自然语言处理中的语言模型与预训练技术的总结
目录
0. 背景
1. 统计语言模型(Statistical Language Model)
马尔科夫假设(Markov Assumption)
N-Gram模型
拉普拉斯平滑(Laplace Smoothing)
语言模型的评价标准(n如何选取?)
2.神经网络语言模型(NNLM 模型)
3. RNNLM模型
4. 静态预处理技术
4.1 Word2Vec
4.2.GloVe(Global Vector)
4.3. FastText
静态预处理小结
5. 动态预训练技术
5.1. ELMo 模型
5.2. GPT 模型
5.3 BERT 模型
6. 新式预训练技术
6.1 RoBERTa
6.2 structBERT
6.3 DeBERTA
6.4 XLNet模型
6.5 ConvBERT
7. 其它
7.1 独热表征/表示(one-hot representation)
7.2 分布式表征/表示(distributed representation)
7.3 统计语言模型的一个例子
7.4 N-Gram模型在自然语言中的应用
7.4 朴素贝叶斯方法与N-gram语言模型的关系
7.5 你认为当下语言模型(Language Model)的定义是什么?
8.参考文献
0. 背景
在现在的自然语言处理(Natural Language Processing) 中,一个句子通常是被看成一系列词语的全排列,这些词语能够形成各种不同的组合状态,比如:
- 我 在 上海 迪斯尼
- 在 我 上海 迪斯尼
- 上海 我 在 迪斯尼
- 上海 在 我 迪斯尼
- 。。。
在这些所有可能的排列的情况中,只有很少一部分(由于语言的多样性,不一定只有一种可能是合法)是可以被人理解的,那么该如何衡量一个词语序列是否是可被理解,或者说怎样的词语序列是合法的?就是语言模型(Language Model 简称LM)。
语言模型:给每一个句子赋予一个概率,合法的句子得到概率比较大,而不合法的句子得到的概率比较小,这样只需要从所有可能的情况中选取概率最大的那种组合,我们就能够得到合法的句子了;比如机器翻译、语音识别得到若干候选之后,可以利用语言模型挑一个尽量靠谱的结果。
应用语言模型几个例子:
在机器翻译中:
P(high winds tonite) > P(large winds tonite)
拼写检查中:
比如这一句话:The office is about fiIeen minuets from my house
显然 P(about fiIeen minutes from) > P(about fiIeen minuets from)
语音识别中:
比如I saw a van 和eyes awe of an听上去差不多,但是P(I saw a van) >> P(eyes awe of an)
1. 统计语言模型(Statistical Language Model)
要判断一段文字是不是一句自然语言,可以通过确定这段文字的概率分布来表示其存在的可能性。 语言模型中的词是有顺序的,给定m个词看这句话是不是一句合理的自然语言,关键是看这些词的排列顺序是不是正确的。所以统计语言模型的基本思想是计算条件概率。
句子通常由不同的最小单元组成,在中文中是字或是词,在英文中就是单词了,一个简单的思想就是知道了每个统计单元( )的出现概率,乘起来不就OK了。下面是形式化的表述方式:
)的出现概率,乘起来不就OK了。下面是形式化的表述方式:
![]()
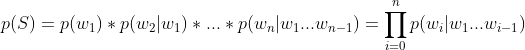
当 i = 0 时 ,![]() 一般w0 表示句子开始标志符号。P(S)被称为语言模型,即用来计算一个句子概率的模型。
一般w0 表示句子开始标志符号。P(S)被称为语言模型,即用来计算一个句子概率的模型。
假设词表的大小为100,000,那么n-gram模型的参数数量![]() ,n越大,模型越准确,也越复杂,需要的计算量越大。
,n越大,模型越准确,也越复杂,需要的计算量越大。
缺点:
- 參数空间过大:条件概率
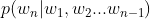 的可能性太多,无法估算,不可能有用;
的可能性太多,无法估算,不可能有用; - 数据稀疏严重:对于非常多词对的组合,在语料库中都没有出现,依据最大似然估计得到的概率将会是0。
马尔科夫假设(Markov Assumption)
为了解决參数空间过大的问题。引入了马尔科夫假设:随意一个词出现的概率只与它前面出现的有限的一个或者几个词有关。
如果一个词的出现仅依赖于它前面出现的一个词,那么:
![]()
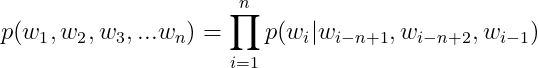
马尔科夫假设中很重要的一点是有限视野假设,即每一个状态只与它前面的个状态有关,这被称为 n 阶马尔可夫链
N-Gram模型
基于马尔科夫假设,提出了n-gram模型如下:
- 当
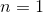 时,每个词的出现只与自己有关,因此每个词相互独立,被称之为Unigram
时,每个词的出现只与自己有关,因此每个词相互独立,被称之为Unigram

- 当
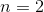 时,每个词的出现只与前一个词有关,被称为Bigram
时,每个词的出现只与前一个词有关,被称为Bigram
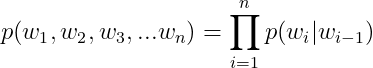
- 当
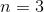 时,每个词的出现只与前两个词有关,被称为Trigram
时,每个词的出现只与前两个词有关,被称为Trigram
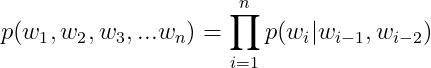
所以n-gram的n表示下一个单词的出现依赖于前个单词,这个n可以根据具体情况来取,但是一般Unigram、Bigram、Trigram比较常用,n太大也会出现上面提到的问题。
优点:
- (1) 采用极大似然估计,参数易训练
- (2) 完全包含了前 n-1 个词的全部信息
- (3) 可解释性强,直观易理解。
缺点:
- (1) 缺乏长期依赖,只能建模到前 n-1 个词
- (2) 随着 n 的增大,参数空间呈指数增长
- (3) 数据稀疏,难免会出现OOV的问题
- (4) 单纯的基于统计频次,泛化能力差。
拉普拉斯平滑(Laplace Smoothing)
拉普拉斯平滑主要是用来解决零概率问题,在这个模型中,当某个单词没有在预料库中出现(OOV)导致MLE计算概率时分子分母均为0,导致模型崩溃。以及上面提到的,当某几个单词的序列没有出现在语料中时,也会出现这个问题,因此引出了拉普拉斯平滑。
即在分母加上语料库的大小V,在分子加上1,分子+1是防止概率为0,分母+分类数是为了使得所有概率相加等于1。
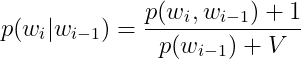
当然也可以在分母加上语料库的大小kV,在分子加上k,k是一个超参。
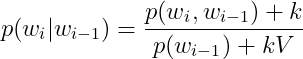
这样就保证所有的概率均大于0,不会出现零概率问题,同时也保证了概率的归一化。平滑技术在朴素贝叶斯中也有应用。
常见的平滑技术有(这里不展开描述,感兴趣的可以自行搜索了解):
- 加法平滑
- 古德-图灵(Good-Turing)估计法
- Katz平滑方法
- Jelinek-Mercer平滑方法
- Witten-Bell平滑方法
- 绝对减值法
- Kneser-Ney平滑方法
语言模型的评价标准(n如何选取?)
