机器学习算法之贝叶斯算法 2、案例一:鸢尾花数据分类
贝叶斯原理是怎么来的呢?贝叶斯为了解决一个叫“逆向概率”问题写了一篇文章,尝试解答在没有太多可靠证据的情况下,怎样做出更符合数学逻辑的推测。
什么是“逆向概率”呢?
所谓“逆向概率”是相对“正向概率”而言。正向概率的问题很容易理解,比如我们已经知道袋子里面有 N 个球,不是黑球就是白球,其中 M 个是黑球,那么把手伸进去摸一个球,就能知道摸出黑球的概率是多少。但这种情况往往是上帝视角,即了解了事情的全貌再做判断。
在现实生活中,我们很难知道事情的全貌。贝叶斯则从实际场景出发,提了一个问题:如果我们事先不知道袋子里面黑球和白球的比例,而是通过我们摸出来的球的颜色,能判断出袋子里面黑白球的比例么?
正是这样的一个问题,影响了接下来近 200 年的统计学理论。这是因为,贝叶斯原理与其他统计学推断方法截然不同,它是建立在主观判断的基础上:在我们不了解所有客观事实的情况下,同样可以先估计一个值,然后根据实际结果不断进行修正。
我们用一个题目来体会下:假设有一种病叫做“贝叶死”,它的发病率是万分之一,即 10000 人中会有 1 个人得病。现有一种测试可以检验一个人是否得病的准确率是 99.9%,它的误报率是 0.1%,那么现在的问题是,如果一个人被查出来患有“叶贝死”,实际上患有的可能性有多大?
你可能会想说,既然查出患有“贝叶死”的准确率是 99.9%,那是不是实际上患“贝叶死”的概率也是 99.9% 呢?实际上不是的。你自己想想,在 10000 个人中,还存在 0.1% 的误查的情况,也就是 10 个人没有患病但是被诊断成阳性。当然 10000 个人中,也确实存在一个患有贝叶死的人,他有 99.9% 的概率被检查出来。所以你可以粗算下,患病的这个人实际上是这 11 个人里面的一员,即实际患病比例是 1/11≈9%。
上面这个例子中,实际上涉及到了贝叶斯原理中的几个概念:
先验概率
通过经验来判断事情发生的概率,比如说“贝叶死”的发病率是万分之一,就是先验概率。再比如南方的梅雨季是 6-7 月,就是通过往年的气候总结出来的经验,这个时候下雨的概率就比其他时间高出很多。
后验概率
后验概率就是发生结果之后,推测原因的概率。比如说某人查出来了患有“贝叶死”,那么患病的原因可能是 A、B 或 C。患有“贝叶死”是因为原因 A 的概率就是后验概率。它是属于条件概率的一种。
条件概率
事件 A 在另外一个事件 B 已经发生条件下的发生概率,表示为 P(A|B),读作“在 B 发生的条件下 A 发生的概率”。比如原因 A 的条件下,患有“贝叶死”的概率,就是条件概率。
似然函数(likelihood function)
你可以把概率模型的训练过程理解为求参数估计的过程。举个例子,如果一个硬币在 10 次抛落中正面均朝上。那么你肯定在想,这个硬币是均匀的可能性是多少?这里硬币均匀就是个参数,似然函数就是用来衡量这个模型的参数。似然在这里就是可能性的意思,它是关于统计参数的函数。
介绍完贝叶斯原理中的这几个概念,我们再来看下贝叶斯原理,实际上贝叶斯原理就是求解后验概率,我们假设:A 表示事件 “测出为阳性”, 用 B1 表示“患有贝叶死”, B2 表示“没有患贝叶死”。根据上面那道题,我们可以得到下面的信息。
患有贝叶死的情况下,测出为阳性的概率为 P(A|B1)=99.9%,没有患贝叶死,但测出为阳性的概率为 P(A|B2)=0.1%。另外患有贝叶死的概率为 P(B1)=0.01%,没有患贝叶死的概率 P(B2)=99.99%。
那么我们检测出来为阳性,而且是贝叶死的概率 P(B1,A)=P(B1)*P(A|B1)=0.01%*99.9%=0.00999%。
这里 P(B1,A) 代表的是联合概率,同样我们可以求得 P(B2,A)=P(B2)*P(A|B2)=99.99%*0.1%=0.09999%。
然后我们想求得是检查为阳性的情况下,患有贝叶死的概率,也即是 P(B1|A)。
所以检查出阳性,且患有贝叶死的概率为:
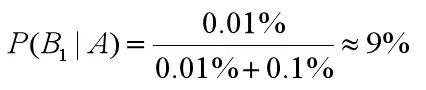
检查出是阳性,但没有患有贝叶死的概率为:
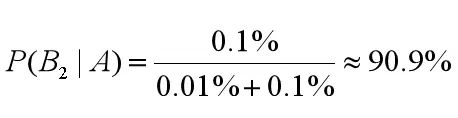
这里我们能看出来 0.01%+0.1% 均出现在了 P(B1|A) 和 P(B2|A) 的计算中作为分母。我们把它称之为论据因子,也相当于一个权值因子。
其中 P(B1)、P(B2) 就是先验概率,我们现在知道了观测值,就是被检测出来是阳性,来求患贝叶死的概率,也就是求后验概率。求后验概率就是贝叶斯原理要求的,基于刚才求得的 P(B1|A),P(B2|A),我们可以总结出贝叶斯公式为:
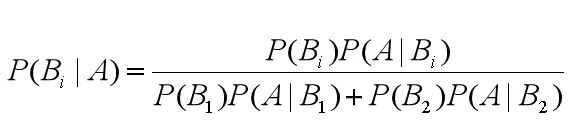
由此,我们可以得出通用的贝叶斯公式:
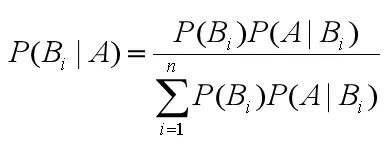
下边举个鸢尾花数据分类的例子

import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn.preprocessing import StandardScaler, MinMaxScaler, PolynomialFeatures
from sklearn.naive_bayes import GaussianNB, MultinomialNB#高斯贝叶斯和多项式朴素贝叶斯
from sklearn.pipeline import Pipeline
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
## 设置属性防止中文乱码
mpl.rcParams['font.sans-serif'] = [u'SimHei']
mpl.rcParams['axes.unicode_minus'] = False
# 花萼长度、花萼宽度,花瓣长度,花瓣宽度
iris_feature_E = 'sepal length', 'sepal width', 'petal length', 'petal width'
