一、准备工作
首先准备两张表用于演示:
CREATE TABLE `student_info` ( `id` int NOT NULL AUTO_INCREMENT, `student_id` int NOT NULL, `name` varchar(20) DEFAULT NULL, `course_id` int NOT NULL, `class_id` int DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1000001 DEFAULT CHARSET=utf8;
CREATE TABLE `course` ( `id` int NOT NULL AUTO_INCREMENT, `course_id` int NOT NULL, `course_name` varchar(40) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=101 DEFAULT CHARSET=utf8;
#准备数据 select count(*) from student_info;#1000000 select count(*) from course; #100
二、索引失效规则
1.优先使用联合索引
如下一条sql语句是没有索引的情况:
#平均耗时291毫秒 select * from student_info where name='123' and course_id=1 and class_id=1;
我们通过建立索引来优化它的查询效率,有如下几种方案:
①建立普通索引:
#建立普通索引 create index idx_name on student_info(name); #平均耗时25毫秒,查看explain执行计划,使用到的是idx_name索引查询 select * from student_info where name='MOKiKb' and course_id=1 and class_id=1;
②在普通索引的基础上,再增加联合索引:
#name,course_id组成的联合索引 create index idx_name_courseId on student_info(name,course_id); #该查询语句一般使用的是联合索引,而不是普通索引,具体看优化器决策 #平均耗时20ms select * from student_info where name='zhangsan' and course_id=1 and class_id=1;

可以看到,在多个索引都可以使用时,系统一般优先使用更长的联合索引,因为联合索引相比来说更快,这点应该也很好理解,前提是要遵守联合索引的最左匹配原则。
如果再创建一个name,course_id,class_id组成的联合索引,那么上述sql语句不出意外会使用这个key_len更长的联合索引(意外是优化器可能会选择其他更优的方案,如果它更快的话)。
联合索引速度不一定优于普通索引,比如第一个条件就过滤了所有记录,那么就没必要用后序的索引了。
2.最左匹配原则
#删除前例创建的索引,新创建三个字段的联合索引,name-course_id-cass_id create index idx_name_cou_cls on student_info(name,course_id,class_id);
①联合索引全部匹配的情况:
#关联字段的索引比较完整 explain select * from student_info where name='11111' and course_id=10068 and class_id=10154;

该sql语句符合最左前缀原则,每个字段条件中的字段恰好和联合索引吻合。这种情况是最优的,因为依靠一个联合索引就可以快速查找,不需要额外的查询。
②联合索引最右边缺失的情况:
explain select * from student_info where name='11111' and course_id=10068;

该sql语句条件中,并不含有联合索引的全部条件,而是抹去了右半部分,该语句使用的索引依旧是该关联查询,只不过只用到了一部分,通过查看key_len可以知道少了5字节,这5字节对应的是class_id,证明class_id并未生效而已(where中没有,当然用不到啦)。
同理,抹掉where中的course_id字段,联合索引依旧会生效,只是key_len会减小。
③联合索引中间缺失的情况:
#联合索引中间的字段未使用,而左边和右边的都存在 explain select * from student_info where name='11111' and class_id=10154;;

如上sql语句依旧使用的是联合索引,但是它的key_len变小了,只有name字段使用到了索引,而class_id字段虽然在联合索引中,但是因为不符合最左匹配原则而GG了。
整个sql语句的执行流程为:先在联合索引的B树中找到所有name为11111的记录,然后全文过滤掉这些记录中class_id不是10154的记录。多了一个全文搜索的步骤,相比于①和②情况性能会更差。
④联合索引最左边缺失的情况:
explain select * from student_info where class_id=10154 and course_id=10068;

