分享本周所学——人工智能语音识别模型CTC、RNN-T、LAS详解
本人是一名人工智能初学者,最近一周学了一下AI语音识别的原理和三种比较早期的语音识别的人工智能模型,就想把自己学到的这些东西都分享给大家,一方面想用浅显易懂的语言让大家对这几个模型有所了解,另一方面也想让大家能够避免我所遇到的一些问题。然后因为我也只是一名小白,所以有错误的地方还希望大佬们多多指正。
目录
一、咋识别啊?
二、CTC是啥玩意啊?
1. 网络结构
2. CTC Loss
三、RNN-T又是个啥东西啊?
1. 网络结构
2. 坎坷的调试过程
三、LAS又是怎么回事
1. 网络结构
2. 没有那么坎坷的调试过程
一、咋识别啊?
在开始说模型之前,先聊一聊语音识别大概是个什么原理,如果已经有了解的话可以跳过这部分。
众所周知,音频的本质就是声波。声波是连续的,但计算机很难储存连续的信息,所以计算机描述声波的方式就是对声波进行采样,把连续的波转换成离散的数据,然后把采样到的内容储存在一个序列里面。如果在Python中用类似Librosa这样的库来读入音频文件的话,你会得到一个一维数组,表示对声音采样后得到的序列,还有一个表示采样率的数值。
>>> import librosa
>>> y, sr = librosa.load('a.wav')
>>> y
array([ 3.4340865e-05, 5.1643779e-05, 5.8888621e-05, ...,
-1.1601039e-03, -6.3401856e-04, 0.0000000e+00], dtype=float32)
>>> y.shape
(140018,)
>>> sr
22050
>>>显然啊,我们是不能直接识别这个玩意的。为什么不能呢?主要有两个原因。
第一个原因涉及到人的发声原理。众所周知啊,人是通过声带发出声音的,但是光有声带是没有用的,因为声带只能发出一些类似噪音的声音,如果想像我们平时说话那样说出有意义的内容,就需要喉咙、口腔、鼻腔等等一系列其他器官的配合,产生出我们想要说出来的话。这些器官会对声带发出的声音起到一个类似滤波的作用。大家可以试一试啊,控制自己的声带,一直保持用相同的力度和音高发声,然后说一句话,就会发现话还是可以说出来,只不过少了一点抑扬顿挫,有点像机器人。声带并不能决定我们说出来的是什么,只能决定音高和音量,而真正起决定性作用的是其他那些器官,但是音高和音量会对音频文件中的数据产生很大的影响,所以,我们需要弱化这部分影响,强化其他器官的滤波作用这部分信息。
第二个原因涉及到人的听觉。众所周知啊,人对于频率的感知能力并不是线性的,比如说人能够很明显地感觉出100Hz和200Hz的声音之间的区别,但是可能很难感觉出10100Hz和10200Hz的声音之间的区别。同样是100Hz的差异,在低频部分就显得很重要,但是在高频部分就显得没那么重要,所以我们要弱化高频部分中频率的差异,而强化低频部分的差异。
所以啊,我们得想个辙来解决这两个问题。一个不错的解决方案是对数梅尔频谱图。我这里随便用飞桨的音频处理库随便画了一个。(这里直接把窗长设成和音频长度相等了,要不然会有一大堆线,看起来会乱七八糟)
import paddle
import paddleaudio
import matplotlib.pyplot as plt
y, sr = paddleaudio.load('a.wav')
y = paddle.to_tensor(y)
extractor = paddleaudio.features.LogMelSpectrogram(sr=sr,
n_fft=len(y),
hop_length=len(y) + 1,
win_length=len(y))
img = extractor(y)
plt.plot(img)
plt.savefig('img.png')然后画出来长这样:

