【计算机视觉】图像检索
这里写目录标题
-
- 一、图像检索概述
-
- 基于文本的图像检索(TBIR)
- 基于内容的图像检索(CBIR)
- 矢量空间模型(BOW表示模型、Bag of Words)
- 视觉单词
- Bag of features原理
- Bag of features 图像检索流程
- 特征提取
- 学习特征词典
- 对输入特征集进行量化
- 单词的TF-IDF权重
- 倒排表
- 直方图匹配
- 二.代码实现过程
- 三.改进
一、图像检索概述
从20世纪70年代开始,有关图像检索的研究就已开始,当时主要是 基于文本的图像检索技术 (Text-based Image Retrieval,简称 TBIR),利用文本描述的方式描述图像的特征,如绘画作品的作者、年代、流派、尺寸等。到90年代以后,出现了对图像的内容语义,如图像的颜色、纹理、布局等进行分析和检索的图像检索技术,即 基于内容的图像检索 (Content-based Image Retrieval,简称 CBIR)技术。
因此按描述图像内容方式的不同可以分为两类:
基于文本的图像检索(TBIR, Text Based Image Retrieval)
基于内容的图像检索(CBIR, Content Based Image Retrieval)
基于文本的图像检索(TBIR)
基于文本的图像检索方法始于上世纪70年代,它利用文本标注的方式对图像中的内容进行描述,从而为每幅图像形成描述这幅图像内容的关键词,比如图像中的物体、场景等,这种方式可以是人工标注方式,也可以通过图像识别技术进行半自动标注。在进行检索时,用户可以根据自己的兴趣提供查询关键字,检索系统根据用户提供的查询关键字找出那些标注有该查询关键字对应的图片,最后将查询的结果返回给用户。
这种基于文本描述的图像检索方式由于易于实现,且在标注时有人工介入,所以其查准率也相对较高。但是这种基于文本描述的方式所带来的缺陷也是非常明显的:
这种基于文本描述的方式需要人工介入标注过程,使得它只适用于小规模的图像数据,在大规模图像数据上要完成这一过程需要耗费大量的人力与财力
对于需要精确的查询,用户有时很难用简短的关键字来描述出自己真正想要获取的图像
人工标注过程不可避免的会受到标注者的认知水平、言语使用以及主观判断等的影响,因此会造成文字描述图片的差异
基于内容的图像检索(CBIR)
随着图像数据快速增长,针对基于文本的图像检索方法日益凸现的问题,在1992年美国国家科学基金会就图像数据库管理系统新发展方向达成一致共识,即表示索引图像信息的最有效方式应该是基于图像内容自身的。自此,基于内容的图像检索技术便逐步建立起来,并在近十多年里得到了迅速的发展。
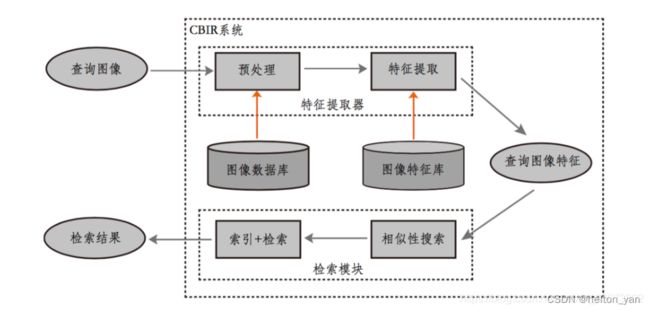
CBIR 利用计算机对图像进行分析,建立图像特征矢量描述(SIFT特征提取 )并存入图像特征库,当用户输入一张查询图像时,用相同的特征提取方法(SIFT)提取查询图像的特征得到查询向量,然后在某种相似性度量准则下计算查询向量到特征库中各个特征的相似性大小,最后按相似性大小进行排序并顺序输出对应的图片。
基于内容的图像检索技术将图像内容的表达和相似性度量交给计算机进行自动的处理,克服了采用文本进行图像检索所面临的缺陷,并且充分发挥了计算机长于计算的优势,大大提高了检索的效率,从而为海量图像库的检索开启了新的大门。
矢量空间模型(BOW表示模型、Bag of Words)
