【时序预测完整教程】以气温预测为例说明论文组成及PyTorch代码管道构建
文章目录
- Intuition
- --------------------------- Paper Component ---------------------------
- 1. Abstract
- 2. Introduction
- 3. Time-Series Forecasting
-
- 3.1 Forecasting Horizon
- 3.2 Forecasting Variable
- 3.3 Forecasting Method
- 3.4 Forecasting Task
- 4. Forecasting Methodology
-
- 4.1 Statistical Model
- 4.2 Tree-based Model
- 4.3 Probability Model
- 4.4 RNN-based Model
- 4.5 CNN-Based Model
- 4.6 RNN and CNN-Based Model
- 4.7 Seq2Seq-Baed Model
- 4.8 Transformer-Based Model
- 4.9 BERT-Based Model
- 4.10 GNN-Based Model
- 4.11 Transfer Learning Model
- 4.12 Multimodal-Based Model
- 5. Evaluation Metrics
-
- 5.1 MAE
- 5.2 MSE
- 5.3 MAPE
- 5.4 RMSE
- 5.5 RMSLE
- 6. Data Preprocessing
-
- 6.1 Data Cleaning
- 6.2 Feature Selection
- 6.4 Standardize and Normalize
- 6.5 Sliding Window
- 7. Experiments
- 8. Ablation Study
- 9. Conclusion
- 10. Acknowledgement
- Appendix
- --------------------------- PyTorch Pipeline ---------------------------
- I. 运行环境
- II. 数据集
- III. LSTNet
- IV. 代码说明
- V. 运行流程
- VI. 一些小问题
-
- 数据处理部分
- 模型输出
- 训练循环
- 结语
Intuition
博客之前发布了一些时间序列分类和时间序列相关的教程,但是代码不够规范,比较适合入门。为了更加系统地进行时间序列预测任务的研究,本文介绍了撰写一篇时间序列预测论文应具有的部分,以及Pytorch框架下构建模型进行实验的代码仓库构建。
为了提高灵活性和可复现性,代码遵循开源代码规范,并且尽可能使用通用术语。代码放到一下仓库:https://github.com/datamonday/TimeSeriesMoonlightBox。目前只更新了LSTM,GRU和LSTNet模型,之后会增加更多的模型,也会更新TensorFlow2 Pipeline。如有问题,欢迎指正。时间序列预测交流群:1028633890。
