅探的缓存一致性协议。
总线是 CPU 和内存地址和数据交互的桥梁,总线嗅探也就是监听着这座交互桥梁,及时的感知数据的变化。
当 CPU 修改私有缓存里面的数据时,会给总线发送一个事件消息,告诉总线上的其他监听者这个数据被修改了。
其他 CPU 感知到自己私有的缓存中存在某个被修改的数据副本时,可以将缓存的副本更新,也可以让缓存的副本失效。
将缓存的副本更新会产生巨大的总线流量,影响系统的正常运行。所以,在监听到更新事件时,更多的是将私有的缓存副本失效处理,也就是丢弃这个数据副本。
将被修改的数据副本失效的这种方式,有个专业的术语,叫做“写无效”(Write-invalidate),基于“写无效”实现的缓存一致性协议,叫做“写无效”协议,常见的 MSI、MESI、MOSI、MOESI 和 MESIF 协议都属于这一类。
MESI
MESI 协议是一个基于失效的缓存一致性协议,是支持写回(write-back)缓存的最常用协议,也是现在一种使用最广泛的缓存一致性协议,它基于总线嗅探实现,用额外的两位给每个缓存行标记状态,并且维护状态的切换,达到缓存一致性的目的。
MESI 状态
MESI 是四个单词的缩写,每个单词分别代表缓存行的一个状态:
- M:modified,已修改。缓存行与主存的值不同。如果别的 CPU 内核要读主存这块数据,该缓存行必须回写到主存,状态变为共享状态(S)。
- E:exclusive,独占的。缓存行只在当前缓存中,但和主存数据一致。当别的缓存读取它时,状态变为共享;当前写数据时,变为已修改状态(M)。
- S:shared,共享的。缓存行也存在于其它缓存中且是干净的。缓存行可以在任意时刻抛弃。
- I:invalid,无效的。缓存行是无效的。
MESI 消息
MESI 协议中,缓存行状态的切换依赖消息的传递,MESI 有以下几种消息:
- Read: 读取某个地址的数据。
- Read Response: Read 消息的响应。
- Invalidate: 请求其他 CPU invalid 地址对应的缓存行。
- Invalidate Acknowledge: Invalidate 消息的响应。
- Read Invalidate: Read + Invalidate 消息的组合消息。
- Writeback: 该消息包含要回写到内存的地址和数据。
MESI 通过消息的传递维护了一个缓存状态机,实现共享内存,至于细节是怎么样的,这里不做过多表述。
如果你对 MESI 不了解的话,我建议你去这个网站动手实验,可以模拟各种场景,能实时生成动画,比较好理解。
如果你打不开这个网站,不用着急,源代码给你扒下来了,回复“MESI”自取,解压在本地运行就行了。

下面就用这个网站演示一个简单的例子:
- CPU0 读取 a0
- CPU1 写 a0
简单分析一下:
- CPU0 读取 a0,读到 Cache0 之后,因为独占,所以缓存行的状态是 E。
- CPU2 写 a0,先把 a0 读到 Cache2,因为共享,所以状态是 S。然后修改 a0 的值,缓存行的状态变成了 E,最后通知 CPU0 ,将 a0 所在的缓存行失效。
MESI 的存在保证了缓存一致性,让多核 CPU 能够更好地进行数据交互,那是否意味着 CPU 是否被压榨到极致了呢?
