推荐系统学习笔记之NFM模型
目录
- 模型简介
- 模型结构与分析
-
- Input层
- Embedding层
- B-Interaction 层
- 隐藏层(Hidden Layers)
- 预测层(Prediction Score)
- 模型搭建及训练
-
- 数据集
- 代码
- 训练结果
- 总结
模型简介
NFM(Neural Factorization Machines)是2017年由新加坡国立大学的何向南教授等人在SIGIR会议上提出的一个模型,是传统FM模型的改良,目的是为了解决FM模型因只能交叉到二阶,且是线性模型从而在真实生活场景中复杂且具有规律的数据上表现不佳的问题。
模型结构与分析
模型结构如图所示,NFM是FM模型与DNN的融合,同时发挥了FM模型的低阶特征的交互能力与DNN的高阶特征学习能力和非线性拟合能力
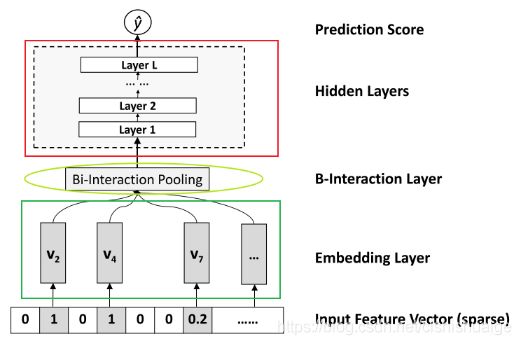
Input层
如图所示,这一层输入的是稀疏(sparse)的,经过ont-hot编码的向量
Embedding层
该层的作用是将稀疏向量转换成稠密的的向量并作为下一层的输入
B-Interaction 层
该层是这个模型的创新点,相当于一个pooling层,其原理是将多个输入向量两两之间(k维)的对应维度相乘(但不相加),输出多个仍是k维的,交叉后的向量,再对这些向量取和,得到输出向量

隐藏层(Hidden Layers)
该层是由多层全连接的神经网络组成,用以学习更高阶的组合特征,由于上一层的FM已经学习到了一定特征,所以需要的隐藏层更少,模型更浅,训练和调参更容易
预测层(Prediction Score)
结构为最后一层的结果直接过一个隐藏层,数学形式如下
![]()
模型搭建及训练
数据集
来源:kaggle(Display Advertising Challenge)
代码
import warnings
warnings.filterwarnings("ignore")
import itertools
import pandas as pd
import numpy as np
from tqdm import tqdm
from collections import namedtuple
import tensorflow as tf
from tensorflow.keras.layers import *
from tensorflow.keras.models import *
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
from utils import SparseFeat, DenseFeat, VarLenSparseFeat
# 简单处理特征,包括填充缺失值,数值处理,类别编码
def data_process(data_df, dense_features, sparse_features):
data_df[dense_features] = data_df[dense_features].fillna(0.0)
for f in dense_features:
data_df[f] = data_df[f].apply(lambda x: np.log(x+1) if x > -1 else -1)
data_df[sparse_features] = data_df[sparse_features].fillna("-1")
for f in sparse_features:
lbe = LabelEncoder()
data_df[f] = lbe.fit_transform(data_df[f])
return data_df[dense_features + sparse_features]
def build_input_layers(feature_columns):
# 构建Input层字典,并以dense和sparse两类字典的形式返回
dense_input_dict, sparse_input_dict = {}, {}
for fc in feature_columns:
if isinstance(fc, SparseFeat):
sparse_input_dict[fc.name] = Input(shape=(1, ), name=fc.name)
elif isinstance(fc, DenseFeat):
dense_input_dict[fc.name] = Input(shape=(fc.dimension, ), name=fc.name)
return dense_input_dict, sparse_input_dict
def build_embedding_layers(feature_columns, input_layers_dict, is_linear):
# 定义一个embedding层对应的字典
embedding_layers_dict = dict()
# 将特征中的sparse特征筛选出来
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if feature_columns else []
# 如果是用于线性部分的embedding层,其维度为1,否则维度就是自己定义的embedding维度
if is_linear:
for fc in sparse_feature_columns:
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size, 1, name='1d_emb_' + fc.name)
else:
for fc in sparse_feature_columns:
embedding_layers_dict[fc.name] = Embedding(fc.vocabulary_size, fc.embedding_dim, name='kd_emb_' + fc.name)
return embedding_layers_dict
def get_linear_logits(dense_input_dict, sparse_input_dict, sparse_feature_columns):
# 将所有的dense特征的Input层,然后经过一个全连接层得到dense特征的logits
concat_dense_inputs = Concatenate(axis=1)(list(dense_input_dict.values()))
dense_logits_output = Dense(1)(concat_dense_inputs)
