一、数据浅析
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import warnings
import seaborn as sns
import re
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import StandardScaler, MinMaxScaler
plt.style.use('ggplot')
warnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif'] =['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
data = pd.read_csv('超市数据.csv',sep=',',encoding='gbk')
data['性别'] = np.where(data['性别']=='Male',1,0)
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 200 entries, 0 to 199
Data columns (total 5 columns):
--- ------ -------------- -----
0 用户id 200 non-null int64
1 性别 200 non-null int32
2 年龄 200 non-null int64
3 年收入(k$) 200 non-null int64
4 消费得分 200 non-null int64
dtypes: int32(1), int64(4)
memory usage: 7.2 KB
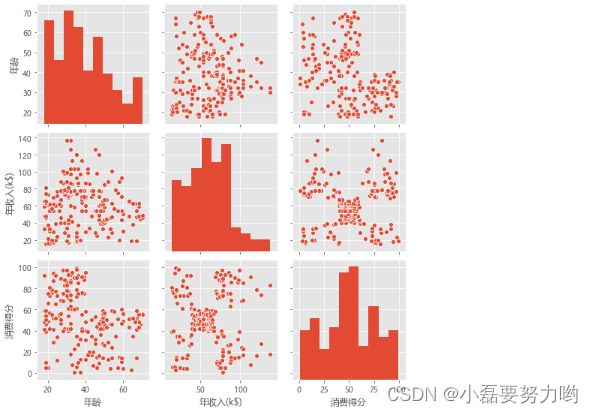
1.1、数据相关性分析
sns.pairplot(data.iloc[:,2:])
plt.show()
1.2、年龄、年收入、消费得分直方图分析
fig, ax =plt.subplots(1,3,constrained_layout=True, figsize=(12, 4))
axesSub = sns.distplot(data['年龄'],ax=ax[0],bins=10)
axesSub.set_title('年龄')
axesSub = sns.distplot(data['年收入(k$)'],ax=ax[1],bins=10)
axesSub.set_title('年收入')
axesSub = sns.distplot(data['消费得分'],ax=ax[2],bins=10)
axesSub.set_title('消费得分')
plt.show()
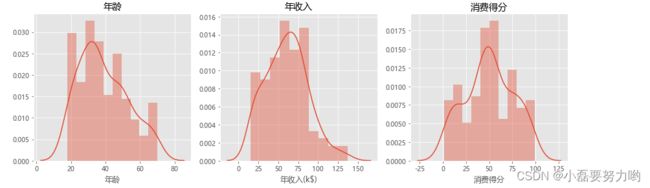
- 年龄:20岁—40岁居多;
- 年收入:年收入为50k$—85k$消费人群较多;
- 消费得分:多数在50分左右波动
1.3、样本数据中的性别比
data['性别'].value_counts().plot.pie(autopct='%.2f%%',labels=['女性','男性'])
plt.show()

1.4、x年龄、y年收入、s消费得分、c性别 气泡图分析
- 以年龄为x轴,年收入为y轴,消费得分决定点的大小(得分越高,点越大),以性别区分点颜色。
fig = plt.figure(figsize=(8,5))
plt.scatter('年龄', '年收入(k$)', s = "消费得分", c= 'r',data=data[data['性别']==0], label='女性',alpha=0.5)
plt.scatter('年龄', '年收入(k$)', s = "消费得分", c= 'b',data=data[data['性别']==1], label='男性',alpha=0.5)
plt.xlabel("年龄")
plt.ylabel("年收入(k$)")
plt.title("年龄—年收入气泡图")
plt.legend()
plt.show()

- 40岁之前,随着年龄的增长,年收入也会增长,消费得分较均匀;40岁以后,年收入趋于直线,在40—60k$之间较多,消费得分与40岁之前相比也低了很多,可能年龄大了,购物需求没那么强烈了;从性别(点的颜色)看收入,男性年收入要高于女性收入。
二、用户分层分析
2.1、三特征:
from sklearn.cluster import KMeans
from sklearn import preprocessing
from mpl_toolkits.mplot3d import Axes3D
x = preprocessing.StandardScaler().fit_transform(data[['年龄','年收入(k$)','消费得分']])
klist = []
for k in range(1,10):
kmn=KMeans(n_clusters=k)
kmn.fit_predict(x)
klist.append(kmn.inertia_)
plt.plot(range(1,10),klist,marker='o')
plt.title('手肘法确定k值')
plt.show()

