多标签算法:MASP 的理论与Python代码分析
本篇文章是基于导师与师姐发布的论文: Xue-Yang Min, Kun Qian, Ben-Wen Zhang, Guojie Song, and Fan Min, Multi-label active learning through serial-parallel neural networks, Knowledge-Based Systems (2022) 相关论文内容可以自行查看, 本文也是主要对于文章算法进行学习和分析, 最后对代码进行学习与自我理解学习
目录
前言
1.多标签概念准备
1.1 何为多标签
1.2 多标签模型
1.3 多标签的其他内容
2.MASP中的主动学习(学习场景)
2.1 冷启动
2.2 主动学习(额外查询)
2.3 主动学习中的一些查询理由
3.MASP中神经网络(学习模型)
4.多标签的评价指标
4.1 传统评价的瓶颈
4.2 混淆矩阵与参数
4.3 相关的评价方案与曲线
4.3.1 ROC曲线与AUC值
4.3.2 PR曲线
4.3.3 F1曲线
5.程序主体框架部分
5.1 总览
5.2 test_active_learning 函数
5.3 Masp构造函数
5.4 MultiLabelData构造函数
5.5 MultiLabelAnn与ParallelAnn构造函数
6.具有代表的函数一览
6.1 网络的学习: one_round_train与bounded_train函数
6.2 冷启动与主动学习: two_stage_active_learn函数
· 关于参数
6.2.1 冷启动批次与主动学习批次计算
6.2.3 冷启动
6.2.4 主动学习
6.3 F1的计算my_test与compute_f1
尾言
前言
MASP全称是Multi-label active learning through serial-parallel neural networks, 是通过串行与并行混合构造的神经网络为学习模型与算法, 并且以主动学习作为学习的场景从而构建的一种面向解决多标签学习问题的一种高效的算法
1.多标签概念准备
1.1 何为多标签
之前我的文章中大多机器学习的算法都聚焦了iris这个数据集, 众所周知, 这个数据集有三个标签
@RELATION iris
@ATTRIBUTE sepallength REAL
@ATTRIBUTE sepalwidth REAL
@ATTRIBUTE petallength REAL
@ATTRIBUTE petalwidth REAL
@ATTRIBUTE class {Iris-setosa,Iris-versicolor,Iris-virginica}
学习中都是确定地对某个数据行进行确定唯一的标签预测, 这应该是属于一种多分类问题, 例如下面这个iris的某三个数据行, 他们的正确标签是"Iris-setosa"这个推断
4.3,3.0,1.1,0.1,Iris-setosa
5.8,4.0,1.2,0.2,Iris-setosa
5.7,4.4,1.5,0.4,Iris-setosa而在机器学习领域对于标签预测中还存在一种多标签的情况, 在多标签的问题中, 一个数据行的标签就不是如此的单一, 有可能是下面的情况. 每个属性列可以有多个情况, 这就是一种多标签的案例. 于是, 假定标签总数是\(L\), 不难发现一个属性行具有的标签可能性就是\(2^L\).
4.3,3.0,1.1,0.1,Iris-setosa,Iris-versicolor
5.8,4.0,1.2,0.2,Iris-virginica
5.7,4.4,1.5,0.4,Iris-versicolor,Iris-virginica
6.4,3.1,5.5,1.8,None
6.0,3.0,4.8,1.8,Iris-setosa,Iris-virginica于是, 假定标签总数是\(L = 1\), 那么通常当\(L=1\), 有\(2^1\), 即是一个二分类问题, 也就是对于数据行进行非1即0的二元断言, AdaBoost中的单个分类器就是实现这种操作, 也是最简单的一种分类器.
当\(L > 1\) 时就是常见的多标签问题了, 此刻如果限定标签选择是互斥的, 那么就回到了常见的多分类问题.
1.2 多标签模型
之前在聊多分类问题时我们有一个固定的\(N \times 1\)标签列, 存放值的范围在0~\(L-1\) , 用于表示确定的某个标签. 而进入多标签领域的话, 这个存放值的" 列 " 应当扩大为一个 " 矩阵 ", 即用一个\(N \times L\)的标签矩阵来存放. 这就与数据集中存放实例的部分的大小为\(N \times M\)的矩阵构成了一个二元组:\[S=(\mathbf{X}, \mathbf{Y}) \tag{1}\]
其中:
- \(\mathbf{X}=\left(\mathbf{x}_{1}, \mathbf{x}_{2}, \ldots, \mathbf{x}_{N}\right)^{\mathrm{T}}=\left(x_{i j}\right)_{N \times M}\)为条件属性矩阵.
- \(\mathbf{Y}=\left(\mathbf{y}_{1}, \mathbf{y}_{2}, \ldots, \mathbf{y}_{N}\right)^{\mathrm{T}}=\left(y_{i j}\right)_{N \times L}\)为标签矩阵.
- \(N\)为对象数, 也是数据集的数据行数
- \(M\)为条件属性数
- \(L\)为标签数
这里每个标签值并不像多分类问题中可以取那么多, 主要来说是布尔含义更多, 常见的数据集中定义的是\(y_{ij}=1\)表示有, \(y_{ij}=-1\)表示无. 当然另外某些情况还会用\(y_{ij}=0\)来表征缺失. 这也是可以理解的, 毕竟现实生活不确信的数据总是多于确信的, 获得数据容易, 但是要明确其含义, 或者说花时间去明确其含义, 其实都是一件复杂的事. 这也是后来主动学习(Active Learning)发端的原因之一.
1.3 多标签的其他内容
多标签有一些相关的特征, 比如标签相关性的问题, 这是许多多标签算法需要考虑的一个部分, 常见的很多算法都会从不同角度去切入, 例如有: 不考虑相关性、考虑两两相关性、考虑两个以上标签相关性. 例如BP-MLL考虑的是两两相关, 而 LIFT 算法又抛弃的了相关性.
BP-MLL 原文: Zhang, M.-L., & Zhou, Z.-H. (2006). Multi-label neural networks with applications to functional genomics and text categorization. IEEE transactions on Knowledge and Data Engineering, 18, 1338–1351.
有关介绍有我老师的博客: BP-MLL
LIFT 原文: Zhang, M.-L., & Wu, L. (2014). LIFT: Multi-label learning with label-specific features. IEEE Transactions on Pattern Analysis and Machine Intelligence, 37, 107–120.
有关介绍有我老师的博客: LIFT
此外标签的取值也可以采用[0,1]的概率值进行多标签研究, 而非布尔, 这就是 标签分布学习问题
这部分更多内容见多标签学习之讲座版 (内部讨论, 未完待续)_闵帆的博客-CSDN博客
2.MASP中的主动学习(学习场景)
通过上述多标签缺失现象与主动学习动机的吻合性, 可以发现多标签的主动学习应当是可能的. MASP中提出了如下的模型: 有限预算的冷启动多标签学习
- 确定专家的查询次数\(T\)
- 通过一定的算法逻辑, 进行初步分析, 从数据集\(N\)挑选出合适的数据样例\(N^{\prime}\)
- 样例\(N^{\prime}\)按照一定的较低预算条件下冷启动(即在神经网络中启动学习), 冷启动中需要专家对于冷启动数据进行打标签, 这个过程中开销足够小.
- 通过上回合启动的神经网络跑出的结果为依据, 再度筛选出一批数据\(Q\), 交给专家打标签, 从而辅助神经网络进行学习 (此操作不断循环)
- 当专家查询的上限达到\(T\)后, 后续训练不再更新已知标签, 通过固有的查询标签结果来反复训练网络直到最终识别率不再显著上升.
大体上如此的过程, 这个中但凡需要目标标签矩阵来辅助的部分都由专家查询完成, 这就是主动学习的核心所在(代码中体现在对于目标矩阵的查询) 这个过程中最特殊的就是冷启动的介入, 冷启动保证了基础的神经网络的成形, 方便我们后续提取某些欠训练标签信息, 从而反哺网络的特征进一步深化. 我试着用两张图来描述这个过程.
2.1 冷启动
 Cold Start Stage
Cold Start Stage
这张图诠释了2,3步的冷启动阶段, 图中的\(Y^{\prime}\)是在专家参与下根据\(X\)标记出的标签矩阵, 这个矩阵的行数是要小于全体标签矩阵\(Y\)的, 但\(Y\)是不可知部分, 因此可知的\(Y^{\prime}\)将会为接下来的学习起指导意见. 图中的\(X^{\prime}\)就是对于特征矩阵\(X\)预处理得到的.
