Convolutional Neural Network Hung-yi Lee 卷积神经网络 李宏毅
Convolutional Neural Network
- Why CNN for image
- The whole CNN
- CNN – Convolution
-
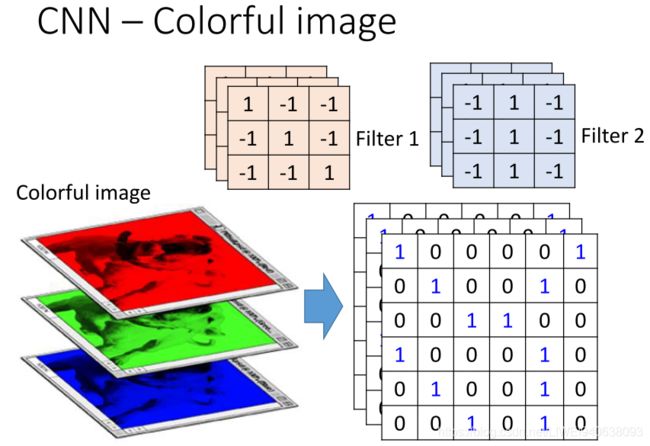
- CNN-Colorful image彩色图像
- Convolution v.s. Fully Connected
- CNN-Max Pooling
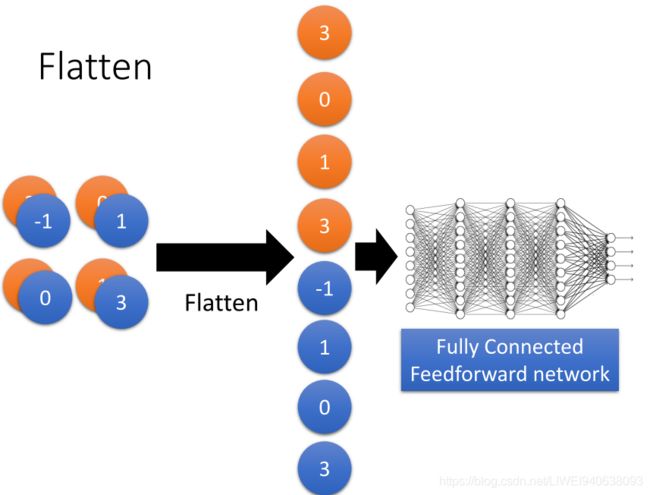
- Flatten
- CNN in Keras
- What does machine learn?
- How about higher layers?
- What dose CNN learn?
- Deep Dream
- Deep Style
- More Application:Playing Go
-
- Why CNN for playing Go?
- More Application: Speech
- More Application: Text
Can the network be simplified by considering the properties of images?
考虑到图像的性质,网络能被简化吗?
Why CNN for image
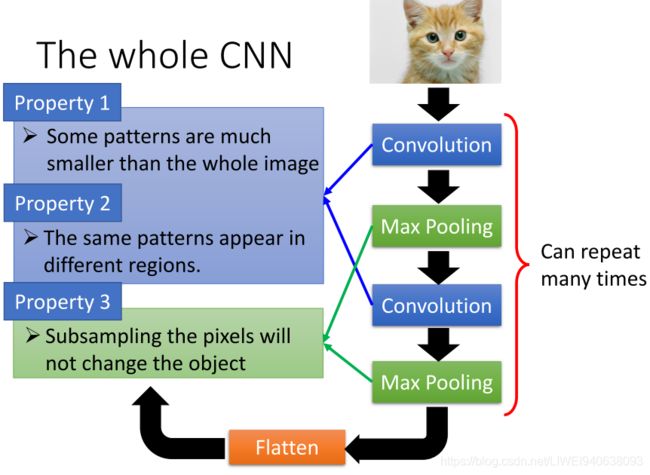
Some patterns are much smaller than the whole image
有些模式比整个图像小得多
A neuron does not have to see the whole image to discover the pattern.
神经元不需要看到整个图像来发现模式。
Connecting to small region with less parameters
连接到参数较少的小区域

The same patterns appear in different regions.
相同的模式出现在不同的区域。
“upper-left beak” detector 左上角喙探测器
Do almost the same thing,They can use the same set of parameters.做几乎相同的事情,他们可以使用相同的一组参数。
“middle beak” detector “中间喙”探测器