答案是否定的,我们接着往下看。
文章的后半段依赖前文的知识点,如果我的表述没让你理解前半段的知识点,你可以直接翻到总结部分,那里有我准备好的思路总结。
如果你准备好了,我们继续开车,看看还能怎么压榨 CPU。

Store Buffer
从上文得知:如果 CPU 对某个数据进行写操作,且这个数据不在私有缓存里,那么 CPU 就会发送一个 Read Invalidate 消息去读取对应的数据,并让其他的缓存副本失效。
但有一个问题你思考了没有,那就是从发送消息之后,到接收到所有的响应消息,中间等待过程对于 CPU 来说是漫长的。
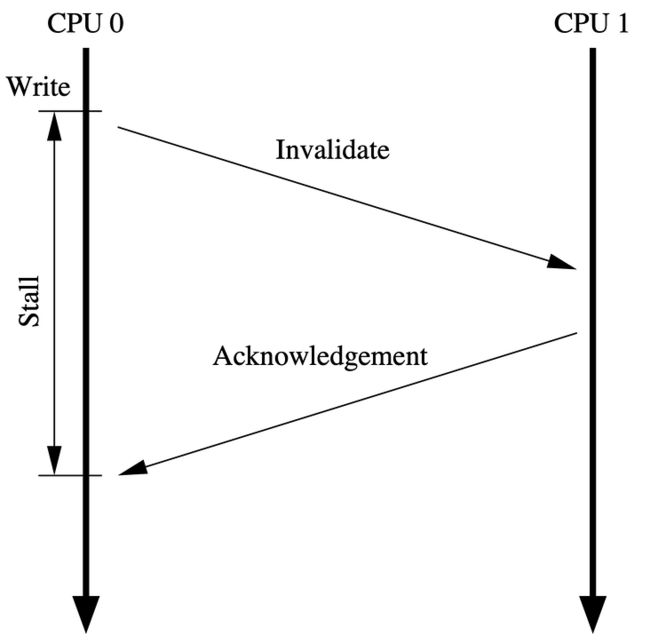
能不能减少 CPU 等待消息的时间呢?
能!store buffer 就是干这个的。
具体怎么干的呢?
store buffer 是 CPU 和缓存中间的一块结构
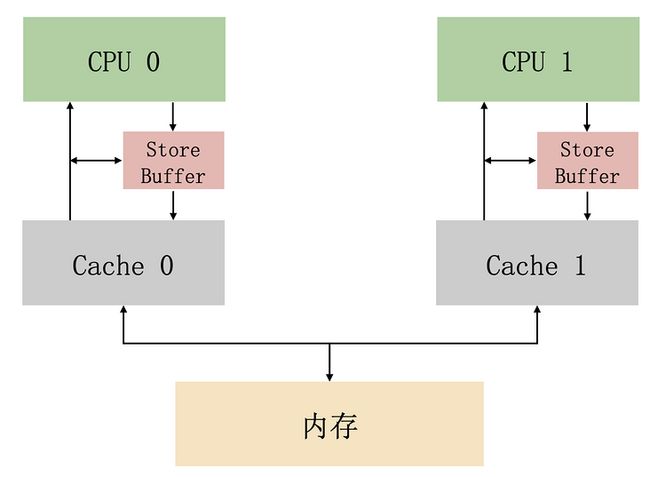
CPU 在写操作时,可以不等待其他 CPU 响应消息就直接写到 store buffer,后续收到响应消息之后,再把 store buffer 里面的数据写入缓存行。
CPU 读数据的时候,也会先判断一下 store buffer 里面有没有数据,如果存在,就优先使用 store buffer 里面的数据(这个机制,叫做“store forwarding”)。
从而提高了 CPU 的利用率,也能保证了在同一CPU,读写都能顺序执行。
注意,这里的读写顺序执行说的是同一CPU,为什么要强调同一呢?