# 获取linear部分sparse特征的embedding层,这里使用embedding的原因是:
# 对于linear部分直接将特征进行onehot然后通过一个全连接层,当维度特别大的时候,计算比较慢
# 使用embedding层的好处就是可以通过查表的方式获取到哪些非零的元素对应的权重,然后在将这些权重相加,效率比较高
linear_embedding_layers = build_embedding_layers(sparse_feature_columns, sparse_input_dict, is_linear=True)
# 将一维的embedding拼接,注意这里需要使用一个Flatten层,使维度对应
sparse_1d_embed = []
for fc in sparse_feature_columns:
feat_input = sparse_input_dict[fc.name]
embed = Flatten()(linear_embedding_layers[fc.name](feat_input))
sparse_1d_embed.append(embed)
# embedding中查询得到的权重就是对应onehot向量中一个位置的权重,所以后面不用再接一个全连接了,本身一维的embedding就相当于全连接
# 只不过是这里的输入特征只有0和1,所以直接向非零元素对应的权重相加就等同于进行了全连接操作(非零元素部分乘的是1)
sparse_logits_output = Add()(sparse_1d_embed)
# 最终将dense特征和sparse特征对应的logits相加,得到最终linear的logits
linear_part = Add()([dense_logits_output, sparse_logits_output])
return linear_part
class BiInteractionPooling(Layer):
def __init__(self):
super(BiInteractionPooling, self).__init__()
def call(self, inputs):
# 优化后的公式为: 0.5 * (和的平方-平方的和) =>> B x k
concated_embeds_value = inputs # B x n x k
square_of_sum = tf.square(tf.reduce_sum(concated_embeds_value, axis=1, keepdims=False)) # B x k
sum_of_square = tf.reduce_sum(concated_embeds_value * concated_embeds_value, axis=1, keepdims=False) # B x k
cross_term = 0.5 * (square_of_sum - sum_of_square) # B x k
return cross_term
def compute_output_shape(self, input_shape):
return (None, input_shape[2])
def get_bi_interaction_pooling_output(sparse_input_dict, sparse_feature_columns, dnn_embedding_layers):
# 只考虑sparse的二阶交叉,将所有的embedding拼接到一起
# 这里在实际运行的时候,其实只会将那些非零元素对应的embedding拼接到一起
# 并且将非零元素对应的embedding拼接到一起本质上相当于已经乘了x, 因为x中的值是1(公式中的x)
sparse_kd_embed = []
for fc in sparse_feature_columns:
feat_input = sparse_input_dict[fc.name]
_embed = dnn_embedding_layers[fc.name](feat_input) # B x 1 x k
sparse_kd_embed.append(_embed)
# 将所有sparse的embedding拼接起来,得到 (n, k)的矩阵,其中n为特征数,k为embedding大小
concat_sparse_kd_embed = Concatenate(axis=1)(sparse_kd_embed) # B x n x k
pooling_out = BiInteractionPooling()(concat_sparse_kd_embed)
return pooling_out
def get_dnn_logits(pooling_out):
# dnn层,这里的Dropout参数,Dense中的参数都可以自己设定, 论文中还说使用了BN, 但是个人觉得BN和dropout同时使用
# 可能会出现一些问题,感兴趣的可以尝试一些,这里就先不加上了
dnn_out = Dropout(0.5)(Dense(1024, activation='relu')(pooling_out))
dnn_out = Dropout(0.3)(Dense(512, activation='relu')(dnn_out))
dnn_out = Dropout(0.1)(Dense(256, activation='relu')(dnn_out))
dnn_logits = Dense(1)(dnn_out)
return dnn_logits
def NFM(linear_feature_columns, dnn_feature_columns):
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
# 将linear部分的特征中sparse特征筛选出来,后面用来做1维的embedding
linear_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns))
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
# linear_logits由两部分组成,分别是dense特征的logits和sparse特征的logits
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_sparse_feature_columns)
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
