利用CNN进行手写数字识别代码详解(新手学习)
利用CNN进行手写数字识别代码详解(新手学习)
首先先附上完整代码,接下来进行分解介绍。
# Copyright 2015 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""A very simple MNIST classifier.
See extensive documentation at
http://tensorflow.org/tutorials/mnist/beginners/index.md
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
# 引入数据集
from tensorflow.examples.tutorials.mnist import input_data
#导入tensorflow库
import tensorflow as tf
flags = tf.app.flags
FLAGS = flags.FLAGS
flags.DEFINE_string('data_dir', '/tmp/data/', 'Directory for storing data') # 第一次启动会下载文本资料,放在/tmp/data文件夹下
print(FLAGS.data_dir)
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True)
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1) # 变量的初始值为截断正太分布
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
sess = tf.InteractiveSession()
x = tf.placeholder(tf.float32, [None, 784])
x_image = tf.reshape(x, [-1,28,28,1]) #将输入按照 conv2d中input的格式来reshape,reshape
W_conv1 = weight_variable([5, 5, 1, 32]) # 卷积是在每个5*5的patch中算出32个特征,分别是patch大小,输入通道数目,输出通道数目
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.elu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.elu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
# 第三层 是个全连接层,输入维数7*7*64, 输出维数为1024
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.elu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
keep_prob = tf.placeholder(tf.float32) # 这里使用了drop out,即随机安排一些cell输出值为0,可以防止过拟合
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 第四层,输入1024维,输出10维,也就是具体的0~9分类
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2) # 使用softmax作为多分类激活函数
y_ = tf.placeholder(tf.float32, [None, 10])
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y_conv), reduction_indices=[1])) # 损失函数,交叉熵
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) # 使用adam优化
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1)) # 计算准确度
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
sess.run(tf.initialize_all_variables()) # 变量初始化
for i in range(20000):
batch = mnist.train.next_batch(50)
if i%100 == 0:
# print(batch[1].shape)
train_accuracy = accuracy.eval(feed_dict={
x:batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, training accuracy %g"%(i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print("test accuracy %g"%accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
flags = tf.app.flags
FLAGS = flags.FLAGS
flags.DEFINE_string('data_dir', '/tmp/data/', 'Directory for storing data')## 第一次启动会下载文本资料,放在/tmp/data文件夹下
tf.app.flags.FLAGS的作用是接受从终端传入的命令行参数,按我的理解它就相当于一个空盒子,用来装存从外面取的参数,从而在后面运用这些参数。
tf.app.flags.DEFINE_string() :定义一个用于接收string类型数值的变量;flags.DEFINE_string(‘data_dir’, ‘/tmp/data/’, ‘Directory for storing data’)的含义是定义一个名称是 “data_dir” 的变量,默认值是 data_dir = ‘/tmp/data/’,'Directory for storing data’是对所做事情的描述:定义用于存储数据的路径。
总结:tf.app.flags.DEFINE_xxx()就是添加命令行的optional argument(可选参数),而tf.app.flags.FLAGS可以从对应的命令行参数取出参数。
print(FLAGS.data_dir)
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True)
因为之前把数据集参数都保存到了data_dir下,所以现在我们要从中拿出来用了。
one_hot=True表示采用one_hot编码形式,也就是用1和0来表示类别,例如如果手写数字是2,那么2对应的位置是1其他9个位置是0。
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
数据集处理完后就搭建模型啦!
模型涉及到权重w、偏置b、网络结构、激活函数、损失函数等,那么我们就要意义定义,这里我们定义的是权重w。
函数tf.truncated_normal(shape, mean, stddev, dtype, seed, name)
释义:截断的产生正态分布的随机数,即随机数与均值的差值若大于两倍的标准差,则重新生成,例如上面代码中随机取数在【-0.2,0.2】之间
shape:表示生成随机数的维度
mean:正太分布的均值,默认为0
stddev:正太分布的标准差
dtype:生成正太分布数据的类型
seed:一个整数,当设置之后,每次生成的随机数都一样
name:正太分布的名字
tf.Variable表示以变量的形式保存和更新神经网络中的参数
4.