至于这个图到底是怎么得到的,我就简单说一下,大概是先把音频分段,大概几十毫秒一段,然后做短时傅里叶变换,然后再把频率转换成可以让人耳线性地感知到频率变化的梅尔频率,最后取对数。如果对这个图做一下包络,就可以轻松过滤掉声带所带来的杂讯。关于这个图具体是怎么回事,为什么有这样的功能,大家如果有想知道的可以去网上搜一搜关于梅尔频谱图的讲解啊,我这里就不细说了。
那现在我们有了这个十分好用的、包含了音频关键信息的图,我们接下来要做什么就很明显了:把这张图塞进一个模型里,让他输出一串向量,每个向量表示一个所有可能的输出结果的概率分布。举个例子,假设我们的模型要做中文的语音识别,那中文的常用字可能有5000个,我们就让模型输出一串5000维的向量,每个维度表示输出其中一个字的概率。我们最后的输出结果就是每一个向量中概率最大值对应的字拼起来。给大家画张图来看一下:

可以看到,这个输出结果由四个向量组成,每个向量有四个维度,那我们的输出就是每个向量里概率最大的数值对应的字,组合起来就是“炉石传说”。
那怎么样设计这样的一个AI,又怎么训练它呢?请大家往下看。
二、CTC是啥玩意啊?
CTC全名是Connectionist Temporal Classification。是时候让大家增加一点词汇量了。(图片来自百度翻译)



所以啊,CTC的中文名字显然就叫做连接机制世俗的分类。CTC本身没什么奇特的,但是它用的损失函数特别厉害,以至于这个损失函数就被命名为CTC Loss,并且在之后被广泛使用。在细说这个损失函数之前,我们还是先来看看它的网络结构。
1. 网络结构

这里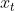 表示第
表示第 时刻的输入、
时刻的输入、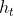 表示Encoder输出的隐状态、
表示Encoder输出的隐状态、![]() 表示最终的输出向量。这个网络应该说是不能再简单了。这里的Encoder基本上就是RNN、LSTM之类的基础结构,所以我们还是主要聊一聊它用的损失函数。
表示最终的输出向量。这个网络应该说是不能再简单了。这里的Encoder基本上就是RNN、LSTM之类的基础结构,所以我们还是主要聊一聊它用的损失函数。
2. CTC Loss
训练RNN时一个很大的难点在于很难把输出序列的长度与目标文本的长度匹配起来,解决这个问题可能还需要人工将输入的频谱图划分成几个片段,每个片段对应最终输出的一个字或者词。然而,如果使用CTC Loss,就完全不用担心这个问题。想要理解CTC Loss到底是怎么回事,我们就得先聊聊神经网络的输出是怎么对应到文本的。其实很简单啊,就是在一串连续的重复输出中只保留其中一个,也就是说,如果网络的输出是“炉炉炉炉石传传说说说说说”,那我们去掉重复的就会得到“炉石传说”。这时候有人就要问了,如果我们需要保留重复的内容怎么办呢?如果我们希望最终输出“炉石石传说”,这根本不可能办到啊。为了解决这个问题,我们需要引入一种新的输出——blank,也就是空位。我们允许网络在输出中包含blank,然后在完成去重之后再把所有的blank去掉。也就是说,如果网络的输出是“炉炉炉炉石石blank石传传说说说说说”,我们先去重,得到“炉石blank石传说”,然后再把blank去掉,就可以得到“炉石石传说”了。
这样一来,我们的目标从让网络输出与目标文本完全一致的一串文本,转变成了让它输出一长串由文本和blank组成的序列,并且使这个序列经过去重和去掉blank可以得到目标文本。这个序列的长度可以远大于目标文本的长度,因此我们就解决了输出序列长度与目标文本长度不匹配的问题。但是问题又来了,我们没办法给这种输出算loss啊,因为假设网络的输出长度是10,那“炉炉炉炉炉炉石传传说”、“炉石传传传传传传传说”和“炉炉blank石传传blank说blankblank”最终都可以得到“炉石传说”,也就是说有多种正确答案都可以对应到目标文本,我们也就没法对网络输出和目标输出之间算Cross Entropy Loss,因为我们没法确定要算网络的输出和哪个正确答案之间的交叉熵。
那我们不妨换一种思路——计算网络输出正确答案的概率。比如说“炉炉炉炉炉炉石传传说”是其中一个正确答案,那我们就去看网络输出的第一个字是“炉”的概率。因为网络的每一位输出都是一个代表概率的向量嘛,我们就把第一个向量中代表“炉”的那一维取出来就好了,然后再把第二个向量中代表“炉”那一维取出来,把两个概率相乘,就得到了前两位是“炉炉”的概率,以此类推。那下面这个图就代表了网络输出“炉炉炉炉炉炉石传传说”的概率是0.000326592。

