2小时入门神经网络与深度学习
入门神经网络与深度学习
【唐宇迪带你学AI】2个小时快速入门神经网络与深度学习是什么感受?
人工神经网络就是一个大黑箱,通过这个黑箱子就可以提取出比较好的特征。
p1
深度学习,就是计算机去学习(提取)什么样的特征是最合适的,有了特征之后,就做任意分类等操作(例如LR、SVM)。
p2
深度学习一般应用在CV(图像数据)、NLP(文本数据)中。
人脸关键点上加上一些视觉变换。
深度学习最大的问题:速度太慢了,在移动端的支持不太好。因为它的计算量太大了,包含成百万、千万的特征。
医学上的应用特别多、变脸、超分辨率重构(变3d、加色彩)
李飞飞,IMAGENET数据集,2009年。举办图像分类比赛,2012年图像分类冠军,ALEX用深度学习完成。17年已经结束了,因为计算机的识别已经超越人类了。
数据集小的时候,一般采用传统机器学习,因为计算速度比深度学习快;只有当数据集到了w级别,才去用深度学习算法,深度学习的计算速度和效率才显著展现。
p3
图像在计算机眼中就是一个矩阵,矩阵中存储的就是图像的RGB值,每个像素点的值从0~255。
例如:300 * 200 * 3,h=300,w=200,3表示3个颜色通道。
面临的挑战:
- 照射角度
- 形状改变
- 部分遮蔽
- 背景乱入
深度学习中需要的数据量,以及相应的标签。
p4
深度学习与机器学习的常规套路一样:
- 收集数据并给定标签
- 训练一个分类器
- 测试,评估
可以玩起来的数据集:CIFAR-10,10类标签,50000个训练数据,10000个测试数据,大小均为32*32.
图像距离:(像素点)矩阵中对应位置上的数据相减得到一个差值。L1distance:
d 1 ( I 1 , I 2 ) = ∑ p ∣ I 1 p − I 2 p ∣ d_{1}\left(I_{1}, I_{2}\right)=\sum_{p}\left|I_{1}^{p}-I_{2}^{p}\right| d1(I1,I2)=p∑∣I1p−I2p∣
KNN做图像分类时遇到的问题:得到的结果中背景相同的给分类到一起了。因为它不知道什么是主体,什么是背景,没有学习的过程。
深度学习算法就会学习出前景和背景,前景就是要识别的主体,后景就是要过滤掉的东西。
p5 神经网络基础-前向传播得到损失
线性函数(得分函数):从输入到输出的映射,y=kx+b,其中b是偏置参数,起到微调的作用,而权重w起到决定性作用,控制整个决策边界的走向。
每个特征要对应不同的权重参数。权重数值的大小代表该特征在分类任务中起到决定性作用的高低;正负代表促进或者抑制的作用。
权重参数的组数根据分类个数来决定。
p6
权重参数矩阵是由梯度下降算法等优化算法得到的。
x输入数据是不会变的。但是一直在改变w值。
神经网络可以做分类、回归任务,做不同的任务就是因为损失函数的定义不同。
p7
如果损失函数的值相同,那么意味着两个模型一样嘛?不一定!
