一个系列搞懂Mysql数据库12:从实践sql语句优化开始
Table of Contents
- 字段
- 索引
- 查询SQL
- 引擎
- MyISAM
- InnoDB
- 0、自己写的海量数据sql优化实践
- mysql百万级分页优化
- 普通分页
- 优化分页
- 总结
除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑、部署、运维的各种复杂度,一般以整型值为主的表在千万级以下,字符串为主的表在五百万以下是没有太大问题的。而事实上很多时候MySQL单表的性能依然有不少优化空间,甚至能正常支撑千万级以上的数据量:
字段
-
尽量使用
TINYINT、SMALLINT、MEDIUM_INT作为整数类型而非INT,如果非负则加上UNSIGNED -
VARCHAR的长度只分配真正需要的空间 -
使用枚举或整数代替字符串类型
-
尽量使用
TIMESTAMP而非DATETIME, -
单表不要有太多字段,建议在20以内
-
避免使用NULL字段,很难查询优化且占用额外索引空间
-
用整型来存IP
索引
-
索引并不是越多越好,要根据查询有针对性的创建,考虑在
WHERE和ORDER BY命令上涉及的列建立索引,可根据EXPLAIN来查看是否用了索引还是全表扫描 -
应尽量避免在
WHERE子句中对字段进行NULL值判断,否则将导致引擎放弃使用索引而进行全表扫描 -
值分布很稀少的字段不适合建索引,例如"性别"这种只有两三个值的字段
-
字符字段只建前缀索引
-
字符字段最好不要做主键
-
不用外键,由程序保证约束
-
尽量不用
UNIQUE,由程序保证约束 -
使用多列索引时主意顺序和查询条件保持一致,同时删除不必要的单列索引
查询SQL
-
可通过开启慢查询日志来找出较慢的SQL
-
不做列运算:
SELECT id WHERE age + 1 = 10,任何对列的操作都将导致表扫描,它包括数据库教程函数、计算表达式等等,查询时要尽可能将操作移至等号右边 -
sql语句尽可能简单:一条sql只能在一个cpu运算;大语句拆小语句,减少锁时间;一条大sql可以堵死整个库
-
不用
SELECT * -
OR改写成IN:OR的效率是n级别,IN的效率是log(n)级别,in的个数建议控制在200以内 -
不用函数和触发器,在应用程序实现
-
避免
%xxx式查询 -
少用
JOIN -
使用同类型进行比较,比如用
'123'和'123'比,123和123比 -
尽量避免在
WHERE子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描 -
对于连续数值,使用
BETWEEN不用IN:SELECT id FROM t WHERE num BETWEEN 1 AND 5 -
列表数据不要拿全表,要使用
LIMIT来分页,每页数量也不要太大
引擎
目前广泛使用的是MyISAM和InnoDB两种引擎:
MyISAM
MyISAM引擎是MySQL 5.1及之前版本的默认引擎,它的特点是:
-
不支持行锁,读取时对需要读到的所有表加锁,写入时则对表加排它锁
-
不支持事务
-
不支持外键
-
不支持崩溃后的安全恢复
-
在表有读取查询的同时,支持往表中插入新纪录
-
支持
BLOB和TEXT的前500个字符索引,支持全文索引 -
支持延迟更新索引,极大提升写入性能
-
对于不会进行修改的表,支持压缩表,极大减少磁盘空间占用
InnoDB
InnoDB在MySQL 5.5后成为默认索引,它的特点是:
-
支持行锁,采用MVCC来支持高并发
-
支持事务
-
支持外键
-
支持崩溃后的安全恢复
-
不支持全文索引
总体来讲,MyISAM适合SELECT密集型的表,而InnoDB适合INSERT和UPDATE密集型的表
0、自己写的海量数据sql优化实践
首先是建表和导数据的过程。
参考https://nsimple.top/archives/mysql-create-million-data.html
有时候我们需要对大数据进行测试,本地一般没有那么多数据,就需要我们自己生成一些。下面会借助内存表的特点进行生成百万条测试数据。
- 创建一个临时内存表, 做数据插入的时候会比较快些
SQL
-- 创建一个临时内存表DROP TABLE IF EXISTS `vote_record_memory`;CREATE TABLE `vote_record_memory` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `user_id` varchar(20) NOT NULL DEFAULT '', `vote_num` int(10) unsigned NOT NULL DEFAULT '0', `group_id` int(10) unsigned NOT NULL DEFAULT '0', `status` tinyint(2) unsigned NOT NULL DEFAULT '1', `create_time` datetime NOT NULL DEFAULT '0000-00-00 00:00:00', PRIMARY KEY (`id`), KEY `index_user_id` (`user_id`) USING HASH) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
- – 创建一个普通表,用作模拟大数据的测试用例
SQL