这个预处理得到了训练的数据行集\(U\), 并通过专业人士所标记的数据中那些sparsity(稀疏)值较高标签确定数据列\(V\), 最后得到了冷启动的查询标签点集\(\{(i,j)|i \in U, j \in V\}\). 然后在训练网络时, \(Y^{\prime}\)提供的标签将作为网络损失函数拟合的目标而进行学习. 最后通过有限次batch训练, 得到一个评价参数: 不确定性(uncertainty). 这个参数可以再度引导专家去标记更多关键标签, 从而进一步推动\(Y\)到\(Y^{\prime}\)的转化, 完善\(Y^{\prime}\).
2.2 主动学习(额外查询)
冷启动阶段sparsity的导入存在一定的主动学习含义, 但是后续uncertainty的反复刷新过程中主动学习的特征更加明显:
 Active Start stage
Active Start stage
上回合冷启动结束后提供的"uncertainty"资料推动专家进一步完善了\(Y^{\prime}\), 自然也扩充了\(X^{\prime}\)的可查询集, 于是根据新的\(S^{\prime} = \mathbf{X^{\prime}}, \mathbf{Y^{\prime}}\)进一步训练网络. 之后训练得到新的uncertainty进一步引导专家进行标签标记, 从而更新\(Y^{\prime}\), 从而形成一个训练->得到新的uncertainty->训练...的循环. 直到专家查询达到上限, 输出最终预测.
2.3 主动学习中的一些查询理由
- representativeness (代表性): \(X\)变为\(X^{\prime}\)的预处理的手段是采用Density Peak中描述数据本身特征关键性程度的一个指标. Density Peak的理论源于14年在Nature上发表的论文 “Clustering by fast search and find of density peaks” , 这篇文章提出的这个算法是数据聚类中很有力的一种方案, 我在我的ALEC主动学习(2.1节)中讲过这个评价算法的实现, 详情可以查看.
- sparsity (稀疏性): 我们在主动学习过程中, 让专家去为我们打标签时会更多的列出那些很少被判断的一些标签让专家去判断. 例如之前我们都是给出一张图片去问专家有没有"狗",",猫","老鼠", 但是"兔子"这个标签却几乎没有问过. 于是在下次选择提问标签时这些标签拿去提问专家的几率就会上升. 论文中提供了下述公式:\[\psi_{k}=1-\frac{|\mathbf{Q} \cap\{1,2, \ldots, N\} \times\{k\}|}{N} \tag{2}\]这个公式中\(Q\)表示所有被查询的标签点, \(\{k\}\)表示第\(k\)列(第\(k\)个标签), \(\{1,2, \ldots, N\}\)表示全体数据行, 因此\(\{1,2, \ldots, N\} \times\{k\}\)表示第\(k\)标签对应的\(N\)个标签点. 因此分子就表示这个\(N\)个标签点被实际查询的次数. 可见其被查询得越少那么\(\psi_{k}\)值就越大, 那么sparsity也就越高, 算法中定义这样的标签更容易被查询.
- uncertainty (不确定性): 请先阅读第3节了解基本的网络构造再继续了解这个指标. 对网络结果的预测是对Output的双端口的两个值进行权衡的结果. 一个端口值靠近1一个端口靠近0, 只是在backPropagation时设定的1/0值拟合的结果, 拟合效果好的自然能表现为一端大一端小的特性. 但是反之, 那些拟合效果不好的, 可能是测试数据, 亦或者是之未进行惩罚的原缺失标签端口. 这些Output双端口的值之间的差别总不是特别大, 预测效率低, 因此需要额外拟合. 于是我们定义双端口的绝对差值与算法提出的"不确定性"存在相关性. 与是有了原论文中的标签不确定性公式:\[\eta(i, k)=\left\{\begin{array}{ll}
0, & \text { if } y_{i k} \text { is queried } \\
1-\left|g_{k}^{-}\left(f\left(\mathbf{x}_{i}\right)\right)-g_{k}^{+}\left(f\left(\mathbf{x}_{i}\right)\right)\right|, & \text { otherwise. }
\end{array}\right.\tag{3}\]
3.MASP中神经网络(学习模型)
MASP中的SP描述了其采用的网络——serial-parallel neural networks. 这里我采用论文中的原图来描述:
 serial-parallel neural networks.
serial-parallel neural networks.
所谓串行(serial)网络就是图中的前导serial part, 这部分网络起到了特征提取的作用, 所有的标签之间的特征都在这里串联进行分析, 同时也实现了标签相关性的处理. 因此MASP中是考虑了标签相关性的, 只不过本文的特点就在于标签相关性的考虑是在先导学习中完成的, 而不是对于预测结果进行分析, 与常见的标签相关性的处理手段有所差异.
并行(parallel)网络是图中平行输出前的这部分网络, 这部分网络的个数等于\(L\), 言下之意, 每个并行网络实现了对于一个标签的单独二分类预测. MASP中采用的并行网络的输出是一个双端口输出, 输出的值范围在[0,1], 在网络进行预测时, 作为一个正向输出的结构, 我们定义双端口中较大部分评估为1, 较小部分评估为0. 最终pairwise = <1, 0>时预测为负标签(-1), 即标签不存在; 最终pairwise = <0, 1> 时预测为正标签(1). 此外还有一种可用的方案就是利用softmax将双端口计算为一个确定的概率值, 作为正标签的概率, 最终通过确定一些阈值来决定当前标签的正负.
在网络进行训练时, 作为一个负向backPropagation的结构时, 目标标签若是负标签(-1), 那么就生成一个pairwise = <1, 0>, 训练时forward后计算损失函数时针对这个pairwise来拟合双端口; 目标标签若是正标签(1), 那么就生成一个pairwise = <0, 1>, 拟合同理. 额外强调, 当目标标签缺失(0), 算法会生成的pairwise = <\(\hat{y}_{0}\), \(\hat{y}_{1}\)>, 从而在计算损失函数中不会产生惩罚. 这就是MASP中不对缺失标签进行惩罚的特征.
具体来说, 代码模拟MASP时, 缺失标签并不是说这个标签在数据集\(Y\)中就缺失了, 而是这个标签并没有被专家标记, 也就是说在\(Y^{\prime}\)中找不到这个标签. 当然, 虽然它缺失了, 但是仍然是可以被成熟的网络给预测出来, 或者在后续被选中为uncertainty的标签从而被专家标记(代码中表征被查询)从而变成非缺失标签.
另外我通过阅读源码还得到一些网络信息, MASP中在backPropagation过程中对于损失函数采用的梯度下降方案是自适应矩估计(Adam: Adaptive Moment Estimation), 大部分层的激活函数使用的是Sigmoid, 但是在串行与并行网络之间采用的是ReLU, 最终采用的损失函数是MSE均方误差.
4.多标签的评价指标
MASP采用的F1评价指标, 对于F1, AUC了解的读者可以直接看4.3.3
4.1 传统评价的瓶颈
在多分类问题中的标签列因为只有一个, 是否预测正确可以用1/0表示, 扩展到多个数据行之后可以判断1的占比得到识别的效果, 这就是accuracy.
但是多标签问题中一个数据行有多个标签列, 若还以1/0表示是否预测正确就会出现不合理的地方: 首先多标签问题的标签正确性是布尔化的, 某个标签预测 " 不存在/存在 " 可能都是合理的, 例如对于一个\(L=4\)的数据行, 如果说真实情况是{+1, -1, -1, -1}, 我绝不能说预测成{+1, -1, +1, -1}就绝对地错误, 因为我毕竟还预测对三个啊 ! 那么用比例来算呢, 比如这个数据行预测的accuracy为75%. 但是这样也不合理, 因为现实中的多标签数据中的多标签矩阵具有严重的标签稀疏性, 简单来说就是一个数据行中负标签的个数可能占到全体标签的九成以上! 如此来说似乎我把一个数据行的标签全预测为负标签就有99%的正确率了, 但是, 这合理吗? 无论给你什么图片, 让你预测有什么动物, 你都预测 " 啥动物都没 ".
因此我们需要提出一些全新的评价指标.
4.2 混淆矩阵与参数
混淆矩阵是评价总体精度一个非常关键的东西, 也是各种评价指标的基础:
 Confusion Matrix
Confusion Matrix
表中重叠交叉部分诞生出四个预测与实际的重叠情况:
- TP:预测为1,样本为1,预测正确
- FP:预测为1,样本为0,预测错误
- FN:预测为0,样本为1,预测错误
- TN:预测为0,样本为0,预测正确
通过这四个信息也诞生了相对应的几个指标:
- Precision(查准率): \(\frac{TP}{TP+FP}\) 在所有预测为正的样本中, 真实为正的样本所占的比重. 我今天在菜市场买了5个西瓜, 我笃定它们很甜, 结果真的很甜的只有2个, 查准率就是\(\frac{2}{5}\). 可见, 查准率的分母是可能随着实验样本增加而增加的, 但是分子却不一定. 比如我今天在昨天基础上右买了10个西瓜, 我相信它们一定非常甜, 结果都还没昨天的甜! 于是查准率变成\(\frac{2}{15}\). 可见, 若我运气超好, 每天买瓜都甜, 那么查准率会一直保持1, 当然世界上也许有运气好的, 但是没有永远运气好的, 所以持续下去, 总会有一天出现不甜的瓜, 这个时候总的查准率就会偏离1了.