因为,store buffer 的引入并不能保证多 CPU 全局顺序执行。
我们看下面这个例子:
// CPU0 执行
void foo() {
a = 1;
b = 1;
}
// CPU1 执行
void bar() {
while(b == 0) continue;
assert(a == 1);
}假设 CPU0 执行 foo 方法,CPU1 执行 bar 方法,如果在执行之前,缓存的情况是这样的:
- CPU0 缓存了 b,因为独占,所以状态是 E。
- CPU1 缓存了 a,因为独占,所以状态是 E。
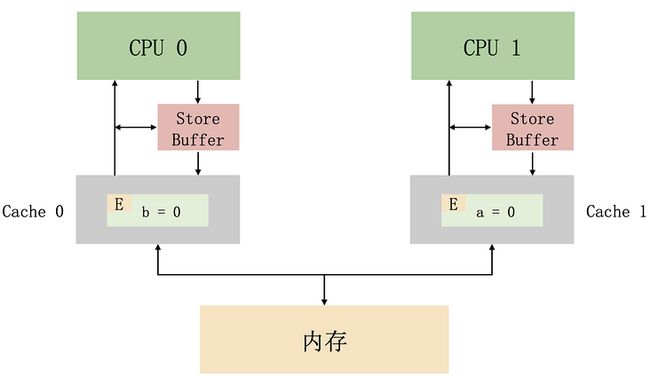
那么,在有了 store buffer 之后,有可能出现这种情况(简化了与内存交互的过程):
用文字表述就是:
- CPU0 执行 a=1,因为 a 不在 CPU0 的缓存中,有 store buffer 的存在,直接写将 a=1 写到 store buffer,同时发送一个 read invalidate 消息。
- CPU1 执行 while(b==1),因为 b 不在 CPU1 的缓存中,所以 CPU1 发送一个 read 消息去读。
- CPU0 收到 CPU1 的 read 消息,知道 CPU1 想要读 b,于是返回一个 read response 消息,同时将对应缓存行的状态改成 S。
- CPU1 收到 read response 消息,知道 b=1,于是将 b=1 放到缓存,同时结束 while 循环。
- CPU1 执行 assert(a==1),从缓存中拿到 a=0,执行失败。
我们站在不同的角度分析分析:
- 站在 CPU0 的角度看自己:a = 1 先于 b = 1,所以 b = 1 的时候 a 一定已经等于 1 了。