由于这学期的课程都是基于PyTorch的,所以决定从一直使用的TensorFlow转PyTorch。通过简单地对比发现,二者之间的差异主要在管道的构建上。TensorFlow封装得更好,训练更加方便,但是难以扩展。PyTorch的灵活性更好,但对于初学者可能有些无从下手。最近阅读了LSTNet,Informer,Autoformer以及Baidu KDD Cup22 的baseline的论文和代码库,非常推荐阅读他们的论文。通过这三个仓库,基本理清了torch框架下构建时间序列预测管道的流程,解决了之前的一些困惑,故总结在此,希望能给需要的同学提供帮助。这些论文的翻译也在之前的博客分享过了,感兴趣的可以在主页搜索。
本文内容包括:首先介绍撰写一篇时间序列预测论文应该考虑的部分,最后介绍代码仓库的搭建。
--------------------------- Paper Component ---------------------------
1. Abstract
摘要部分。不需要标号。
2. Introduction
本文以气温预测为例,说明在torch框架下构建时间序列预测建模的流程。更具体地:
- 模型:LSTM,GRU,LSTNet
- 领域:时间序列预测(气温预测)
- 预测范围:单步预测,多步预测
- 预测变量:单变量预测,多变量预测
- 预测方式:直接预测,递归(滚动)预测
- 预测任务:多变量输入单变量预测,多变量输入多变量预测,单变量输入单变量预测等等
说明:本文研究的问题仅适用于同质数据建模。简单地说,比如一个监测站收集的历年气温数据(一个csv文件或者可以无歧义地合并为一个csv文件)。对于多个监测站的异质数据或者说多个域(domain)的数据,应该考虑用GNN或者其他方式建模,将在后续的文章讨论,本文暂不涉及。
3. Time-Series Forecasting
3.1 Forecasting Horizon
对于预测范围(horizon),一般分为单步预测和多步预测。
- 单步预测(single-step forecasting):例如预测下一时刻的气温。
- 多步预测(multi-step forecasting):例如预测未来H个时间步(timestamp)的气温。
3.2 Forecasting Variable
对于预测变量,一般分为单变量预测和多变量预测。
- 单变量预测(single-variable forecasting):即预测一个变量,例如只预测气温。
- 多变量预测(multi-variable forecasting):即预测多个变量,例如预测气温,风速,风向等。
对于多变量预测的情况,从之前博客的评论区来看,疑问比较多的是如何构建数据的标签。一般有两种处理方式:使用滚动预测方式,模型在训练时的输出维度是 [batch size, feature num] ,在进行预测的时候,使用滚动预测的方式,可以参考LSTNet的源码。第二种方式是将多个变量的多个时间步进行flatten操作,将向量拼接为新的维度 [batch size, feature num * multi steps],在得到预测结果之后,重新解释为各个变量的多步预测结果。
3.3 Forecasting Method
对于预测方法,一般分为直接预测和递归(滚动)预测。这常常是在多步预测场景下使用。
- 直接预测(direct forecasting):一次性输出H个时间步的预测值。现在更为常用。
- 滚动预测(rolling forecasting):递归预测,上一时刻的预测值当做下一时刻的输入,直到预测到第H个输出。这可能造成误差累计。
3.4 Forecasting Task