Subsampling the pixels will not change the object 对像素进行下采样不会改变对象
Subsampling 下采样

We can subsample the pixels to make image smaller——Less parameters for the network to process the image
对像素进行子采样,使图像更小——减少网络处理图像的参数
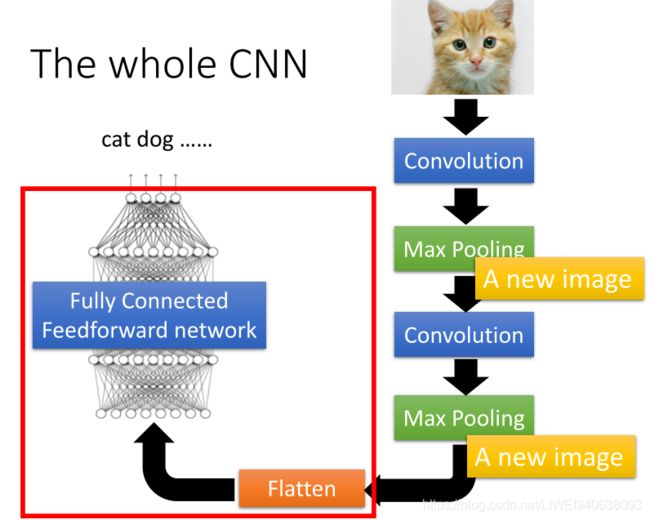
The whole CNN
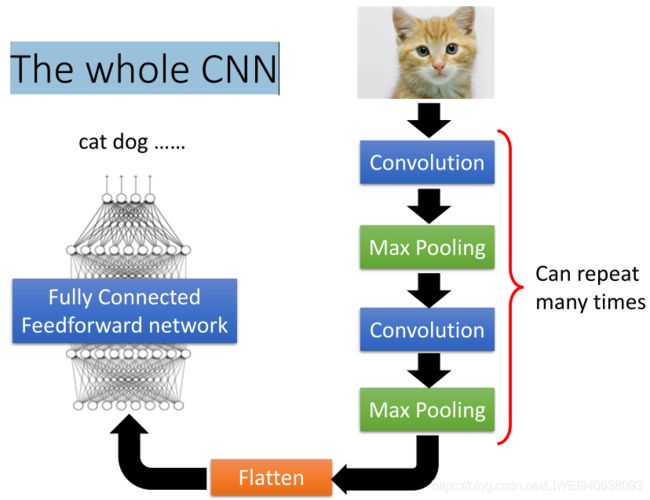
fltten:变平/变单调
Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。
fully connected feedforward network 全连接前馈网络
Convolution:
Property 1: Some patterns are much smaller than the whole image一些模式比整张图像小
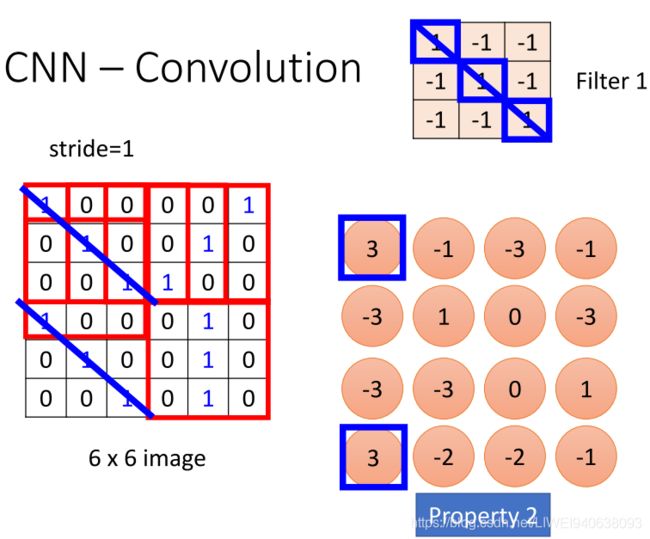
Property 2: The same patterns appear in different regions.相同模式出现在不同区域
Max Pooling:
Property 3: Subsampling the pixels will not change the object对像素下采样不会改变对象
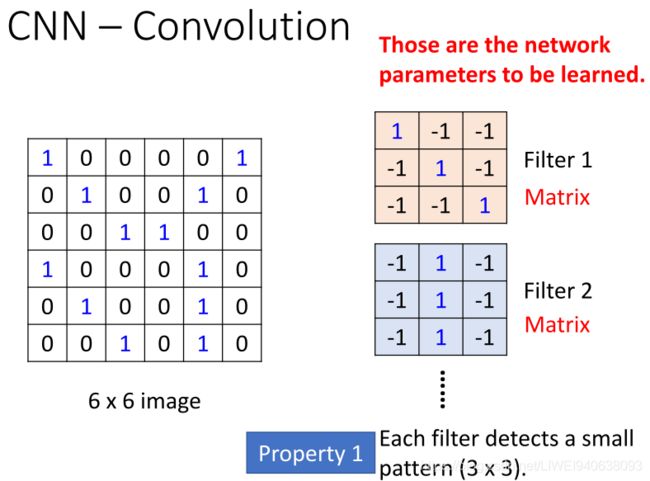
CNN – Convolution
Those are the network parameters to be learned.这些是需要学习的网络参数。
Filter 1 Matrix 过滤器1 矩阵
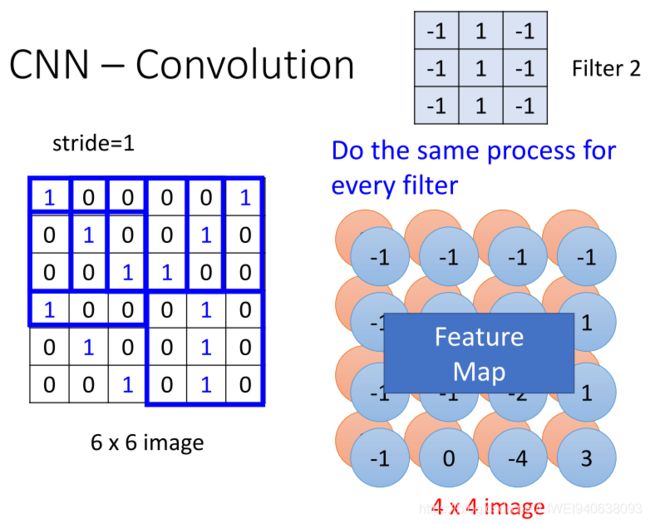
Filter 2 Matrix 过滤器2 矩阵
Property 1:Each filter detects a small pattern (3 x 3). 每个过滤器检测一个小的模式(3*3)
stride=1 移动步幅=1