- 站在 CPU0 的角度看 CPU1:因为 b = 1 的时候 a 一定等于 1,所以 CPU1 因为 b == 1 跳出循环的时候,接下来执行 assert 一定为成功,但是实际上失败了,也就是说站在 CPU0 的角度,CPU1 发生了重排序。
那如何解决 store buffer 的引入带来的全局顺序性问题呢?
硬件设计师给开发者提供了内存屏障(memory-barrier)指令,我们只需要使用内存屏障将代码改造一下,在 a = 1 后面加上 smp_mb(),就能消除 store buffer 的引入带来的影响。
// CPU0 执行
void foo() {
a = 1;
smp_mb();
b = 1;
}
// CPU1 执行
void bar() {
while(b == 0) continue;
assert(a == 1);
}内存屏障是如何做到全局顺序性的呢?
有两种方式,分别是等 store buffer 生效和进 store buffer 排队。
等 store buffer 生效
等 store buffer 生效就是内存屏障后续的写必须等待 store buffer 里面的值都收到了对应的响应消息,都被写到缓存行里面。
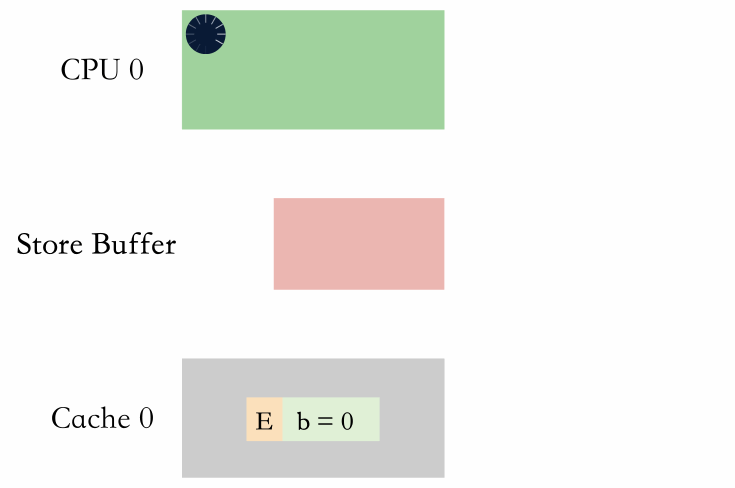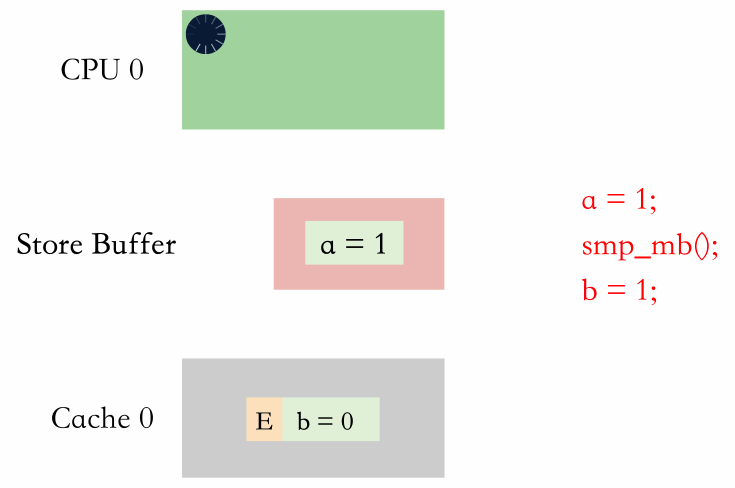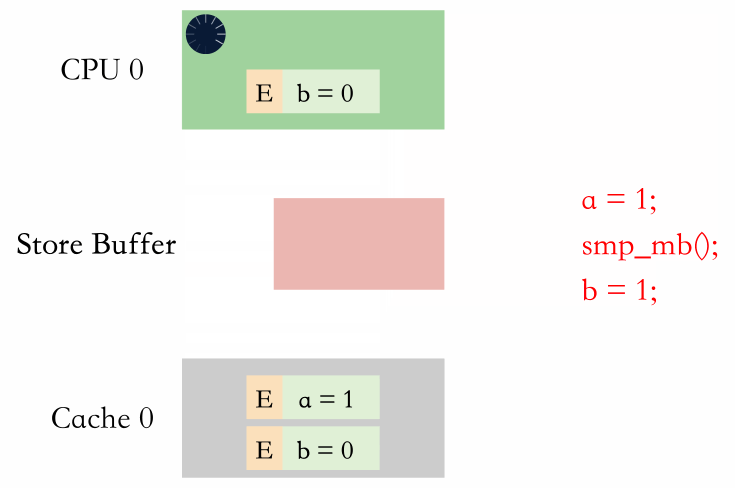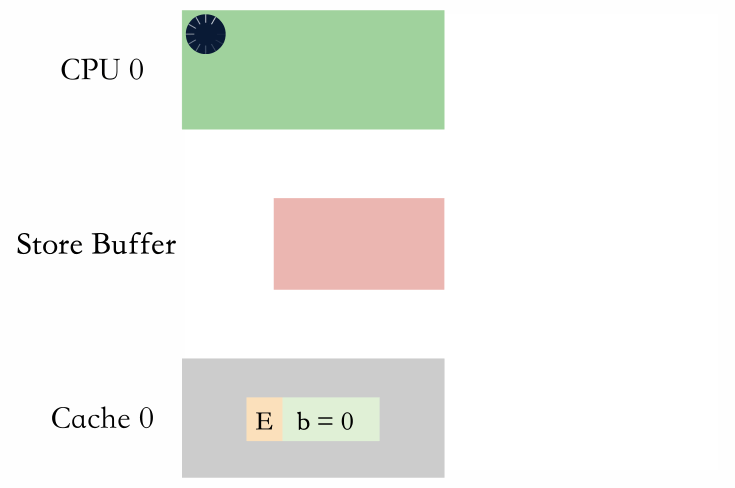
进 store buffer 排队
进 store buffer 排队就是内存屏障后续的写直接写到 store buffer 排队,等 store buffer 前面的写全部被写到缓存行。