# embedding层用户构建FM交叉部分和DNN的输入部分
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
# 将输入到dnn中的sparse特征筛选出来
dnn_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))
pooling_output = get_bi_interaction_pooling_output(sparse_input_dict, dnn_sparse_feature_columns, embedding_layers) # B x (n(n-1)/2)
# 论文中说到在池化之后加上了BN操作
pooling_output = BatchNormalization()(pooling_output)
dnn_logits = get_dnn_logits(pooling_output)
# 将linear,dnn的logits相加作为最终的logits
output_logits = Add()([linear_logits, dnn_logits])
# 这里的激活函数使用sigmoid
output_layers = Activation("sigmoid")(output_logits)
model = Model(input_layers, output_layers)
return model
if __name__ == "__main__":
# 读取数据
data = pd.read_csv('./data/criteo_sample.txt')
# 划分dense和sparse特征
columns = data.columns.values
dense_features = [feat for feat in columns if 'I' in feat]
sparse_features = [feat for feat in columns if 'C' in feat]
# 简单的数据预处理
train_data = data_process(data, dense_features, sparse_features)
train_data['label'] = data['label']
# 将特征分组,分成linear部分和dnn部分(根据实际场景进行选择),并将分组之后的特征做标记(使用DenseFeat, SparseFeat)
linear_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)
for feat in dense_features]
dnn_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)
for feat in dense_features]
# 构建NFM模型
history = NFM(linear_feature_columns, dnn_feature_columns)
history.summary()
history.compile(optimizer="adam",
loss="binary_crossentropy",
metrics=["binary_crossentropy", tf.keras.metrics.AUC(name='auc')])
# 将输入数据转化成字典的形式输入
train_model_input = {name: data[name] for name in dense_features + sparse_features}
# 模型训练
history.fit(train_model_input, train_data['label'].values,
batch_size=64, epochs=5, validation_split=0.2, )
训练结果
Total params: 672,925
Trainable params: 672,917
Non-trainable params: 8
__________________________________________________________________________________________________
Epoch 1/5
3/3 [==============================] - 1s 245ms/step - loss: 1.6539 - binary_crossentropy: 1.6539 - auc: 0.4551 - val_loss: 1.3856 - val_binary_crossentropy: 1.3856 - val_auc: 0.4601
Epoch 2/5
3/3 [==============================] - 0s 18ms/step - loss: 1.2138 - binary_crossentropy: 1.2138 - auc: 0.5016 - val_loss: 1.1914 - val_binary_crossentropy: 1.1914 - val_auc: 0.4644
Epoch 3/5
3/3 [==============================] - 0s 18ms/step - loss: 0.7241 - binary_crossentropy: 0.7241 - auc: 0.6163 - val_loss: 0.9865 - val_binary_crossentropy: 0.9865 - val_auc: 0.4644
Epoch 4/5
3/3 [==============================] - 0s 18ms/step - loss: 0.7129 - binary_crossentropy: 0.7129 - auc: 0.7653 - val_loss: 0.9532 - val_binary_crossentropy: 0.9532 - val_auc: 0.4658
Epoch 5/5
3/3 [==============================] - 0s 17ms/step - loss: 0.5924 - binary_crossentropy: 0.5924 - auc: 0.8429 - val_loss: 1.0116 - val_binary_crossentropy: 1.0116 - val_auc: 0.4644
总结
NFM相对更好理解,但要更深入理解,还是得啃论文