If stride=2 移动步幅=2

下面的都设定步幅=1
下面的符合:Property 2: The same patterns appear in different regions.相同模式出现在不同区域
Filter 2 过滤器2
Do the same process for every filter每个过滤器做相同过程
Feature Map 特征图谱
CNN-Colorful image彩色图像
Convolution v.s. Fully Connected

卷积层仅连接9个输入,不是连接全部输入
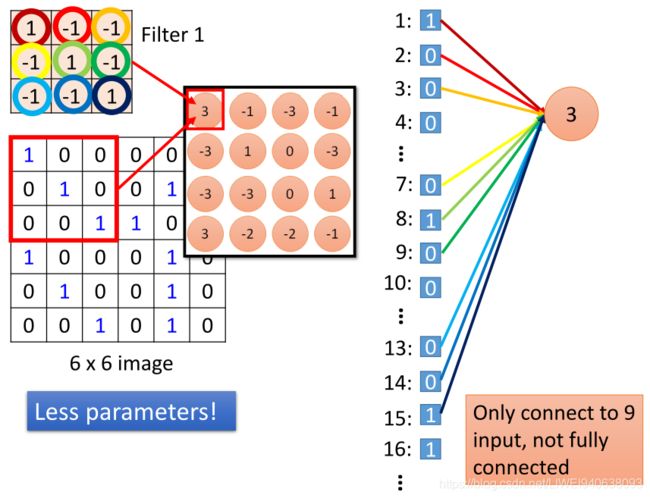
Less parameters!Even less parameters!
Shared weights 权值共享/共享权重