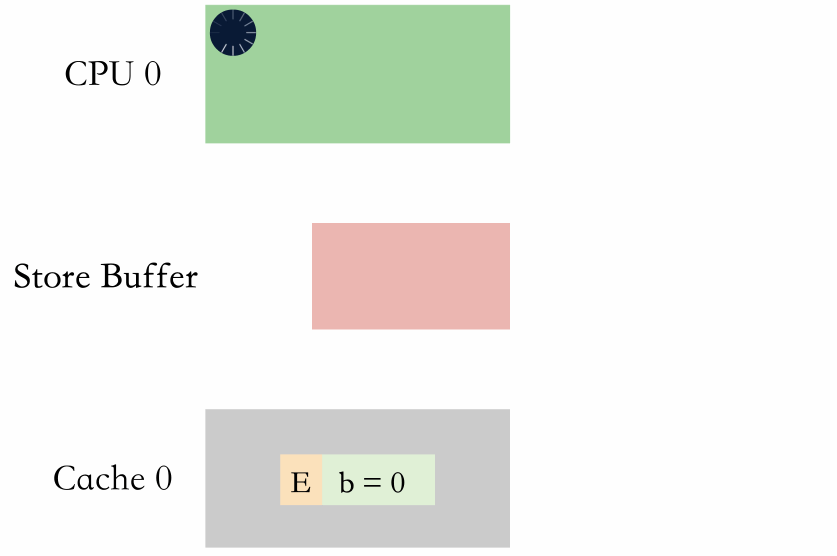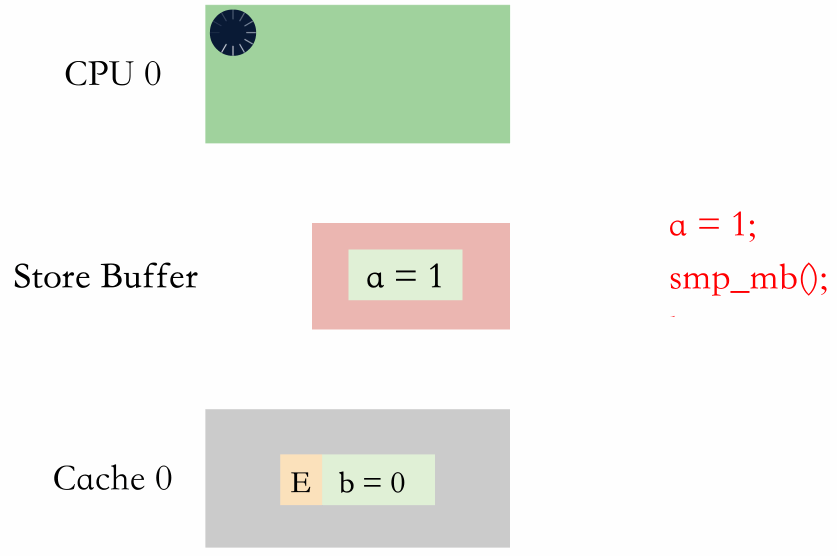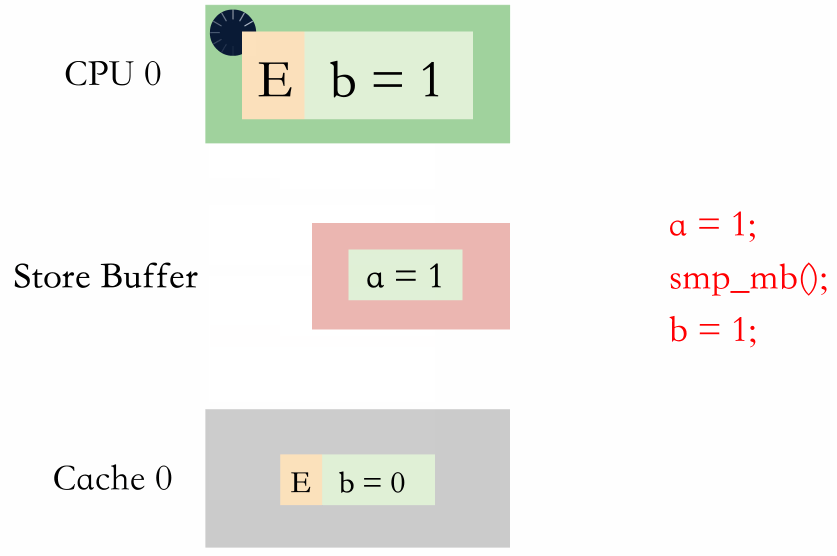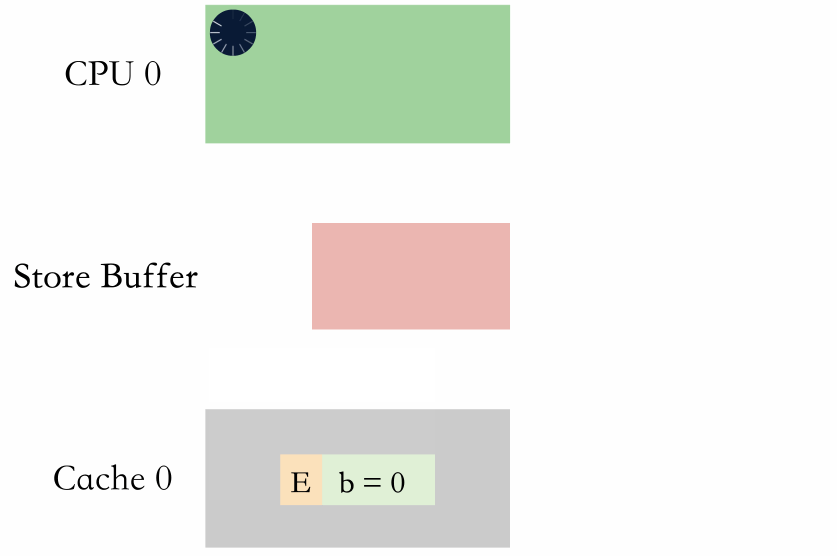
从动图上可以看出,两种方式都需要等,但是等 store buffer 生效是在 CPU 等,而进 store buffer 排队是进 store buffer 等。
所以,进 store buffer 排队也会相对高效一些,大多数的系统采用的也是这种方式。
Invalidate Queue
内存屏障能解决 store buffer 带来的全局顺序性问题。但有一个问题,store buffer 容量非常小,如果在其他 CPU 繁忙的时候响应消息的速度变慢,store buffer 会很容易地被填满,会直接的影响 CPU 的运行效率。
怎么办呢?
这个问题的根源是响应消息慢导致 store buffer 被填满,那能不能提高消息响应速度呢?
能!invalidate queue 出现了。
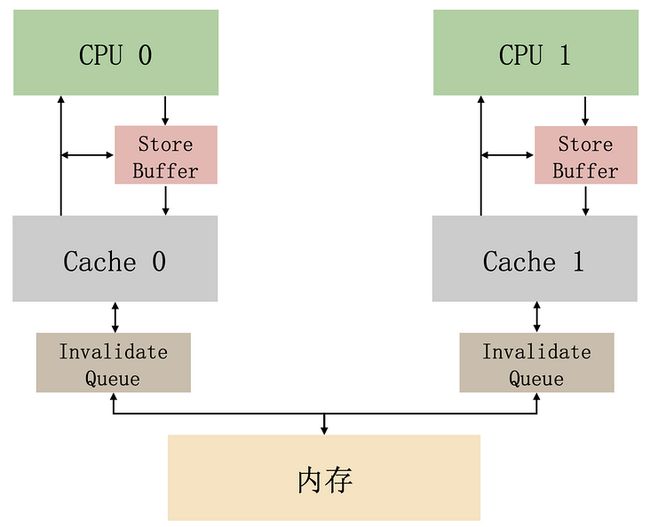
invalidate queue 的主要作用就是提高 invalidate 消息的响应速度。
有了 invalidate queue 之后,CPU 在收到 invalidate 消息时,可以先不讲对应的缓存行失效,而是将消息放入 invalidate queue,立即返回 Invalidate Acknowledge 消息,然后在要对外发送 invalidate 消息时,先检查 invalidate queue 中有无该缓存行的 Invalidate 消息,如果有的话这个时候才处理 Invalidate 消息。