对于预测任务,可以根据上述三种情景,进行组合,常用的有:
- 单变量输入-单变量输出-单步-直接预测
- 单变量输入-单变量输出-多步-直接预测
- 单变量输入-单变量输出-多步-滚动预测
- 多变量输入-单变量输出-单步-直接预测
- 多变量输入-单变量输出-多步-直接预测
- 多变量输入-单变量输出-多步-滚动预测
- 多变量输入-多变量输出-单步-直接预测
- 多变量输入-多变量输出-多步-直接预测
- 多变量输入-多变量输出-多步-滚动预测
4. Forecasting Methodology
本部分概述了目前用于时间序列预测建模的常用模型。
4.1 Statistical Model
常用的统计模型有AR,ARMA,ARIMA等。
4.2 Tree-based Model
常用的树模型有XGBoost,CatBoost,LightGBM等。
4.3 Probability Model
常用概率模型有DeepAR,DeepState,MQ-RNN,Prophet等。
4.4 RNN-based Model
基于RNN的模型有RNN,LSTM,GRU。
4.5 CNN-Based Model
基于CNN的模型有WaveNet。最开始用于语音识别,使用空洞因果卷积增大关注的输入序列长度。
4.6 RNN and CNN-Based Model
基于CNN和RNN的模型有:CNN-LSTM,LSTM-CNN,LSTM-RNN,ConvLSTM,LSTNet等。
4.7 Seq2Seq-Baed Model
基于序列到序列的模型,其组成通常包括Encoder,Decoder及注意力机制。
4.8 Transformer-Based Model
与之前的注意力不同,Transformer引入了多头自注意力(Self-Attention)机制。基于Transformer的模型有:Transformer,LogSparseTransformer,Informer,Autoformer,SpaceTimeformer等。
4.9 BERT-Based Model
原生BERT只使用了Transformer的编码器部分,并且是双向的,用于NLP任务。其贡献主要在于自监督(Self-Supervised)的预训练和微调(Pretrain and Fine-Tune)的训练方式,提高了模型性能。
4.10 GNN-Based Model
对于空间上有关联性的预测问题,常常使用图神经网络(Graphic Neural Network)建模。根据输入数据的不同,可以分为同质(homogeneous)图和异质(heterogeneous)图。
4.11 Transfer Learning Model
基于迁移学习的模型常常用于多个域的数据建模。例如不同气象数据监测站。常用的方法是域适应(Domain Adaptation)和域泛化(Domain Generalization),这也是目前比较火热的研究方向。
4.12 Multimodal-Based Model
基于多模态数据的模型不仅仅使用表格数据,还通常结合图片、音频等数据,模型中分别使用不同的网络提取特征,然后进行特征融合,最后将提取得到特征输入到下游预测网络以进行预测。
5. Evaluation Metrics
本部分介绍时间序列预测任务中常用的评估指标。
5.1 MAE
5.2 MSE
5.3 MAPE
5.4 RMSE
5.5 RMSLE
此外,还有一些针对具体任务的评估指标,此处不再介绍。