CNN-Max Pooling
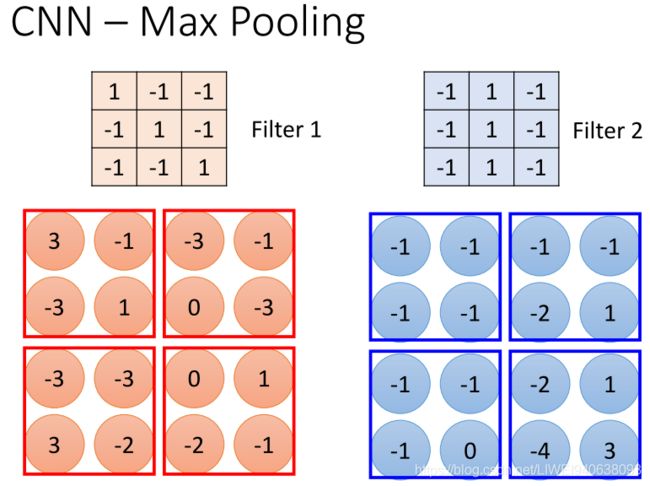
New image but smaller 新图像但更小
Each filter is a channel 每个过滤器都是一个通道

Smaller than the original image 比原图像小
The number of the channel is the number of filters 通道的数量就是过滤器的数量

Flatten
Fully Connected Feedforward network全连接前馈网络
Flatten层的实现在Keras.layers.core.Flatten()类中。
作用:
Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。
例子:
from keras.models import Sequential
from keras.layers.core import Flatten
from keras.layers.convolutional import Convolution2D
from keras.utils.vis_utils import plot_model
model = Sequential()
model.add(Convolution2D(64,3,3,border_mode="same",input_shape=(3,32,32)))
# now:model.output_shape==(None,64,32,32)
model.add(Flatten())
# now: model.output_shape==(None,65536)
plot_model(model, to_file='Flatten.png', show_shapes=True)
为了更好的理解Flatten层作用,我把这个神经网络进行可视化如下图:

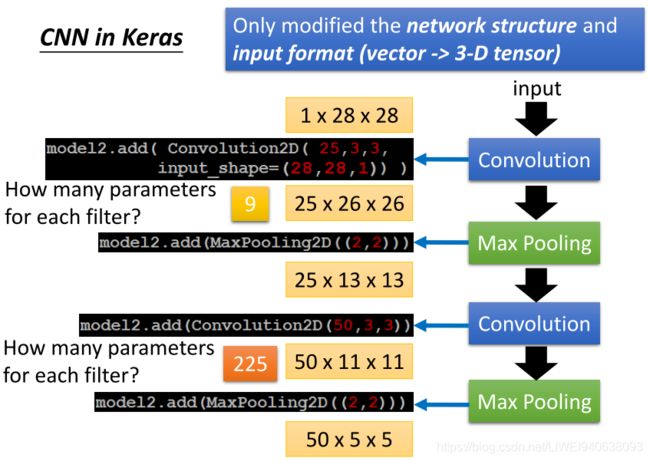
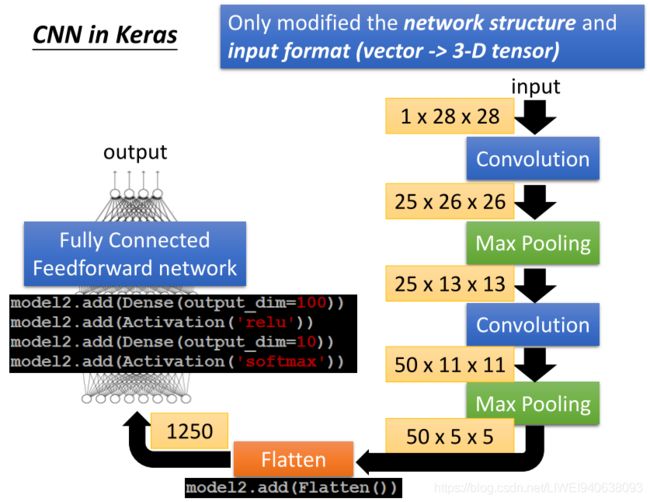
CNN in Keras
Only modified the network structure and input format (vector -> 3-D tensor)仅修改网络结构和输入格式(矢量 ->三维张量)

