学习率-pytorch
定义:学习率(Learning rate)作为监督学习以及深度学习中重要的超参,其决定着目标函数能否收敛到局部最小值以及何时收敛到最小值。合适的学习率能够使目标函数在合适的时间内收敛到局部最小值。
![]()
学习率的大小对训练的影响
(1)参数-损失
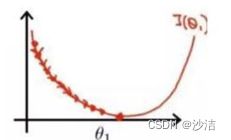

当学习率设置的过小时 当学习率设置的过大时
由上图可以看出来,当学习率设置的过小时,收敛过程将变得十分缓慢。且容易陷入局部最优解出不来。而当学习率设置的过大时,梯度可能会在最小值附近来回震荡,甚至可能无法收敛。
(2)epoch-损失

[红线]曲线 初始时 上扬 :
解决:初始 学习率过大 导致 振荡,应减小学习率,并 从头 开始训练 。
[紫线]曲线 初始时 强势下降 没多久 归于水平 [紫线]:
解决:后期 学习率过大 导致 无法拟合,应减小学习率,并 重新训练 后几轮 。
[黄线]曲线 全程缓慢 :
解决:初始 学习率过小 导致 收敛慢,应增大学习率,并 从头 开始训练 。
[绿线]理想情况下 曲线 应该是 滑梯式下降。
固定学习率和衰减学习率对训练的影响

可以由上图看出,固定学习率时,当到达收敛状态时,会在最优值附近一个较大的区域内摆动;而当随着迭代轮次的增加而减小学习率,会使得在收敛时,在最优值附近一个更小的区域内摆动。
torch.optim.lr_scheduler中包含的学习率方法:
class lass _LRScheduler(object)
class LambdaLR(_LRScheduler)
class MultiplicativeLR(_LRScheduler)
class StepLR(_LRScheduler)
class MultiStepLR(_LRScheduler)
class ExponentialLR(_LRScheduler)
class CosineAnnealingLR(_LRScheduler)
class ReduceLROnPlateau(object)
class CyclicLR(_LRScheduler)
class CosineAnnealingWarmRestarts(_LRScheduler) class OneCycleLR(_LRScheduler)
学习率的三种变化方式
- 学习率的固定衰减方法
(1) LambdaLR(_LRScheduler)自定义衰减方法
[base_lr * lmbda(self.last_epoch) for lmbda, base_lr in zip(self.lr_lambdas, self.base_lrs)] (2)StepLR(_LRScheduler)和MultiStepLR(_LRScheduler) 功能: 等间隔调整学习率,调整倍数为gamma倍,调整间隔为step_size。torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1) 参数:step_size指epoch,last_epoch:从last_start开始后已经记录了多少个epoch,Default: -1。
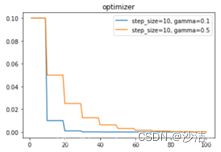
(3)MultiStepLR(_LRScheduler)
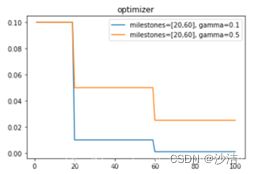
功能:调节的epoch是自己定义,当last_epoch=-1时,将初始LR设置为LR。torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)
参数:milestones :lr改变时的epoch数目,如[30,80]。
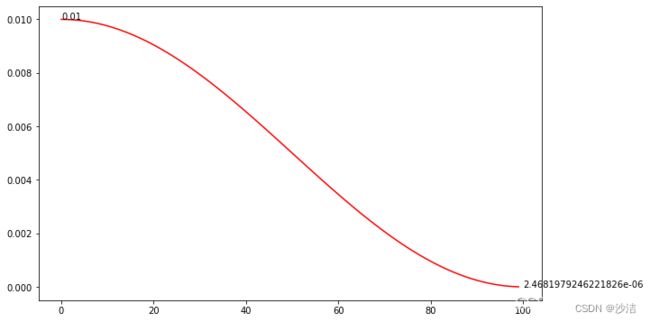
(4)ExponentialLR(_LRScheduler)
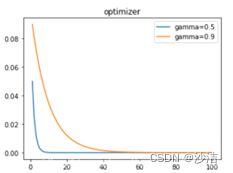
功能:按次方的形式来减少。
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1)
公式:
![]()
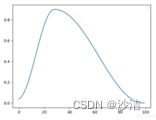
(5)OneCycleLR
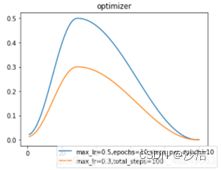
功能:先从一个较低的学习率开始,逐渐达到一个峰值,然后再从峰值下降到一个比初始学习率更小的值。
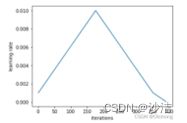
torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr, total_steps=None, epochs=None, steps_per_epoch=None, pct_start=0.3 参数:max_lr :lr 的最大值,total_steps scheduler=lr_scheduler.OneCycleLR(optimizer,max_lr=0.5,epochs=10,steps_per_epoch=10)scheduler1 = lr_scheduler.OneCycleLR(optimizer1,max_lr=0.3,total_steps=100)
默认是"cos"方式,当然也可以选择"linear"
2.周期学习率衰减
为了使得梯度下降方法能够逃离局部最小值或鞍点,一种经验性的方式是在训练过程中周期性地增大学习率。虽然增加学习率可能短期内有损网络的收敛稳定性,但从长期来看有助于找到更好的局部最优解。周期性学习率调整可以使得梯度下降方法在优化过程中跳出尖锐的局部极小值,虽然会短期内会损害优化过程,但最终会收敛到更加理想的局部极小值。
(1)CosineAnnealingLR,余弦退火。一般每个epoch训练完成后调用。
功能:学习率按照余弦周期变化。设置每 T_max 个 epoch 迭代后衰减到 eta_min 所设置的最小值,然后逐渐恢复其初值,依此类推、往复波动:
![]()
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1, verbose=False)
参数:T_max半周期,按epoch算,eta_min:学习率最小值,
lr = 0.1 ,T_max 设为 20 和 15,eta_min = 0.1 为例,其学习率的变化情况:
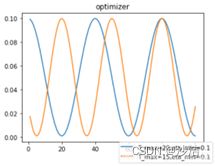
当T_max=epoch(设置的要训练的总数)时,
(2)CosineAnnealingWarmRestarts,一般每个epoch训练完成后调用。
功能:类似 CosineAnnealingLR,不同的是 CosineAnnealingWarmRestarts 在学习率上升时使用热启动。
torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0, T_mult=1, eta_min=0, last_epoch=-1, verbose=False)
参数:T_0是学习率 restart 的周期,T_mult 是restart 之后的周期倍数。![]()
lr = 0.1 ,T_0 设为 10、T_mult 设置为 2、eta_min 设置为 0.05 ,和仅设置 T_0 为 15 为例,其学习率的变化情况:
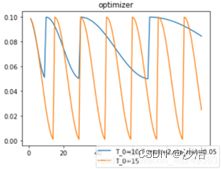
(3)Cyclical learning rate(CLR)
周期性学习率遵从从小到大再从大到小,然后又是从小到大再从大到小,如此这般循环下去。1个Cycle定义为从小到大再从大到小的变化。1个Cycle由两个step_size组成。 一个step_size是半个cycle,一个step_size可能跨4-8个epoch。
对于CLR,需要设定一个最大的学习率(max_lr) 和一个最小的学习率(base_lr), 整个学习率在训练期间会在这两个限定值之间来回振荡。按照振荡的方式不同,这里介绍三种CLR。
(1.1)第一种CLR命名为"triangular",每一个Cycle的max_lr是不变的,也即为图1所示情况。