6. Data Preprocessing
本部分介绍数据预处理方法。
6.1 Data Cleaning
为提高模型鲁棒性,一般先要处理数据中的异常值和填充缺失值。
6.2 Feature Selection
为了降低特征共线性,降低过拟合风险,通常先选择模型输入特征。关于特征选择方法的原理和代码,在之前的博文已经介绍过了,感兴趣的可以下主页搜索特征选择方法。
6.4 Standardize and Normalize
关于数据标准化和归一化需要注意的是只能使用训练集计算均值、方差或者最大值、最小值,然后将其应用到验证集和测试集上,以防止数据泄露。
6.5 Sliding Window
滑动窗口是常用的时间序列预测样本构建方法的原理和代码,在之前的博客也已经介绍过了,感兴趣的可以主页搜索滑动窗口。
7. Experiments
实验部分一般需要给出训练配置,数据介绍以及对预测任务及结果给出合理的分析。
8. Ablation Study
消融研究一般用于探索模型的鲁棒性,更充分地证明模型的优异性能。常有的包括,多个数据集对比,预测步长的影长,序列长度的影响,模型超参数的影响,网络架构的影响等等。
9. Conclusion
结论部分。
10. Acknowledgement
致谢部分。不需要标号。感谢基金支持、研究者的帮助等。
Appendix
实验过程中,重要程度较低、不适合放到正文中的一些实验结果分析或者具体地说明。
--------------------------- PyTorch Pipeline ---------------------------
I. 运行环境
- OS:Windows 11
- Python:3.8.0
- PyTorch:1.11.0
具体地,可查看 requirements.txt。
II. 数据集
- 名称:Jena Climate Dataset
- 地址:Weather Station, Max Planck Institute for Biogeochemistry in Jena, Germany
- 范围:Jan 10, 2009 - December 31, 2016
- 下载:https://www.bgc-jena.mpg.de/wetter/
- 分辨率:10分钟间隔采样
- 数据量:42万条记录
- 特征数量:14个变量
- 目标变量:
'T (degC)'
数据集概览:
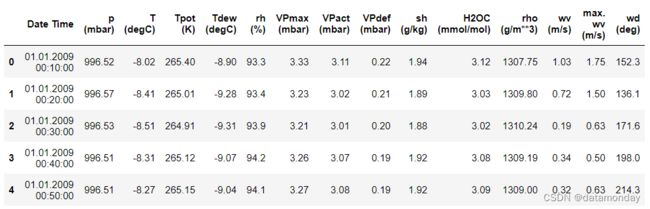
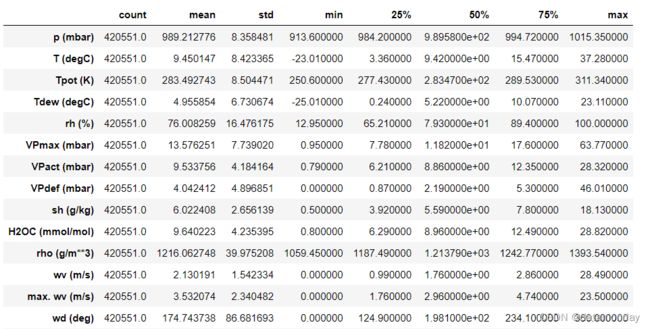
III. LSTNet
- 模型介绍:LSTNet详解
- 论文翻译:LSTNet:结合 CNN、RNN 以及 AR 的时间序列预测模型
- 开源代码:https://github.com/laiguokun/LSTNet
IV. 代码说明
代码文件结构如下图所示:
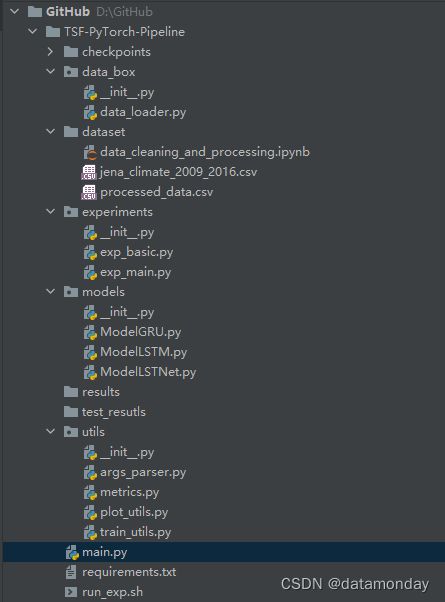
文件说明:
checkpoints/:检查点文件dataset/:存放数据集data_cleaning_and_processing.ipynb:数据预处理脚本,包括:填充缺失值,替换异常值
data_box/:数据处理相关代码data_loader.py:数据标准化,滑动窗口生成样本
experiments/:训练、测试循环代码,类似于TF的train和predictexp_basic.py:训练基类exp_main.py:训练主类
