大前端 - nodejs 基础(核心模块、模块加载机制)
node基础
一 nodejs 核心模块、模块加载机制
- nodejs异步io和事件循环
- nodejs单线程
- nodejs实现api服务
- nodejs核心模块和api使用
- 提供应用程序可直接调用库,例如:fs,path,http等
- js语言无法直接操作底层硬件设置。
底层:
v8:1. 主要负责js代码的执行 2. 提供桥梁接口。
libuv:事件循环,事件队列,异步io
第三方功能模块:zlib,http,c-areas等。
nodejs核心组成
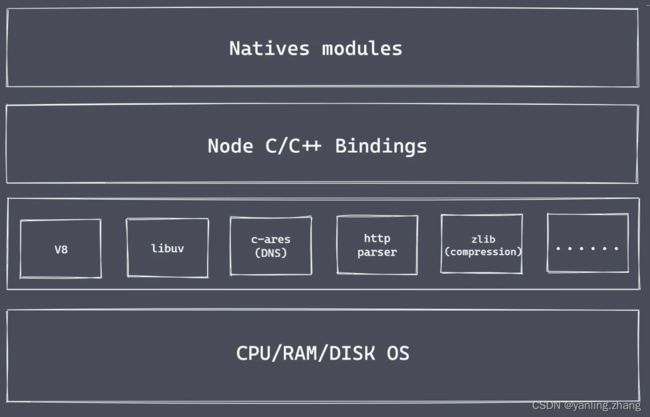

为什么是nodejs
nodejs是为了实现高性能的web服务器,后来经过长时间的发展nodejs就变成了一门服务端语言。这样就jsavascript在浏览器场景工作之外的场景。

数据的读写操作,总归是有消耗的。
并发服务端解决思路:1.多线程,2.多进程。
reactor模式:单线程完成多线程工作,并且是非阻塞。
多线程的消耗:1. 状态保存,2.时间消耗 3.状态锁
reactor模式下实现异步io,事件驱动。
nodejs更适用io密集型高并发请求。
nodejs三层架构:
- nodejs异步io:

轮询:重复调用io操作,判断io是否结束。
常见的轮询技术:read,select,poll,kqueue,event ports
期望实现的io技术:无需主动判断的非阻塞io。
linuv:是一个抽象封装层。
io操作属于系统级别,平台都有对用实现。nodejs单线程配合事件驱动架构及libuv实现了异步io。
nodejs事件驱动架构
发布者广播消息,其他的订阅者接收之前订阅的消息,之后在处理响应的处理。
const EvnentEmitter = require('events')
const myEvent = new EvnentEmitter()
myEvent.on('事件1', () => {
console.log('事件1执行了')
})
myEvent.emit('事件1')
node单线程
nodejs核心:1.异步io,2.事件循环,3.事件驱动
nodejs单线程如何实现高并发?
答:在nodejs的底层是:异步io + 事件循环 + 事件驱动的架构去通过回调通知的方式实现非阻塞的io调用和并发。具体的表现是在代码中出现多个请求的时候,是无需阻塞的。会由上到下的执行,等待libuv库完成工作之后,再按顺序通知响应的事件回调触发执行。这样的话,单线程就完成了多线程的工作。这里的单线程指的是:主线程是单线程,并不说nodejs只能是单线程。
nodejs中的代码都是由v8执行的。
const http = require('http')
const server = http.createServer((req, res) => {
// res.end:向客户端返回内容
res.end('server starting....')