DROP TABLE IF EXISTS `vote_record`;CREATE TABLE `vote_record` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `user_id` varchar(20) NOT NULL DEFAULT '' COMMENT '用户Id', `vote_num` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '投票数', `group_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '用户组id 0-未激活用户 1-普通用户 2-vip用户 3-管理员用户', `status` tinyint(2) unsigned NOT NULL DEFAULT '1' COMMENT '状态 1-正常 2-已删除', `create_time` int(10) unsigned NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '创建时间', PRIMARY KEY (`id`), KEY `index_user_id` (`user_id`) USING HASH COMMENT '用户ID哈希索引') ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='投票记录表';
- 为了数据的随机性和真实性,我们需要创建一个可生成长度为n的随机字符串的函数。
SQL
-- 创建生成长度为n的随机字符串的函数DELIMITER // -- 修改MySQL delimiter:'//'DROP FUNCTION IF EXISTS `rand_string` //SET NAMES utf8 //CREATE FUNCTION `rand_string` (n INT) RETURNS VARCHAR(255) CHARSET 'utf8'BEGIN DECLARE char_str varchar(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789'; DECLARE return_str varchar(255) DEFAULT ''; DECLARE i INT DEFAULT 0; WHILE i < n DO SET return_str = concat(return_str, substring(char_str, FLOOR(1 + RAND()*62), 1)); SET i = i+1; END WHILE; RETURN return_str;END //
- 为了操作方便,我们再创建一个插入数据的存储过程
SQL
-- 创建插入数据的存储过程DROP PROCEDURE IF EXISTS `add_vote_record_memory` //CREATE PROCEDURE `add_vote_record_memory`(IN n INT)BEGIN DECLARE i INT DEFAULT 1; DECLARE vote_num INT DEFAULT 0; DECLARE group_id INT DEFAULT 0; DECLARE status TINYINT DEFAULT 1; WHILE i < n DO SET vote_num = FLOOR(1 + RAND() * 10000); SET group_id = FLOOR(0 + RAND()*3); SET status = FLOOR(1 + RAND()*2); INSERT INTO `vote_record_memory` VALUES (NULL, rand_string(20), vote_num, group_id, status, NOW()); SET i = i + 1; END WHILE;END //DELIMITER ; -- 改回默认的 MySQL delimiter:';'
- 开始执行存储过程,等待生成数据(10W条生成大约需要40分钟)
SQL
-- 调用存储过程 生成100W条数据CALL add_vote_record_memory(1000000);
- 查询内存表已生成记录(为了下步测试,目前仅生成了105645条)
SQL
SELECT count(*) FROM `vote_record_memory`;-- count(*)-- 105646
- 把数据从内存表插入到普通表中(10w条数据13s就插入完了)
SQL
INSERT INTO vote_record SELECT * FROM `vote_record_memory`;
- 查询普通表已的生成记录
SQL
SELECT count(*) FROM `vote_record`;-- count(*)-- 105646
- 如果一次性插入普通表太慢,可以分批插入,这就需要写个存储过程了:
SQL
-- 参数n是每次要插入的条数-- lastid是已导入的最大idCREATE PROCEDURE `copy_data_from_tmp`(IN n INT)BEGIN DECLARE lastid INT DEFAULT 0; SELECT MAX(id) INTO lastid FROM `vote_record`; INSERT INTO `vote_record` SELECT * FROM `vote_record_memory` where id > lastid LIMIT n;END
- 调用存储过程:
SQL
-- 调用存储过程 插入60w条CALL copy_data_from_tmp(600000);
