9.Paper小结——《VerifyNet: Secure and Verifiable Federated Learning》
题目:《VerifyNet: Secure and Verififiable Federated Learning》
——《安全的和可验证的联邦学习》
0.Abstract
联邦学习作为一种新兴的神经网络训练模型,由于其能够在不收集用户原始数据的情况下更新参数而受到了广泛的关注。然而,由于对手可以从共享的梯度中跟踪和获得参与者的隐私,联邦学习仍然暴露在各种安全和隐私威胁中。在本文中,我们考虑了深度神经网络(DNNs)训练过程中的两个主要问题:1)如何在训练过程中保护用户的隐私(即局部梯度),2)如何验证从服务器返回的聚合结果的完整性(或正确性)。为了解决上述问题,人们提出了几种关注安全或隐私保护联邦学习的方法,并应用于不同的场景。然而,这仍然是一个开放的问题,使客户端能够验证云服务器是否正确运行,同时保证用户在培训过程中的隐私。在本文中,我们提出了第一个保护隐私和可验证的VerifyNet的联邦学习框架。具体来说,我们首先提出了一种双掩蔽协议,以保证用户在联邦学习过程中的局部梯度的机密性。然后,需要云服务器需要向每个用户提供关于其聚合结果正确性的证明。我们声称,对手不可能通过伪造证据来欺骗用户,除非它能够解决我们的模型中采用的np硬问题。此外,VerifyNet还支持用户在训练过程中退出。在真实数据上进行的大量实验也证明了我们所提出的方案的实际性能。
1.Introduction
深度学习需要大量通常由用户收集的数据。但是,用户的数据可能在本质上很敏感,或包含一些私人信息。例如,在医疗保健系统中,患者可能不愿意与第三方服务提供商(如云服务器)[7]-[9]共享其医疗数据。近年来,联邦学习[10]、[11]能够在不收集用户原始数据的情况下进行训练网络,并逐渐引起学术界和工业界的关注,所有用户和云服务器只能通过共享本地梯度和全局参数来一起工作。
FL潜在的问题:
- 研究表明,攻击者仍然可以基于共享的梯度间接获取敏感信息,包括标签、成员资格等。
- 联邦学习中的数据完整性漏洞也经常在媒体[16],[17]中被报道。特别是,受某些非法利益的驱动,恶意的云提供商可能会向用户返回不正确的结果。例如,一个“懒惰的”云提供商可能会用一个更简单但更不准确的模型来压缩原始模型,以降低它自己的计算成本,或者更糟的是,恶意地伪造发送给用户的聚合结果。
因此,保护用户的隐私和数据完整性(特别是从服务器返回的结果的正确性)是联邦学习训练过程中的两个基本问题。因此,设计一个安全的联邦训练协议是非常迫切和有意义的,这种协议可以有效地验证从服务器返回的结果的正确性,同时保护用户的数据隐私。
为了解决上述问题,人们提出了一些注重隐私保护深度学习的工作。
- Shokri等人。[18]提出了一种通过选择性共享更新参数的隐私保护深度学习协议,可以实现实用性和安全性之间的平衡。
- Trieu Phong等人。[19]通过加法同态加密和梯度下降技术,提出了一种安全的深度学习系统。
- Bonawitz 等人. [11]通过利用秘密共享和密钥协议协议(key agreement protocol),提出了一种实用、安全的联邦学习架构,允许用户在执行过程中离线,同时仍然保证高精度。
但是,上述任何解决方案都不支持验证从服务器返回的结果的正确性。它与服务器返回结果的正确性与用户局部梯度的隐私密切相关。一旦对手能够操纵返回给用户的数据,用户隐私受到损害的风险往往会增加。例如,在众所周知的白盒攻击[14],[15]中,对手可以小心地将精心制作的结果返回给用户,以分析用户上传数据的统计特征,并诱导用户发布更多的敏感信息。
近年来,一些[16],[17]方案相继被提出来缓解训练有素的神经网络下的数据完整性问题。然而,这些方案要么支持少量的激活功能,要么需要额外的硬件帮助。据我们所知,目前在训练过程中还不支持神经网络的可验证性。与训练有素的神经网络相比,在训练过程中验证结果的正确性显然更加复杂,因为我们除了预测结果外,还必须更新整个网络的参数。此外,如何支持在工作流中退出的同时容忍用户退出(由于网络、设备不可靠、电池问题等)也是一个挑战。并确保所有用户(包括退出)局部梯度的一致性。
在本文中,我们提出了VerifyNet,第一个支持在训练神经网络过程中进行验证的隐私保护方法。我们首先设计了一种基于同态哈希函数和伪随机技术的可验证方法来支持每个用户的可验证性。然后,我们使用一种秘密共享技术和关键协议协议来保护用户局部梯度的隐私,并处理用户在培训过程中退出的问题。综上所述,我们的贡献可以总结如下:
- 我们利用与伪随机技术集成的同态散列函数作为VerifyNet的底层结构,它允许用户以可接受的开销验证从服务器返回的结果的正确性。
- 我们提出了一种双掩蔽协议,以保证用户在联邦学习过程中的局部梯度的机密性。在培训过程中,它可以因一定原因忍受一定数量的用户退出,这些退出用户的隐私仍然受到保护。
- 我们为我们的VerifyNet提供了一个全面的安全分析。我们声称,即使云服务器与多个用户合并,攻击者也不会获得任何关于用户本地梯度的有用信息。此外,对真实数据进行的大量实验也表明,我们的verifynet是实用的。
2.PROBLEM STATEMENT
在本节中,我们首先回顾联邦深度学习的主要概念。然后,我们描述了系统的体系结构、威胁模型和设计目标。
A. Federated Deep Learning
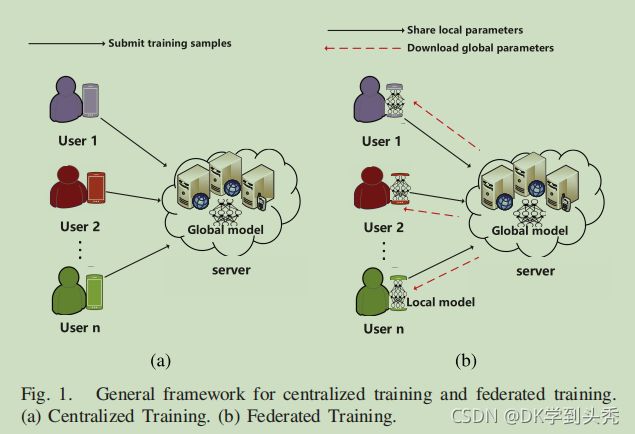
1)概述:根据训练风格,深度学习可分为以下两种类型。
- 集中式训练。如图所示。1(a),传统的集中式训练从服务器要求用户将他们的本地数据(即训练样本)上传到云中开始。然后,服务器初始化云上的深度神经网络,并通过训练样本进行训练,直到得到最优参数。最后,云服务器将发布预测服务接口或将最优参数返回给用户。
- 联邦学习。如前所述,用户直接将本地数据上传到服务器,并可能存在隐私泄露的威胁。因此,与集中训练不同,在联邦训练中(如图所示。1(b)),每个用户和服务器协作训练一个统一的神经网络模型。为了加快模型的收敛速度,每个用户与云服务器共享本地参数(即梯度),云服务器聚合所有梯度并将结果返回给每个用户。最终,服务器和每个用户都将得到最优的网络参数。与集中式训练相比,联邦训练降低了用户隐私被损害的风险。但研究表明,攻击者仍然可以基于共享的梯度间接获得敏感信息。此外,受某些非法利益的驱动,恶意的云提供商可能会向用户返回不正确的结果。因此,在本文中,我们的重点是保护用户的局部梯度的隐私,同时验证在联邦训练过程中从服务器返回的结果的正确性。
2)神经网络:神经网络作为深度学习的底层结构,可以与各种技术集成,实现分类、预测和回归。
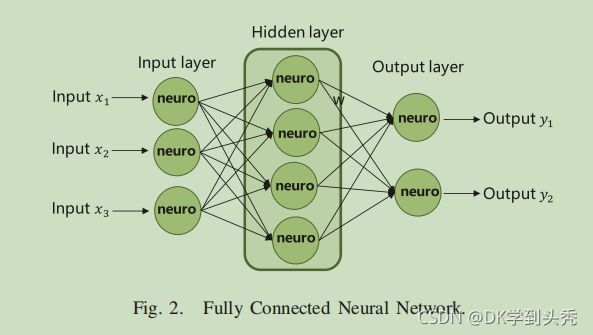
如图2所示。有一个完全连接的神经网络,有3个输入,一个隐藏层和2个输出。完全连接意味着相邻两层之间的所有神经元都通过变量(在本节中称为ω)相互连接。一般来说,一个神经网络可以表示为一个函数f(x,ω)=ˆy,其中x表示用户的输入,ˆy是通过参数ω的函数f对应的输出。
3)联邦学习更新:
在不失去一般性的情况下,假设每个数据记录都是一个观察对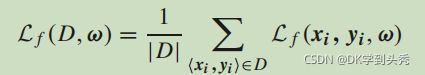 ,其中,针对特定损失函数l、Lf(x、y、ω)=l(y、f(x、ω))。在本文中,损失函数被设置为l(y,f(x,ω))=l(y,ˆy)=||y,ˆy||2,其中||·||2是一个向量的l2范数。
,其中,针对特定损失函数l、Lf(x、y、ω)=l(y、f(x、ω))。在本文中,损失函数被设置为l(y,f(x,ω))=l(y,ˆy)=||y,ˆy||2,其中||·||2是一个向量的l2范数。
训练神经网络的目的是找到最优参数ω,从而最小化损失函数。在我们的VerifyNet中,我们采用随机梯度下降[20],[21]来完成这个任务。具体来说,每个参数的迭代计算如下。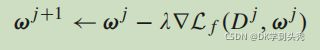
其中,ωj表示第j次迭代后的参数。Dj是D的一个随机子集,λ是学习速率的参数。在我们的联邦学习中,每个用户n∈N都拥有一个私有的本地数据集Dn,并预先与所有其他参与者同意的特定神经网络训练本地集,其中D=∑Dn。具体来说,服务器在第j次迭代中选择一个随机子集Nj⊆N,然后每个用户n∈Nj随机选择一个子集Djn⊆Dn来执行随机梯度下降。因此,参数更新可以重写如下。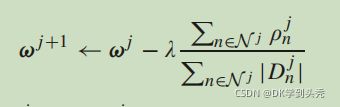 其中,ρjn=|Djn|∇Lf(Djn,ωj)由每个用户计算,并随后共享到云服务器。然后,云服务器向所有用户返回全局参数ωj+1。
其中,ρjn=|Djn|∇Lf(Djn,ωj)由每个用户计算,并随后共享到云服务器。然后,云服务器向所有用户返回全局参数ωj+1。