iris_feature_C = u'花萼长度', u'花萼宽度', u'花瓣长度', u'花瓣宽度'
iris_class = 'Iris-setosa', 'Iris-versicolor', 'Iris-virginica'
features = [2,3]
## 读取数据
path = './datas/iris.data' # 数据文件路径
data = pd.read_csv(path, header=None)
x = data[list(range(4))]
x = x[features]
y = pd.Categorical(data[4]).codes ## 直接将数据特征转换为0,1,2
print ("总样本数目:%d;特征属性数目:%d" % x.shape)
## 0. 数据分割,形成模型训练数据和测试数据
x_train1, x_test1, y_train1, y_test1 = train_test_split(x, y, train_size=0.8, random_state=14)
x_train, x_test, y_train, y_test = x_train1, x_test1, y_train1, y_test1
print ("训练数据集样本数目:%d, 测试数据集样本数目:%d" % (x_train.shape[0], x_test.shape[0]))
训练数据集样本数目:120, 测试数据集样本数目:30
## 高斯贝叶斯模型构建
clf = Pipeline([
('sc', StandardScaler()),#标准化,把它转化成了高斯分布
('poly', PolynomialFeatures(degree=1)),
('clf', GaussianNB())])
## 训练模型
clf.fit(x_train, y_train)
Pipeline(steps=[(‘sc’, StandardScaler(copy=True, with_mean=True, with_std=True)), (‘poly’, PolynomialFeatures(degree=1, include_bias=True, interaction_only=False)), (‘clf’, GaussianNB(priors=None))])
## 计算预测值并计算准确率
y_train_hat = clf.predict(x_train)
print ('训练集准确度: %.2f%%' % (100 * accuracy_score(y_train, y_train_hat)))
y_test_hat = clf.predict(x_test)
print ('测试集准确度:%.2f%%' % (100 * accuracy_score(y_test, y_test_hat)))
训练集准确度: 95.83%
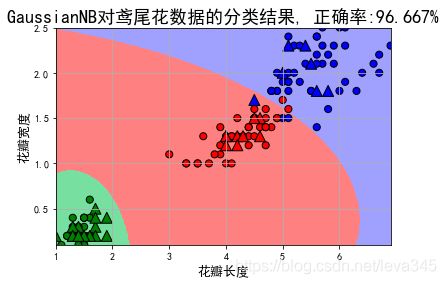
测试集准确度:96.67%
## 产生区域图
N, M = 500, 500 # 横纵各采样多少个值
x1_min1, x2_min1 = x_train.min()
x1_max1, x2_max1 = x_train.max()
x1_min2, x2_min2 = x_test.min()
x1_max2, x2_max2 = x_test.max()
x1_min = np.min((x1_min1, x1_min2))
x1_max = np.max((x1_max1, x1_max2))
x2_min = np.min((x2_min1, x2_min2))
x2_max = np.max((x2_max1, x2_max2))
t1 = np.linspace(x1_min, x1_max, N)
t2 = np.linspace(x2_min, x2_max, N)
x1, x2 = np.meshgrid(t1, t2) # 生成网格采样点
x_show = np.dstack((x1.flat, x2.flat))[0] # 测试点
cm_light = mpl.colors.ListedColormap(['#77E0A0', '#FF8080', '#A0A0FF'])
cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
y_show_hat = clf.predict(x_show) # 预测值
y_show_hat = y_show_hat.reshape(x1.shape)
## 画图
plt.figure(facecolor='w')
plt.pcolormesh(x1, x2, y_show_hat, cmap=cm_light) # 预测值的显示
plt.scatter(x_train[features[0]], x_train[features[1]], c=y_train, edgecolors='k', s=50, cmap=cm_dark)
plt.scatter(x_test[features[0]], x_test[features[1]], c=y_test, marker='^', edgecolors='k', s=120, cmap=cm_dark)
plt.xlabel(iris_feature_C[features[0]], fontsize=13)
plt.ylabel(iris_feature_C[features[1]], fontsize=13)
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.title(u'GaussianNB对鸢尾花数据的分类结果, 正确率:%.3f%%' % (100 * accuracy_score(y_test, y_test_hat)), fontsize=18)
plt.grid(True)
plt.show()
链接: 贝叶斯算法例子代码.