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
这里是定义参数偏差b,大体和定义w相同只不过这里用tf.constant来创建常量值。
tf.constant(value, dtype=None, shape=None, name=’Const’, verify_shape=False)
value:是一个必须的值,可以是一个数值,也可以是一个列表;可以是一维的,也可以是多维的。
dtype:数据类型,一般可以是tf.float32, tf.float64等
shape:表示张量的“形状”,即维数以及每一维的大小
name: 可以是任何内容,只要是字符串就行
verify_shape:默认为False,如果修改为True的话表示检查value的形状与shape是否相符,如果不符会报错。
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
这里是要调用卷积函数了,之后就可以做卷积了。
def conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None,
data_format=None, name=None):
前几个参数分别是input, filter, strides, padding, use_cudnn_on_gpu, …下面来一一解释
input:待卷积的数据。格式要求为一个张量,[batch, in_height, in_width, in_channels].
分别表示 批次数,图像高度,宽度,输入通道数。
filter: 卷积核。格式要求为[filter_height, filter_width, in_channels, out_channels].
分别表示 卷积核的高度,宽度,输入通道数,输出通道数。
strides :一个长为4的list. 表示每次卷积以后卷积窗口在input中滑动的距离
padding :有SAME和VALID两种选项,表示是否要保留图像边上那一圈不完全卷积的部分。如果是SAME,则保留
use_cudnn_on_gpu :是否使用cudnn加速。默认是True
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
这里要调用池化函数进行最大池化。
def max_pool(value, ksize, strides, padding, data_format=“NHWC”, name=None):
value: 一个4D张量,格式为[batch, height, width, channels],与conv2d中input格式一样
ksize: 长为4的list,表示池化窗口的尺寸
strides: 池化窗口的滑动值,与conv2d中的一样
padding: 与conv2d中用法一样。
sess = tf.InteractiveSession()
x = tf.placeholder(tf.float32, [None, 784])
x_image = tf.reshape(x, [-1,28,28,1])
sess = tf.InteractiveSession():建立交互式会话
placeholder又叫占位符,是一个抽象的概念。用于表示输入输出数据的格式。告诉系统:这里有一个值/向量/矩阵,现在我没法给你具体数值,不过我正式运行的时候会补上的,例如上面表示[?,784]的矩阵,?具体是多少,后文按情况指定
#Variable代表变量,用来指定参数。
x_image = tf.reshape(x, [-1,28,28,1]):代表将输入按照 conv2d中所规定的input的格式来进行输入,如在这里就是按照28*28的大小输入、通道为1。
W_conv1 = weight_variable([5, 5, 1, 32]) # 卷积是在每个5*5的patch中算出32个特征,分别是patch大小,输入通道数目,输出通道数目
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.elu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
第一层卷积
卷积核(filter)的尺寸是55, 通道数为1,输出通道为32,即feature map 数目为32
又因为strides=[1,1,1,1] 所以单个通道的输出尺寸应该跟输入图像一样。即总的卷积输出应该为?282832
也就是单个通道输出为2828,共有32个通道,共有?个批次
在池化阶段,ksize=[1,2,2,1] 那么卷积结果经过池化以后的结果,其尺寸应该是 ?141432
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.elu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
第二层卷积
卷积核55,输入通道为32,输出通道为64。
卷积前图像的尺寸为 ?141432, 卷积后为?141464
池化后,输出的图像尺寸为?7764
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.elu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
这是全连接层
全连接层的输入为第二层卷积层的输出,所以全连接层的输入为三维的7764,输出为一维的1024,相当于把输入的feature map拉平。
h_pool2_flat = tf.reshape(h_pool2, [-1, 7764]):这一行是在改变输入张量的结构,-1表示任意数量的样本数,大小为7*7深度为64的张量。