invalidate queue 虽然能加快 invalidate 消息的响应速度,但是也带了全局顺序性问题,这个和 store buffer 带来的全局性问题类似。
看下面这个例子:
// CPU0 执行
void foo() {
a = 1;
smp_mb();
b = 1;
}
// CPU1 执行
void bar() {
while(b == 0) continue;
assert(a == 1);
}上面这段代码,还是假设 CPU0 执行 foo 方法,CPU1 执行 bar 方法,如果在执行之前,缓存的情况是这样的:
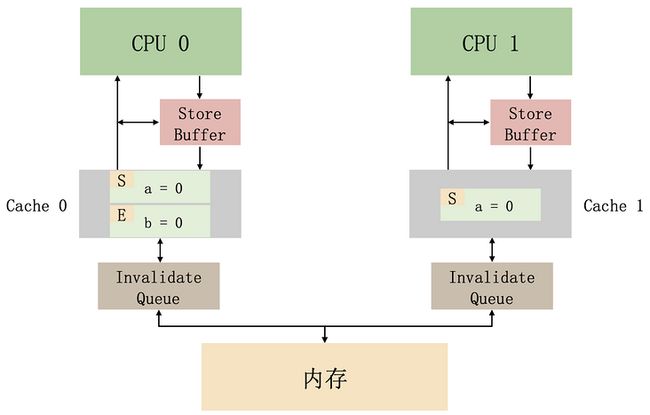
那么,在有了 invalidate queue 之后,有可能出现这种执行情况:
- CPU0 执行 a=1。对应的缓存行在 cpu0 的缓存中是只读的,所以 cpu0 把新值 a=1 放在了它的 store buffer 中,并发送了一个 invalidate 消息,以便从 cpu1 的 cache 中刷新对应的缓存行。
- 当(b==0)继续执行时,CPU1 执行,但是包含 b 的缓存行不在它的缓存中。因此,它发送一个 read 消息。
- CPU0 执行 b=1。因为已经缓存了这个缓存行,所以直接更新缓存行,将 b=0 更新成 b=1。
- CPU0 接收到 read 消息,并将包含 b 的缓存行发送给 CPU1,同时 b 所在缓存行的状态改成 S。
- CPU1 接收到 a 的 invalidate 消息,将其放入自己的 invalidate 队列,并向 CPU0 发送一个 invalidate 确认消息。注意,原来的值“a”仍然保存在 CPU1 的缓存中。
- CPU1 接收到包含 b 的缓存行,并将其写到它的缓存中。
- CPU1 现在可以在(b==0)继续时完成执行,因为它发现 b 的值是 1,它继续执行下一条语句。