kmn = KMeans(n_clusters=5)
res = kmn.fit_predict(x)
lables = kmn.labels_
centers=kmn.cluster_centers_
print(centers)
[[ 1.20484056 -0.23577338 -0.05236781]
[-0.42880597 0.97484722 1.21608539]
[-0.98067852 -0.74305983 0.46744035]
[ 0.07333084 0.97494509 -1.19729675]
[ 0.5310735 -1.2905084 -1.23646671]]
x = pd.DataFrame(x)
x.columns = ['年龄','年收入(k$)','消费得分']
x['标签'] = lables
x_pre = [[20,70,67],[34,56,45],[56,23,78],[65,50,50]]
x_pre = preprocessing.StandardScaler().fit_transform(x_pre)
y_pre = kmn.predict(x_pre)
y_pre
fig = plt.figure(figsize=(8,4))
ax = Axes3D(fig)
colors = ['red','blue','green','purple','yellow']
for i in range(5):
ax.scatter(x[x['标签']==i]['年龄'],x[x['标签']==i]['年收入(k$)'],x[x['标签']==i]['消费得分'],color=colors[i],label=i)
ax.scatter(x_pre[:,0],x_pre[:,1],x_pre[:,2],marker='o',color='k',s=120)
ax.set_zlabel('消费得分', fontdict={'size': 12, 'color': 'k'})
ax.set_ylabel('年收入', fontdict={'size': 12, 'color': 'k'})
ax.set_xlabel('年龄', fontdict={'size': 12, 'color': 'k'})
for i,j in enumerate(x_pre):
ax.text(j[0]-0.25,j[1],j[2],"类别:{%d}" % y_pre[i],color='r')
plt.legend(bbox_to_anchor=(1.1,1))
plt.show()

- 第一类标签为0的:年龄大,收入高,消费水平低;
- 第二类标签为1的:年龄小,收入高,消费水平高;
- 第三类标签为2的:年龄小,收入低,消费水平高;
- 第四类标签为3的:年龄大,收入中等,消费水平低;
- 第五类标签为4的:年龄大,收入低,消费水平低
2.2、双特征:
x = preprocessing.StandardScaler().fit_transform(data[['年收入(k$)','消费得分']])
kmn=KMeans(n_clusters=5)
res=kmn.fit_predict(x)
lable_pred=kmn.labels_
centers=kmn.cluster_centers_
print(centers)
[[-1.30751869 -1.13696536]
[-0.20091257 -0.02645617]
[ 1.05500302 -1.28443907]
[-1.32954532 1.13217788]
[ 0.99158305 1.23950275]]
x = pd.DataFrame(x)
x.columns = ['年收入(k$)','消费得分']
x['标签'] = lable_pred
x_pre = [[70,67],[56,45],[23,78],[50,50]]
x_pre = preprocessing.StandardScaler().fit_transform(x_pre)
y_pre = kmn.predict(x1)
y_pre
for i in range(5):
plt.scatter(x[x['标签']==i]['年收入(k$)'],x[x['标签']==i]['消费得分'],label=i)
plt.scatter(x=x_pre[:,0],y=x_pre[:,1],marker='o',color='k',s=100)
for i,j in enumerate(x1):
plt.text(j[0],j[1],"类别:{%s}" % y_pre[i],color='red',size=12)
plt.legend(bbox_to_anchor=(1,1))
plt.xlabel('年收入')
plt.ylabel('消费得分')
plt.show()
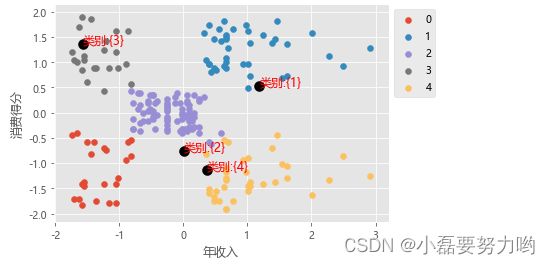
- 第一类标签为0的:收入低,消费水平低;
- 第二类标签为1的:收入高,消费水平高;
- 第三类标签为2的:收入中等,消费水平中等
- 第四类标签为3的:收入低,消费水平高;
- 第五类标签为4的:收入高,消费水平低