SELECT * FROM vote_record;
全表查询
建完表以后开启慢查询日志,具体参考下面的例子,然后学会用explain。windows慢日志的位置在c盘,另外,使用client工具也可以记录慢日志,所以不一定要用命令行来执行测试,否则大表数据在命令行中要显示的非常久。
1 全表扫描select * from vote_record
慢日志
SET timestamp=1529034398; select * from vote_record;
Time: 2018-06-15T03:52:58.804850Z
User@Host: root[root] @ localhost [::1] Id: 74
Query_time: 3.166424 Lock_time: 0.000000 Rows_sent: 900500 Rows_examined: 999999
耗时3秒,我设置的门槛是一秒。所以记录了下来。
explain执行计划
id select_type table partitions type possible_keys key key_len ref rows filtered Extra
1 SIMPLE vote_record \N ALL \N \N \N \N 996507 100.00 \N
全表扫描耗时3秒多,用不到索引。
2 select * from vote_record where vote_num > 1000
没有索引,所以相当于全表扫描,一样是3.5秒左右
3 select * from vote_record where vote_num > 1000
**加索引create **
CREATE INDEX vote ON vote_record(vote_num);
explain查看执行计划
id select_type table partitions type possible_keys key key_len ref rows filtered Extra
1 SIMPLE vote_record \N ALL votenum,vote \N \N \N 996507 50.00 Using where
还是没用到索引,因为不符合最左前缀匹配。查询需要3.5秒左右
最后修改一下sql语句
EXPLAIN SELECT * FROM vote_record WHERE id > 0 AND vote_num > 1000;
id select_type table partitions type possible_keys key key_len ref rows filtered Extra
1 SIMPLE vote_record \N range PRIMARY,votenum,vote PRIMARY 4 \N 498253 50.00 Using where
用到了索引,但是只用到了主键索引。再修改一次
EXPLAIN SELECT * FROM vote_record WHERE id > 0 AND vote_num = 1000;
id select_type table partitions type possible_keys key key_len ref rows filtered Extra
1 SIMPLE vote_record \N index_merge PRIMARY,votenum,vote votenum,PRIMARY 8,4 \N 51 100.00 Using intersect(votenum,PRIMARY); Using where
用到了两个索引,votenum,PRIMARY。
这是为什么呢。
再看一个语句
EXPLAIN SELECT * FROM vote_record WHERE id = 1000 AND vote_num > 1000
id select_type table partitions type possible_keys key key_len ref rows filtered Extra
1 SIMPLE vote_record \N const PRIMARY,votenum PRIMARY 4 const 1 100.00 \N
也只有主键用到了索引。这是因为只有最左前缀索引可以用>或<,其他索引用<或者>会导致用不到索引。
下面是几个网上参考的例子:
一:索引是sql语句优化的关键,学会使用慢日志和执行计划分析sql
背景:使用A电脑安装mysql,B电脑通过xshell方式连接,数据内容我都已经创建好,现在我已正常的进入到mysql中
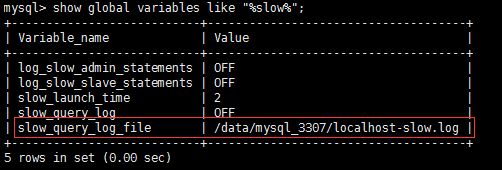
步骤1:设置慢查询日志的超时时间,先查看日志存放路径查询慢日志的地址,因为有慢查询的内容,就会到这个日志中:
show global variables like "%slow%";
2.开启慢查询日志
set global slow_query_log=on;
3.查看慢查询日志的设置时间,是否是自己需要的
show global variables like "%long%";
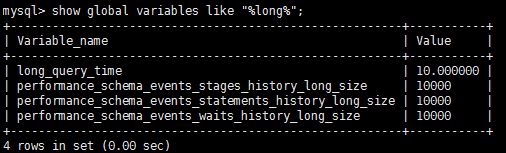
4.如果不是自己想的时间,修改慢查询时间,只要超过了以下的设置时间,查询的日志就会到刚刚的日志中,我设置查询时间超过1S就进入到慢查询日志中
set global long_query_time=1;
5.大数据已准备,进行数据的查询,xshell最好开两个窗口,一个查看日志,一个执行内容