在此引入困惑度的概念(Perplexity),Perplexity衡量了一个语言模型的好坏,Perplexity的计算公式如下:
![]()
![]()
![]() 是平均对数似然函数,困惑度越小,模型越好。
是平均对数似然函数,困惑度越小,模型越好。
2.神经网络语言模型(NNLM 模型)
使用统计语言模型变得困难的基本问题是维度灾难(curse of dimensionality),2003 年 Bengio 提出的 NNLM 是早期使用神经网络实现语言模型的经典模型。
NNLM 使用神经网络来搭建语言模型,并且优化后的模型的副产品就是词向量。NNLM模型分为三部分:向量到隐藏层的映射;隐藏层到输出层的映射。

输入:n-1个之前的word(用词典库V中的index表示)
映射:通过|V|*D的矩阵C映射到D维
隐层:映射层连接大小为H的隐层
输出:输出层大小为|V|,表示|V|个词中每个词的概率
网络第一层:将 ![]() 这n-1个向量首尾相接拼起来,形成一个(n-1)*m维的向量,记为输出x。
这n-1个向量首尾相接拼起来,形成一个(n-1)*m维的向量,记为输出x。
网络第二层:就是神经网络的隐藏层,直接使用 d + Hx 计算得到,H是权重矩阵,d是一个偏置向量。然后使用tanh作为激活函数。
网络第三层:输出一共有|V|个节点,每个节点 表示下一个词为i的未归一化log概率,最后使用softmax激活函数将输出值y归一化成概率。
表示下一个词为i的未归一化log概率,最后使用softmax激活函数将输出值y归一化成概率。
神经网络语言模型(NNML)_solitude23的博客-CSDN博客_神经网络语言模型详解
主要贡献是创见性地将模型的第一层特征映射矩阵当作词的文本表征,从而开创了将词语表示向向量形式的模式,这直接启发了后来的word2vec
3. RNNLM模型
RNNLM 论文:《Recurrent neural network based language model》
论文地址: https://www.fit.vutbr.cz/research/groups/speech/publi/2010/mikolov_interspeech2010_IS100722.pdf
4. 静态预处理技术
以 Word2Vec 为代表的静态预训练技术将每一个词表示成词向量,并将其语义通过上下文来表征,其理论基础来自 1954 年 Harris提出的分布假说:上下文相似的词,其语义也相似
这些静态预训练技术的贡献远不只是给每一个词赋予一 个分布式的表征,它开启了一种全新的模型训练方式———迁移学习。使用词向量方法学习到的词语表征,初始化下游任 务网络结构的第一层,能够为下游任务带来显著的效果提升, 以至于这种做法早已成为业内的标配,极大地促进了自然语 言处理领域的发展.
4.1 Word2Vec
2013 年 Mikolov 发布的 Word2Vec 针对 NNLM 存在的问题,提出使用语言模型作词量.Word2Vec 对 NNLM 的优化主要体现在模型结构和训练技巧两方面。
为了简化模型结构,Word2Vec 提出 CBOW 和 Skip-gram两种模型结构。
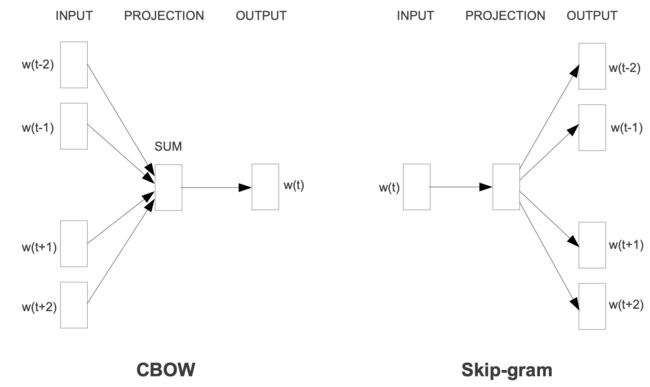
优化训练技巧主要针对输出层的普通 Softmax 计算量过大的问题,使用了 Hierarchical Softmax 和负采样技术(Negative Sampling).