- Recall(查全率) , TPR(真正率, 灵敏度): \(\frac{TP}{TP+FN}\) 在所有真实的正样本中, 预测为正的样本所占的比重. 查全率的分母是一个全局性数据, 言下之意只要数据的总量确定了, 那么从最开始他就不会变动, 变动的只有分子. 假如说有10个犯人跑到了总人口有990的一个小镇, 现在警官们挨家挨户去抓人作为嫌疑人审问(现实中不可能这么干啦), 我们的底数就是10, 可能说审完前50家都抓错人, 那么我们的查全率仍保持在\(\frac{0}{10}\), 但凡找到一个犯人就会给分子+1, 直到找到全部10个人, 查全率达到1. 由此可知, 查全率的初始值是0, 随着查询的增加, 总会达到1, 只不过时机不同, 运气好时会很快, 刚好我们查的前10户就是10个罪犯躲藏的地方, 运气不好时, 最后1的罪犯在第1000次查询时才找到, 前者查询量只有10, 而后者却是1000.
- FPR(假正率, 特异度): \(\frac{FP}{FP+TN}\) 在所有真实的负样本中, 预测为正的样本所占的比重. 这个可以和TPR相反对比, 假如说还是之前的那个小镇, 保持刚刚那个策略. 最初负样本是990, 查到第一户抓去认为是嫌疑人并且审问, 结果抓错了, 那么我们的FPR就从\(\frac{0}{990}\)变成\(\frac{1}{990}\), 从这里也可以发现, 随着调查深入, 不是TPR增加\(\frac{x+1}{10}\)就是FPR增加\(\frac{y+1}{990}\), 最终两者全到达1
4.3 相关的评价方案与曲线
由上面三个指标衍生出了非常多的评价指标, 这里简单列举几个.
4.3.1 ROC曲线与AUC值
首先是ROC曲线, 全称“受试者曲线”, 简单来说, 他将随着调查样本的深入过程中不断增大的TPR和FPR分别作为纵坐标与横坐标. 而实际看这个图像时请不要把它理解为一个函数图像, 请看成一张地图, 而(0,0)处有个旅行者, 他每一回合只能向北或向东走, 但是无论怎么走他最终都会走到(1,1)点. 这样理解能完美诠释上文紫色文字的内涵.
 ROC曲线(横坐标为FPR, 纵坐标为TPR)
ROC曲线(横坐标为FPR, 纵坐标为TPR)
可见ROC曲线是个梯度线, 但随着样本的增加, 我们的曲线也会变得更平滑. 与此同时, 当这个曲线"越凸"时, 就证明了TPR的增加是很快的, 也就是说那个旅行者在最开始就尽可能多的往北走, 最后无可奈何必须到达(1,1)于是才向东走. 我们是希望这样的结果的, 用刚刚将TPR的抓罪犯的例子来看, 若在最开始的前几次审判中就能抓住劫匪, 我们似乎就能提前结束抓捕避免了余下的冤假错案. 因此为了度量"凸"的程度, 我们定义这个曲线在[0,1]上的定积分值(面积)为AUC值, 作为评判样本分布好坏的指标.
 ROC曲线与AUC值
ROC曲线与AUC值
若最开始抽取的\(x\)个样本预测为正全部预测正确, 而且刚好把所有的\(x\)个真实正样本全部预测了出来, 那么TPR在前\(x\)次预测时分数就会从\(\frac{0}{x}\)直接变成\(\frac{x}{x}\), 这就是best的ROC曲线, 他的AUC值为1.
4.3.2 PR曲线
通过介绍得知, Precision的值最开始是从1开始(Precision值一开始就是\(\frac{0}{1}\))的可能性是比较小的, 因为我们往往在实际做预测时都会按照为正样本可能性排序, 往往第一个样本的预测为正的可能性是接近100%), 然后随着预测过程中误差的发生导致逐步偏离1, 但是因为分子有积累量, 故最终也不会到0. 而Recall值会随着调查深入从0 逐步接近1, 样本分布有序时, 这种接近会更早达到. 最终, 以Recall为横坐标, Precision为纵坐标, 从而得到PR曲线.

对于不同的模型在相同数据集上的预测效果, 我们可以画出一系列的PR曲线, 一般来说如果一个曲线完全“包围”另一个曲线, 我们可以认为该模型的分类效果要好于对比模型. 但是PR曲线的描述终究还是比较粗糙的, 实际上关于Precision与Recall我们更多用的是F1, 这也是MASP中选择的度量方案之一.
4.3.3 F1曲线
F1值是P和R的调和平均值的2倍:\[F_{1} = \frac{2PR}{P+R} \tag{4}\]这里P代表Precision, R代表Recall.
实际我们通过网络的学习或者是其他手段得到了最终的预测的标签值, 最开始这些标签值还没有转换为确定的1/-1时他们都是一个双端口值<\(\hat{y}_{0}\), \(\hat{y}_{1}\)> (\(\hat{y}_{p} \in [0,1]\)), 并唯一地与它的真实标签值在逻辑上对应. 逻辑上这些单独的双端口二元组与它的真实标签值不过都是在标签矩阵中某个坐标\(\{(i,j)| 0 \leq i < N , 0 \leq j < L\}\) 的映射和取值. 现在我把他们都降为一维数组, 这个对应关系依旧不变, 然后我将真实的标签值进行依据 双端口二元组softmax概率值 的排序, 也就是按照网络训练出来的标签可能为正的概率对真实标签进行重排, 得到一个真实标签重排数组sortedArray(数组长为N*L, 内容大概是[1,1,1,...,1,1, -1,-1,-1,...,-1,-1], 但是因为预测有缺陷, 可能会出现连续的1中夹杂-1, 连续-1中夹杂1). 然后不断取出sortedArray的前\(Q\%\)数据, 并且都预测这个数据内的数据为正标签, 然后根据公式4来计算F1.
 F1比对曲线
F1比对曲线
best的曲线表示最佳的F1曲线, 若当前数据总量为\(x+y\), 其中\(x\)个是真实的正样本, \(y\)个是真实的负样本. 通过公式可以判断, 最佳情况下前\(x\)样本的确是正样本, 因此前\(x\)次抽样中Precision将永远是1(抽取一个预测为正就预测对), 而当预测进入第\(x+1\)个数据时Precision将从1下降(已经没有正样本了, 再抽取一个预测为正就会预测错), 直到最后下降为\(\frac{x}{x+y}\). 而Recall在最开始是\(\frac{0}{x}\), 随着抽样继续逐步\(\frac{1}{x}\),\(\frac{2}{x}\)...增加. 然后在检查完第\(x\)个数据时变为\(\frac{x}{x} = 1\), 后续将不再变化. 因此当检查到第\(x\)个数据时, Precision是最后一次为1, 而Recall第一次变为1, 因此就得到best上图中best曲线最高值:\(F_{1} = \frac{2 \times 1 \times 1}{1+1} = 1\). 之前[0~\(x\)]区间内Precision保持1不变, 而Recall又是一个逐步从0->1的递增过程, 因此图中曲线这部分就是递增.
而实际数据将是蓝色的actual曲线, 虽然[0~\(x\)]区间会递增一部分, 但是Precision可能因为一些错误预测导致提前从1开始下降, 而Recall也会因为错误预测增加变慢. 所以蓝色线会提前偏离best曲线, 提前达到Peak并下降, 最后在末尾又因为少量的成功预测导致Recall上升从而略微拔高F1. 最后关于worst与random曲线诸位读者可以进行类似分析, 简言之worst其实就是先排负标签后排序正标签的结果.
最终无论怎么折腾, 最后全局数据测试后Recall一定是1, Precision一定是\(\frac{x}{x+y}\). 所以最后曲线最后都殊途同归地汇聚于\((1.0,\frac{2x}{2x+y})\)(初中数学计算)
5.程序主体框架部分
5.1 总览
源代码的体量比较庞大, 进行了多轮测试, 场景分为了监督学习, 随机查询的半监督学习和主动学习. 在训练数据方面, 有通过5折交叉验证来只利用一个训练集来分化完成训练和测试, 也有利用默认原数据集给出的训练/测试文件来分别指导测试和训练. 这里为了简单起见主要展示一条分支:
 代码选择
代码选择
具体描述时我就省略一些读写文件的代码了, 一些变量的作用我将在描述时介绍, 并在最后放出一些常用变量的理解. 这次一反我文章常态, 我将自顶向下介绍此代码, 先将主体, 具体涉及到某函数时我在简单阐述. 具体有兴趣的欢迎查看源码.