Sql查询语句:select sql_no_cache * from employees_tmp where first_name='Duangkaew' and gender='M'

发现查数据的总时间去掉了17.74S
查看日志:打开日志
![]()

标记1:执行的sql语句
标记2:执行sql的时间,我的是10点52执行的
标记3:使用那台机器
标记4:执行时间,query_tims,查询数据的时间
标记5:不知道是干嘛的
标记6:执行耗时的sql语句,我在想我1的应该是截取错了!但是记住最后一定是显示耗时是因为执行什么sql造成的
6.执行打印计划,主要是查看是否使用了索引等其他内容,主要就是在sql前面加上explain 关键字
explain select sql_no_cache * from employees_tmp where first_name='Duangkaew' and gender='M';

描述extra中,表示只使用了where条件,没有其他什么索引之类的
7.进行sql优化,建一个fist_name的索引,索引就是将你需要的数据先给筛选出来,这样就可以节省很多扫描时间
create index firstname on employees_tmp(first_name);

注:创建索引时会很慢,是对整个表做了一个复制功能,并进行数据的一些分类(我猜是这样,所以会很慢)
8.查看建立的索引
show index from employees_tmp;

9.在执行查询语句,查看语句的执行时间
select sql_no_cache * from employees_tmp where first_name='Duangkaew' and gender='M'

发现时间已经有所提升了,其实选择索引也不一开始就知道,我们在试试使用性别,gender进行索引
10.删除已经有的索引,删除索引:
drop index first_name on employees_tmp;
11.创建性别的索引(性别是不怎么好的索引方式,因为有很多重复数据)
create index index_gendar on employees_tmp(gender);
在执行sql语句查询数据,查看查询执行时间,没有创建比较优秀的索引,导致查询时间还变长了,
为嘛还变长了,这个我没有弄懂

12.我们在试试使用创建组合索引,使用性别和姓名
alter table employees_tmp add index idx_union (first_name,gender);
在执行sql查看sql数据的执行时间
select sql_no_cache * from employees_tmp where first_name='Duangkaew' and gender='M'
速度提升了N多倍啊

查看创建的索引
show index from employees_tmp;
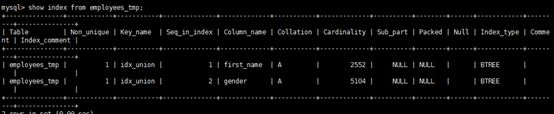
索引建的好真的一个好帮手,建不好就是费时的一个操作
目前还不知道为什么建立性别的索引会这么慢
二:sql优化注意要点,比如索引是否用到,查询优化是否改变了执行计划,以及一些细节
场景
我用的数据库是mysql5.6,下面简单的介绍下场景
课程表
create table Course( c_id int PRIMARY KEY, name varchar(10) )
数据100条
学生表:
create table Student( id int PRIMARY KEY, name varchar(10) )
数据70000条
学生成绩表SC
CREATE table SC( sc_id int PRIMARY KEY, s_id int, c_id int, score int )
数据70w条
查询目的:
查找语文考100分的考生
查询语句:
select s.* from Student s where s.s_id in (select s_id from SC sc where sc.c_id = 0 and sc.score = 100 )
执行时间:30248.271s
晕,为什么这么慢,先来查看下查询计划:
EXPLAIN select s.* from Student s where s.s_id in (select s_id from SC sc where sc.c_id = 0 and sc.score = 100 )
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NwqjOR7A-1599269361887)(http://static.codeceo.com/images/2015/04/d70d7123827c0d988fdc69074a97105b.png “image”)]
发现没有用到索引,type全是ALL,那么首先想到的就是建立一个索引,建立索引的字段当然是在where条件的字段。
先给sc表的c_id和score建个索引
CREATE index sc_c_id_index on SC(c_id);
CREATE index sc_score_index on SC(score);
再次执行上述查询语句,时间为: 1.054s
快了3w多倍,大大缩短了查询时间,看来索引能极大程度的提高查询效率,看来建索引很有必要,很多时候都忘记建
索引了,数据量小的的时候压根没感觉,这优化感觉挺爽。