4.2.GloVe(Global Vector)
CBOW/Skip-Gram 是一个local context window的方法,比如使用NS来训练,缺乏了整体的词和词的关系,负样本采用sample的方式会缺失词的关系信息。
另外,直接训练Skip-Gram类型的算法,很容易使得高曝光词汇得到过多的权重
Global Vector融合了矩阵分解Latent Semantic Analysis (LSA)的全局统计信息和local context window优势。融入全局的先验统计信息,可以加快模型的训练速度,又可以控制词的相对权重。
相比 Word2Vec,GloVe 主要利用词语的共现信息构建模型,它的训练主要分为统计共现矩阵和训练获取词向量两个步骤。
我的理解是skip-gram、CBOW每次都是用一个窗口中的信息更新出词向量,但是Glove则是用了全局的信息(共线矩阵),也就是多个窗口进行更新
具体参考下面博客
理解GloVe模型(Global vectors for word representation)_饺子醋的博客-CSDN博客
4.3. FastText
Word2Vec 和 GloVe 都是使用无监督数据得到词向量,而 FastText 则是利用带有监督标记的文本分类数据完成训练。
FastText的网络结构与CBOW基本一致,均使用了Hierachical softmax技巧来加速训练。其模型结构与普通的CBOW在输入层和输出层有所不同:在输入层,CBOW输入的是窗口中除目标词外的所有其它词,而FastText为了利用更多的语序信息,增加了N-Gram的输入信息;在输入层,CBOW的预测目标是语境中的中心词,而FastText的预测目标是输入文本的类型,因此也称FastText是一个监督模型。
FastText 最大的特点在于其预测速度有较大优势,在它的文献中对这一点也做了详细的实验验证。在一些分类数据集上,FastText 通常可以把要耗时几小时甚至几天的模型训练 时间大幅压缩到几秒钟
Fasttext的两篇论文地址
Enriching Word Vectors with Subword Information
Bag of Tricks for Efficient Text Classification
静态预处理小结
以Word2Vec为代表的静态预处理技术将一个词表示称词向量,并将其语义通过上下来表征,其理论来自1954年Harris提出的分布假说:上下文相似的词,其语义也相似。
它开启了一种全新的模型训练方式--迁移学习,极大地促使了自然处理领域的发展。
[1] Harris Z S . Distributional Structure[J]. Springer Netherlands, 1981.
然而这种静态的词向量技术无法较好地处理一词多义问题,为此,出现了一种动态的预训练技术方案
5. 动态预训练技术
模型训练一般包含两阶段Unsupervised pre-training和Supervised fine-tuning
5.1. ELMo 模型
为了解决一词多义的问题,ELMo通过使用针对语言模型训练好的双向LSTM来构建文本表示,由此捕捉上下文相关的词义信息。ELMo通过使用两层双向LSTM来训练语言模型,不仅考虑了上文信息,也融合了下文信息。ELMo是一种特征抽取式的预训练模型。其主要贡献是提供了一种新的文本表征的思路;在大规模无监督数据上训练预训练语言模型,并将其迁移到下游特定任务中使用。
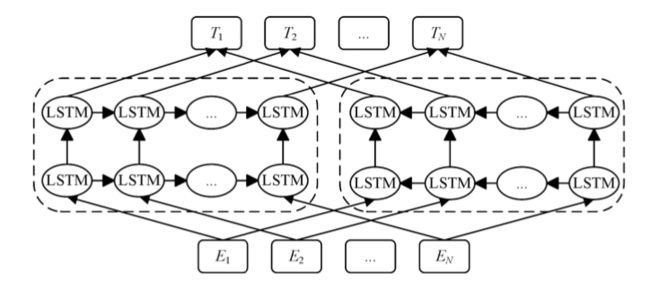
5.2. GPT 模型
2018年,GPT(generative pre-training),是指的生成式的预训练模型。GPT 使用 Transformer 的Decoder 结构,并对 Transformer Decoder 进行了一些改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT 只保留了 Mask Multi-Head Attention,如下图所示。GPT的思想跟Elmo, BERT和XLNET基本保持一致,同样包括两阶段的训练,包括两阶段的训练,第一阶段是预训练,即在大型未标注的语料上进行预训练,第二阶段是fine-tuning,即将预训练的模型迁移到具体的NLP任务,进行模型微调。下图是GPT模型结构图。
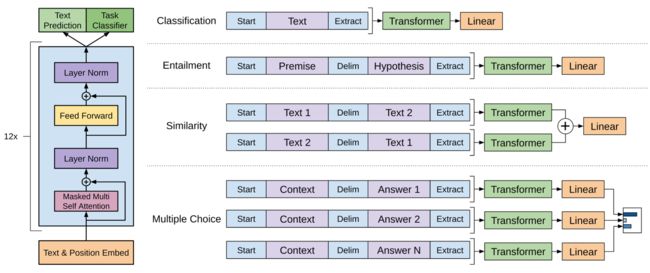 左边是Transformer的结构图用于训练的。右边是具体的NLP任务,把有结构的输入向量化并且输入到预训练模型中,最后在模型加上全连接和SoftMax层输出。
左边是Transformer的结构图用于训练的。右边是具体的NLP任务,把有结构的输入向量化并且输入到预训练模型中,最后在模型加上全连接和SoftMax层输出。
GPT 预训练时利用上文预测下一个单词,ELMO和BERT (下一篇将介绍)是根据上下文预测单词,因此在很多 NLP 任务上,GPT 的效果都比 BERT 要差。但是 GPT 更加适合用于文本生成的任务,因为文本生成通常都是基于当前已有的信息,生成下一个单词。它的优点是:1)RNN所捕捉到的信息较少,而Transformer可以捕捉到更长范围的信息。2)计算速度比循环神经网络更快,易于并行化。3)实验结果显示Transformer的效果比ELMo和LSTM网络更好。它的缺点是:1)对于某些类型的任务需要对输入数据的结构作调整。2)对比BERT,没有采取双向形式,削弱了模型威力。
无监督预训练(Unsupervised pre-training)公式:
给定一个无监督的标记集 ![]() , 我们使用标准语言建模目标来最大化以下可能性:
, 我们使用标准语言建模目标来最大化以下可能性:

其中k是上下文窗口的大小,条件概率P使用带参数Θ的神经网络建模。这些参数使用随机梯度下降法(stochastic gradient descent)进行训练。
在GPT的实验中,使用多层Transfomer decoder作为语言模型,它是Transformer的变体。该模型在输入上下文标记上应用多头自我注意操作,然后是位置前馈层,以在目标标记上产生输出分布:
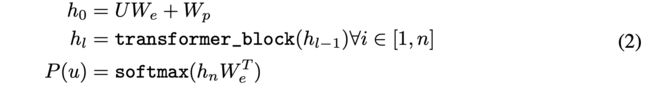
其中 ![]() 是令牌的上下文向量,n是层数(论文时12层),
是令牌的上下文向量,n是层数(论文时12层),![]() 是令牌嵌入矩阵,
是令牌嵌入矩阵,![]() 是位置嵌入矩阵。
是位置嵌入矩阵。
有监督的微调(Supervised fine-tuning)
预训练后,还要根据具体的下游的监督目标任务进行调整参数。假设一个带标签的数据集C,其中每个实例由一系列输入标记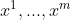 ,以及对应的标签y。输入预先训练的模型,以获得最终Transformer block的激活,然后加上一个带有参数
,以及对应的标签y。输入预先训练的模型,以获得最终Transformer block的激活,然后加上一个带有参数![]() 的线性输出层以预测y:
的线性输出层以预测y:
注意:这里的![]() 和上面的无监督训练时候
和上面的无监督训练时候![]() 不一样
不一样
![]()
这为我们提供了以下最大化的目标:

我们还发现,将语言建模作为微调的辅助目标有助于学习(a)改进监督模型的泛化,以及(b)加速收敛。这与之前的工作是一致的,他们也观察到,通过这样一个辅助目标,绩效有所提高。具体而言,我们优化了以下目标(权重λ):
![]()
总的来说,在微调过程中,我们需要的唯一额外参数是![]() 和分隔符标记的嵌入(embeddings for delimiter tokens) ,具体看上面的图。
和分隔符标记的嵌入(embeddings for delimiter tokens) ,具体看上面的图。
无监督预训练模型的数据集:
BooksCorpus ,它包含7000多本独特的未出版书籍,来自各种类型,包括冒险、幻想和浪漫。关键的是,它包含了长时间的连续文本,这使得生成模型能够学习以长时间的信息为条件。另一个数据集是1B Word Benchmark,由类似的方法ELMo使用,其大小大致相同
训练时间:
8个GPU训练一个月。
5.3 BERT 模型
2019年,Devlin等人利用Transformer模型的encoder层,提出了BERT模型全称为Bidirectional Encoder Representation from Transformers,是一个预训练的语言表征模型。BERT强调了不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练。在预训练时候采用两阶段训练的方式,第一个阶段叫做Masked language model(MLM),随机的抽取15%的token作为即将参与mask的对象。在这些被选中的token中,数据生成器并不不是把他们全部变成[MASK],而是有下列3个选择:
1)在80%的概率下,用[MASK]标记替换该token,比如my dog is hairy -> my dog is [MASK]
2) 在10%的概率下,用⼀个随机的单词替换该token,比如my dog is hairy -> my dog is apple
3)在10%的概率下, 保持该token不变, 比如my dog is hairy -> my dog is hairy
ERT在训练的过程中,并不知道它将要预测哪些单词? 哪些单词是原始的样? 哪些单词被遮掩成了[MASK]?哪些单词被替换成了其他单词?这样可以让模型快速学习该token的分布式上下文的语义,尽最大努力学习原始语言说话的样子。
第二个阶段叫做下⼀句话的预测任务Next Sentence Prediction (NSP),目的是为了服务问答,推理,句子主题关系等NLP任务。所有的参与任务训练的语句都被选中参加。 50%的B是原始文本中实际跟随A的下⼀句话。标记为IsNext,代表正样本。50%的B是原始文本中随机抽取的⼀句话。标记为NotNext,代表负样本。
6. 新式预训练技术
基于 BERT 的改进模型
6.1 RoBERTa
2019年,Yinhan Liu等人提出了RoBERTa(A Robustly Optimized BERT Pretraining Approach)。RoBERTa在BERT模型基础上做了几点改动:1)用更多的训练数据,Batch大小增大,训练时间更长;2)移除了预测下一个语句的任务;3)用更长的语句训练;4)动态的改变MASK的方式;
6.2 structBERT
2019年,Wei Wang等人在BERT的基础上提出了StructBERT(Incorporating language structures into pre-training for deep language understanding)。StructBERT主要有两点贡献,1)训练增加了两个新的目标Word Structural Objective和Sentence Structural Objective,使得新的模型能显式对语言的顺序进行正确重构,并对正确顺序的句子作出预测;2)该模型超越了BERT,在现有大部分NLU任务取得了state-of-the-art的效果;
6.3 DeBERTA