本文用于描述测试的数据是Birds数据集:
 Birds数据集 (训练)属性矩阵 322行数据与230个属性构成
Birds数据集 (训练)属性矩阵 322行数据与230个属性构成
 Birds数据集 (训练)标签矩阵 322行数据与19个标签构成 (注意图中矩阵经过转置)
Birds数据集 (训练)标签矩阵 322行数据与19个标签构成 (注意图中矩阵经过转置)
(测试矩阵就不放图了, 有323个测试数据, 测试与训练数据集的个数几乎一致)
具体流程我用一张图描述
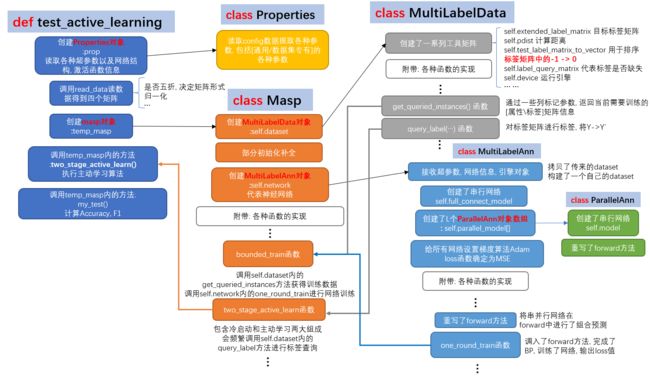 执行流程中各个类的分工
执行流程中各个类的分工
这张图中每一种颜色代表一个类, 除了最左边的那个函数除外, 你可以把test_active_learning视为本流程的main函数来理解. 所有类的纵向同颜色流程框代表着此类构造函数中任务完成的过程, 而在"附带: 各种函数的实现"白框之下是这个类的一些关键函数成员, 若没有这个白框的话说明当前类所拥有方法已经全部展示. 显然, 只有ParallelAnn和Properties类符合, 因为它们的体量是最小的. 其余三个类都是相对比较庞大的, 具有非常多的附带方法, 本文不可能也没必要都介绍, 我只对部分关键的做基本阐述.有兴趣欢迎查看源码.
5.2 test_active_learning 函数
def test_active_learning(para_dataset_name: str = 'Emotion'):
"""
用于填写第三组实验数据, 与一般的多标签学习主动算法比.
:param para_dataset_name: 数据集名称.
"""
print(para_dataset_name)
temp_start_time = time.time()
prop = Properties(para_dataset_name)
temp_train_data, temp_train_labels, temp_test_data, temp_test_labels = read_data(para_train_filename=prop.filename, param_cross_flag=False)
prop.train_data_matrix = temp_train_data
prop.test_data_matrix = temp_test_data
prop.train_label_matrix = temp_train_labels
prop.test_label_matrix = temp_test_labels
prop.num_instances = prop.train_data_matrix.shape[0]
prop.num_conditions = prop.train_data_matrix.shape[1]
prop.num_labels = prop.train_label_matrix.shape[1]
prop.full_connect_layer_num_nodes[0] = prop.num_conditions
temp_masp = Masp(para_train_data_matrix=prop.train_data_matrix,
para_test_data_matrix=prop.test_data_matrix,
para_train_label_matrix=prop.train_label_matrix,
para_test_label_matrix=prop.test_label_matrix,
para_num_instances=prop.num_instances,
para_num_conditions=prop.num_conditions,
para_num_labels=prop.num_labels,
para_full_connect_layer_num_nodes=prop.full_connect_layer_num_nodes,
para_parallel_layer_num_nodes=prop.parallel_layer_num_nodes,
para_learning_rate=prop.learning_rate,
para_mobp=prop.mobp, para_activators=prop.activators)
temp_init_end_time = time.time()
temp_masp.two_stage_active_learn(para_instance_selection_proportion=prop.instance_selection_proportion,
para_budget=prop.budget,
para_cold_start_labels_proportion=prop.cold_start_labels_proportion,
para_label_batch=prop.label_batch,
para_instance_batch=prop.instance_batch,
para_dc=prop.dc, para_pretrain_rounds=prop.pretrain_rounds,
para_increment_rounds=prop.increment_rounds,
para_enhancement_threshold=prop.enhancement_threshold)
temp_acc, temp_f1 = temp_masp.my_test()
temp_test_end_time = time.time()
print('Init time: ', temp_init_end_time - temp_start_time)
print('Cold start time: ', temp_masp.cold_start_end_time - temp_init_end_time)
print('One round time: ', (temp_masp.multi_round_end_time - temp_masp.cold_start_end_time)/temp_masp.num_additional_queries)
print('Bounded time: ', temp_masp.final_update_end_time - temp_masp.multi_round_end_time)
print('Test time: ', temp_test_end_time - temp_masp.final_update_end_time)- (Line 8) 通过Properties类获得prop对象, 这个类主要封装了当前学习的各种参数, 统一的包括像求数据代表性中会使用的范围半径\(d_c\), 梯度因子, 常规训练的次数, 冷启动预算值等等. 非统一的还有针对不同数据采用的网络层数组, 数据集地址, 激活函数字符串, batch训练的批次等等. 有兴趣的可用通过源码查看.
- (Line 9~18) 读文件, 并存到变量中, 同时也将一些必要信息存储下来. 这里为了方便都将数据存到了prop对象中, 这在大型代码中非常重要, 确保多个不同的类能共享同一个全局数据.
- (Line 20) 通过读入的矩阵\(X\)的属性数来确定网络输入端神经元个数, 具体变量内容详见代码中config.json文件与Properties类中的初始化.
- (Line 22~32) 构造masp对象: temp_masp. 这是本代码的关键
- (Line 35~42) 执行temp_masp内的two_stage_active_learn方法完成冷启动与主动学习
- (Line 43) 计算Accuracy与F1
- (Line 45~49) 输出不同阶段的时间分析, 这是论文中表7的由来
5.3 Masp构造函数
class Masp:
"""
Multi-label active learning through serial-parallel networks.
The main algorithm.
"""
def __init__(self, para_train_data_matrix, para_test_data_matrix, para_train_label_matrix, para_test_label_matrix, # 四个矩阵
para_num_instances: int = 0, para_num_conditions: int = 0, para_num_labels: int = 0, # 矩阵的三个参数
para_full_connect_layer_num_nodes: list = None, para_parallel_layer_num_nodes: list = None,
para_learning_rate: float = 0.01, para_mobp: float = 0.6, para_activators: str = "s" * 100):
# Step 1. Accept parameters.
self.dataset = MultiLabelData(para_train_data_matrix=para_train_data_matrix,
para_test_data_matrix=para_test_data_matrix,
para_train_label_matrix=para_train_label_matrix,
para_test_label_matrix=para_test_label_matrix,
para_num_instances=para_num_instances, para_num_conditions=para_num_conditions,
para_num_labels=para_num_labels)
self.representativeness_array = np.zeros(self.dataset.num_instances)
self.representativeness_rank_array = np.zeros(self.dataset.num_instances)
self.output_file = None
self.device = torch.device('cuda')
self.network = MultiLabelAnn(self.dataset, para_full_connect_layer_num_nodes, para_parallel_layer_num_nodes,
para_learning_rate, para_mobp, para_activators, self.device).to(self.device)
self.cold_start_end_time = 0
self.multi_round_end_time = 0
self.final_update_end_time = 0
self.num_additional_queries = 0在test_active_learning函数中声明了一个Masp对象, 这个类描述了算法的主要过程
- (Line 7~10) 构造传参有11个参数, 前四个是[训练\测试]属性矩阵与[训练\测试]标签矩阵, 后续依次是数据行数\(N\), 条件属性个数\(M\), 标签个数\(L\), 串行连接层数组, 并行连接层数组, 学习因子, 惯性因子mobp, 激活函数字符串
- (Line 12~17) 构造MultLabelData对象: self.dataset. 这个对象掌管了整个学习过程中非常多关键的标记矩阵. 这里的变量要和Properties类提供的变量做区分, prop对象主要是既定的一些超参数, 是用于调控的,是人为调控的参数. 而self.dataset中的变量是算法各种阶段可能用到的各种标记数组, 桶数组, 暂存数组. 相应地, 不同于Properties类地, 它有设置基于这些数组的一系列操作, 这也是为何Properties类只有66行 而MultLabelData类却有近乎500行左右(算上一些注释)
- (Line 19~20) 代表性数组与排序后代表性的下标数组初始化, 这是冷启动之前挑选数据集时需要用到的内容
- (Line 24) 确定CUDA引擎, 这个是torch编程中的内容, 用于后序代码执行GPU驱动的引导对象
- (Line 26~27) 构造MultLabelAnn对象: self.network. 这个对象内有实现网络学习的各种构造方法.