当然,这只是其中一种正确答案的概率。最终输出“炉石传说”的概率应该是所有正确答案的概率之和。
但是问题又来了,能够输出“炉石传说”的答案数量实在是太多了,这还只是在文本长度只有四个字的情况下,如果目标文本有100个字,分别计算每一种正确答案的概率是一件几乎不可能完成的事情。那怎么才能更高效地统计所有的正确答案的概率之和呢?我们可以思考一下这些正确答案有什么共同点。显然啊,所有这些答案都会包含“炉”、“石”、“传”、“说”这四个字,并且是严格按照“炉”在最前面、“石”在第二位、“传”在第三位、“说”在最后的顺序,也就是说“炉”绝对不能出现在一个不是“炉”的字之后。另外,两个字之间可以穿插一些blank。那么我们可以利用这个是个人都能看出来的特性,来压缩计算正确率所需的时间复杂度。

我们可以用一个动态规划算法来解决这个问题。如上图所示,按照以下规则从t=1走到t=10:
- 必须从t=1时刻最上面的blank或者它下面的“炉”这两个位置出发;
- 每次只能往右一格、往右一格往下一格、或者往右一格往下两格;
- 如果当前位置对应的输出是blank,则不能往右一格往下两格,只能选择其他两种走法;
- 到达t=10时,最终位置必须在最下面的blank或者它上面的“说”这两个位置。
下图给出了一种可行的路径:(为了方便,我把所有blank都标上了序号)

不难发现,如果把路径上每一个位置对应的文字连起来,然后去重去blank,就一定能够得到正确的目标文本“炉石传说”。不信的朋友可以自己试试,按照上面的规则走,就一定能够得到一串能转换成“炉石传说”的文本。同时,所有正确的输出也一定可以对应到一条合法的路径。具体的证明我这里就不证了,感兴趣的朋友可以去网上查一查。
那这个概率也好算多了,我们只需要计算t=10时走到“说”和blank5这两个位置的概率之和就行了。不难发现啊,在第t时刻走到输出k的概率应该是上一时刻所有能走到输出k的格子的概率之和乘上第t时刻输出为k的概率。说的通俗一点的话,就比如我们想要计算t=10时“说”这个位置的概率,那它等于t=9这一时刻“传”的概率、blank4的概率和“说”的概率相加,再乘以t=10时刻网络输出的向量中“说”对应的维度的概率。说得再通俗一点就是:
![]()
这里![]() 表示第t时刻的输出。其实这就是这个动态规划的状态转移方程,而我们又能从第一时刻输出的向量得到t=1时k为blank1或“炉”的概率,因此我们就能轻松推出t=10时刻走到“说”和blank5这两个位置的概率,也就得到了最终输出正确文本的概率。
表示第t时刻的输出。其实这就是这个动态规划的状态转移方程,而我们又能从第一时刻输出的向量得到t=1时k为blank1或“炉”的概率,因此我们就能轻松推出t=10时刻走到“说”和blank5这两个位置的概率,也就得到了最终输出正确文本的概率。
那接下来要做什么就显而易见了。我们可以直接对这个概率做gradient ascent,也可以把这个概率取负对数然后做gradient descent。一般我们会选择后者。
CTC基本上就这么点东西。我没有自己试着写一个CTC,主要是因为它的网络结构被接下来要说到的这个RNN-T完爆了。
三、RNN-T又是个啥东西啊?
RNN-T的全名是Recurrent Neural Network Transducer。
1. 网络结构
说实话,RNN-T跟CTC区别真不大,就是网络结构稍微做的复杂了一点,大概长这样:

其实就是把前一时刻的输出当成网络的另外一个输入塞进来。这样的好处也显而易见,就是考虑了一下输出之间的关联性而已。那给大家看一下我拙劣的代码。我是用飞桨的人工智能库Paddlepaddle写的,主要是为了能在飞桨的平台上用他们的GPU在线运行,这样我自己的GPU就可以省下来打游戏啦!(命运2二象性地牢1=2)
class ConvBlock(nn.Layer):
def __init__(self, in_channels, out_channels, kernel_size, **kwargs):
super(ConvBlock, self).__init__()
self.conv1 = nn.Conv1D(in_channels, out_channels, kernel_size,
**kwargs)
self.relu1 = nn.ReLU()
self.bn1 = nn.BatchNorm1D(out_channels)
def forward(self, x):
x = self.conv1(x)
x = self.relu1(x)
x = self.bn1(x)
return x
class Model(nn.Layer):
def __init__(self):
super(Model, self).__init__()
self.encoder1 = nn.BiRNN(nn.LSTMCell(64, 128), nn.LSTMCell(64, 128))
self.conv1 = ConvBlock(256, 512, 3, stride=1, dilation=2, padding=2)
self.encoder2 = nn.BiRNN(nn.LSTMCell(512, 512), nn.LSTMCell(512, 512))
self.conv2 = ConvBlock(1024, 2048, 3, stride=1, dilation=2, padding=2)
self.pred1 = nn.LSTMCell(512, 1024)
self.pred2 = nn.LSTMCell(1024, 1024)
self.joint1 = nn.LSTMCell(3072, 4096)
self.joint2 = nn.LSTMCell(4096, 4096)
self.fc1 = nn.Linear(4096, 1024)
self.tanh1 = nn.Tanh()
self.fc2 = nn.Linear(1024, 512)
self.tanh2 = nn.Tanh()
self.fc3 = nn.Linear(512, 3)
def forward(self, x):
x1 = self.encoder1(x)[0]
x1 = paddle.transpose(x1, (0, 2, 1))
x1 = self.conv1(x1)
x1 = paddle.transpose(x1, (0, 2, 1))
x1 = self.encoder2(x1)[0]
x1 = paddle.transpose(x1, (0, 2, 1))
x1 = self.conv2(x1)
x1 = paddle.transpose(x1, (0, 2, 1))
x = paddle.randn((batch_size, 512))
states1 = None
states2 = None
states3 = None
states4 = None
output = paddle.zeros((batch_size, 0, 3))
for idx in range(len(x1[0])):
x, states1 = self.pred1(x, states1)
x, states2 = self.pred2(x, states2)
xt = paddle.index_select(x1, paddle.to_tensor(idx), axis=1)
x = paddle.concat((paddle.squeeze(xt, axis=1), x), axis=1)
x, states3 = self.joint1(x, states3)
x, states4 = self.joint2(x, states4)
x = self.fc1(x)
x = self.tanh1(x)
x = self.fc2(x)
x = self.tanh2(x)
xt = self.fc3(x)
output = paddle.concat((output, paddle.unsqueeze(xt, 1)), axis=1)
output = paddle.transpose(output, (1, 0, 2))
return output不过其实这个和PyTorch不能说是区别不大,只能说是一模一样。可能唯一的区别就在于这个BiRNN,它是一个双向RNN,参数是前向和后向两个RNN cell。PyTorch如果实现双向RNN要方便一点,直接在构造的时候加一个bidirectional的参数就行了。
这里我主要想说一下这两层CNN。用CNN主要是为了实现一个类似下采样的过程,这个步骤是非常关键的,这么说主要有两个原因:第一是输入序列里相邻的两个时刻的输入可能会非常相似,所以把相邻的几个输入变成一个能在不影响性能的情况下节省很多计算量;第二是过长的输入序列在经过RNN的时候很可能会发生梯度爆炸或者梯度消失的情况。所以,这两层CNN真的非常重要。另外我在CNN里加了空洞,主要也是为了避免相邻的输入太过相似。
2. 坎坷的调试过程
其实我在训练这个RNN-T的时候真的花了很长很长时间解决各种各样奇奇怪怪的问题。除了代码的bug和参数算错了之类的错误以外,有两个问题困扰了我很长时间才解决,所以就想给大家提个醒。第一是我在训练的过程中在调用CTC Loss的时候,老是提示我数据类型出错了,我也没有什么头绪,网上也找不到什么解决方法,最后大概在我第4遍读Paddlepaddle的官方文档的时候,我终于发现,他对输入数据的位数有一个非常邪门的规定:

然后我还特意去翻了一下PyTorch的文档,也是看了好几遍才发现他们在CTC Loss那一页的最下面有一个不起眼的note:

所以我就觉得如果同时在算CTC Loss的时候调用了CuDNN,那可能就会有这种比较邪门的位数要求,大家在用CTC Loss的时候一定要去多看几遍自己用的AI库的官方文档,然后检查一下自己的数据类型是不是合法。
然后另外一个问题就是我刚才提到的下采样,我一开始不知道要下采样的时候,网络一直训练不起来,经常出现很奇怪的现象,就是loss的确是噌噌往下降了,但是准确率就是死活上不去,而且是训练集上的准确率上不去,甚至有时候(不知道是不是因为梯度爆炸)loss居然给我算出来一个负数,当时直接给我气乐了。我还特意存了一下某一次训练的图:
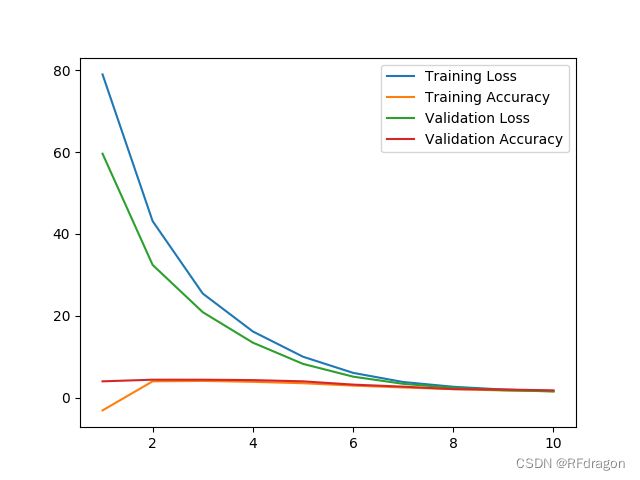
这里插一句啊,因为我是初学,不太敢用比较大的数据集,怕效果不好,就用的是PyTorch里面自带的一个叫yesno的数据集,里面是一个人用也不知道是哪种语言说话,每条音频总共有8个词,要么是yes要么是no,所以感觉是一个比较好识别而且适合我这种初学者的数据集。然后我这张图里的Accuracy可以明显看出来有的地方小于0,有的地方大于1,是因为我算Accuracy的方法是用目标文本长度减编辑距离,所以理想的Accuracy应该是8,然后因为编辑距离有时候会很大,所以会出现小于0。我这么做主要是因为Loss比较大,像这张图里就到了80,所以如果不把Accuracy放大一点的话,放在一张图里就看不清了。
总之我就一直不知道为什么训练不起来,然后就一通乱试,因为AI本身也比较玄学嘛,我就想着乱改一改这个网络结构是不是就好了?结果在我一同乱试了很长时间之后还真就好了。所以大家在做这种语音识别的时候一定不要忘了用下采样。这里放一张我上面的代码在同一个数据集上的训练效果:

虽然效果也不是特别好吧,但是起码是能训练出来一点东西了。
三、LAS又是怎么回事
LAS的全程是Listen, Attend and Spell。至于这个名字为什么这么奇怪,我在李宏毅老师的课那里了解到,是因为有一段时间论文的题目特别流行用三个动词作开头,然后写LAS的那篇论文的题目就叫Listen, Attend and Spell,所以这个网络也就用了那篇论文的题目当名字。但是现在好像很难看到三个动词作题目的论文,估计是因为过气了。然后又因为这三个词实在是太简单了,我就不去查翻译了。
1. 网络结构
LAS其实和前面两个也差不多,不过还是有一点本质性的变化的,因为它用到了Attention。