models/:模型库ModelGRU.py:GRU模型架构ModelLSTM.py:LSTM模型架构ModelLSTNet.py:LSTNet模型架构
results/:存放训练结果test_results/:存放测试结果utils/:通用工具args_parser.py:参数配置metrics.py:模型评估指标定义plot_utils.py:绘图函数train_utils.py:训练工具,包括学习率调整,earlystopping等
main.py:开始训练和测试run_exp.sh:运行不同配置实验的脚本文件
V. 运行流程
模型的运行流程,可以在 exp_main.py 的 Experiment 类窥见一斑。
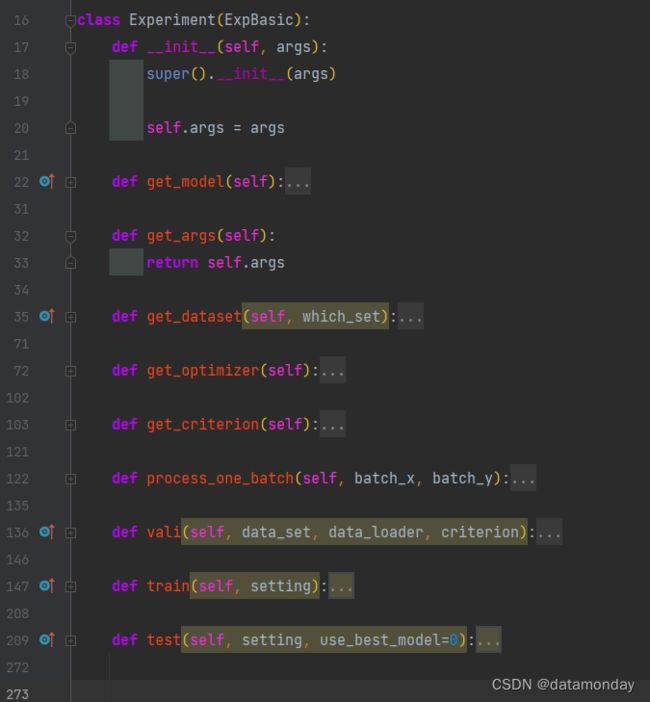
进一步抽象为:
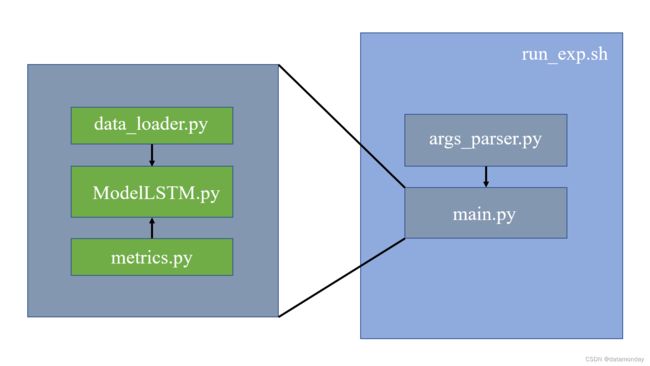
运行试验:
- 命令行运行:
./run_exp.sh - IDE运行:
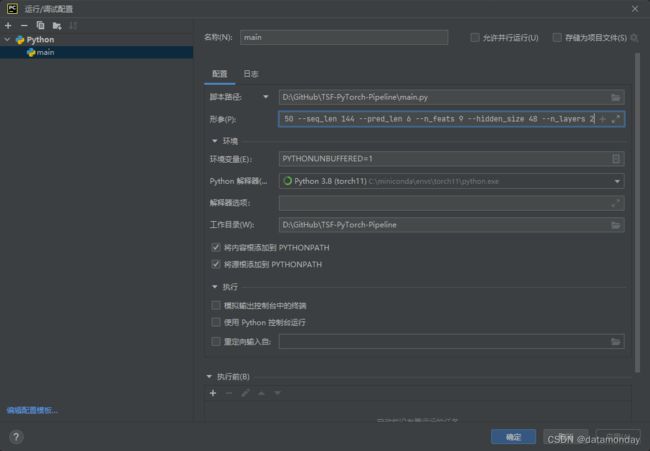
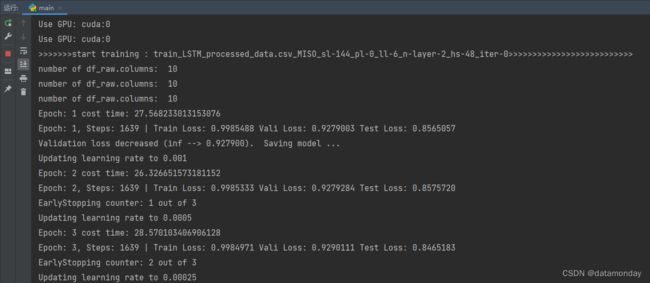
运行状态:
VI. 一些小问题
数据处理部分
data_loader.py 中的 Data2Sample 类继承自PyTorch中的 torch.utils.data.Dataset 类,其有一个 __read_data__ 方法和 __getitem__ 方法。其结合 DataLoader 类可以实现迭代器批次读取操作,降低内存占用。类似TensorFlow中的 Data.Dataset 类。
在 Data2Sample 类的 __getitem__(self, index) 方法中,返回的样本和样本标签的特征数量是一样的,这与常规的Python直接处理方式不同,容易引起困惑,比如在多变量输入单变量输出的预测问题中。其实这样适用范围更广,实际使用的时候,可以对批次数据进行截取,比如只截取一维特征列用于单变量预测问题。在本文代码的实现中,截取操作位于 exp_main.py 中的 Experiment 类的 process_one_batch(self, batch_x, batch_y) 方法中。如以下代码所示:
def __getitem__(self, index):
# start and end index of a single sample data_boxes.
s_begin = index
s_end = s_begin + self.seq_len
# start and end index of a single sample label. The label_len param can be set zero.
r_begin = s_end - self.label_len
r_end = r_begin + self.label_len + self.pred_len
# shape: two dim without batch size, [seq_len, n_feats]
seq_x = self.data_x[s_begin:s_end]
# shape: two dim without batch size, [pred_len, n_feats]
seq_y = self.data_y[r_begin:r_end]