(1.2)第二种CLR命名为"triangular2",每一个Cycle的max_lr会逐渐减半,如下图2所示。
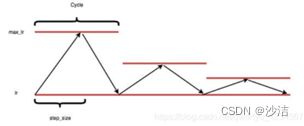
(3)第三种CLR命名为"exp_range",每一个Cycle的max_lr随着Cycle指数下降,如下图3所示。
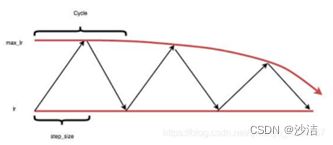
对于第一种Triangular型周期性学习率,由于即便到了训练的末期,其学习率仍然可以达到最大或者比较大的一个值,因此就有可能会使得原本已经训练到了最优的模型又跳出最优点位置,使得模型的训练结果变得不太稳定。因此后面的trainglar2 和 exp_rangle两种类型的周期性学习率可以保证避免这种不稳定性问题。
三种CLR的代码实现:

当然可以自己定义最大幅度函数scale_fn
3.自适应学习率
(1) Adagrad算法
(2) RMSprop算法
(3) AdaDelta算法
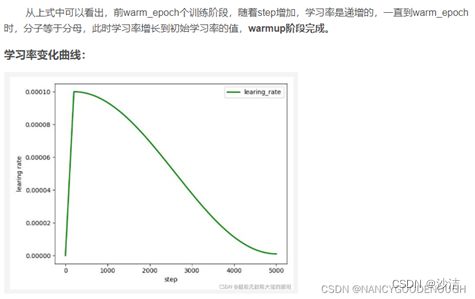
4. Warmup
(1)什么是Warmup?
Warmup是在ResNet论文中提到的一种学习率预热的方法,它在训练开始的时候先选择使用一个较小的学习率,训练了一些epoches或者steps(比如4个epoches,10000steps),再修改为预先设置的学习率来进行训练。
(2)为什么使用Warmup?
由于刚开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择Warmup预热学习率的方式,可以使得开始训练的几个epoches或者一些steps内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
例如:Resnet论文中使用一个110层的ResNet在cifar10上训练时,先用0.01的学习率训练直到训练误差低于80%(大概训练了400个steps),然后使用0.1的学习率进行训练。
(3)Warmup的改进
上述的Warmup是constant warmup,它的不足之处在于从一个很小的学习率一下变为比较大的学习率可能会导致训练误差突然增大。于是18年Facebook提出了gradual warmup来解决这个问题,即从最初的小学习率开始,每个step增大一点点,直到达到最初设置的比较大的学习率时,采用最初设置的学习率进行训练。