- CPU1 执行 assert(a==1),由于原来的值 a 仍然在 CPU1 的缓存中,所以断言失败了。
- cpu1 处理队列中 invalidate 的消息,并从自己的 cache 中使包含 a 的 cache 行失效。但是已经太迟了。
从这个例子可以看出,在引入 invalidate queue 之后,全局顺序性又得不到保障了。
怎么解决呢,和 store buffer 的解决办法是一样的,用内存屏障改造代码:
// CPU0 执行
void foo() {
a = 1;
smp_mb();
b = 1;
}
// CPU1 执行
void bar() {
while(b == 0) continue;
smp_mb();
assert(a == 1);
}改造之后的运行过程不做过多表述,但总结来说就是内存屏障可以解决 invalidate queue 带来的全局顺序性问题。
内存屏障和 Lock 指令
内存屏障
从上文得知,内存屏障有两个作用,处理 store buffer 和 invalidate queue,保持全局顺序性。
但很多情况下,只需要处理 store buffer 和 invalidate queue 中的其中一个即可,所以很多系统将内存屏障细分成了读屏障(read memory barrier)和写屏障(write memory barrier)。
读屏障用于处理 invalidate queue,写屏障用于处理 store buffer。
以场景的 X86 架构下,不同的内存屏障对应的指令分别是:
- 读屏障:lfence
- 写屏障:sfence
- 读写屏障:mfence
Lock 指令
我们再回顾一下,在上一篇讲 volatile 的文章中,我提到了 volatile 关键字的底层实现是 lock 前缀指令。
lock 前缀指令和内存屏障到底有什么关系呢?
