事件抽取浅尝
事件抽取是什么?
Event extraction (EE) task aims to detect the event from texts and then extracts corresponding arguments as different roles
事件抽取相比于关系抽取而言,略感复杂。基本的信息元素较多,不仅是实体和关系,还有他们的上一层级信息,比如,类型信息、论文角色信息。
综合来说,事件是由schema的,不同类型的事件的schema不同。
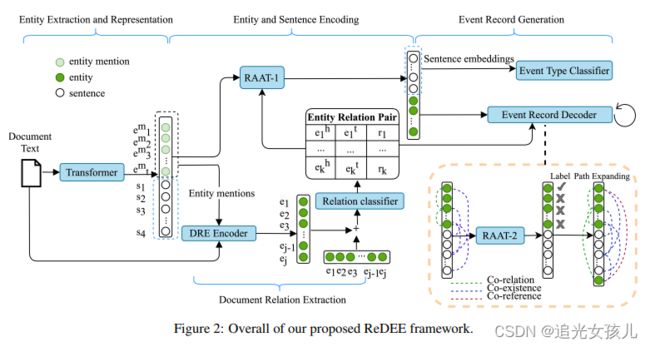
------------事件描述
----------------事件类型
--------------------触发词
--------------------------论元角色(要素角色)
----------------------------------论文(要素)
也有下面这一种说法,事件抽取任务中核心概念:
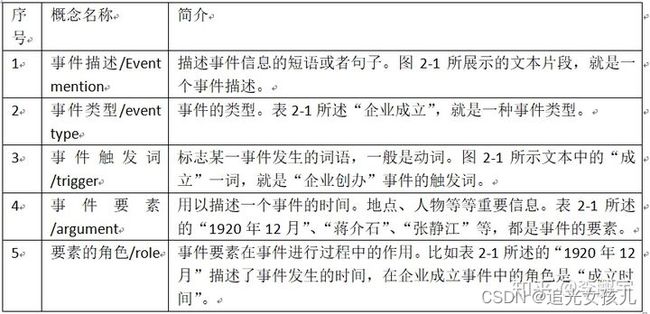
- 实体:真实世界的对象,例如人、组织、位置等。2) 实体提及:文档中引用实体对象的文本跨度。 3) 事件角色:对应于事件中预定义字段的属性。 4) 事件参数:扮演特定事件角色的实体。 5) 事件记录:表示事件本身的记录,包括一系列事件参数。
再举一个百度事件抽取的例子:
{
"text": "雀巢裁员4000人:时代抛弃你时,连招呼都不会打!",
"id": "409389c96efe78d6af1c86e0450fd2d7",
"event_list": [
{
"event_type": "组织关系-裁员",
"trigger": "裁员",
"trigger_start_index": 2,
"arguments": [
{
"argument_start_index": 0,
"role": "裁员方",
"argument": "雀巢",
"alias": [
]
},
{
"argument_start_index": 4,
"role": "裁员人数",
"argument": "4000人",
"alias": [
]
}
],
"class": "组织关系"
}
]
}
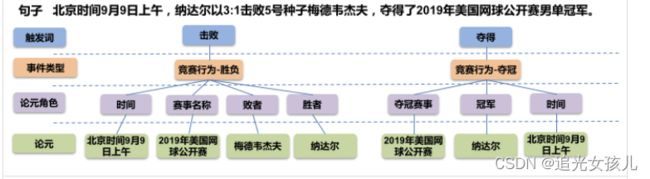
在举一个图形化的例子:
事件抽取的方法
先从苏剑林的博客看起
参考https://kexue.fm/archives/8926/comment-page-1?replyTo=18485
核心是采用实体识别的方法,那么,如何转化为实体识别任务?
在实体识别中,是type-entity作为任务形式,
因此,文章中,将触发词作为论文角色,统一将(事件类型,论文角色)作为一个大类(实体类型),而论文就是作为对应的实体
注意,由于同一事件类型+论元角色可能对应多种不同的事件,比如
DuEE有一个样本是“主要成员程杰、王绍伟被法院一审判处有期徒刑22年和20年。”,分别有两个事件“程杰判处有期徒刑22年”和“王绍伟判处有期徒刑20年”,触发词都是“有期徒刑”,事件类型都是“入狱”。
如何进行事件划分?