})
// 模拟代码执行消耗的时间
function sleepTime(timer) {
const sleep= Date.now() + time * 1000
while(Date.now() < sleep) {}
return
}
// 开启本地服务。
server.linten(8080, () => {
console.log('服务启动了')
})
nodejs应用场景
需求:希望有一个服务,可以依据请求的接口内容返回相应的数据。
app.js
import express from 'express'
import list from './list.json'
const app = express()
app.get('/', (req, res) => {
res.json(list)
})
app.listener(8080, () => {
console.log('服务正常开启')
})
list.json
[
{
name: 'liz',
age: 1,
},
{
name: 'lizz',
age: 2,
}
]
nodejs全局对象
- 与浏览器平台的window不完全相同
- nodejs全局对象上挂载了许多属性
- 全局对象是javascript中的特殊对象,因为在js中任何地方都可以访问到的,也不需要重新定义,对于浏览器来说,全局对象就是window。通过window可以访问到很多属性和方法
- nodejs的全局对象是global。global的根据作用就是作为宿主。
- 全局对象可以看作是全局变量的宿主。
nodejs中常见的全局对象:
1.__filename:返回正在执行脚本文件的绝对路径
2.__dirname:返回正在执行脚本所在目录。(绝对目录)
3.timer类函数,执行顺序和事件循环间的关系(setTimeout,setInterval,setImmediate,nextTicl)
6. process:提供与当前进程互动的接口。(获取当前进程的数据)
7. require:实现模块的加载
8. module,exports:处理模块的导出。
9. 在nodejs中默认情况下this是空对象,和global并不是一样的。
console.log(global) // 看看都有啥
console.log(__filename, __dirname)
console.log(this==global) // false
全局变量 - process(进程)
资源:cpu,内存
const fs = require('fs')
console.log(processs.memoryUsage)
console.log(processs.cpuUsage)
// 运行环境:运行目录,node环境,cpu架构,开发环境状态,系统平台是max,linux,windows
console.log(process.cwd()) // 获取当前的运行目录
console.log(process.version) // node当前的版本
console.log(process.versions) // 得到更多的版本信息,
console.log(process.arch) // cpu架构 x64
console.log(process.env.NODE_ENV) // 开发/生产环境状态
console.log(process.env.PATH) // 当前本机配置的环境变量
console.log(process.env.USERPROFILE)
console.log(process.platform)
// 运行状态:启动参数,PID,运行时间
console.log(process.argv) // 启动参数 是一个数组:默认有2个值:1:nodejs启动程序目录 2:文件绝对路径 启动的参数默在数组的尾部
console.log(process.argv0) // 获取数组的第一个
console.log(process.execArgv)
console.log(process.pid) // ppid
console.log(process.uptime)
全局变量之 process
事件基本上都是基于:发布订阅模式。
// 事件
// 当前的脚本文件执行完成之后执行
process.on('exit', (code) => {
console.log('代码执行完了')
})
process.on('beforeExit', () => {
console.log('before exit' + code)
})
console.log('代码执行完了')
// 标准的输入,输出,错误
console.log = function(data) {
process.stdout.write('--' + data + '\n')
}
const fs = require('fs')
fs.createREadStream('test.txt')
.pip(process.stdout)
process.stdin.pipe(process.stdout)
process.stdin.setEncoding('utf-8')
process.stdon('readable', () => {
let chunk = process.stdin.read()
if(chunk !==null) {
process.stdout.write('data' + chunk)
}
})
node核心模块
1.内置模块 – path
用于处理文件/目录的路径
- basename():获取目录中基础名称
- dirname(): 获取路径中目录名称
- extname(): 获取路径中扩展名称
- isAbsolute():获取路径是否为绝对路径
- join():拼接多个路径片段
- resolve():返回绝对路径
- pasre():解析路径
- format():序列化路径
- normalize() : 规范化路径。
const path = require('path')
console.log(__filename) // D:\Desktop\Node 高级编程\code\06-path.js
// 1.获取路径中的基础名称
// 1. 返回的就是接收路径中的最后一部分 2.第二个参数表示扩展名,如果说没有设置则返回完整的文件名称带后缀。 3.第二个参数作为后缀,如果没有在当前路径中呗匹配到,那么就会忽略 4. 处理目录路径的时候,结尾处有路径分割符,则会被忽略掉。
console.log(path.basename(__filename)) // 06-path.js
console.log(path.basename(__filename, 'js')) // 06-path
console.log(path.basename(__filename, '.css')) // 06-path.js
console.log(path.basename('/a/b/c')) // c
console.log(path.basename('/a/b/c/')) // c
// 2.获取路径目录名(路径)
// 1.返回路径中最后一个部分的上一层目录所在路径。
console.log(path.dirname(__filename)) // D:\Desktop\Node 高级编程\code
console.log(path.dirname('/a/b/c')) // /a/b
console.log(path.dirname('/a/b/c/')) // /a/b
// 3.获取路径的扩展名
// 1.返回path路径中相应文件的后缀名 2.如果path路径当中存在多个点,匹配的是最后一个点到结尾的内容。
console.log(path.extname(__filename)) // .js
console.log(path.extname('/a/b')) // ''
console.log(path.extname('/a/b/index.html.js.css')) // .css
console.log(path.extname('/a/b/index.html.js.')) // .
// 4.解析路径
// 1.接收一个路径,返回一个对象,包含不懂的信息
// root,dir,base,ext,name
// 处理文件路径
const obj = path.parse('/a/b/c/index.html')
console.log(obj) // { root: '/' , dir: '/a/b/c', base: 'index.html', ext: '.html', name: 'index' }
// 处理目录
const obj = path.parse('/a/b/c') // { root: '/' , dir: '/a/b', base: 'c', ext: '', name: 'c' }
const obj = path.parse('/a/b/c/') // { root: '/' , dir: '/a/b', base: 'c', ext: '', name: 'c' }
const obj = path.parse('./a/b/c/') // { root: '' , dir: './a/b', base: 'c', ext: '', name: 'c' }
// 5. 序列化路径
const obj = path.parse('./a/b/c')
console.log(path.format(onj)) / ./a/b\c
// 6. 判断当前的路径是否为绝对路径
console.log(path.isAbsolute('foo')) // false
console.log(path.isAbsolute('/foo')) // true
console.log(path.isAbsolute('///foo')) // true
console.log(path.isAbsolute('')) // false
// 7.拼接路径
console.log(path.join('a/b', 'c', 'index.html')) // a\b\c\index.html
全局变量 - Buffer
- Buffer是什么?在哪?做什么?