- (Line 29~32) 计时器初始化, 因为Masp类构造完毕之后, 陆续有些对象的函数方法就要开始调用了, 有效运算代码要开始了, 因此需要准备好计时器开始工作.
5.4 MultiLabelData构造函数
class MultiLabelData:
"""
Multi-label data.
This class handles the whole data.
"""
def __init__(self, para_train_data_matrix, para_test_data_matrix, para_train_label_matrix, para_test_label_matrix,
para_num_instances: int = 0, para_num_conditions: int = 0, para_num_labels: int = 0):
"""
Construct the dataset.
:param para_train_filename: The training filename.
:param para_test_filename: The testing filename. The testing data are not employed for testing.
They are stacked to the training data to form the whole data.
:param para_num_instances:
:param para_num_conditions:
:param para_num_labels:
"""
# Step 1. Accept parameters.
self.num_instances = para_num_instances
self.num_conditions = para_num_conditions
self.num_labels = para_num_labels
self.data_matrix = para_train_data_matrix
self.label_matrix = para_train_label_matrix
self.test_data_matrix = para_test_data_matrix
self.test_label_matrix = para_test_label_matrix
# -1 to 0
self.test_label_matrix[self.test_label_matrix == -1] = 0
self.label_matrix[self.label_matrix == -1] = 0
self.test_label_matrix_to_vector = self.test_label_matrix.reshape(-1) # test label matrix n*l to vector
self.extended_label_matrix = np.zeros((self.num_instances, self.num_labels * 2))
for i in range(self.num_instances):
for j in range(self.num_labels):
# Copy label matrix.
if self.label_matrix[i][j] == 0:
self.extended_label_matrix[i][j * 2] = 1
self.extended_label_matrix[i][j * 2 + 1] = 0
else:
self.extended_label_matrix[i][j * 2] = 0
self.extended_label_matrix[i][j * 2 + 1] = 1
# Step 2. Space allocation for other member variables.
self.test_predicted_proba_label_matrix = np.zeros((self.num_instances, self.num_labels))
self.predicted_label_matrix = np.zeros((self.num_instances, self.num_labels))
self.test_predicted_label_matrix = np.zeros(self.test_label_matrix.size)
self.label_query_matrix = np.zeros((self.num_instances, self.num_labels))
self.has_label_queried_array = np.zeros(self.num_instances)
self.label_query_count_array = np.zeros(self.num_labels)
self.distance_measure = MyEnum.EUCLIDEAN
self.device = torch.device('cuda')
self.pdist = torch.nn.PairwiseDistance(p=2, eps=0, keepdim=True).to(self.device)刚刚也提到过, MultiLabelData类中声明的成员变量是算法各种阶段可能用到的各种标记[数组/矩阵], 桶数组, 暂存[数组/矩阵] 以及作用于这些结构之上的各种操作. 是不同于Properties类的, 既定的, 用于调控的超参数.
- (Line 8~9) 类的调入参数依旧是经典的[训练\测试]属性矩阵与[训练\测试]标签矩阵, 后续依次是数据行数\(N\), 条件属性个数\(M\), 标签个数\(L\).
- (Line 20~27) 接收函数形参
- (Line 30~31) 将标签矩阵中所有的-1转变为0, 即在代码层面, 1表示正标签, 0表示负标签. 不实际设计-1的含义, 后续出现-1的设置也是局部的含义传递. 这个地方非常重要, 不然会理解错一些代码用意.
- (Line 33) 将测试集的标签矩阵压缩为一维(\(N\) * \(L\) -> 1 * \(NL\)) 这里的用意可参考4.3.3中F1曲线的横坐标取值来历. 此外需要了解, 任何有意义的评价指标都是对测试集做的.
- (Line 35~44) 创造一个训练集标签矩阵的双端口版本(\(N\) * \(L\)-> \(N\) * 2\(L\))
这个操作是为网络的学习准备, 因为俯视来看, 网络是\(M\)个输入和\(2L\)个输出的结构, 传统的\(N*L\)的标签矩阵是无法实适配的, 因此需要构造一个\(N*2L\)标签矩阵来为损失函数的计算做准备.
 单端口到双端口转化
单端口到双端口转化
- (Line 47) 这个概率预测测试矩阵是一个单端口矩阵, 存储的值位于[0,1], 是由测试网络的Output双端口矩阵通过softmax转换而来(未经处理的Output矩阵的单个值位于[0,1])的概率值, 用来表示某个标签为正的概率程度.
- (Line 49~50) 两个是[训练/测试]标签预测矩阵, 分别由[训练/测试]网络的Output双端口矩阵转换而来, 转化机制是\(\left\{\begin{matrix}
\hat{y} = 1 & ,\{<\hat{y}_0,\hat{y}_1>|\hat{y}_0<\hat{y}_1\} \\
\hat{y} = 0 & ,\{<\hat{y}_0,\hat{y}_1>|\hat{y}_0>\hat{y}_1\} \\
\end{matrix}\right.\) 用于表示当前数据经过网络后得到的实际预测标签情况 - (Line 52) 表示当前标签缺失(查询)情况的矩阵, 1时表示标签不缺失(被查询), 0时表示标签缺失(未被查询). 这是个关键变量, \(Y^{\prime}\)就是\(Y\)在这个变量掩码下的映射, 模拟现实中可知的矩阵内容.
- (Line 54) 这个与52行的矩阵是共同使用的, 只不过它表示的是查询的数据行, 有时候虽然这个数据行已经被查询过, 但是他的某些标签可能还处于缺失(未查询)的状态.
- (Line 55) 标签查询桶, 这个可以表示标签被查询的频度, 这个数组仅在主动学习阶段使用, 我们在挑选查询标签时尽可能挑选self.label_query_count_array值较小的矩阵参与学习, 这就是我们理论部分提到的sparsity值, 毫无疑问, self.label_query_count_array越小的sparsity越大, 越有可能被查询.
- (Line 57~62) 完成torch自带的距离计算的一些预处理操作.
5.5 MultiLabelAnn与ParallelAnn构造函数
class MultiLabelAnn(nn.Module):
"""
Multi-label ANN.
This class handles the whole network.
"""
def __init__(self, para_dataset: MultiLabelData = None, para_full_connect_layer_num_nodes: list = None,
para_parallel_layer_num_nodes: list = None, para_learning_rate: float = 0.01,
para_mobp: float = 0.6, para_activators: str = "s" * 100, para_device=None):
"""
:param para_dataset:
:param para_full_connect_layer_num_nodes:
:param para_parallel_layer_num_nodes:
:param para_learning_rate:
:param para_mobp:
:param para_activators:
:param para_device:
"""
super().__init__()
self.dataset = para_dataset
self.num_parts = self.dataset.num_labels
self.num_layers = len(para_full_connect_layer_num_nodes) + len(para_parallel_layer_num_nodes)
self.learning_rate = para_learning_rate
self.mobp = para_mobp
self.device = para_device
temp_model = []
for i in range(len(para_full_connect_layer_num_nodes) - 1):
temp_input = para_full_connect_layer_num_nodes[i]
temp_output = para_full_connect_layer_num_nodes[i + 1]
temp_linear = nn.Linear(temp_input, temp_output)
temp_model.append(temp_linear)
temp_model.append(get_activator(para_activators[i]))
self.full_connect_model = nn.Sequential(*temp_model)
temp_parallel_activators = para_activators[len(para_full_connect_layer_num_nodes) - 1:]
self.parallel_model = [ParallelAnn(para_parallel_layer_num_nodes, temp_parallel_activators).to(self.device)
for _ in range(self.dataset.num_labels)]
self.my_optimizer = torch.optim.Adam(itertools.chain(self.full_connect_model.parameters(),
*[model.parameters() for model in self.parallel_model]),
lr=para_learning_rate)
self.my_loss_function = nn.MSELoss().to(para_device)
class ParallelAnn(nn.Module):
"""
Parallel ANN.
This class handles the parallel part.