文章中给出的迭代式完全子图搜索算法,同一事件的任意两个论元之间是相连的,那么就会构成完全子图。
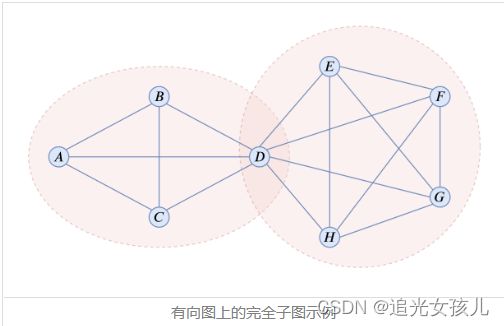
RAAT: Relation-Augmented Attention Transformer for Relation Modeling in Document-Level Event Extraction
核心
考虑到事件元素之间的关系,解决EE(event extraction)问题。-----注意力机制的运用,内部信息的显示注入
相关工作
(1)句子级别的事件抽取
pipeline model:先抽取触发词,然后识别论元角色和论文元素;
joint model: 联合抽取触发词和事件参数
(2)文档级事件抽取
面临两个问题:一是跨句子问题;二是多事件问题,前者是指一个事件可能出现在多个句子,后者是指存在多个事件。
论文中主要回顾了,基于实体导向的文档级关系抽取,但我不太熟悉,暂不做过多评论。
难题在于:
一个文件可能含有多个事件,一个事件的元素可能并不齐全。一个实体可能存在多个mention。
论文方法
pipeline 范式 :命名实体识别、事件角色预测和事件参数提取
我们的 ReDEE 框架中有四个关键组件:实体提取和表示 (EER)、文档关系提取 (DRE)、实体和句子编码 (ESE) 以及事件记录生成 (ERG)。
1. 命名实体识别
我们采用经典的 BIOSE 序列标记方案。(Bert+CRF)
2. 文档关系提取
DRE组件将上一步提取的文档文本(D)和实体({e1, e2, …, ej})作为输入,以三元组的形式输出实体之间的关系对
3. 实体和句子编码 (ESE)
(1)实体和句子依赖(Co-relation 与 NA、Co-reference 和 Co-existence):**Co-relation 和 Co-reference 被定义为表示实体-实体依赖关系。**对于前一个,如果两个实体属于预测关系三元组,则它们之间具有共同关系依赖关系。如果实体对所涉及的三元组具有不同的关系,则认为实体对具有不同的 Co-relation。共同引用显示了指向相同实体的实体提及之间的依赖关系。也就是说,**如果一个实体在文档中存在多个提及,则它们中的每一个都具有 Co-reference **
Co-existence来描述实体和实体提及来自的句子之间的依赖关系。更具体地说,**实体mention与其所属句子共存。**对于剩下的没有任何依赖的实体-实体和实体句子对,我们统一将它们视为 NA 依赖。表 2 显示了完整的依赖机制。 Co-relation 与 NA、Co-reference 和 Co-existence 的不同之处在于它有几个子类型,其数量等于文档关系提取任务中定义的关系类型的数量。
(2)RAAT
**两部分:自我注意和关系增强注意计算**。
矩阵由头部实体聚类。最后将聚类矩阵集成到transformer结构中进行注意力计算。
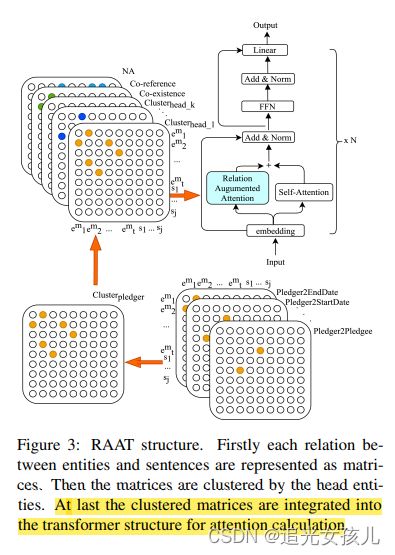
4. Event Record Generation
两个子模块:事件类型分类器(给定句子的嵌入,我们对每种事件类型采用几个二元分类器来预测是否识别出相应的事件)和事件记录解码器(每次迭代的目标是预测某个事件角色的事件参数。)。

数据集
1. ChiFinAnn
包含 32,040 份文件,包含 5 类事件,涉及金融领域的股权相关活动。统计显示,大约 30% 的文档包含多个事件记录。我们以 8/1/1 的比例将数据集随机拆分为训练/开发/测试集。读者可以参考原论文了解详情。
2. DuEE-fin
也来自金融领域,共有约 11,900 份文档。该数据集是从在线竞赛网站下载的*。由于测试集没有公开的基本事实,我们只能将提取的结果提交给网站作为黑盒在线评估。