但是1s的时间还是太长了,还能进行优化吗,仔细看执行计划:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-465nizjA-1599269361887)(http://static.codeceo.com/images/2015/04/5f5a2cffb3c1f46725c97891f38de796.png “image”)]
查看优化后的sql:
SELECT `YSB`.`s`.`s_id` AS `s_id`, `YSB`.`s`.`name` AS `name`FROM `YSB`.`Student` `s`WHERE < in_optimizer > ( `YSB`.`s`.`s_id` ,< EXISTS > ( SELECT 1 FROM `YSB`.`SC` `sc` WHERE ( (`YSB`.`sc`.`c_id` = 0) AND (`YSB`.`sc`.`score` = 100) AND ( < CACHE > (`YSB`.`s`.`s_id`) = `YSB`.`sc`.`s_id` ) ) ) )
补充:这里有网友问怎么查看优化后的语句
方法如下:
在命令窗口执行
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V65Pecs0-1599269361888)(http://static.codeceo.com/images/2015/04/0e19723574e5c7933c06775b4ddc288c.png “image”)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Taz51awz-1599269361888)(http://static.codeceo.com/images/2015/04/077cd791216230276824fa4fdff5f965.png “image”)]
有type=all
按照我之前的想法,该sql的执行的顺序应该是先执行子查询
select s_id from SC sc where sc.c_id = 0 and sc.score = 100
耗时:0.001s
得到如下结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mroOxmY4-1599269361889)(http://static.codeceo.com/images/2015/04/18f95079548bd3f27aaa0a335cf07a52.png “image”)]
然后再执行
select s.* from Student s where s.s_id in(7,29,5000)
耗时:0.001s
这样就是相当快了啊,Mysql竟然不是先执行里层的查询,而是将sql优化成了exists子句,并出现了EPENDENT SUBQUERY,
mysql是先执行外层查询,再执行里层的查询,这样就要循环70007*11=770077次。
那么改用连接查询呢?
SELECT s.* from Student s INNER JOIN SC sc on sc.s_id = s.s_id where sc.c_id=0 and sc.score=100
这里为了重新分析连接查询的情况,先暂时删除索引sc_c_id_index,sc_score_index
执行时间是:0.057s
效率有所提高,看看执行计划:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KzQPCy8Y-1599269361889)(http://static.codeceo.com/images/2015/04/bd52af34bf50067236e4857ce214ecff.png “image”)]
这里有连表的情况出现,我猜想是不是要给sc表的s_id建立个索引
CREATE index sc_s_id_index on SC(s_id);
show index from SC
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fhMkMKY2-1599269361890)(http://static.codeceo.com/images/2015/04/729e4844ae44553d1422d480dc8c0e0a.png “image”)]
在执行连接查询
时间: 1.076s,竟然时间还变长了,什么原因?查看执行计划:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aaC5CWqT-1599269361890)(http://static.codeceo.com/images/2015/04/ac1b338ea87df2dba5577abf413833cb.png “image”)]
优化后的查询语句为:
SELECT `YSB`.`s`.`s_id` AS `s_id`, `YSB`.`s`.`name` AS `name`FROM `YSB`.`Student` `s`JOIN `YSB`.`SC` `sc`WHERE ( ( `YSB`.`sc`.`s_id` = `YSB`.`s`.`s_id` ) AND (`YSB`.`sc`.`score` = 100) AND (`YSB`.`sc`.`c_id` = 0) )
貌似是先做的连接查询,再执行的where过滤
回到前面的执行计划:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-euSpLnzS-1599269361890)(http://static.codeceo.com/images/2015/04/7d46786578e5b88a00b59c4ebab098d9.png “image”)]