2020年,Pengcheng等人提出新预训练语言模型DeBERTa(Decoding enhanced BERT with disentangled attention)[12]。它被证明比RoBERTa和BERT作为PLM(Pre-trained Languge Model)更有效,并且经过微调后,在一系列NLP任务中取得了更好的效果。DeBERTa对BERT模型做了两个修改。1.每个单词都是用两个向量表示的,这两个向量分别对其内容和位置进行编码,并且单词之间的注意力权重是根据单词的位置和内容来计算的内容和相对位置。这是因为观察到一对词的注意力权重不仅取决于它们的内容,而且取决于它们的相对位置。例如,当单词“deep”和“learning”相邻出现时,它们之间的依赖性要比出现在不同句子中时强得多。2. DeBERTa在预训练时增强了BERT的输出层。在模型预训练过程中,将BERT的输出Softmax层替换为一个增强的掩码解码器(EMD)来预测被屏蔽的令牌。这是为了缓解训练前和微调之间的不匹配。在微调时,我使用一个任务特定的解码器,它将BERT输出作为输入并生成任务标签。然而,在预训练时,我不使用任何特定任务的解码器,而只是通过Softmax归一化BERT输出(logits)。因此,我将掩码语言模型(MLM)视为任何微调任务,并添加一个任务特定解码器,该解码器被实现为两层Transformer解码器和Softmax输出层,用于预训练。
6.4 XLNet模型
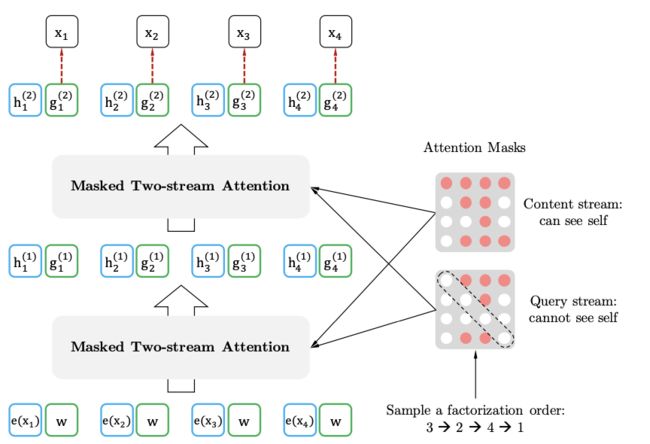
2019年,Yang等人针对BERT中问题提出了XLNet全称为 (Generalized Autoregressive Pretraining for Language Understanding) 。作者在对BERT进行了如下三个方面优化:1)采用了排列语言模型PLM (Permutation Language Model), 将句子随机排列,然后用自回归的方法训练,从而即可以获得双向信息和学习token之间的依赖关系而且解决了BERT在训练过程中输入噪声问题,即BERT采用了Mask的训练方式,一方面忽略了被Mask掉词之间的依赖关系,其次是下游的fine-tuning中不会出现[MASK],这就是出现了不匹配。(2)双流注意力机制,如图2-27,虽然排列语言模型能满足目前的目标,但是并不依赖于其要预测的内容的位置信息,因为无论预测目标的位置在哪里,因式分解后得到的所有情况都是一样的,所以引入了双流注意力机制即查询流和内容流。两个流的网络权重是共享的,训练时用双流,最后在微调阶段,只需要简单的把查询流移除,只采用内容流即可。(3)另外XLNet使用了Transformer-XL,即相对位置编码和片段循环机制。片段循环机制是解决超长序列的依赖问题,
6.5 ConvBERT
Improving BERT with Span-based Dynamic Convolution
6.5.1 论文指出的BERT以及相关变体的问题
1. Bert 以及相关变体严重依赖于全局自注意力模块,这导致了模型占用了很大内存和计算成本,但是根据现有的最新论文和观察attention map发现一些注意力的头只学习到了局部依赖,也就是用全局注意力模块学习局部依赖,造成了计算的浪费和计算的冗余。
2. 自然语言中的固有特征,局部依赖性强。
3. 在对下游任务进行微调时,移除一些注意力的头没有降低性能。模型中存在大量的计算冗余。
6.5.2. 论文的目标
论文的目标是解决这个固有的冗余问题,并进一步提高BERT的效率和下游任务性能。
思考的问题:我们可以通过使用自然的局部操作来替换注意力集中来减少注意力的冗余吗?
论文中提出了一种新的模型ConvBERT, 把基于Span的动态卷机融入bert模型里用于获取局部依赖。其实就是卷机和bert混合模型。
6.5.3 主要的方法
我们注意到卷积在提取局部特征方面非常成功,因此建议使用卷积层作为自我注意的更有效补充,以解决自然语言中的局部依赖性。
具体来说,我们建议将卷积与自我注意相结合,形成一种混合注意机制,将这两种操作的优点结合起来。自我注意使用所有输入标记生成注意权重,以捕获全局依赖关系,同时我们希望执行局部操作。
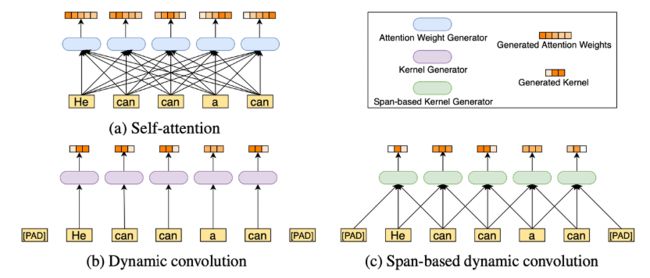
图1:产生注意力权重或卷积核的过程。(a) 自我注意:需要所有输入标记来生成需要二次复杂性的注意权重。(b) 动态卷积:动态内核是通过只接收一个当前令牌来生成的,这会导致为相同的输入令牌生成相同的内核,这些令牌具有不同的含义,比如“can”令牌。(c) 基于广度的动态卷积:内核是通过获取当前标记的局部广度生成的,这可以更好地利用局部依赖性,并区分同一标记的不同含义(例如,如果输入句子中“a”在“can”前面,“can”显然是名词而不是动词)。
7. 其它
7.1 独热表征/表示(one-hot representation)
在传统的自然语言处理中,每个词被视为离散的符号,每个词用唯一的 id 来标识,词被表示为 one-hot 的向量,词与词之间没有任何关系。但实际上词之间具有明显的关系,比如“白色”和“黑色”都是表颜色的词,但是基于 one-hot 的表示法不能表示出词之间这种关系。
white = [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0]
black = [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0]
使用 one-hot 表示的词向量维度巨大(向量长度等于词表大小),且向量之间彼此正交(內积为0)