- 二进制数据,流操作,Buffer
- Stream流操作并非nodejs独创。流操作配合管道实现数据分段传输。
- 数据的端到端的传输会产生生产者和消费者。
- nodejs中buffer是一片内存空间。
Buffer总结: - 无需require的一个全局变量
- 实现nodejs平台下的二进制数据操作
- 不占据v8堆内存大小的内存空间。
- 内存的使用由node来控制,由v8的GC回收。
- 一般配合stream流使用,充当数据缓冲区。

创建Buffer
Buffer是nodejs的内置类
- alloc:创建指定字节大小的buffer
- allocUnsafe:创建指定大小的buffer(不安全)
- from:接收数据,创建buffer
const b1 = Buffer.alloc(10)
const b2 = Buffer.allocUnsafe(10)
console.log(b1, b2)
// from
const b1 = Buffer.from('1', 'utf-8')
console.log(b1)
const b1 = Buffer.from([1,2,3, '中'], 'utf-8')
console.log(b1) // Buffer 实例方法
- fill:使用数据填充buffer
- write:向buffer中写入数据
- toString:从buffer中提取数据
- slice:截取buffer
- indexOf:在buffer中查找数据
- copy:拷贝buffer中的数据
// slice
buf = Buffer.from('拉钩教育')
let b1 = buf.slice(-3)
consooe.log(b1)
consooe.log(b1.toString())
// indexOf
buf = Buffer.from('liz爱前端,爱上拉钩教育,爱大家,我爱所有')
console.log(buf.indexOf('爱', 4)) // 15
Buffer静态方法
- concat:将多个buffer拼接成一个新的buffer
- isBuffer:判断当前数据是否为buffer
let b1 = Buffer.from('拉钩')
let b2 = Buffer.from('拉教育')
let b = Buffer.concat([b1, b2])
consoe.log(b) // Buffer-split 实现
ArrayBuffer.prototype.split = function (sep) {
let len = Buffer.from(sep).length
let ret = [] // 最终返回的结果
let offset = 0
let start = 0
while(offset = this.indexOf(sep, start)!==-1) {
ret.push(this.slice(start, offset))
start = offset + len
}
ret.push(this.slice(start))
return ret
}
let buf = 'zce吃馒头,吃面条,我吃所有的好吃的'
let bufArr = buf.split('吃')
console.log(bufArr) // []
FS模块
- 一个是缓冲区,一个是数据流?
- Buffer,Stream,与FS有什么关系?
FS是内置核心模块,提供文件系统操作的api
- FS模块结构 1. fs基本操作类 2.fs常用api
权限位,标识符,文件描述符


fs文件操作api - 文件读写与拷贝操作
readFile:从指定文件中读取数据
writeFile:向指定文件中写入数据
appendFile:追加的方式向指定文件中写入数据
copyFile: 将某个文件中的数据拷贝至另一个文件
watchFile: 对指定文件进行监控
const fs = require('fs')
const path = require('path')
// 读取文件中的数据
fs.readFile(path.resolve('data.txt'), 'utf-8', (err, data) => {
if (!err) {
console.log(data)
}
})
// 向文件中写入数据
// 设置权限:{ mode: '438', flag: 'r+' }
fs.writeFile('data.txt', 'hello node js', { mode: '438', flag: 'r+', encoding: 'utf-8' }, (err, data) => {
if(!err) {
fs.readFile('data.txt', 'utf-8', (err, data) => {
consoel.log(data)
})
}
})
appendFile
fs.appendFile('data.txt' , '拉钩教育', (err) => {
console.log('写入成功')
})
copyFile
fs.copyFile('data.txt', 'test.txt', () => {
console.log('拷贝成功')
})
watchFile
fs.watchFile('data.txt', { interval: 20 }, (curr, prev) => {
console.log(curr, prev)
if(curr.mtime !== prev.mtime) {
console.log('文件被修改了')
// 取消对文件的监控
fs.unwatchFile('data.txt')
}
})
md转html实现 - 文件操作实现md转html
const fs = require('fs')
const path = require('path')
const marked = require('marked')
const browserSync = require('browser-sync')
// 1.读取md和css内容。2.将上述读取出来的内容替换占位符,生成一个最终需要展示的html字符串。 3.将上述的html字符写入到指定的html文件中。 4.监听md文档内容的变化,然后更新html内容。 5.使用browser-sync来实时显示html内容
// 拿到md文件的路径
let mdPath = path.join(__dirname, process.argv[2])
let cssPath = path.resolve('gihub.css')
let htmlPath = mdPath.replace(path.extname(mdPath), '.html')
// 数据读取
fs.readFile(mdPath, 'utf-8', (err, data) => {
let htmlStr = marked(data)
fs.readFile(cssPath, 'utf-8', (err, data) => {
let retHtml = teml.replace('{{content}}', htmlStr).replace("{{style}}", data)
// 将上述的内容写到指定的html文件中,用于在浏览器里进行展示。
fs.writeFile(htmlPath, retHtml, (err) => {
console.log('html 生成成功了!')