这里是先做的where过滤,再做连表,执行计划还不是固定的,那么我们先看下标准的sql执行顺序:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ax0anrCu-1599269361891)(http://static.codeceo.com/images/2015/04/9ca2a9a19c797c4e6d6d8c6959433b92.png “image”)]
正常情况下是先join再where过滤,但是我们这里的情况,如果先join,将会有70w条数据发送join做操,因此先执行where
过滤是明智方案,现在为了排除mysql的查询优化,我自己写一条优化后的sql
SELECT s.*FROM ( SELECT * FROM SC sc WHERE sc.c_id = 0 AND sc.score = 100 ) tINNER JOIN Student s ON t.s_id = s.s_id
即先执行sc表的过滤,再进行表连接,执行时间为:0.054s
和之前没有建s_id索引的时间差不多
查看执行计划:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ck32jiic-1599269361891)(http://static.codeceo.com/images/2015/04/570a833e7153af710a59b9da940d56d9.png “image”)]
先提取sc再连表,这样效率就高多了,现在的问题是提取sc的时候出现了扫描表,那么现在可以明确需要建立相关索引
CREATE index sc_c_id_index on SC(c_id);
CREATE index sc_score_index on SC(score);
再执行查询:
SELECT s.*FROM ( SELECT * FROM SC sc WHERE sc.c_id = 0 AND sc.score = 100 ) tINNER JOIN Student s ON t.s_id = s.s_id
执行时间为:0.001s,这个时间相当靠谱,快了50倍
执行计划:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WW2zrVhJ-1599269361891)(http://static.codeceo.com/images/2015/04/0c66c0f779dcecfda9c69039a0fe3751.png “image”)]
我们会看到,先提取sc,再连表,都用到了索引。
那么再来执行下sql
SELECT s.* from Student s INNER JOIN SC sc on sc.s_id = s.s_id where sc.c_id=0 and sc.score=100
执行时间0.001s
执行计划:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KBNazOJI-1599269361892)(http://static.codeceo.com/images/2015/04/0fd83ae9e1fae07ad9d55c2f5b15e259.png “image”)]
这里是mysql进行了查询语句优化,先执行了where过滤,再执行连接操作,且都用到了索引。
总结:
1.mysql嵌套子查询效率确实比较低
2.可以将其优化成连接查询
3.建立合适的索引
4.学会分析sql执行计划,mysql会对sql进行优化,所以分析执行计划很重要
由于时间问题,这篇文章先写到这里,后续再分享其他的sql优化经历。
三、海量数据分页查找时如何使用主键索引进行优化
mysql百万级分页优化
普通分页
数据分页在网页中十分多见,分页一般都是limit start,offset,然后根据页码page计算start
select * from user limit **1**,**20**
这种分页在几十万的时候分页效率就会比较低了,MySQL需要从头开始一直往后计算,这样大大影响效率
SELECT * from user limit **100001**,**20**; //time **0**.151s explain SELECT * from user limit **100001**,**20**;
我们可以用explain分析下语句,没有用到任何索引,MySQL执行的行数是16W+,于是我们可以想用到索引去实现分页

优化分页
使用主键索引来优化数据分页
select * from user where id>(select id from user where id>=**100000** limit **1**) limit **20**; //time **0**.003s
使用explain分析语句,MySQL这次扫描的行数是8W+,时间也大大缩短。
explain select * from user where id>(select id from user where id>=**100000** limit **1**) limit **20**;

总结
在数据量比较大的时候,我们尽量去利用索引来优化语句。上面的优化方法如果id不是主键索引,查询效率比第一种还要低点。我们可以先使用explain来分析语句,查看语句的执行顺序和执行性能。
转载于:https://my.oschina.net/alicoder/blog/3097141