7.2 分布式表征/表示(distributed representation)
即一个词的词向量表示,若干元素的连续表现形式,将词的语义分布式地存储在各个维度中,与之相反的是独热向量。有下面三大类词向量:
- 基于矩阵的分布表示(n-gram、Glove)
- 基于聚类的分布表示(根据两个词的聚类类别判断相似度,布朗聚类(Brown clustering))
- 基于神经网络的分布表示,分布式表示、词向量、词嵌入(word embedding)
核心依然是上下文的表示以及上下文与目标词之间的关系的建模。
到目前为止所有词向量训练方法都是在训练语言模型的同时,顺便得到词向量的,这样就引入了语言模型概念。
语料库、词向量、词嵌入、语言模型之间的关系是什么? - 简书
如果向量长度为 N,那么每个词都是 N 维空间中的一点。向量的每一个维度,可能表示词的某种特征。举个例子,比如某一维度可能表示这个词是否为表示颜色的词。当然各个维度代表的含义是隐含的,但用向量来表示词语,确实能够刻画词的不同特征。
用来表示 word 的向量被称为 Embedding,因为这个词被嵌入到(embedded)了向量空间中。
| 对比 | 独热表征 | 分布式表征 |
|---|---|---|
| 稀疏/稠密 | 稀疏 | 稠密 |
| 语义表示 | 高纬向量中只有一个维度描述了词的含义 | 语义分布式地存储在向量的各个维度中 |
| 新种类 | 需要添加一个新的维度 | 可能不需要添加新维度就能够表示 |
分布式语义(distributed representation, representing words by their context)
分布式语义的意思是:一个词语的含义是由它周围的词来决定的(a word's meaning is given by the words that frequently appear close-by)。
分布式的意思也意味着,一个dense vector的每一位可以表示多个特征、一个特征也可以由很多位来表示。

我们将每个词语都表示成一个dense vector,使得周围词(context word)相近的两个词的dense vector也相似。这样就可以衡量词语的相似性了。
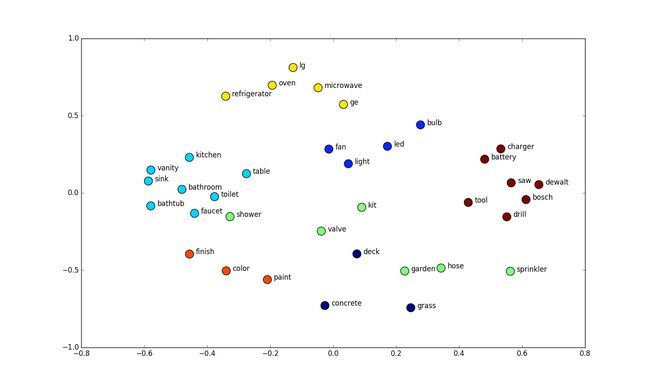
一个好的word representation 能够把握住词语的syntactic(句法,如主谓宾)与semantic(词语的语义含义)信息,例如,一个优秀的词语表示可以做到:
7.3 统计语言模型的一个例子
下面我们举出一个例子(例子来源于https://class.coursera.org/nlp/):
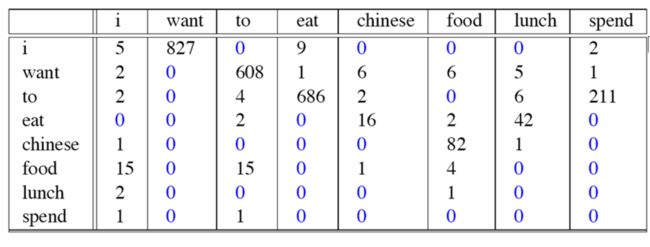
这个例子来自大一点的语料库,为了计算对应的二元模型的参数,即P(wi | wi-1),我们要先计数即c(wi-1,wi),然后计数c(wi-1),再用除法可得到这些条件概率。可以看到对于c(wi-1,wi)来说,wi-1有语料库词典大小(记作|V|)的可能取值,wi也是,所以c(wi-1,wi)要计算的个数有|V|^2。
c(wi-1,wi)计数结果如下:
c(wi-1)的计数结果如下:

那么二元模型的参数计算结果如下:

比如计算其中的P(want | i) = 0.33如下:
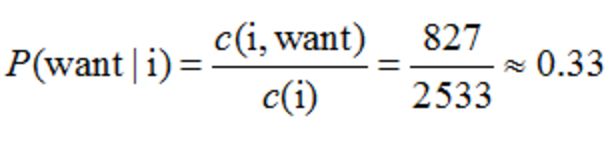
那么针对这个语料库的二元模型建立好了后,我们可以计算我们的目标,即一个句子的概率了,一个例子如下:
P( I want english food ) = P(I|) × P(want|I) × P(english|want) × P(food|english) × P(|food) = 0.000031
那么我们就能通过一个二元语言模型能够计算所需要求的句子概率大小。
二元语言模型也能比一元语言模型能够更好的get到两个词语之间的关系信息。
比如在p(pizza|eats)与p(pizza|drinks)的比较中,二元语言模型就能够更好的get到它们的关系,比如我们再看一下该二元模型所捕捉到的一些实际信息:

图片来自于:Statistical language model 统计语言模型
7.4 N-Gram模型在自然语言中的应用
基于N-Gram模型定义的字符串距离
利用N-Gram模型评估语句是否合理
使用N-Gram模型时的数据平滑算法
在自然语言处理时,最常用也最基础的一个操作是就是“模式匹配”,或者称为“字符串查找”。而模式匹配(字符串查找)又分为精确匹配和模糊匹配两种
所谓的模糊匹配,它的应用也随处可见。例如,一般的文字处理软件(例如,Microsoft Word等)都会提供拼写检查功能。当你输入一个错误的单词,例如 “ informtaion” 时,系统会提示你是否要输入的词其实是 “information” 。将一个可能错拼单词映射到一个推荐的正确拼写上所采用的技术就是模糊匹配。
假设有一个字符串 s,那么该字符串的N-Gram就表示按长度 N 切分原词得到的词段,也就是 s
中所有长度为 N 的子字符串。设想如果有两个字符串,然后分别求它们的N-Gram,那么就可以从它们的共有子串的数量这个角度去定义两个字符串间的N-Gram距离。但是仅仅是简单地对共有子串进行计数显然也存在不足,这种方案显然忽略了两个字符串长度差异可能导致的问题。比如字符串 girl 和 girlfriend,二者所拥有的公共子串数量显然与 girl 和其自身所拥有的公共子串数量相等,但是我们并不能据此认为 girl 和girlfriend 是两个等同的匹配。为了解决该问题,有学者便提出以非重复的N-Gram分词为基础来定义 N-Gram距离这一概念,可以用下面的公式来表述:
|GN(s)|+|GN(t)|−2×|GN(s)∩GN(t)|
此处,|GN(s)|是字符串 s的 N-Gram集合,N 值一般取2或者3。以 N = 2 为例对字符Gorbachev和Gorbechyov进行分段,可得如下结果(我们用下画线标出了其中的公共子串)。
结合上面的公式,即可算得两个字符串之间的距离是8 + 9 − 2 × 4 = 9。显然,字符串之间的距离越小,它们就越接近。当两个字符串完全相等的时候,它们之间的距离就是0。
利用N-Gram计算字符串间距离的Java实例
import org.apache.lucene.search.spell.*;
public class NGram_distance {
public static void main(String[] args) {
NGramDistance ng = new NGramDistance();
float score1 = ng.getDistance("Gorbachev", "Gorbechyov");
System.out.println(score1);
float score2 = ng.getDistance("girl", "girlfriend");
System.out.println(score2);
}
}字符串Gorbachev和Gorbechyov所得之距离评分较高(=0.7),说明二者很接近;而girl和girlfriend所得之距离评分并不高(=0.3999),说明二者并不很接近。
7.4 朴素贝叶斯方法与N-gram语言模型的关系
1、从独立性假设到联合概率( joint probability)链
朴素贝叶斯中使用的独立性假设为
$$P(x_1,x_2,x_3,...x_n)=P(x_1)P(x_2)P(x_3),...,P(x_n) \tag{1}$$
去掉独立性假设,有下面这个恒等式,即联合概率链规则
$$P(x_1,x_2,x_3,...,x_n)=P(x_1)P(x_2|x_1)P(x_3|x_1,x_2),...,P(x_n|x_1,x_2,...,x_{n-1})\tag{2}$$
其中, ![]() 代表一个词,联合概率链规则表示句子中每个词都跟前面一个词有关,而独立性假设则是忽略了一个句子中词与词之间的前后关系。
代表一个词,联合概率链规则表示句子中每个词都跟前面一个词有关,而独立性假设则是忽略了一个句子中词与词之间的前后关系。
2、从联合概率链规则到n-gram语言模型
联合概率链规则是考虑了句子中每个词之间的前后关系,即第n个词 与前面n个词
与前面n个词![]()
有关,而n-gram语言模型模型则是考虑了n个词语之间的前后关系,比如n=2时(二元语法(bigram,2-gram)),第n个词![]() 与前面2−1=1个词有关,即
与前面2−1=1个词有关,即
$$P(x_1,x_2,x_3,...,x_n)=P(x_1)P(x_2|x_1)P(x_3|x_2),...,P(x_n|x_{n-1})\tag{3}$$
比如 n=3时(三元语法(trigram,3-gram)),第n个词 与前面 3−1=2个词有关,即
$$P(x_1,x_2,x_3,...,x_n)=P(x_1)P(x_2|x_1)P(x_3|x_1,x_2),...,P(x_n|x_{n-2},x_{n-1})\tag{4}$$
公式(3)(4)即马尔科夫假设(Markov Assumption):即下一个词的出现仅依赖于它前面的一个或几个词。
3、N-gram语言模型与马尔科夫假设
如果对向量 X 采用条件独立假设,就是朴素贝叶斯方法。
如果对向量 X 采用马尔科夫假设,就是N-gram语言模型。
7.5 你认为当下语言模型(Language Model)的定义是什么?
你认为当下语言模型(Language Model)的定义是什么? - 知乎
简单地说,语言模型(language model, LM)就是给定一个句子,输出它在文本中出现的概率。对于sequence ,建模概率 。传统的LM把这个概率分解成autoregressive形式: 。从最早的N-gram到RNN模型,ELMo再到后来的GPT都是这个套路。但是后来Google出了BERT,事情发生了一些变化。为了实现双向的语言理解,BERT没有针对句子概率进行建模,而是mask掉部分token进行预测。BERT使用Masked language model loss进行预训练,严格意义上BERT不算是normal LM,它不是autoregressive model,更像是个autoencoder。
总结:现在LM的定义和之前相同,但是当下的Pretrained language model (PLM)一般包括autoregressive 和 autoencoder两类,GPT和BERT分别是这两类的典型代表,前者是normal LM一脉相承的。
8.参考文献
[1] Bengio Y , Schwenk H , Jean-Sébastien Sené ca l, et al. Neural Probabilistic Language Models[J]. The Journal of Machine Learning Research, 2003, 3(6):1137-115
[2] Mikolov T , Chen K , Corrado G , et al. Efficient Estimation of Word Representations in Vector Space[J]. Computer Science, 2013.