# print(f'seq_x.shape: {seq_x.shape}, seq_y.shape: {seq_y.shape}.')
return seq_x, seq_y
def process_one_batch(self, batch_x, batch_y):
batch_x = batch_x.float().to(self.device)
batch_y = batch_y.float()
# model prediction values
prediction = self.model(batch_x)
# which dimension(variable) to forecast
f_dim = -1 if self.args.task == 'MISO' else 0
batch_y = batch_y[:, -self.args.pred_len:, f_dim:].float().to(self.device)
prediction = prediction[..., :, f_dim:].float()
return prediction, batch_y
注意上面代码块中 f_dim 即为截取的目标特征列,在进行数据处理的时候(Data2Sample 类)已经将目标特征列放到最后一列了,所以在单变量预测任务中,只截取最后一列是没有问题的。
模型输出
PyTorch的模型输出与TensorFlow不同,往往需要自己调整。模型通常通过类定义,前向传播在 forward 方法中完成。
def forward(self, input_seq):
# input shape: (batch_size, seq_len, input_size)
batch_size, seq_len = input_seq.shape[0], input_seq.shape[1]
h_0 = torch.randn(self.num_directions * self.num_layers, batch_size, self.hidden_size).to(self.device)
c_0 = torch.randn(self.num_directions * self.num_layers, batch_size, self.hidden_size).to(self.device)
# h_0 = torch.randn(self.num_directions * self.num_layers, batch_size, self.hidden_size)
# c_0 = torch.randn(self.num_directions * self.num_layers, batch_size, self.hidden_size)
# output shape: (batch_size, seq_len, num_directions * hidden_size)
output, hidden = self.lstm(input_seq, (h_0, c_0))
# pred shape: (batch_size, seq_len, output_size)
pred = self.linear(output)
# out_var=1 表示单变量预测
pred = pred[:, -self.output_size:, -self.out_var:]
return pred
上述代码块中,模型输出的维度是 [batch_size, seq_len, output_size],经过调整后输出的维度变为:pred[:, -self.output_size:, -self.out_var:] 。其中第二个所以表示截取预测序列长度个输出,第三个所以表示截取变量预测个数。
训练循环
在PyTorch中需要自己编写训练循环,这与TensorFlow不同。通常由两层for循环组成,外层处理epoch,内层处理batch。这部分就是触类旁通的,各个任务都是大同小异。
def train(self, setting):
train_data, train_loader = self.get_dataset(which_set='train')
vali_data, vali_loader = self.get_dataset(which_set='val')
test_data, test_loader = self.get_dataset(which_set='test')
path = os.path.join(self.args.checkpoints, setting)
if not os.path.exists(path):
os.makedirs(path)
time_now = time.time()
train_steps = len(train_loader)
early_stopping = EarlyStopping(patience=self.args.patience, verbose=True)
model_optim = self.get_optimizer()
criterion = self.get_criterion()
for epoch in range(self.args.train_epochs):
iter_count = 0
train_loss = []
self.model.train()
epoch_time = time.time()
for i, (batch_x, batch_y) in enumerate(train_loader):
iter_count += 1
model_optim.zero_grad()
batch_pred, batch_truth = self.process_one_batch(batch_x, batch_y)
loss = criterion(batch_pred, batch_truth)
train_loss.append(loss.item())
loss.backward()
model_optim.step()
if (i + 1) % 100 == 0:
print("\titers: {0}, epoch: {1} | loss: {2:.7f}".format(i + 1, epoch + 1, loss.item()))
speed = (time.time() - time_now) / iter_count
left_time = speed * ((self.args.train_epochs - epoch) * train_steps - i)
print('\tspeed: {:.4f}s/iter; left time: {:.4f}s'.format(speed, left_time))
iter_count = 0
time_now = time.time()
print("Epoch: {} cost time: {}".format(epoch + 1, time.time() - epoch_time))
train_loss = np.average(train_loss)
vali_loss = self.vali(vali_data, vali_loader, criterion)
test_loss = self.vali(test_data, test_loader, criterion)
if self.args.verbose > 0:
print("Epoch: {0}, Steps: {1} | Train Loss: {2:.7f} Vali Loss: {3:.7f} Test Loss: {4:.7f}".format(
epoch + 1, train_steps, train_loss, vali_loss, test_loss))
early_stopping(vali_loss, self.model, path)
if early_stopping.early_stop:
print("Early stopping")
break
adjust_learning_rate(model_optim, epoch + 1, self.args)
best_model_path = path + '/' + 'checkpoint.pth'
self.model.load_state_dict(torch.load(best_model_path))
结语
具体地可以查看代码仓库,个人认为弄清楚数据处理步骤,模型输出和编写训练循环是入门的第一步。欢迎指出问题和提出意见,看到之后会第一时间解答。