"""
def __init__(self, para_parallel_layer_num_nodes: list = None, para_activators: str = "s" * 100):
super().__init__()
temp_model = []
for i in range(len(para_parallel_layer_num_nodes) - 1):
temp_input = para_parallel_layer_num_nodes[i]
temp_output = para_parallel_layer_num_nodes[i + 1]
temp_linear = nn.Linear(temp_input, temp_output)
temp_model.append(temp_linear)
temp_model.append(get_activator(para_activators[i]))
self.model = nn.Sequential(*temp_model)MultiLabelData类掌管了网络的构造与运算等一系列操作. 大部分内容使用了torch编程中的内容.
- (Line 9~20) 类的调入参数是MultLabelData对象dataset, 串行网络数组与并行网络数组, 学习因子, 惯性参数, 激活函数字符串, 执行的引擎. 通过调入的参数可以发现都是一些构建网络所需要的超参数, 而关于各种繁杂的标记矩阵都由dataset完成就好了.
- (Line 21~27) 接收形参.
- (Line 29~37) 依据para_full_connect_layer_num_nodes提供的网络各层深度, para_activators提供的各层采用的激活函数完成神经网络串行神经网络部分的搭建. 具体可以参考torch编程中的nn.Sequential方法.
- (Line 39~42) 利用python的for生成列表生成一个长度为\(L\)的ParallelAnn对象列表. 每个元素都存放着一个串行网络. 这个数组将和之前构造的主串行网络在后续forward过程中建立联系, 最终搭建出串并行网络.
- (Line 44~46) 给每个网络部分设置梯度下降方法Adam(自适应矩估计), 生成优化器对象. optim是torch的一个优化包, 这里提供了多种运算的优化工具, 这里adam是里面的一种方法, lr用于接收梯度的步长.
- (Line 48) 生成损失函数对象, 损失函数方法为MSE, 计算过程调用了GPU.
- ParallelAnn类的方法是MultiLabelAnn类的复刻, 主要用于实现并行网络的每个子串联部分. 因为主要的学习和计算方法都在ParallelAnn上实现, 因此MultoiLabelAnn具有的功能几乎被阉割了, 主要就是负责构建网络和forward计算, BP都统一由MultiLabelAnn类的BP包揽了.
6.具有代表的函数一览
6.1 网络的学习: one_round_train与bounded_train函数
one_round_train函数是位于MultiLabelAnn类的一个方法, 用于实现一次forward+backPropagation的过程, 这里因为使用了torch编程, 所以非常简洁(轮子真实太香了!). 具体轮子的内核是什么欢迎见我的博客: 基于 Java 机器学习自学笔记 (第71-73天:BP神经网络)_LTA_ALBlack的博客-CSDN博客
def one_round_train(self, para_input: np.ndarray = None, para_extended_label_matrix: np.ndarray = None, para_label_query_matrix: np.ndarray = None) -> object:
"""
One round train. Use instances with labels.
:return:
"""
temp_outputs = self(para_input)
temp_memory_outputs = temp_outputs.cpu().data
para_extended_label_matrix = torch.tensor(para_extended_label_matrix, dtype=torch.float)
i_index, j_index = np.where(para_label_query_matrix == 0)
para_extended_label_matrix[i_index, j_index * 2] = temp_memory_outputs[i_index, j_index * 2]
para_extended_label_matrix[i_index, j_index * 2 + 1] = temp_memory_outputs[i_index, j_index * 2 + 1]
temp_loss = self.my_loss_function(temp_outputs, para_extended_label_matrix.to(self.device))
self.my_optimizer.zero_grad()
temp_loss.backward()
self.my_optimizer.step()
return temp_loss.item()
def forward(self, para_input: np.ndarray = None):
temp_input = torch.as_tensor(para_input, dtype=torch.float).to(self.device)
temp_inner_output = self.full_connect_model(temp_input)
temp_inner_output = [model(temp_inner_output) for model in self.parallel_model]
temp_output = temp_inner_output[0]
for i in range(len(temp_inner_output) - 1):
temp_output = torch.cat((temp_output, temp_inner_output[i + 1]), -1)
return temp_output这个函数需要传三个参数, 一个是需要训练的属性矩阵, 用于forward时提供输入神经元; 另一个是扩展的目标标签矩阵, 用于BackPropagation时计算损失函数并为量化惩罚信息更新网络边权做准备; 最后是标签矩阵是否缺失的标记矩阵, 在训练时专门引入它是为了在计算损失函数的时候专门把那些缺失的标签拎出来 " 单独关照 ", 保证其损失为0, 不进行惩罚
- (Line 7) 这是一个非常Python化的编程, 也是非常torch的编程. 这里的self是MultiLabelAnn对象, 这个对象继承于model, 而model在被单参数调用时会触发封装好的__call__方法, 而nn.Module把__call__方法实现为类对象的forward函数, 因此其本质上等价于self.forward(para_input)
- (Line 24) 于是进入forward函数, 首先将np.ndarray对象的矩阵转化为torch中的tensor对象, 这是为了匹配轮子的接口
- (Line 25~26) nn.Sequential构造的对象也可直接接收参数触发forward的自我迭代, 这个是torch设计好的, 只管用就好了. 最后得了串行网络输出神经元tensor: temp_inner_output. 然后再以这些tensor神经元为起点, 分别进行并行网络列表中不同的并行网络对象, 最终每个网络的输出结果再度存到temp_inner_output中. 这时temp_inner_output已经变成一个列表了(python自带接收格式转换), 列表中每一项都表示一个标签所对应的双端口Output矩阵(类似为tensor).
- (Line 27~30) 将列表中所有\(k * 2\)tensor连接在一起, 构成一个\(k*2L\)的tensor并返回.
- (Line 10, 15) 把形参中的扩展矩阵转化为tensor再带入损失函数中, 损失函数计算启用GPU
- (Line 11~13) 对于缺失标签(未查询标签), 设置其目标矩阵值与预测的值一致, 这样的话其损失结果就是0, 在实际运算中不对其进行惩罚.
- (Line 17~20) 初始化梯度值, 进行backPropagation, 更新权值, 最终返回损失函数值.
def bounded_train(self, para_lower_rounds: int = 200, para_checking_rounds: int = 200,
para_enhancement_threshold: float = 0.001):
temp_input, temp_extended_label_matrix, temp_label_query_matrix = self.dataset.get_queried_instances()
print("bounded_train")
# Step 2. Train a number of rounds.
for i in range(para_lower_rounds):
if i % 100 == 0:
print("round: ", i)
self.network.one_round_train(temp_input, temp_extended_label_matrix, temp_label_query_matrix)
# Step 3. Train more rounds.
i = para_lower_rounds
temp_last_training_accuracy = 0
while True:
temp_loss = self.network.one_round_train(temp_input, temp_extended_label_matrix, temp_label_query_matrix)
if i % para_checking_rounds == para_checking_rounds - 1:
temp_training_accuracy, temp_testing_accuracy, temp_overall_accuracy = self.network.test()
print("Regular round: ", (i + 1), ", training accuracy = ", temp_training_accuracy)
if temp_last_training_accuracy > temp_training_accuracy - para_enhancement_threshold:
break # No more enhancement.
else:
temp_last_training_accuracy = temp_training_accuracy
print("The loss is: ", temp_loss)
i += 1
temp_training_accuracy, temp_testing_accuracy, temp_overall_accuracy = self.network.test()
print("Training accuracy (learner knows it) = ", temp_training_accuracy,
", testing accuracy (learner does not know it) = ", temp_testing_accuracy,
", overall accuracy (learner does not know it) = ", temp_overall_accuracy)bounded_train函数一言以蔽之就是做循环训练的, 第一个参数para_lower_rounds 就描述了循环次数, para_checking_rounds是检查点宽度, 在实际做循环测试的时候将会在抵达检查点后输出提示, 第三个形参para_enhancement_threshold表示当前训练的精度阈值, 在para_lower_rounds次循环测试之后会进入精度检测训练, 当每次训练之后精度提升低于这个阈值了就停止训练.
- (Line 4) 这行代码使用了MultiLabelData类中的get_queried_instances方法, 这个方法为一次训练提供了训练的样本. 在MASP的代码中, 并不是所有训练都直接调用主要的数据集矩阵, 而是通过查询标记矩阵/数组来把未缺失的标签, 判定有需要查询的数据行获取出来. 这些资料才是下次网络学习的资料, 而get_queried_instances方法正是承担把他们读出来的任务.