矢量空间模型 是一个用于表示和搜索文本文档的模型。它基本上可以应用于任何对象类型,包括图像。该名字来源于用矢量来表示文本文档,这些矢量是由文本词频直方图构成的。矢量包括了每个单词出现的次数,而且在其他别的地方包含很多 0 元素。由于其忽略了单词出现的顺序及位置,该模型也被称为 BOW 表示模型(Bag of Words)。
通过单词计数来构建文档直方图向量 v,从而建立文档索引。通常,在单词计数时会忽略掉一些常用词,如 “这” “和” “是” 等,这些常用词称为 停用词 。由于每篇文档长度不同,故除以直方图总和将向量归一化成单位长度。对于直方图向量中的每个元素,一般根据每个单词的重要性来赋予相应的权重。通常,数据集(或语料库)中一个单词的重要性与它在文档中出现的次数成正比,而与它在语料库中出现的次数成反比。
最常用的权重是 tf-idf (term frequency-inverse document frequency,词频-逆向文档频率),单词 w 在文档 d 中的词频是:
t f w , d = n w ∑ j n j t f_{w, d}=\frac{n_{w}}{\sum_{j} n_{j}} tfw,d=∑jnjnw
nw是单词 w 在文档 d 中的出现的次数。为了归一化,将n_w除以整个文档中单词的数。
逆向文档频率为:
i d f w , d = log ∣ ( D ) ∣ ∣ { d : w ∈ d } ∣ i d f_{w, d}=\log \frac{|(D)|}{|\{d: w \in d\}|} idfw,d=log∣{d:w∈d}∣∣(D)∣
∣D∣是在语料库 D DD 中文档的数目,分母是语料库中包含单词 w 的文档数 d 。将两者相乘可以得到矢量 v 中对应元素的 tf-idf权重
视觉单词
为了将文本挖掘技术应用到图像中,我们首先需要建立视觉等效单词,通常采用SIFT局部描述子技术。它的思想是将描述子空间量化成一些典型实例,并将图像中的每个描述子指派到其中的某个实例中。这些典型实例可以通过分析训练图像集确定,并被视为视觉单词。所有这些视觉单词构成的集合称为 视觉词汇 ,有时也称为 视觉码本 。对于给定的问题、图像类型,或在通常情况下仅需要呈现视觉内容,可以创建特定的词汇。
从一个训练图像集提取特征描述子,利用一些聚类算法可以构建出视觉单词。聚类算法中最常用的是 KMeans算法。视觉单词并不高端,只是在给定特征描述子空间中的一组向量集,在采用 KMeans进行聚类时得到的视觉单词是聚类质心。用视觉单词直方图来表示图像,则该模型便称为 BOW 模型。
Bag of features原理
Bag of Feature 是一种图像特征提取方法,它借鉴了文本分类的思路(Bag of Words),从图像抽象出很多具有代表性的「关键词」,形成一个字典,再统计每张图片中出现的「关键词」数量,得到图片的特征向量
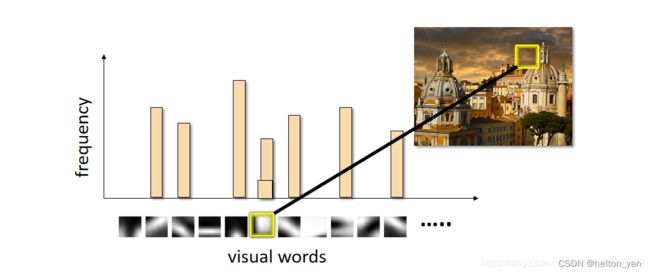
Bag of features 图像检索流程
1 特征提取
2 学习 “视觉词典(visual vocabulary)”
3 针对输入特征集,根据视觉词典进行量化
4 把输入图像转化成视觉单词(visual words)的频率直方图
5 构造特征到图像的倒排表,通过倒排表快速索引相关图像
6 根据索引结果进行直方图匹配
特征提取
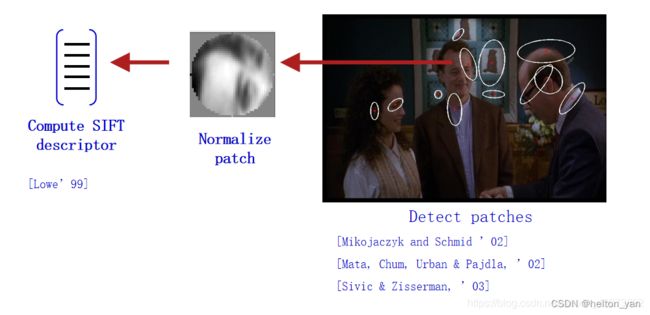
特征提取通常使用 SIFT局部描述子技术,具体过程与上述的视觉单词流程类似

