hadoop和hdfs
一.hadoop
1.项目起源
Hadoop由 Apache Software Foundation 公司于 2005 年秋天作为Lucene的子项目Nutch的一部分正式引入。它受到最先由 Google Lab 开发的 Map/Reduce 和 Google File System(GFS) 的启发。
2.核心组件
核心组件包括Hadoop的基础组件HDFS、MapReduce和Yarn,以及其他常用组件如:HBase、Hive、Hadoop Streaming、Zookeeper等。

3.组件介绍
- HDFS:分布式海量数据存储功能
- Yarn:提供资源调度与任务管理功能
- 资源调度:根据申请的计算任务,合理分配集群中的计算节点(计算机)。
- 任务管理:任务在执行过程中,负责过程监控、状态反馈、任务再调度等工作。
- MapReduce:分布式并行编程模型和计算框架。解决分布式编程门槛高的问题,基于其框架对分布式计算的抽象map和reduce,可以轻松实现分布式计算程序。
- Hive:提供数据摘要和查询的数据仓库。解决数据仓库构建问题,基于Hadoop平台的存储与计算,与传统SQL相结合,让熟悉SQL的编程人员轻松向Hadoop平台迁移。
- Streaming:解决非Java开发人员使用Hadoop平台的语言问题,使各种语言如C++、python、shell等均可以无障碍使用Hadoop平台。
- HBase:基于列式存储模型的分布式数据库。解决某些场景下,需要Hadoop平台数据及时响应的问题。
- Zookeeper:分布式协同服务。主要解决分布式下数据管理问题:统一命名、状态同步、集群管理、配置同步等。
4.生态圈

5.Ambari平台环境介绍
- Apache Ambari是一种基于Web的工具,支持Apache Hadoop集群的供应、管理和监控。Ambari已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeper、Sqoop和Hcatalog等。
- 同类产品为Cloudera Manager的CDH。
- 优点:
- Web安装图形界面操作便捷
- Hadoop家族各组件支持全面
- 社区资源比较丰富
- 缺点:
- Bug较多:安装过程中,莫名其妙的出现错误。系统运维过程中偶尔出错。以上两种情况重启就正常。
- 安装速度与网络质量关系较大,往往时间较长。
在合理避免大坑的情况下,3小时内可以搭建一个基本版的集群。
二.HDFS
1.产生背景
传统的本地文件系统(单机式),在数据量增长过快、数据备份、数据安全性、操作使用便捷性上存在严重不足。
2.特点介绍
- 高容错和高可用性,硬件错误是常态而不是异常
HDFS设计为运行在普通硬件上,所以硬件故障是很正常的。HDFS提供文件存储副本策略,可以实现错误自检并快速自动恢复。个别硬件的损坏不影响整体数据完整性和计算任务的正常执行。
- 流式数据访问
HDFS主要采用流式数据读取,做批量处理而不是用户交互处理,因此HDFS更关注数据访问的高吞吐量。
- 弹性存储,支持大规模数据集
HDFS支持大文件存储,典型的文件在GB甚至TB级别,可以支持数以千万计的大规模数据集。根据业务需要灵活的增加或者缩减存储节点。弹性存储的最大挑战是减小在修改存储节点时的数据震荡问题。
- 简单一致性模型
HDFS文件实行一次性写、多次读的访问模式。设计为文件一经创建、写入和关闭之后就不需要再更改了,这种设计和假定简化了数据一致性问题,使高吞吐量成为可能。
- 移动计算而非移动数据
由于HDFS支持大文件存储,对于大文件来说,移动计算比移动数据的代价要低。这样也可以减少网络的拥塞和提高系统的吞吐量。
- 协议和接口多样性
为上层应用提供了多种接口,Http RestFul接口、NFS接口、Ftp接口等等POSIX标准协议,另外通常会有自己的专用接口。
- 多样的数据管理功能
对于数据压缩、数据加密、数据缓存和存储配额等提供了多样的管理功能。
3.应用场景
- 各大电信运营商
- 中大型互联网公司,如BAT、京东、乐视、美团等
- 金融银行保险类公司
- 各大云平台底层存储平台
- 其他本地系统无法承载存储能力的应用
HDFS架构设计
1.HDFS是什么
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统。
由论文为GFS(Google File System)Google 文件系统启发,是Google GFS的开源Java实现。
2.HDFS组件角色
2.1 NameNode(简称NN)
- HDFS元数据管理者,管理NameSpace(文件系统命名空间),记录文件是如何分割成数据块以及他们分别存储在集群中的哪些数据节点上。
- NameSpace或其本身属性的任何更改都由NameNode记录,维护整个文件系统的文件和目录。
2.2 DataNode(简称DN)
- DataNode是文件系统的工作节点。根据客户端或者NameNode发送的管理指令,负责HDFS的数据块的读写和检索操作。
- 通过心跳机制定期向NameNode发送他们的存储块的列表。
2.3 Client
- 客户端Client代表用户与NameNode或者DataNode交互来访问整个文件系统的对象。
- 开发人员面向Client API来编程实现,对NameNode、DataNode来说透明无感。
3.HDFS架构设计
3.1基本架构