- (Line 6~11) 循环训练部分
- (Line 14~27) 精度训练部分
6.2 冷启动与主动学习: two_stage_active_learn函数
冷启动与主动学习部分通过一个完整的函数体实现, 大体上分为四个阶段
- 冷启动批次与主动(额外查询)学习批次计算
- 以代表性重排数据集
- 冷启动
- 主动(额外查询)学习
· 关于参数
def two_stage_active_learn(self, para_instance_selection_proportion: float = 1.0,
para_budget: float = 0.2,
para_cold_start_labels_proportion: float = 0.2,
para_label_batch: int = 2,
para_instance_batch: int = 2,
para_dc: float = 0.12, para_pretrain_rounds: int = 200,
para_increment_rounds: int = 100,
para_enhancement_threshold: float = 0.001):
"""
两阶段: 冷启动与主动学习阶段. 总的标签查询个数为
num_instances * num_labels * para_budge
:param para_instance_selection_proportion: 实际数据占训练数据的比例. 其它数据肯定不被查询, 所以不保留.
:param para_budget: 总的查询比例. 占总数据 (不只是训练集) 标签数的比例.
:param para_cold_start_labels_proportion: 冷启动阶段查询标签占总查询的比例.
:param para_label_batch: 冷启动阶段每个实例每次查询标签数.
:param para_instance_batch: 第二阶段每轮查询实例个数.
:param para_dc: 用于计算实例密度的半径. 为一个比例.
:param para_pretrain_rounds: 网络预训练轮数.
:param para_increment_rounds: 每次查询标签后, 进行的固定训练轮数.
:param para_enhancement_threshold: 训练精度提升小于这个阈值时停止.
:return:
"""源代码已有注释, 这里再额外强调几点.
大多为超参数. budge是一个百分比, 主要用于限制冷启动阶段涉及的标签个数避免开销过大. para_instance_selection_proportion是定义数据集时每个数据集内部单独设置的一个百分比, 用于对于某些超大的数据集进一步限制数据量. para_cold_start_labels_proportion是一个分化冷启动和主动学习的一个比率, 假如说这个比率是\(p \%\), 那么\(p \%\)的筛选标签用于冷启动, 而\(1-p \%\)用于主动学习, 避免两个阶段占用同个数据内容.
这部分的训练采用的batch训练, 所以说冷启动和主动学习都有一个批次步长, 这就是形参中提到的batch.
6.2.1 冷启动批次与主动学习批次计算
# Step 1. Reset the dataset to clean learning information.two_stage_active_learn
print("two_stage_active_learn test 1, para_dc = ", para_dc)
self.dataset.reset()
print("two_stage_active_learn test 2")
# This code should be changed later to suit user requirement.
temp_num_selected = int(self.dataset.num_instances * para_instance_selection_proportion)
print("self.dataset.num_instances = ", self.dataset.num_instances,
"para_instance_selection_proportion = ", para_instance_selection_proportion,
"temp_num_selected: ", temp_num_selected)
temp_cold_start_instances = int(self.dataset.num_instances * self.dataset.num_labels
* para_budget * 5 / 4
* para_cold_start_labels_proportion
// para_label_batch)
print("Cold start instances = ", temp_cold_start_instances)
temp_num_additional_queries = int(self.dataset.num_instances * self.dataset.num_labels
* para_budget * 5 / 4
* (1 - para_cold_start_labels_proportion)
/ para_instance_batch)
print("temp_num_additional_queries = ", temp_num_additional_queries)
self.num_additional_queries = temp_num_additional_queries批次计算用公式说明可能更好理解(沿用参数解释中"\(p\)"的定义):\[\operatorname{ColdstartInstances} = \frac{\frac{5}{4}NL\times \text{budget} \times p}{\text{LabelBatchsize}} \tag{5}\]为何冷启动的批次会用"Instances"来表示? 实际上代码中冷启动并不是一批一批进行(不是严格意义上的batch训练), 而是一次性启动. 代码中将冷启动的一批作为一行, 每行查询的标签数目应该是均等的, 例如我们分子算出了15个标签量, 而限定一批(一行)最多查3个标签, 那么一共就会冷启动5行. 这5行不会分为5次训练, 而是整合为一个矩阵加入一次训练中去. 实际中我们的数据集会通过代表性进行排序, 因此往往默认对Top-ColdstartInstances数据冷启动.
此外在冷启动选择标签时会尽量选择那些查询次数比较少的标签, 这就是按照sparsity选取的原则.
 Coldstart的标签选择机制
Coldstart的标签选择机制
\[\operatorname{AdditionalQueries} = \frac{\frac{5}{4}NL\times \text{budget} \times (1-p)}{\text{InstanceBatchsize}} \tag{6}\] 第二个阶段是正式的主动学习阶段, 这部分是货真价实的batch训练, 计算得到的额外查询次数作为批次总量, 并执行如此量的总循环, 每次循环查询InstanceBatchsize次, 并按照这个查询量构建新的\(X^{\prime}\), \(Y^{\prime}\)投入训练, 更新uncertainty并进一步查询.
这里公式中的\(\frac{5}{4}NL\times \text{budget}\)其实就是我们根据实际数据集的数据量估计的一个查询上限, 换言之, 这就是专家查询的最大标签总量, 是第二节介绍MASP主动学习的流程中的上限\(T\).
6.2.2 以代表性重排数据集
self.compute_instance_representativeness(para_dc, 0)
temp_selected_array = self.representativeness_rank_array[0: temp_num_selected]
temp_dataset_select = self.dataset.select_data(temp_selected_array)
# Replace the training data with the selected part.
self.dataset = temp_dataset_select
self.network.dataset = temp_dataset_select
首先需要通过每个数据行的代表性重排数据, 具体的操作的方案可以参考我在这篇文章中采用的Master树的Java方案(3.2~3.3), 当然那个方案略显冗长, 有100多行, 而Python只需要区区30行, 简直不要更爽. 最后将获得的代表性排序下标指导数据集重排, 获得一个排序后的数据集(因为MultiLabelAnn中拷贝了一个dataset, 因此这里面的dataset也要重排).
def compute_instance_representativeness(self, para_dc: float = 0.1, para_scheme: int = 0):
"""
Compute the representativeness of all instances.
:param para_dc: The dc ratio.
:return: An array.
"""
# Step 1. Calculate density using Gaussian kernel.
temp_dc_square = para_dc * para_dc
# The array length is n(n-1)/2.
temp_dist2 = torch.nn.functional.pdist(torch.from_numpy(self.dataset.data_matrix)).to(self.device)
# Convert to an n^2 matrix
temp_distances_matrix = scipy.spatial.distance.squareform(temp_dist2.cpu().numpy(), force='no', checks=True)
# Gaussian density.
temp_density_array = np.sum(np.exp(np.multiply(-temp_distances_matrix, temp_distances_matrix) / temp_dc_square),
axis=0)
# Step 2. Calculate distance to its master.
temp_distance_to_master_array = np.zeros(self.dataset.num_instances)
for i in range(self.dataset.num_instances):
temp_index = np.argwhere(temp_density_array > temp_density_array[i])
if temp_index.size > 0:
temp_distance_to_master_array[i] = np.min(temp_distances_matrix[i, temp_index])
# Step 3. Representativeness.
self.representativeness_array = temp_density_array * temp_distance_to_master_array
# Step 4. Sort instances according to representativeness.
self.representativeness_rank_array = np.argsort(self.representativeness_array)[::-1]
return self.representativeness_rank_array一言以蔽之, 算出\(N\)个数据彼此的距离, 从而通过根据重要性计算的高斯优化公式得到重要性, 然后每个数据都找到距离自己最近的那个重要性比自己大的数据点从而得到独立性最终相乘就好了. 这段代码要注意矩阵运算的性质特点, 特别是第15行.
6.2.3 冷启动
# Step 2. Cold start stage.
# Can be revised to support the random label selection scheme. This is not the efficiency bottleneck.
for i in range(temp_cold_start_instances):
self.dataset.query_label_batch(i, self.dataset.get_scare_labels(para_label_batch))
print("two_stage_active_learn test 3")
self.bounded_train(para_pretrain_rounds, 100, para_enhancement_threshold)
self.cold_start_end_time = time.time()冷启动阶段主要是先通过query_label_batch完成标签的查询, 建立一些新的未缺失标签集. 然后在利用循环训练去训练这部分数据.
def get_scare_labels(self, para_length):
temp_indices = np.argsort(self.label_query_count_array)
result_array = np.zeros(para_length)
for i in range(para_length):
result_array[i] = temp_indices[i]
return result_array代码中的get_scare_labels方法可以返回sparsity满足Top-LabelBatchsize的标签集. 其原理并不复杂, 其实就是每次选择时都重排标签桶 label_query_count_array, 选择其中值最小的前LabelBatchsize个标签下标. 这个变量初始声明是在MultiLabelData的构造函数中.
而确定当前第\(i\)行和行内的标签列数组之后就可以唯一确定一堆标签了, 确定标签之后需要为这个标签进行标记(也就是" 专家查询 "), 执行这个操作的就是dataset.query_label_batch方法.