学习特征词典
在提取完图像特征后,下一步是学习特征词典,利用一些聚类算法可以构建出视觉单词,而聚类算法中最常用的是 KMeans 算法。KMeans 算法具体流程在上述视觉单词模块中
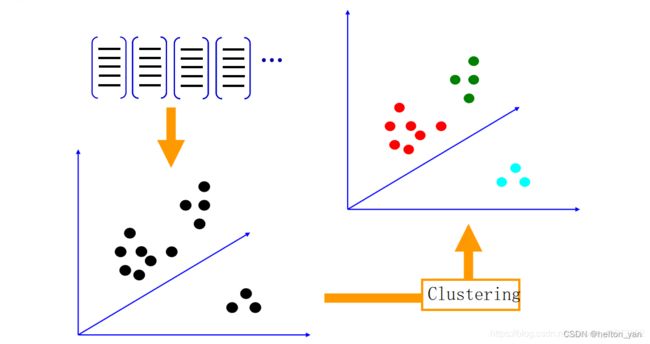
聚类后,就得到了这 k kk 个向量组成的词典,称为visual words(视觉单词)。所有这些视觉单词构成的集合称为 视觉词汇

对输入特征集进行量化
上一步训练得到的字典,是为了这一步对图像特征进行量化。对于一幅图像而言,我们可以提取出大量的「SIFT」特征点,但这些特征点仍然属于一种浅层(low level)的表达,缺乏代表性。因此,这一步的目标,是根据字典重新提取图像的高层特征。
具体做法是,对于图像中的每一个「SIFT」特征,都可以在字典中找到一个最相似的 visual word,这样,我们可以统计一个 k 维的直方图,代表该图像的「SIFT」特征在字典中的相似度频率。
我们匹配图片的「SIFT」向量与字典中的 visual word,统计出最相似的向量出现的次数,最后得到这幅图片的直方图向量
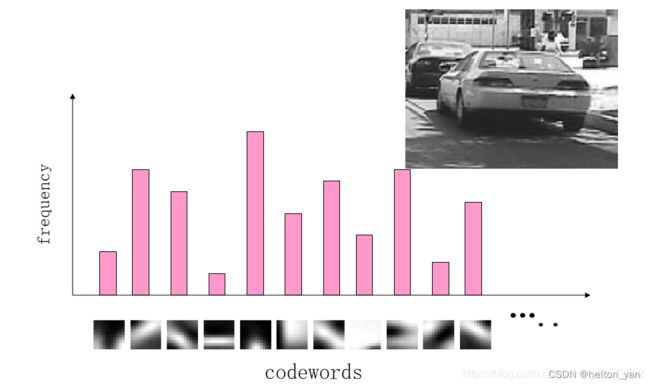
单词的TF-IDF权重
在上述介绍中,在矢量空间模型中提到了单词权重,在文本检索中,不同单词对文本检索的贡献有差异,所以在将输入图像转换为频率直方图时需要根据TF-IDF赋予权值。具体流程在上述视觉单词模块中提及。
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
倒排表
倒排表是一种逆向的索引方法,构造倒排表可以快速索引图像。倒排索引,通过搜索要查询的关键字,查询到跟该关键字相关的所有文档。倒排表可以获得是各视觉单词出现在图像库的哪些图像中。
直方图匹配
最后,根据索引的结果进行直方图匹配,就完成了图像索引。