该情况是上一个情况的特例,联合索引中最左边的字段未找到,所以虽然有其他部分,但是统统都失效了,走的是全文查找。
结论:最左匹配原则指的是查询从索引的最左列开始,并且不能跳过索引中的列,如果跳过了某一列,索引将部分失效(后面的字段索引全部失效)。
注意:创建联合索引时,字段的顺序就定格了,最左匹配就是根据该顺序比较的;但是在查询语句中,where条件中字段的顺序是可变的,意味着不需要按照关联索引字段的顺序,只要where条件中有就行了。
3.范围条件右边的列索引失效
承接上面的联合索引,使用如下sql查询:
#key_len=> name:63,course_id:5,class_id:5 explain select * from student_info where name='11111' and course_id>1 and class_id=1;

key_len只有68,代表关联索引中class_id未使用到,虽然符合最左匹配原则,但因为>符号让关联索引中该条件字段右边的索引失效了。
但如果使用>=号的话:
#不是>、<,而是>=、<= explain select * from student_info where name='11111' and course_id>=20 and course_id<=40 and class_id=1;
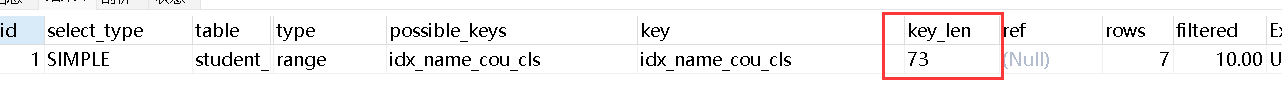
右边的索引并未失效,key_len为73,所有字段的索引都使用到了。
结论:为了充分利用索引,我们有时候可以将>、<等价转为>=、<=的形式,或者将可能会有<、>的条件的字段尽量放在关联索引靠后的位置。
4.计算、函数导致索引失效
#删除前面的索引,新创建name字段的索引,方便演示 create index idx_name on student_info(name);
现有一个需求,找出name为li开头的学生信息:
#使用到了索引 explain select * from student_info where name like 'li%'; #未使用索引,花费时间更久 explain select * from student_info where LEFT(name,2)='li';
上面的两条sql语句都可以满足需求,然而第一条语句用了索引,第二条没有,一点点的改变真是天差地别。
结论:字段使用函数会让优化器无从下手,B树中的值和函数的结果可能不搭边,所以不会使用索引,即索引失效。字段能不用就不用函数。
类似:
#也不会使用索引 explain select * from student_info where name+''='lisi';
类似的对字段的运算也会导致索引失效。
5.类型转换导致索引失效
#不会使用name的索引 explain select * from student_info where name=123; #使用到索引 explain select * from student_info where name='123';
如上,name字段是VARCAHR类型的,但是比较的值是INT类型的,name的值会被隐式的转换为INT类型再比较,中间相当于有一个将字符串转为INT类型的函数。
6.不等于(!= 或者<>)索引失效
#创建索引 create index idx_name on student_info(name); #索引失效 explain select * from student_info where name<>'zhangsan'; explain select * from student_info where name!='zhangsan';
不等于的情况是不会使用索引的。因为!=代表着要进行全文的查找,用不上索引。
7.is null可以使用索引,is not null无法使用索引
#可以使用索引 explain select * from student_info where name is null; #索引失效 explain select * from student_info where name is not null;
和前一个规则类似的,!=null。同理not like也无法使用索引。
最好在设计表时设置NOT NULL约束,比如将INT类型的默认值设为0,将字符串默认值设为''。
8.like以%开头,索引失效
#使用到了索引 explain select * from student_info where name like 'li%'; #索引失效 explain select * from student_info where name like '%li';
只要以%开头就无法使用索引,因为如果以%开头,在B树排序的数据中并不好找。
9.OR前后存在非索引的列,索引失效
#创建好索引 create index idx_name on student_info(name); create index idx_courseId on student_info(course_id);
如果or前后都是索引:
#使用索引 explain select * from student_info where name like 'li%' or course_id=200;

如果其中一个没有索引:
explain select * from student_info where name like 'li%' or class_id=1;

那么索引就失效了,假设还是使用索引,那就变成了先通过索引查,然后再根据没有的索引的字段进行全表查询,这种方式还不如直接全表查询来的快。
10.字符集不统一
字符集如果不同,会存在隐式的转换,索引也会失效,所有应该使用相同的字符集,防止这种情况发生。
三、建议
- 对于单列索引,尽量选择针对当前query过滤性更好的索引
- 在选择组合索引时,query过滤性最好的字段应该越靠前越好
- 在选择组合索引时,尽量选择能包含当前query中where子句中更多字段的索引
- 在选择组合索引时,如果某个字段可能出现范围查询,尽量将它往后放
到此这篇关于MySQL导致索引失效的几种情况的文章就介绍到这了,更多相关MySQL 索引失效内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!