[3] MIKOLOV T,SUTSKEVER I,CHEN K,et al.Distributed rep- resentations of words and phrases and their compositionality [C]∥Advances in Neural Information Processing Systems. 2013:3111-3119.
[2] Statistical language model 统计语言模型_天道酬勤,做一个务实的理想主义者-CSDN博客
自然语言处理模型(一):一文读懂TF-IDF_学苑新空-CSDN博客_idf模型
https://blog.csdn.net/hao5335156/article/details/82730983
https://www.jianshu.com/p/4452cf120bd7
https://blog.csdn.net/songbinxu/article/details/80209197
https://zhuanlan.zhihu.com/p/32829048
论文|万物皆可Vector之语言模型:从N-Gram到NNLM、RNNLM - 知乎
论文学习:Class-Based n-gram Models of Natural Language - 知乎
NLP的巨人肩膀 - 知乎
NLP发展-从语言模型到预训练模型_徐先森的博客-CSDN博客
层次softmax (hierarchical softmax)理解_BGoodHabit的博客-CSDN博客_层次softmax
下面是NLP从语言模型到预训练模型的总结表:
| 序号 | 年份 | NLP发展历程 | 论文 |
|---|---|---|---|
| 1 | 1986 | 分布式表示思想出现 (Distributed representation) |
Hinton, G. (1986). Learning distributed representations of concepts. In Proceedings of the Eighth Annual Conference of the Cognitive Science Society, pages 1–12, Amherst. Lawrence Erlbaum, Hillsdale. |
| 2 | -- | 统计语言模型 | -- |
| 3 | 2003 | NNLM 语言模型 | Bengio Y , Schwenk H , Jean-Sébastien Sené ca l, et al. Neural Probabilistic Language Models[J]. The Journal of Machine Learning Research, 2003, 3(6):1137-115 |
| 4 | 2013 | Word2Vector | Mikolov T , Chen K , Corrado G , et al. Efficient Estimation of Word Representations in Vector Space[J]. Computer Science, 2013. 提高word2Vector的向量的质量和训练速度 MIKOLOV T,SUTSKEVER I,CHEN K,et al.Distributed representations of words and phrases and their compositionality [C]∥Advances in Neural Information Processing Systems. 2013:3111-3119. |
| 5 | 2014 | Glove | Pennington, Jeffrey, Richard Socher, and Christopher D. GloVe: Global Vectors for Word Representation[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha, Qatar: Association for Computational Linguistics, 2014: 1532–1543. |
| 6 | 2015 | RNNLM | Mikolov T , M Karafiát, Burget L , et al. Recurrent neural network based language model[C]// Interspeech, Conference of the International Speech Communication Association, Makuhari, Chiba, Japan, September. DBLP, 2015. |
| 7 | 2015 | FastText | 1.Enriching Word Vectors with Subword Information 2篇文章,一个是分类,一个是词分布 2016年 |
| 8 | 2018 | ELMO | Embeddings from Language Models |
| 9 | 2018 | GPT | Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J]. 2018 |
| 10 | 2019 | BERT | Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding [C]∥NAACL-HLT.2019. |
| 11 | 2019 | Roberta | Liu Y, Ott M, Goyal N, et al. Roberta: A robustly optimized bert pretraining approach[J]. arXiv preprint arXiv:1907.11692, 2019. |
| 12 | 2019 | XLNet | Yang Z,Dai Z,Y-ang Y et a1.XLNet: Generalized autoregressive pretraining for language understanding[J].Advances in Neural Information Processing Systems,2019,32:5753-5763. |
| 13 | 2020 | DeBERTa | He P , Liu X , Gao J , et al. DeBERTa: Decoding-enhanced BERT with Disentangled Attention[J]. arXiv, 2020. |
| 14 | 2020 | ConvBERT | Jiang Z H, Yu W, Zhou D, et al. Convbert: Improving bert with span-based dynamic convolution[J]. Advances in Neural Information Processing Systems, 2020, 33: 12837-12848 |
| 15 | 2020 | Fusion-ConvBERT | Lee S , Han D K , Ko H . Fusion-ConvBERT: Parallel Convolution and BERT Fusion for Speech Emotion Recognition[J]. Sensors, 2020, 20(22):6688. |
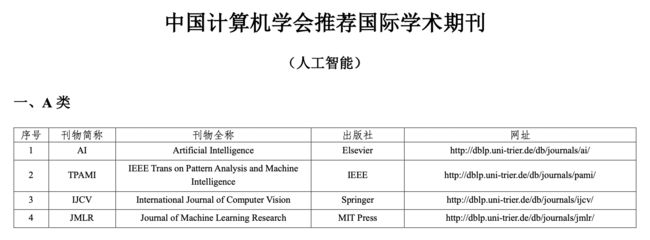
A类人工智能领域的期刊
A类人工智能领域的国际学术会议
其它B类和C类的国际会议和期刊可以参考下面链接
最新版《中国计算机学会推荐国际学术会议和期刊目录》正式发布-中国计算机学会
与NLP相关的比较有影响力的顶会主要有ACL、EMNLP、NAACL、COLING、ICLR、AAAI、CoNLL、NLPCC等。
其中,ACL、NAACL、EMNLP、COLING被称为是NLP领域的四大顶会。ACL、NAACL以及EMNLP均由ACL(Association of Computational Linguistics)主办,而COLING则由ICCL(International Committee on Computational Linguistics)主办。