How many parameters for each filter?每个过滤器有多少参数?
What does machine learn?
Typical-looking filters on the trained first layer 在训练的第一层上使用典型的过滤器

How about higher layers?
Which images make a specific neuron activate?哪些图像会激活一个特定的神经元
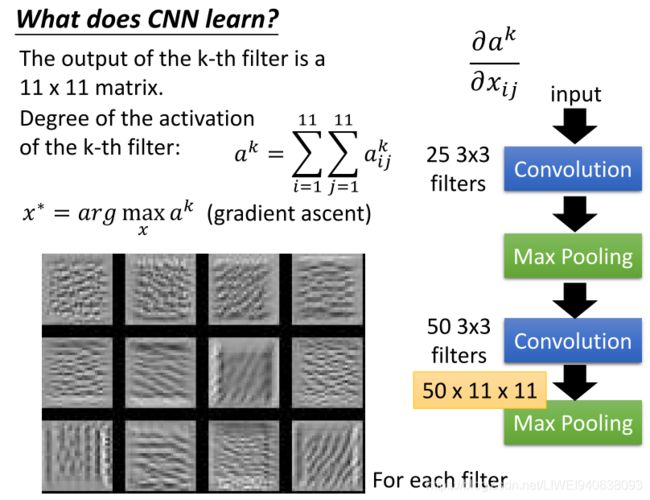
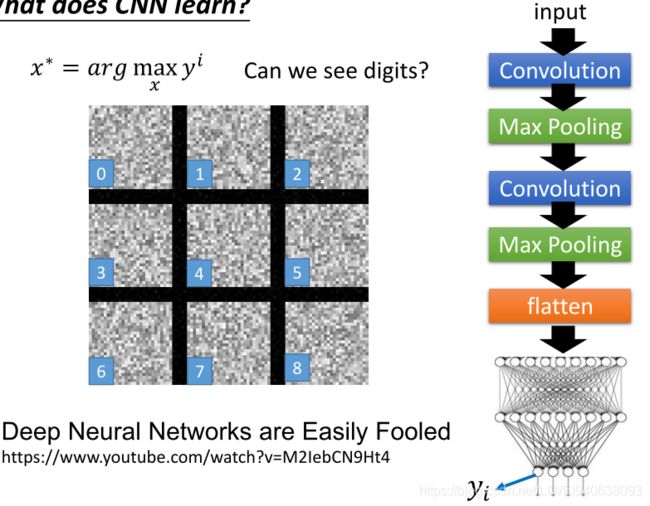
What dose CNN learn?
The output of the k-th filter is a 11 x 11 matrix. 第k个滤波器的输出是一个11x11矩阵。
Degree of the activation of the k-th filter:第k个滤波器的激活程度:
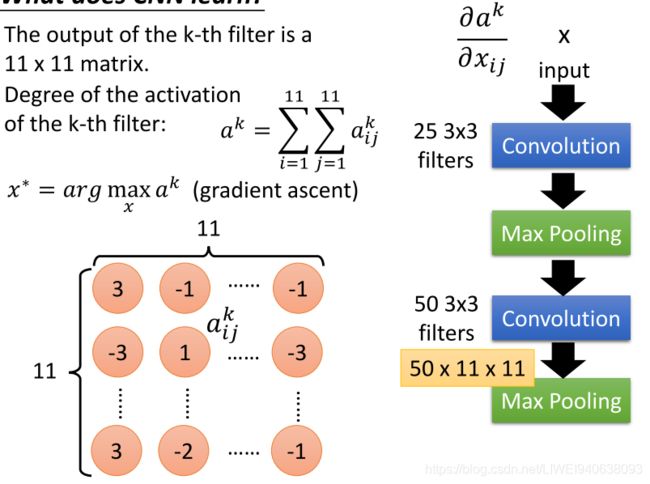
gradient ascent 梯度上升法
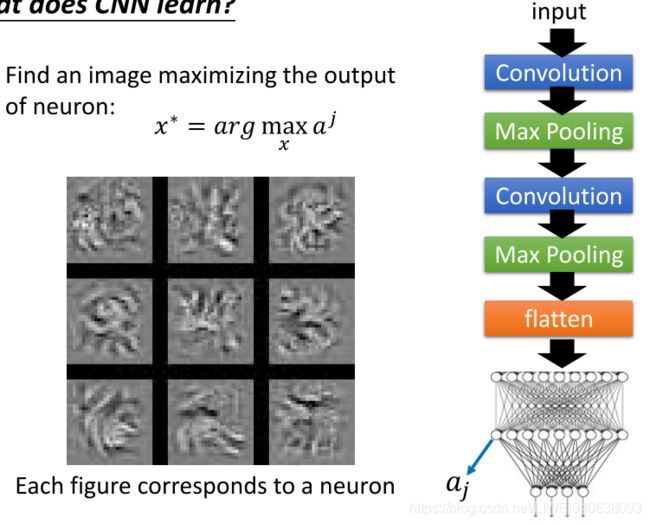
Find an image maximizing the output of neuron:找到一个最大化神经元输出的图像
Each figure corresponds to a neuron每个图形对应一个神经元
Deep Neural Networks are Easily Fooled 深层神经网络很容易被愚弄