6.2.4 主动学习
# Step 3. Active learning stage.
for i in range(temp_num_additional_queries):
print("Incremental training process: ", i, " out of ", temp_num_additional_queries)
temp_query_matrix = self.network.get_uncertain_label_batch(para_instance_batch)
for j in range(para_instance_batch):
self.dataset.query_label(int(temp_query_matrix[j][0]), int(temp_query_matrix[j][1]))
temp_input, temp_extended_label_matrix, temp_label_query_matrix = self.dataset.get_queried_instances()
for i in range(para_increment_rounds):
self.network.one_round_train(temp_input, temp_extended_label_matrix, temp_label_query_matrix)
self.multi_round_end_time = time.time()
self.bounded_train(200, 100, para_enhancement_threshold)
self.final_update_end_time = time.time()主动学习过程其实就是学习->获得最大certainty,完善数据集->学习->... 的循环往复, 直到循环总的次数达到上限.
- (Line 4) get_uncertain_label_batch方法返回一个InstanceBatchsize * 2标签坐标矩阵, 表示当前需要参与训练的标签坐标. 这个函数的实现流程如下: 先将全部的训练数据集投入到学习的网络中得到双端口的Output训练预测标签集, 然后利用uncertainty的计算公式3计算出每个双端口的uncertainty值, 并且压缩存放于数组temp_certainty_array 中, 而后对这个数组进行以值排下标序, 得到下标数组temp_indices, 而后提取出temp_indices的前InstanceBatchsize值, 并将值通过一维转二维得到实际上需要标签坐标, 于是进行标记(认定非缺失)并把其坐标存储到一个InstanceBatchsize * 2的坐标矩阵中并返回.
- (Line 6~7) 依据InstanceBatchsize * 2 提示的每行标签坐标进行查询
- (Line 9) 依据查询的标签, 通过get_queried_instances方法, 提取待训练的\(X^{\prime}\), \(Y^{\prime}\)
- (Line 11~12) 执行para_increment_rounds次训练, 主动学习一批训练次数para_increment_rounds也是一个自定义超参数.
- (Line 14) 主动学习完成之后还进行了一次循环训练以测试精度.
6.3 F1的计算my_test与compute_f1
F1的计算我在介绍F1时(4.3.3)与讲解MultiLabelData类的标签压缩数组时(5.4 Line 33, 47)有做过类似的参数, 现在简单一览下其实现:
def my_test(self):
temp_test_start_time = time.time()
temp_input = torch.tensor(self.dataset.test_data_matrix[:], dtype=torch.float, device='cuda:0')
temp_predictions = self(temp_input)
temp_switch = temp_predictions[:,::2] < temp_predictions[:,1::2]
self.dataset.test_predicted_label_matrix = temp_switch.int()
self.dataset.test_predicted_proba_label_matrix = torch.exp(temp_predictions[:, 1::2]) / \
(torch.exp(temp_predictions[:, 1::2]) + torch.exp(temp_predictions[:, ::2]))
temp_test_end_time = time.time()
temp_my_testing_accuracy = self.dataset.compute_my_testing_accuracy()
temp_testing_f1 = self.dataset.compute_f1()
print("Test takes time: ", (temp_test_end_time - temp_test_start_time))
print("-------My test accuracy: ", temp_my_testing_accuracy, "-------")
print("-------My test f1: ", temp_testing_f1, "-------")
return temp_my_testing_accuracy, temp_testing_f1- (Line 4~7) 基础的forward操作, 得到temp_predictions矩阵 : 一个双端口的Output预测标签矩阵.
- (Line 9~10) 利用softmax公式: \(S_{i}=\frac{ \exp{\hat{y}_i}}{\sum_{2} \exp{\hat{y}_i}}\) 计算出第二个端口的占比, 也就是\(S_1\), 最终得到一个又\(S_1\)构成的\(N\times L\)标签softmax预测矩阵. 为何是第二个端口, 因为实际预测中, 我们对于Output输出的数据预测将较大一方预测为1, 较小一方预测为0, 而只有在pairwise=<0,1>是预测为正标签. 理所应当, 第二个端口值越大是越有可能为1. 用阈值的思想, 可以说我们断言{\(S_1\)>0.5}时将标签预测为正标签.
- (Line 15) 计算F1, 具体见下面的代码.
def compute_f1(self):
"""
our F1
"""
temp_proba_matrix_to_vector = self.test_predicted_proba_label_matrix.reshape(-1).cpu().detach().numpy()
temp = np.argsort(-temp_proba_matrix_to_vector)
all_label_sort = self.test_label_matrix_to_vector[temp]
temp_y_F1 = np.zeros(temp.size)
all_TP = np.sum(self.test_label_matrix_to_vector == 1)
for i in range(temp.size):
TP = np.sum(all_label_sort[0:i+1] == 1)
P = TP / (i+1)
R = TP / all_TP
if (P+R)==0:
temp_y_F1[i] = 0
else:
temp_y_F1[i] = 2.0*P*R / (P+R)
return np.max(temp_y_F1)这部分联合4.3.3节来理解.
- (Line 5) 将softmax的概率矩阵压缩为数组temp_proba_matrix_to_vector, 它将作为排序的资料
- (Line 7) 生成以temp_proba_matrix_to_vector为基础的降序排序数组, 简单举个例子, temp[0] = 77就表明temp_proba_matrix_to_vector[77]是最大的概率值, 言下之意, 我们认为下标77所表示的标签是最有可能为正标签的. (因为知道标签矩阵的长宽, 所以77可用一维转二维的手段变成一个坐标)
- (Line 9) 将真实的标签数组self.test_label_matrix_to_vector 按照temp的下标进行排序, 用上面的例子的话, 真实的标签数组的第77标签就会排到第一位, 大概是什么样子其实可以想象, 最终重排的数组all_label_sort一定是形如[1 1 1 1 1 ... 1 1 1 0 0 0 ... 0 0 0] 的模样(代码中负标签统一转换为0了), 只不过在连续的1中可能会有那么几个0, 在连续的0中总会有几个1, 否则F1曲线就逼近best曲线了.
- (Line 12) 要理解下列for循环和下述几个参数之前要有一个思想的预备, F1的计算要有一个统一的正预测, 因此后续for循环中每选定一个范围时都预测它们是正标签. 此处的all_TP统计了实际的all_label_sort中1的数目, 自然这就是全部真实样例中正标签的个数, 所以用混淆矩阵的话说, all_TP = TP + FN
- (Line 14~15) 假定\(\text{len} = N \times L\)下述的for循环其实按序取出一个\(i\)(\(0
- (Line 16) i+1是[0, i] 范围的宽度, 这个范围内我们都预测为正标签. 因此i + 1就是当前我们预测为正的个数, 所以用混淆矩阵的话说, i + 1 = TP + FP. 所以变量P就是Precision.
- (Line 17) all_TP表示 TP + FN. 因此这个R就是Recall.
- (Line 18~22) 通过公式4计算F1, 并范围曲线中的Peak-F1

Peak-F1究竟为什么可用?
我们在测量Peak-F1时将标签矩阵进行了排序, 其目的是更大地确保在最开始前面大部分都能预测正确, 这样最开始的实际1就能更多与我们预测的正标签匹配. 自然, 若这连续的1中没有夹杂0, 连续的0中没有夹杂1, 那么就能逼近F1的best曲线.
由此, 诞生出best曲线的双端口的softmax概率值中一定能找到一个阈值\(\theta\), 大于\(\theta\)的双端口预测为正标签后全部正确, 小于\(\theta\)预测为负标签也全部正确. 再度以预测值重排标签数组就能构成一个完美的连续1与连续0构成的排序数组.
也就是说\(\theta\)成为了一个完美的分水岭, 分水岭左右没有杂质. 这种\(\theta\)的存在能说明我们的网络能做到100%预测正确. 但是在实际中, 再好的多标签方案也无法找到这样实现完美分割的\(\theta\), 左右总是有杂质, 但是算法却能尽可能地找到一个\(\theta\)让左右的杂质尽可能地最少.
因此Peak-F1本质上描述了多标签算法能找到尽可能完美得到的\(\theta\)的能力.
尾言
最后就不展示算法的相关运行结果了, 这部分内容可参考原论文. 论文从监督学习, 半监督学习, 主动学习的Accuracy, 以及F1结果, 运行时间等多个角度与各种多标签算法进行了平行比对, 内容足够详尽充实.
 关于主动学习的Accuracy横向比对
关于主动学习的Accuracy横向比对
文中描述有失偏颇之处欢迎提出指正, 关于多标签的内容博主也正处在学习过程中 !