3.2读文件流程
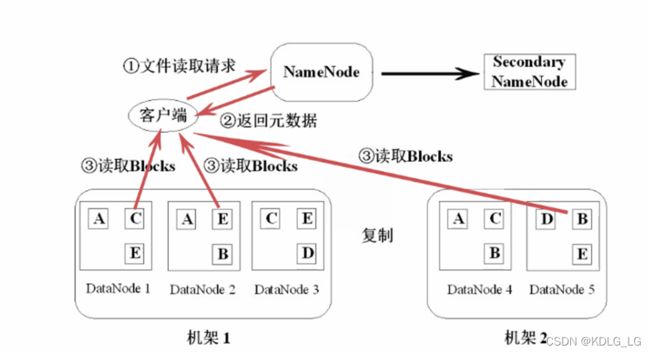
详细步骤:
- 第一步:Client向NameNode发送数据请求后,寻找数据对应的数据块的位置信息。
- 第二步:NameNode返回文件对应的数据块元数据信息,如所属机器、数据块的block_id、数据块的先后顺序等。
第三步:由Client与DataNode直接通信,读取各个block数据块的信息。过程为并行读取,由客户端合并数据
3.3写文件流程

详细步骤:
- 第一步:
- Client向NameNode发送写数据请求后,寻找可以写入的数据块block信息的机器位置。
- 若文件过大,写入可能会分成很多block数据块,实际上是通过一个block一个block的申请。
- 若副本为3,则每次请求后返回一个block的对应的3个副本的block的存放位置。
- 第二步:
- Client获取到对应的block数据块所处的DataNode节点位置后,Client开始写操作。
- Client先写入第一个DataNode,以数据包package的方式逐个发送和接收。如64K大小的package包大小来发送和接收。
- 存在多个副本时,package包的写入是依次进行的。写入到第一个DataNode后,第一个向第二个DataNode传输。第二个写完后,由第二个向第三个DataNode传输package。以此类推。
- 写完一个block数据块后,如果还有则反复进行第一步和第二步。
- 第三步:
- 待所有的数据块block均写完后,Client接收到全部写完的ack答复,告诉NameNode数据已写完,Client关闭socket流。
DataNode也会向NameNode报告新增block数据块的信息。
HDFS Java API应用
HDFS 提供了两种访问接口,除了上面介绍的Hadoop Shell接口,还另外提供了Java API 接口,对HDFS里面的文件进行操作,具体每个Block放在哪台DataNode上面,对于开发者来说是透明的,可以像操作本地系统文件一样,对HDFS进行文件上传、创建、重命名、删除等操作。
下面就以实际操作为例子来说明其API的具体使用。
1.操作需求
// hdfs dfs -cat /tmp/tianliangedu/input.txt
从hdfs文件/tmp/tianliangedu/input.txt中读取其文本内容,并打印出来
2.步骤分解