Deep Dream
Given a photo, machine adds what it sees 给定一张照片,机器会添加它看到的东西


Deep Style
Given a photo, make its style like famous paintings给一张照片,让它的风格像名画一样


More Application:Playing Go
1919 matrix(image)——Network——Next move(1919 positions)
19*19 vector
Fully-connected feedforward network can be used可采用全连接前馈网络
But CNN performs much better但CNN的表现要好得多

Training:record of previous plays 训练:记录以前的行为

Why CNN for playing Go?
Some patterns are much smaller than the whole image。有些模式比整个图像小得多。
Alpha Go uses 5 x 5 for first layer 第一层使用5×5
The same patterns appear in different regions.相同的模式出现在不同的区域

Neural network architecture.The input to the policy network is a 191948 image stack consisting of 48 feature planes.The first hidden layer zero pads the input into a 2323 image,then convolves k filters of kernel size 55 with stride 1 with the input image and applies a rectifier nonlinearity.Each of the subsequent hidden layers 2 to 12 zero pads the respective previous hidden layer into a 2121 image,then convolves k filters of kernel size 33 with stride 1,again followed by a rectifier nonlinearity.The final layer convolves 1 filter of kernel size 11 with stride 1
神经网络结构.策略网络的输入是一个191948的图像堆叠层,由48个特征平面组成。第一个隐藏层0将输入垫入一个2323的图像,然后将核尺寸为55、移动步幅为1的k个滤波器与输入图像进行卷积,并且应用非线性整流器。每个后续的隐藏层(2到12个0)垫入各自的前一个隐藏层到一个2121的图像,然后用步幅1,卷积核为33的k个滤波器进行卷积,之后进行非线性整流。最后一层用步幅为1、kernel为11的filter进行卷积。

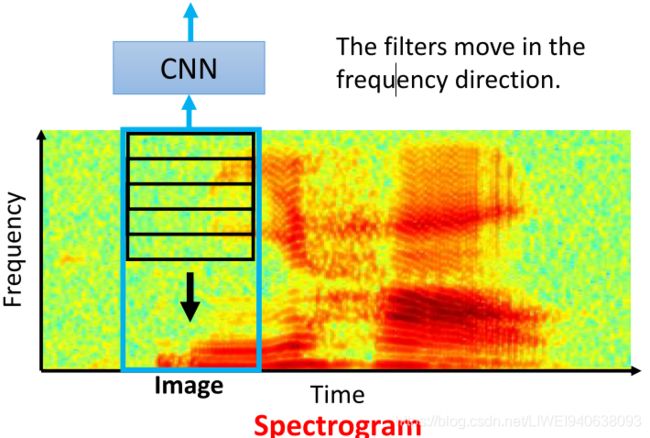
More Application: Speech
The filters move in the frequency direction.滤波器在频率方向上移动。
Spectrogram 频谱图(所有时间点的频率分布图)
More Application: Text