如图3所示。我们的系统模型由三个实体组成,可信权威(TA)、用户和云服务器。
- 可信权限(TA):TA的主要任务是初始化整个系统,生成公共参数,并为每个参与者分配公钥和私钥。之后,除非出现争议,否则它将会下线。
- 用户:在每个迭代期间,每个用户都需要将其加密的本地梯度发送到云服务器。此外,云服务器还将接收一些其他加密信息,以准备生成其计算结果的证明。
- 云服务器:云服务器聚合所有在线用户上传的梯度,并将结果与证明一起发送给每个用户,其中我们要求云服务器只对加密的梯度和最终结果一无所知。

B. Homomorphic Hash Functions

C. Pseudorandom Functions

4.TECHNICAL INTUITION
如上所述,在联邦学习中,每个用户需要向云提交其本地梯度,然后从服务器接收聚合的结果(所有本地梯度的和)。然而,有三个问题需要解决。首先,我们需要保护用户的局部梯度的隐私,因为对手可以通过这些梯度信息间接破坏用户的敏感信息。其次,为了防止服务器的恶意欺骗,每个用户都应该能够有效地验证服务器返回的结果的正确性。第三,在现实场景中,由于不可靠的网络或设备电池问题,用户通常无法按时将数据上传到服务器。因此,我们提出的协议应该在培训过程中由于某种原因对用户离线支持。在本节中,我们将给出一个技术直觉来解释我们如何解决这三个挑战。
5.PROPOSED SCHEME
在本节中,我们将介绍VerifyNet的技术细节。从高层来看,VerifyNet的目的是解决联邦培训过程中存在的三个问题。一是保护工作流中用户的本地梯度的隐私。第二,为了防止服务器的恶意欺骗,我们的VerifyNet支持每个用户有效地验证服务器返回的结果的正确性。第三,VerifyNet在训练过程中也支持离线用户。
图4显示了我们的VerifyNet的详细描述,它包括五轮任务来完成上述任务。具体来说,TA首先初始化整个系统,并生成VerifyNet中所需的所有公钥和私钥。然后,每个用户n加密其局部梯度xn,并提交给云服务器。在收到来自所有在线用户的足够消息后,云服务器将聚合所有在线用户的梯度,并将结果和Proof一起返回给每个用户。最后,每个用户决定通过验证证明来接受或拒绝计算结果,并返回到第0轮来开始一个新的迭代。




6.Conclusions
在本文中,我们提出了支持向每个用户验证服务器计算结果的VerifyNet。此外,VerifyNet还支持退出训练过程的用户。安全分析显示,我们的VerifyNet在诚实但好奇的安全设置下的高安全性。此外,在真实数据上进行的实验也证明了该方案的实际性能。作为未来研究工作的一部分,我们将专注于减少整个协议的通信开销。