python爬虫之scrapy框架
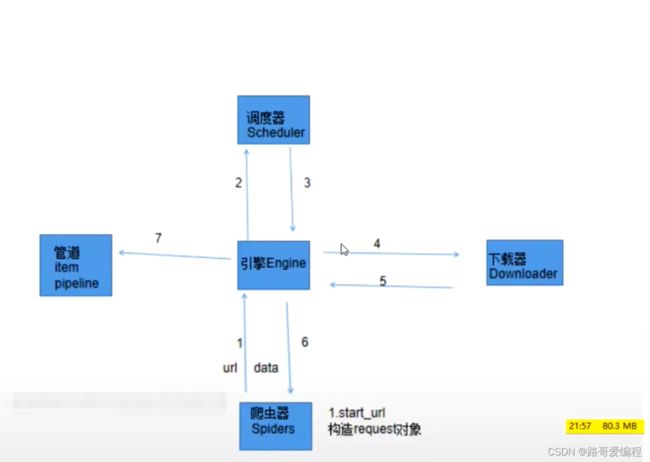
在能够使用基础代码实现爬虫效果的基础上。使用scrapy框架会大大的提高我们的效率。那么scrapy框架实现爬虫的流程是什么呢?如下图:

1、手动完成
--在爬虫器内定义起始url,构造一下request对象,由于是起始url,request请求对象的构成是自动的。然后把request请求对象交给了引擎。
2、自动完成
--引擎拿到request请求,交给调度器。
3、自动完成
--调度器将request请求入队列,出队列,然后交给引擎。
4、自动完成
--引擎吧request请求对象交给下载器。
5、自动完成
--下载器拿到request请求后发送网络请求,得到响应response后交给引擎。
6、手动完成
--引擎把响应response交给了爬虫器,根据需求进行解析(两种情况)
--(1)如果是需要的数据,那么就构建item对象交给引擎
--(2)如果是需要继续发送请求的url,手动构建request请求对象,交给引擎
7、手动完成
--引擎拿到了爬虫器yield过来的数据
--(1)如果是item对象,引擎就交给管道(pipeline)进行保存
--(2)如果是request请求对象,引擎会交给调度器在把流程重新走一遍
下面是一个简单的流程图