然后是我的代码:
class ConvBlock(nn.Layer):
def __init__(self, in_channels, out_channels, kernel_size, **kwargs):
super(ConvBlock, self).__init__()
self.conv1 = nn.Conv1D(in_channels, out_channels, kernel_size,
**kwargs)
self.relu1 = nn.ReLU()
self.bn1 = nn.BatchNorm1D(out_channels)
self.conv2 = nn.Conv1D(out_channels, out_channels, kernel_size)
self.relu2 = nn.ReLU()
self.bn2 = nn.BatchNorm1D(out_channels)
def forward(self, x):
x = self.conv1(x)
x = self.relu1(x)
x = self.bn1(x)
x = self.conv2(x)
x = self.relu2(x)
x = self.bn2(x)
return x
class Attention(nn.Layer):
def __init__(self, x_channels, y_channels, attention_size):
super(Attention, self).__init__()
channels = max(x_channels, y_channels)
self.att_size = attention_size
self.fc1 = nn.Sequential(nn.Linear(x_channels, channels), nn.Tanh(),
nn.Linear(channels, channels))
self.fc2 = nn.Sequential(nn.Linear(y_channels, channels), nn.Tanh(),
nn.Linear(channels, channels))
self.fc = nn.Sequential(nn.Tanh(), nn.Linear(channels, channels // 4),
nn.Tanh(), nn.Linear(channels // 4, 1))
def forward(self, states, z, key):
att_dis = self.att_size // 2
z = paddle.expand(z, (batch_size, self.att_size, len(z[0])))
states = paddle.index_select(
states,
paddle.to_tensor(list(range(key - att_dis, key + att_dis + 1))),
axis=1)
states1 = self.fc1(states)
z = self.fc2(z)
x = z + states1
x = self.fc(x)
x = nn.functional.softmax(x, axis=1)
x *= states
x = paddle.sum(x, axis=1)
return x
class BiRNN(nn.Layer):
def __init__(self, in_channels, out_channels):
super(BiRNN, self).__init__()
channels = out_channels // 2
self.birnn1 = nn.BiRNN(nn.LSTMCell(in_channels, channels // 2),
nn.LSTMCell(in_channels, channels // 2))
self.birnn2 = nn.BiRNN(nn.LSTMCell(channels, channels), nn.LSTMCell(channels, channels))
self.conv = nn.Conv1D(channels * 2 + in_channels, out_channels, 1)
def forward(self, x):
x1, _ = self.birnn1(x)
x1, _ = self.birnn2(x1)
x = paddle.concat((x, x1), axis=2)
x = paddle.transpose(x, (0, 2, 1))
x = self.conv(x)
return x
class Model(nn.Layer):
def __init__(self):
super(Model, self).__init__()
self.encoder1 = BiRNN(64, 128)
self.conv1 = ConvBlock(128, 256, 3, stride=2, dilation=3, padding=2)
self.encoder2 = BiRNN(256, 512)
self.conv2 = ConvBlock(512, 1024, 3, stride=2, dilation=3, padding=2)
self.attention = Attention(1024, 1024, 3)
self.decoder1 = nn.LSTMCell(2048, 4096)
self.decoder2 = nn.LSTMCell(4096, 4096)
self.fc1 = nn.Sequential(nn.Linear(4096, 1024), nn.Tanh())
self.fc2 = nn.Sequential(nn.Linear(1024, 256), nn.Tanh(),
nn.Linear(256, 3))
def forward(self, x):
h = self.encoder1(x)
h = self.conv1(h)
h = paddle.transpose(h, (0, 2, 1))
h = self.encoder2(h)
h = self.conv2(h)
h = paddle.transpose(h, (0, 2, 1))
z = paddle.randn((batch_size, 1024))
output = paddle.zeros((batch_size, 0, 3))
states1 = None
states2 = None
for i in range(2, len(h[0]) - 2):
att = self.attention(h, z, i)
att = paddle.concat((att, z), axis=1)
z, states1 = self.decoder1(att, states1)
z, states2 = self.decoder2(z, states2)
z = self.fc1(z)
y = self.fc2(z)
output = paddle.concat((output, paddle.unsqueeze(y, 1)), axis=1)
output = paddle.transpose(output, (1, 0, 2))
return output2. 没有那么坎坷的调试过程
因为有之前RNN-T的教训,所以遇到的问题没有之前那么多,但是还是遇到了一点问题,然后这个问题也是看了李宏毅老师的课才解决的。
这个问题主要就是Attention机制似乎不太适合语音识别这个场景,因为语音识别并不像翻译那样有时候需要在翻译第一个词的时候关注最后一个词的意思,只需要关注正在识别的东西就行了。所以我就把global attention换成了local attention,问题就基本上解决了。
事实证明LAS效果还是要好一点。(但是至于为什么测试集上效果比训练集好我就不知道了,我也检查过,不是因为图例标反了)