我认为是没有什么关系的。
只不过 lock 前缀指令一部分功能能达到内存屏障的效果罢了。
这一点在《IA-32 架构软件开发人员手册》上也能找到对应的描述。
![]()
手册上给 lock 前缀指令的定义是总线锁,也就是 lock 前缀指令是通过锁住总线保证可见性和禁止指令重排序的。
虽然“总线锁”的说法过于老旧了,现在的系统更多的是“锁缓存行”。但我想表达的是,lock 前缀指令的核心思想还是“锁”,这和内存屏障有着本质的区别。
回顾问题
我们再来回顾读者的这两个观点:
- 读者:lock 指令触发了缓存一致性协议
- 读者:JMM 靠缓存一致性协议保证
对于第一个观点,我的看法是:
lock 前缀指令的作用是锁住缓存行,能起到和读写屏障一样的效果,而读写屏障解决的问题是 store buffer 和 invalidate queue 带来的全局顺序性问题。
缓存性一致性问题是用来解决多核系统下的缓存一致性问题,是由硬件来保证的,对软件来说是透明的,伴生于多核系统,是一个客观存在的东西,并不需要触发。
对于第二个观点,我的看法是:
JMM 是一个虚拟的内存模型,它抽象了 JVM 的运行机制,让 Java 开发人员能更好的理解 JVM 的运行机制,它封装了 CPU 底层的实现,让 Java 的开发人员可以更好的进行开发,不被底层的实现细节折磨。
JMM 想表达的是,在某种程度上,你可以通过一些 Java 关键字让 Java 的内存模型达到一种强一致性。
所以 JMM 和缓存一致性协议并不挂钩,本质上就没什么联系。举个例子,你不能因为你单身,然后刘亦菲也单身,你就说刘亦菲单身是因为在等你。
总结
本文对一些没有基础的同学来说,理解起来会稍微吃力一点,所以我们总结一下全文的一个思路,应付应付普通面试是没什么问题的。
- 因为内存的速度和 CPU 匹配不上,所以在内存和 CPU 之间加了多级缓存。
- 单核 CPU 独享不会出现数据不一致的问题,但是多核情况下会有缓存一致性问题。
- 缓存一致性协议就是为了解决多组缓存导致的缓存一致性问题。
- 缓存一致性协议有两种实现方式,一个是基于目录的,一个是基于总线嗅探的。
- 基于目录的方式延迟高,但是占用总线流量小,适合 CPU 核数多的系统。
- 基于总线嗅探的方式延迟低,但是占用总线流量大,适合 CPU 核数小的系统。
- 常见的 MESI 协议就是基于总线嗅探实现的。
- MESI 解决了缓存一致性问题,但是还是不能将 CPU 性能压榨到极致。
- 为了进一步压榨 CPU,所以引入了 store buffer 和 invalidate queue。
- store buffer 和 invalidate queue 的引入导致不满足全局有序,所以需要有写屏障和读屏障。
- X86 架构下的读屏障指令是 lfenc,写屏障指令是 sfence,读写屏障指令是 mfence。
- lock 前缀指令直接锁缓存行,也能达到内存屏障的效果。
- x86 架构下,volatile 的底层实现就是 lock 前缀指令。
- JMM 是一个模型,是一个便于 Java 开发人员开发的抽象模型。
- 缓存性一致性协议是为了解决 CPU 多核系统下的数据一致性问题,是一个客观存在的东西,不需要去触发。
- JMM 和缓存一致性协议没有一毛钱关系。
- JMM 和 MESI 没有一毛钱关系。
写在最后
这篇文章, 主要参考了维基百科和 Linux 内核大牛 Paul E. McKenney 的论文以及书籍,如果你想对并发编程的底层有更深入的研究,Paul E. McKenney 的论文和书籍非常值得一看,有需要的后台回复“MESI”自取。
因为笔者水平有限,文章中难免会有错误,如果你发现了,欢迎指出!
好了,今天的文章就到这里结束了,我是小汪,我们下期再见!
欢迎关注我的个人公众号:CoderW
参考资料
- 《深入理解并行编程》
- 《IA-32+架构软件开发人员手册》
- 《Memory Barriers: a Hardware View for Software Hackers》
- 《Is Parallel Programming Hard, And, If So, What Can You Do About It?》