ChineseNER——BILSTM-CRF 命名实体识别 (一)
部分内容转载自:https://www.jianshu.com/p/495c23aa5560
作者:炼己者
博客:https://www.cnblogs.com/lookfor404/
序言:
感谢大佬!!!这位讲解的非常清楚,作为入门非常好。我针对这篇文章所引用的代码做了一些修改和使用。
本系列为学习记录。
先放上炼己者大佬的文章链接:https://www.jianshu.com/p/495c23aa5560
然后我先抄一遍炼己者大佬的文章哈哈
以下均为摘抄,我下一篇再写模型详解和一些其他问题哈。
一. 摘要
- 之前用CRF做了命名实体识别,效果还可以,最高达到0.9293,当然这是自己用sklearn写的计算F1值,后来用conlleval.pl对CRF测试结果进行评价,得到的F1值是0.9362。
- 接下来基于BILSTM-CRF做命名实体识别,代码不是自己写的,用的github上的一个大佬写的,换了自己的数据集,得到最终的结果是0.92。
- 本文主要简单的介绍下BILSTM-CRF的原理,以及如何把大佬的数据集换成我们自己的数据集,进行训练。
二. 正文
如果你想细致地了解BILSTM,那你首先得去看RNN(循环神经网络),然后再看RNN的升级版本LSTM,最好才能过渡到BILSTM。了解完这些再去看CRF(条件随机场),CRF这边可又是一番天地了,等你了解完你的老板该炒你鱿鱼了。所以对于初学者我一向主张不择手段先把模型跑下来,跑出结果,然后才有信心去好好学习原理。在这里还是要好好感谢那位大佬。
1. BILSTM-CRF的原理简介
如果你不懂什么叫做BILSTM,CRF,没关系,你只要知道他们是命名实体识别里两个层就行,就像神经网络里的概念一样,层次结构。
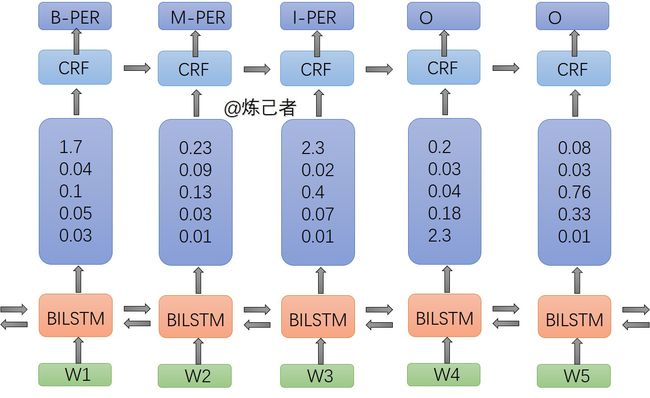
如上图,这里面做了一件什么事情呢?
- 输入是词向量,这个直接用word2vec训练就能得到
- 输出是每个句子预测的标签
流程
词向量输入到 BILSTM层 ,然后输出值是这句话每个标签的预测分数,这些分数便是 CEF层 的输入,其实没有CRF层我们也可以训练 BILSTM,但是我们就不能保证每次预测的都是对的,因为它有可能胡来,比如第一个预测的是B-PER,下一个预测的是B-ORG,这就不符合自然语言的规则了,所以我们加入了CRF这一层,用来约束这些标签,它可以自动地去学习这些约束。
那么CRF是怎么学习这些约束的呢?
简单地说就是计算每个标签下一个标签地概率,概率大就有可能出现这样的标签,概率小就不会出现了。
2. 他山之石,可以攻玉
1). 保证代码运行正确
我这里的环境是python3.6,经过如下改动可以正常运行。
Chinese NER:https://github.com/zjy-ucas/ChineseNER
大家点击去Clone下来就行
然后就是重点来了!!!
下载下来运行并不会那么顺利,会报错的
首先打开main.py文件,如果训练的话就是图中的两个True,如果测试的话就把图中的两个True改成False
flags = tf.app.flags
flags.DEFINE_boolean("clean", True, "clean train folder")
flags.DEFINE_boolean("train", True, "Wither train the model")错误1
TypeError: slice indices must be integers or None or have an index method
解决方案:遇到这个错误你就去data_utils.py文件里找到下面的代码,改一下即可这是一个int的问题,添加几个int类型转换
def sort_and_pad(self, data, batch_size):
num_batch = int(math.ceil(len(data) /batch_size))
sorted_data = sorted(data, key=lambda x: len(x[0]))
batch_data = list()
for i in range(num_batch):
batch_data.append(self.pad_data(sorted_data[i*int(batch_size) : (i+1)*int(batch_size)]))
return batch_data错误2
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xa3 in position 0: invalid start byte
解决方案:这个是编码问题,遇到这个问题你就进到utils.py里,找到下面的代码,加上一句encoding = 'utf-8'就OK了。我印象中是这几处,如果还报这个错误就继续排查类似的即可
def test_ner(results, path):
"""
Run perl script to evaluate model
"""
output_file = os.path.join(path, "ner_predict.utf8")
with open(output_file, "w", encoding='utf-8') as f:
to_write = []
for block in results:
for line in block:
to_write.append(line + "\n")
to_write.append("\n")
f.writelines(to_write)
eval_lines = return_report(output_file)
return eval_lines
def save_config(config, config_file):
"""
Save configuration of the model
parameters are stored in json format
"""
with open(config_file, "w", encoding="utf8") as f:
json.dump(config, f, ensure_ascii=False, indent=4)
def load_config(config_file):
"""
Load configuration of the model
parameters are stored in json format
"""
with open(config_file, encoding="utf8") as f:
return json.load(f)错误3
NameError: name 'os' is not defined
这个错误很奇怪,我是看到作者代码里有导入os的
解决方案:import os#这里我也看到最开始有import os 了。报错的那一行是flag里面的训练集路径参数,我在这个flag的前一行又import了一遍。
#就像下面这样,成功运行。
flags.DEFINE_string("emb_file", "wiki_100.utf8", "Path for pre_trained embedding")
import os
flags.DEFINE_string("train_file", os.path.join("data", "dev"), "Path for train data")
flags.DEFINE_string("dev_file", os.path.join("data", "dev"), "Path for dev data")
flags.DEFINE_string("test_file", os.path.join("data", "test"), "Path for test data")2). 更换数据集
打开下载下来的文件,data文件夹里面有三个文件,分别为验证,测试,训练数据集,你只需把你的数据集切分成这三份即可(比例自己定,我的是7:2:1)。
- 标签必须得是BIO格式,总之你的标签要和它的一模一样。
- 还有标识符,windows生成的数据集文件我们发现换行符都是\r\n,也就是在notpad++上打开的话,显示所有标识符后会发现CRLF,我们要把它改成LF。
可以用替换的方法,直接把\r\n替换成\n,这样就满足条件了#注:iobes和iob两种格式都可以作为训练集。传参内部有转换函数。
3). 训练
这些操作之后你就可以运行main.py了
三. 总结与展望
最近一直在努力地理解这些个原理,争取早日攻克它们。大家工作的话一般项目会比较紧急,没有时间给你慢慢理解原理,然后再去写代码做项目。所以要学会用别人的代码,改造它们,让它为自己所用。最后很感谢github的那位大佬,真的很厉害。希望这篇博客能帮到大家,谢谢各位