希望模型趋于稳定,不要变异,出现过拟合,所以需要加入正则化惩罚项。
softmax分类器:
将得到的得分值转为概率,将值都转为概率值。
映射出来的输出值->归一化得到概率值->交叉熵损失
无论是什么框架,一般都需要自己写一个损失函数。
回归任务:根据得分值计算一个损失。
分类任务:由概率值得到一个损失。
p8
如何更新模型,就是要进行反向传播(梯度下降)
链式法则(梯度是一步一步计算传播的)
p9
加法门单元:均等分配(如果是x+y,则梯度反向传播时,会均匀地传给x、y)
MAX门单元:给最大的(只会把梯度传给大的,小的就没用了)
乘法门单元:互换的感觉(如果是x*y,则对x求导得到y,对y求导得到x,所以是一种互换的感觉)
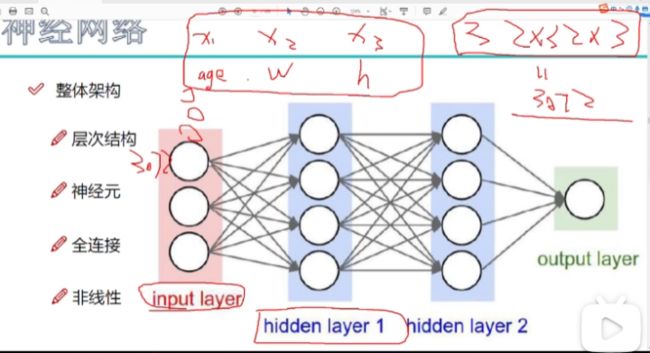
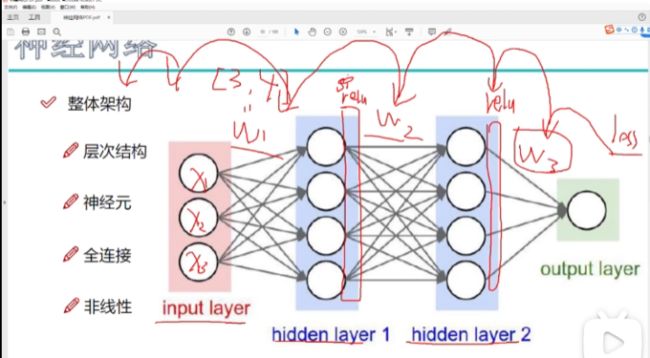
输入层:特征个数
全连接->输入层中的每一个⚪(特征)与隐层的每一个⚪连接。
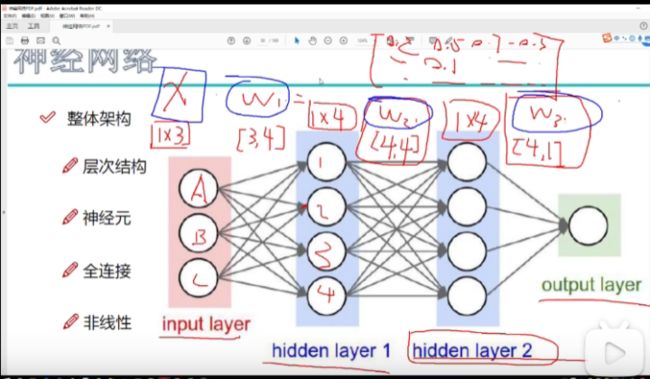
隐层的作用:对输入的原始特征(原始的图像像素值)与权重矩阵相乘,得到计算机更能识别的数据。提取特征(注意看下面3个权重矩阵的大小,w1、w2、w3)
每一层之间都是很通过权重参数矩阵连接的。
非线性(激活函数):sigmoid、max,加在每一步矩阵计算之后

p11 神经元个数的影响
神经元越多,效果约到,但得到的过拟合的程度就越大。
p12
隐层神经元个数加1的话,那意味着会再增加一组参数。隐层元的个数与参数个数息息相关。
正则化的作用:就是对参数的一种惩罚力度。使得决策边界更加简单平滑。
激活函数:sigmoid(停用)、ReLu(max,实用90%,梯度好算,不会出现梯度消失)
梯度消失:因为是乘法的操作,如果中间遇到梯度反向传播回来的为0了,那就相当于消失了。
p13
数据预处理:不同的预处理会使得模型的效果发生很大的差异。(常见:标准化)
参数初始化:同样很重要!通常使用随机策略来进行参数初始化。(初始的学习率是比较小的)
在初始化的时候,前面*0.01,会使得初始的随机参数比较平稳,比较小:
W = 0.0 1 ∗ n p . random. randn ( D , H ) W=0.01^{*} \mathrm{np} . \text { random. } \operatorname{randn}(\mathrm{D}, \mathrm{H}) W=0.01∗np. random. randn(D,H)
DROPOUT舍弃,训练阶段使用(传说中的七伤拳,伤敌七分自损3分,互相伤害):过拟合是神经网络非常头疼的大问题。舍弃其中一部分,以增强抗拒拟合的能力(每次训练随机在每一层中杀死一部分神经元,即保持一些参数不变,不去参与更新)。
目标:就是找权重参数!然后在隐层中进行特征变换,最终输出值前向传播就是利用已知的权重参数求得loss,反向传播就是通过loss再返回去更新参数…这样循环反复,就为了得到最优的参数,然后loss最小。