二.代码实现过程
本次的数据集分为三个部分
1.64_CASIA-FaceV5人脸数据集

2.指纹识别数据集

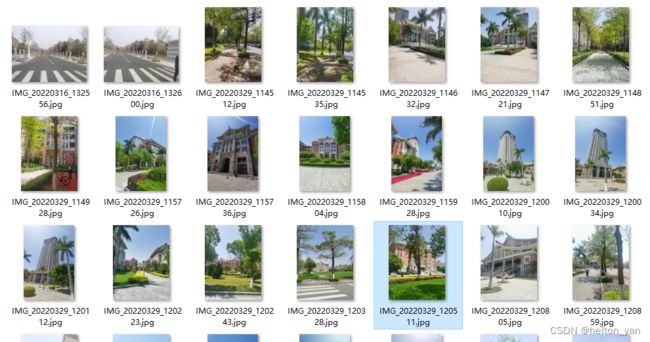
3.校园建筑数据集
代码实现
代码中实现了SIFT和ORB的检测方法:
# 提取图像ORB特征
def extraORBfromImg(ORB, img):
# 关键点检测(kps), 并生成描述符(des
kps, desc = ORB.detectAndCompute(img, mask=None) # 关键点检测
return desc
# 提取图像SIFT特征
def extraSIFTKeyPoints(sift, img):
# 对于 opencv4.4.0 这个版本来说,SIFT方法已经可以直接使用了,
# 因此cv2.xfeatures2d.SIFT_create()不再使用
# 关键点检测(kps), 并生成描述符(des)
kps, des = sift.detectAndCompute(img, None)
# 绘制SIFT关键点
# drawSIFTKeyPoints(img, kps)
return des
基于KMeans的小批量聚类方法:
# 聚类
def KMeansClustering(corner, k):
kmeans = MiniBatchKMeans(n_clusters=k, init='k-means++', batch_size=8192, max_iter=200)
kmeans.fit_predict(corner)
# 聚类中心
centroids = kmeans.cluster_centers_
# # 每条数据所属类别
# labels = kmeans.labels_
return centroids
基于数据集生成词袋模型:
# 生成词袋
def genBOWfromImgs(ORB, root):
# 批处理
desc = []
for img in tqdm(os.listdir(root)):
image = cv2.imread(root + img)
# img,_,_ = utils.auto_reshape(img, 720)
# 只需提取特征点的描述子
# des = extraSIFTKeyPoints(sift, image)
des = extraORBfromImg(ORB, image)
desc.append(des)
# 数据集中所有描述子
descriptors = np.concatenate([_ for _ in desc], axis=0)
print(descriptors.shape)
descriptors = np.load('bdow2.npy')
# 聚类(使用小批量聚类,原因和训练神经网络使用小批量数据相同)
centroids = norm(KMeansClustering(descriptors, 1000))
print(centroids.shape)
np.save('bow_1000.npy', centroids)
return centroids
基于数据集生成数据集每张图像的词袋向量:
# 生成数据集的词袋向量
def extraBOWFeaturefromImgs(ORB, bow, root):
Vec = []
for img in os.listdir(root):
image = cv2.imread(root + img)
# img,_,_ = utils.auto_reshape(img, 720)
# 只需提取特征点的描述子
# des = extraSIFTKeyPoints(sift, image)
des = norm(extraORBfromImg(ORB, image))
# 相似索引矩阵
sim = np.argmax((bow @ des.T).T, 1)
# 生成词袋向量
vec = np.zeros(1000)
for i in sim:vec[i] += 1
Vec.append(vec)
Vec = norm(np.array(Vec))
np.save('./BowVec.npy',Vec)
给定新的图像生成词袋向量:
def img2vec(ORB, bow, bow_vec, img):
# 只需提取特征点的描述子
# des = extraSIFTKeyPoints(sift, img)
des = norm(extraORBfromImg(ORB, img))
# 相似索引矩阵
sim = np.argmax((bow @ des.T).T, 1)
# 生成词袋向量
vec = np.zeros(1000)
for i in sim:vec[i] += 1
vec = norm(vec)
sim_vec = bow_vec @ vec
return sim_vec
行向量归一化(TF):
# 行数据标准化
def norm(x):
if (len(x.shape) == 1):
return x / np.linalg.norm(x)
return x / np.linalg.norm(x,axis=1).reshape(-1,1)
测试
# 这里先生成一个sift检测实例
# sift = cv2.SIFT_create(nfeatures=800)
orb = cv2.ORB_create(1000)
'''train'''
train_set = './jmu/train/'
# 生成词袋
bow = genBOWfromImgs(orb, train_set)
extraBOWFeaturefromImgs(orb, bow, train_set)
'''test'''
train_set = './jmu/train/'
test_set = './jmu/valid/'
img_database = os.listdir('./jmu/train/')
bow = np.load('./bow_1000.npy')
bow_vec = np.load('./BowVec.npy')
sim = []
for img in os.listdir(test_set):
image = cv2.imread(test_set + img)
sim.append(img2vec(orb, bow, bow_vec, image))
sim = np.array(sim)
plt.imshow(sim)
plt.show()
print (img_database[19])
测试结果:
基于词袋模型的人脸识别和指纹识别的效果非常一般,这里就不放结果了,从数据集上分析,一个可能的原因是词袋模型实则只能提取图像中非常表层的纹理特征以及轮廓特征,而并不能提取纹理之上更深层次的抽象语义特征,而我所使用的数据集中每张图像的表层特征都具有非常高的相似性(蓝色背景,人脸的大致轮廓,黑色的指纹轮廓,以及白色的背景)
其他可能的原因有:本人的代码中并没有考虑词向量的IDF,以及一些数据处理技巧,聚类的迭代次数不够,聚类的k选择不当等等。
基于校园数据集的检索效果:


三.改进
ORBSLAM2中提供了一种基于ORB特征的离线词袋库DBow2(现已更新至DBow3),我们可以利用其中的ORBvoc.txt作为我们的词袋模型:

其构造基于树形结构:
第一行中10代表词袋树的分支,6代表树的深度,0,代表相似度,0代表权重。
第二行的0代表节点的父节点,第二个0代表是否叶子结点,这里表示非叶子结点,252-43表示特征描述子(长度为32),最后一个表示权重
而每一个非叶节点是其所有叶节点的聚类中心。
相较于自己构造的词袋,DBow提供的词袋模型包含更为丰富的特征,因此我们在构造图像的词向量时可以直接基于DBoW库提供的离线词袋直接进行构造。