3.操作实现
3.1资源准备
本地新建文件index.txt,写入“HelloWorld Hadoop”内容,上传至HDFS文件系统的/tmp/tianliangedu/input.txt文件中。
3.2 Maven环境搭建
Maven开发环境搭建,用Eclipse IDE工具,创建一个新的Maven项目。
3.3 Pom配置依赖
修改新建项目的pom.xml的配置文件,将Hadoop的依赖加入进去:
- 配置依赖jar包的坐标,即描述我是谁。
- 指定依赖的仓库
- 具体需要哪些相关依赖
- 配置打包插件
具体配置参考如下:
4.0.0
com.tianliangedu.course
TlHadoopCore
0.0.1-SNAPSHOT
UTF-8
nexus-aliyun
Nexus aliyun
http://maven.aliyun.com/nexus/content/groups/public
org.apache.hadoop
hadoop-client
2.7.4
provided
TlHadoopCore
maven-compiler-plugin
2.3.2
1.8
1.8
UTF-8
maven-assembly-plugin
jar-with-dependencies
com.tl.job009.hdfs.HdfsFileRead
make-assembly
package
assembly
3.4 编码实现
- 实现步骤
- 定义读取的HDFS文件路径
- 用HDFS Java API将HDFS文本文件转化为字符串形式:
1)、先将HDFS文本文件以字节数组形式读取到内存中。
2)、将字节数组转换成字符串。
- 通过控制台将字符串打印出来
- 涉及Hadoop中的类说明
- Configuration
1)、负责HDFS系统的配置文件的加载或者更改配置文件的工具类,将配置文件件加载到内存中。
2)、通过new Configuration()初始化Configuration对象,即将HDFS的默认配置文件加载到内存中,供别的对象使用。
- FileSystem
1)、对HDFS系统的引用,操作HDFS的根类。所有HDFS文件操作均以此类为源头发起。
2)、通过FileSystem.get(new Configuration())初始化针对某集群的FileSystem对象。
- Path
1)、HDFS文件的抽象,与Java IO流中的File对象对等。
2)、通过new Path(hdfsFilePath)得到Path对象。
- FSDataInputStream
1)、HDFS系统的文件字节输入流,类比于Java IO中的InputStream类,实现对HDFS文件的读取。
2)、FileSystem.open(filePath)可以获取HDFS的输入流。
- FSDataOutputStream
1)、HDFS系统的文件字节输出流,类比于Java IO中的OutputStream类,实现对HDFS文件的写入。
2)、FileSystem.create(filePath)可以获取HDFS的输出流。
- 具体代码
- //新建源码包com.tianliangedu.utils,并在其中新建java文件HdfsFileOperatorUtil.java。
- //代码如下:
- package com.tianliangedu.utils;
- import java.io.ByteArrayOutputStream;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.FSDataInputStream;
- import org.apache.hadoop.fs.FileSystem;
- import org.apache.hadoop.fs.Path;
- import org.apache.log4j.Logger;
- /**
- * hdfs 文件操作工具类,从任意的hdfs filepath中读取文本内容
- */
- public class HdfsFileOperatorUtil {
- //添加日志输出能力
- Logger logger = Logger.getLogger(HdfsFileOperatorUtil.class);
- // 加载配置文件到内存对象
- static Configuration hadoopConf = new Configuration();
- /** 从HDFS上读取文件 */
- public static String readFromFile(String srcFile) throws Exception {
- //文件路径的空判断
- if (srcFile == null || srcFile.trim().length() == 0) {
- throw new Exception("所要读取的源文件" + srcFile + ",不存在,请检查!");
- }
- //将文件内容转换成字节数组
- byte[] byteArray = readFromFileToByteArray(srcFile);
- if (byteArray == null || byteArray.length == 0) {
- return null;
- }
- //将utf-8编码的字节数组通过utf-8再进行解码
- return new String(byteArray, "utf-8");
- }
- /**
- * 将指定的文件路径从hdfs读取并转换为byte array.
- *
- * @param srcFile
- * @return
- */
- public static byte[] readFromFileToByteArray(String srcFile)
- throws Exception {
- if (srcFile == null || srcFile.trim().length() == 0) {
- throw new Exception("所要读取的源文件" + srcFile + ",不存在,请检查!");
- }
- //获取hadoopConf对应的hdfs集群的对象引用
- FileSystem fs = FileSystem.get(hadoopConf);
- //将给定的srcFile构建成一个hdfs的路径对象Path
- Path hdfsPath=new Path(srcFile);
- FSDataInputStream hdfsInStream = fs.open(hdfsPath);
- //初始化一块字节数组缓冲区,大小为65536。缓存每次从流中读取出来的字节数组
- byte[] byteArray = new byte[65536];
- //初始化字节数输出流, 存放最后的所有字节数组
- ByteArrayOutputStream bos = new ByteArrayOutputStream();
- // 实际读过来多少
- int readLen = 0;
- //只要还有流数据能读出来,就一直读下去
- while ((readLen = hdfsInStream.read(byteArray)) > 0) {
- bos.write(byteArray,0,readLen);
- //byteArray = new byte[65536];
- }
- //读取完成,将hdfs输入流关闭
- hdfsInStream.close();
- //将之前写到字节输出流中的字节,转换成一个整体的字节数组
- byte[] resultByteArray=bos.toByteArray();
- bos.close();
- return resultByteArray;
- }
- public static void main(String[] args) throws Exception {
- //定义要读入的hdfs的文件路径
- String hdfsFilePath = "/tmp/tianliangedu/input.txt";
- //将文件从hdfs读取下来,转化成字符串
- String result = readFromFile(hdfsFilePath);
- //根据题意,将字符串通过命令行输出
- System.out.println(result);
- }
- }
- 本地运行
1)Hadoop2.x及以后已经支持本地local模式模拟运行hdfs操作
-
- 将输入路径改为windows开发环境的本地路径即可。
- 如:String hdfsFilePath = “E:/temp/input.txt”
- 直接右击运行主类main_class即可,效果如下
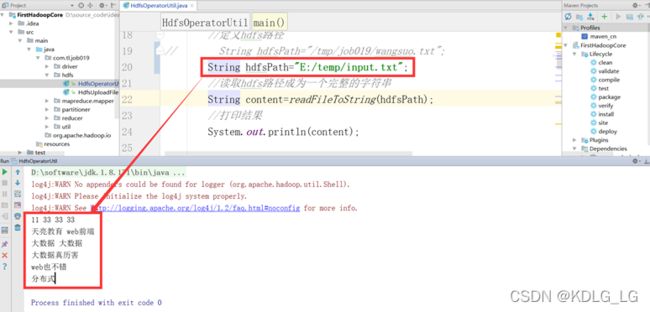
- 将输入路径改为windows开发环境的本地路径即可。
- 标准运行-远程生产环境正式布署运行
- Maven打包
-
右击项目,run as -> maven install进行打包及上传至本地仓库中,生成target目录下的
TlHadoopCore-jar-with-dependencies.jar文件。
- 将运行包发布上传至Hadoop环境
-
通过rz命令,将生成的TlHadoopCore-jar-with-dependencies.jar上传到hdfs环境中。
- 线上测试运行
- 查看验证效果
-
yarn jar TlHadoopCore-jar-with-dependencies.jar com.tianliangedu.utils.HdfsFileOperatorUtil