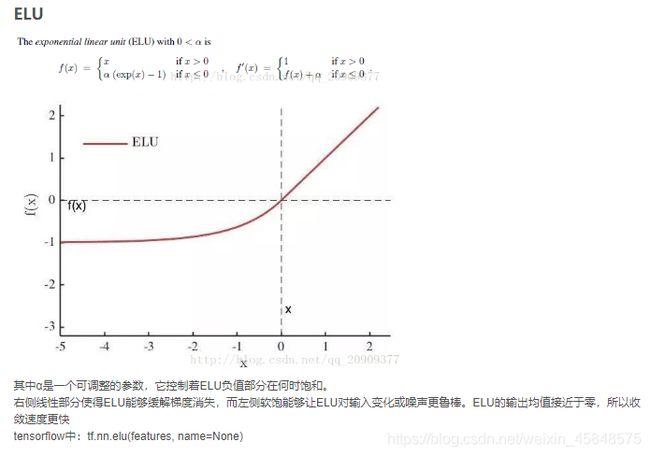
h_fc1 = tf.nn.elu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1):在这里采用elu激活函数进行分类,将输入的input经过加权求和后被应用于elu函数。
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
这里这里使用了drop out,即随机安排一些cell输出值为0,也就是随机去掉一些神经元从而减少网络中参数的数量,可以防止过拟合。
函数:tf.nn.dropout( x, keep_prob,noise_shape=None, seed=None,name=None)
x:指输入,输入tensor
keep_prob: float类型,每个元素被保留下来的概率,设置神经元被选中的概率,在初始化时keep_prob是一个占位符, keep_prob = tf.placeholder(tf.float32) 。tensorflow在run时设置keep_prob具体的值,例如keep_prob: 0.5
noise_shape : 一个1维的int32张量,代表了随机产生“保留/丢弃”标志的shape。
seed : 整形变量,随机数种子。
name:指定该操作的名字
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
y_ = tf.placeholder(tf.float32, [None, 10])
这一层是网络的输出层。输入为上层全连接层的输出1024,输出为10,也就是对应0-9分类。
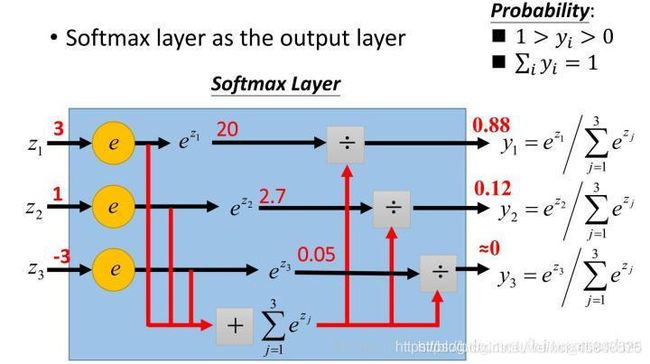
使用softmax作为分类函数,tf.nn.softmax(logits,axis=None,name=None,dim=None)
logits:一个非空的Tensor。必须是下列类型之一:half, float32,float64
axis:将在其上执行维度softmax。默认值为-1,表示最后一个维度
name:操作的名称(可选)
dim:axis的已弃用的别名
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y_conv), reduction_indices=[1])) # 损失函数,交叉熵
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) # 使用adam优化
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1)) # 计算准确度
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
在上面我们已将把模型构建完成了,那么下面我们就要定义怎样训练模型。
模型训练涉及到损失函数、模型优化和计算精度。
损失函数使用交叉熵损失函数。交叉熵损失函数表示预测概率和真实概率之间的差异,这个差异越小越好,其公式为:
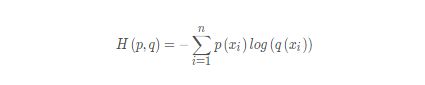
使用Adam算法进行优化,Adam是梯度下降的一种变形,通过不断优化权重,找到全局最优点,使得损失函数loss的值(cross_entropy)达到最小,其中学习率为0.001。
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
tf.argmax表示找到概率是最大值的位置(也就是预测的分类和实际的分类),然后看看他们是否一致,是就返回true,不是就返回false,这样得到一个boolean数组。
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.cast将boolean数组转成int数组,如果是True就转化成1,如果是False就转化成0,最后求平均值,得到分类的准确率。
sess.run(tf.initialize_all_variables()) # 把所有变量初始化
for i in range(20000): #进行2万步训练
batch = mnist.train.next_batch(50) #每次从训练集中获取50批数据
if i%100 == 0:
# 计算训练精度,keep_prot=1表示神经元全部使用
train_accuracy = accuracy.eval(feed_dict={
x:batch[0], y_: batch[1], keep_prob: 1.0})
#把测试过程进行可视化,打印测试步数和相应精度
print("step %d, training accuracy %g"%(i, train_accuracy))
#进行模型训练,去掉一半的神经元
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
#进过上述用训练集进行训练后得到新的模型,那么现在就要用测试集来检测一下经训练后模型的好坏,计算精度并进行可视化。
print("test accuracy %g"%accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
定义模型训练后我们就要进行训练和测试模型了。
feed_dict的作用是给使用placeholder创建出来的tensor赋值,上面就把mnist.test.images赋值给x,把mnist.test.labels赋值给y