})
})
})
browserSync.init({
browser: '',
server: __dirname,
watch: true,
index: path.basename(htmlPath)
})
const temp = ``
index.md
### 我是婊气
文件打开与关闭
const fs = require('fs')
const path = require('path')
// fd:文件操作符
// open:打开文件
fs.open(path.resolve('data.txt'), 'r', (err, fd) => {
console.log(fd)
})
close
fs.close('data.txt', 'r', (err, fd) => {
console.log(fd)
fs.close(fd, err=> {
consoel.log('关闭成功')
})
})
大文件读写
大文件读写操作,由于内存限制问题,不要直接使用fs.readFile 和 fs.writeFile。
必须使用fs.read 和 fs.write 来对文件进行读写操作。
const fs = require('fs')
// read:所谓的读操作就是将数据从磁盘文件中写入到buffer中。
let buf = Buffer.alloc(10)
fs.open('data.txt', 'r', (err, rfd) => {
console.log(rfd)
fs.read(rfd, buf, 0, 3, 0, (err, readBytes, data) => {
console.log(readBytes, data, data.toString())
})
})
// write将缓冲区里的内容写到磁盘文件中。
buf = Buffer.from('1234567890')
fs.open('b.txt', 'w', (err, wfd) => {
fs.write(wfd, buf, 0, 3, 0, (err, written, buffer) => {
console.log(err, written, buffer.toString())
})
})
文件拷贝自定义实现
- 打开a文件,利用read api将数据保存到buffer中暂存起来。
- 打开b文件,利用 write 将 buffer 中数据写入到 b 文件中。
let buf = Buffer.alloc(10)
// 1.打开指定的文件
fs.open('a.txt', 'r', (err, rfd) => {
// 3.打开b文件,用于执行数据写入操作
fs.open('b.txt', 'w', (err, wfd) => {
// 2.从打开的文件中读取数据
fs.read(rfd, buf, 0, 10, 0 , (err, readBytes, buffer) => {
// 4.将buffer中的数据写入到b.txt文件中
fs.write(wfd, buf, 0, 10, 0, (err, written) => {
console.log('写入成功')
})
})
})
const BUFFER_SIZE = buf.length
let readOffset = 0
fs.open('a.txt', 'r', (err, rfd) => {
fs.open('b.txt', 'w', (err, rfd) => {
function next() {
fs.read(rfd, buf, 0, BUFFER_SIZE, readOffset, (err, readBytes) => {
if (!readBytes){
// 如果条件成立,说明读写操作已经完成。
fs.close(rfd, () => {})
fs.close(wfd, () => {})
consoel.log('拷贝完成')
return
}
readOffset += readBytes
fs.write(wfd, buf, 0, 10, 0, (err, written) => {
next()
})
})
}
next()
})
})
FS之目录操作
- access: 判断文件或目录是否有操作权限
- stat:获取目录及文件信息
- mkdir:创建目录
- rmdir:删除目录
- readdir:读取目录中内容
- unlink:删除指定文件
const fs = require('fs')
// access
fs.access('a.txt', (err) => {
if (err) console.log(err)
console.log('有操作权限')
})
const fs = require('fs')
// stat
fs.stat('a.txt', (err, statObj) => {
console.log(statObj.size)
console.log(statObj.isFile())
console.log(statObj.isDirectory())
})
mkdir
fs.mkdir('a/b/c', { recursive: true } ,(err) => {
if(!err) console.log('创建成功')
console.log(err)
})
rmdir
fs.rmdir('a/b/c', { recursive: true } ,(err) => {
if(!err) console.log('删除成功')
console.log(err)
})
创建目录之同步实现
const fs = require('fs')
const path = require('path')
// 1.
模块化历程
前端开发为什么需要模块化?
- 项目难以维护不方便复用
模块:就是小而精且利于维护的代码片段。
利用:函数,对象,自执行函数实现分块
commonjs规范
commonjs是语言层面的规范:
-
commonjs规范:
1.模块引用:require
2.模块定义:exports导出
3.模块标识:模块ID,为了找到对应的模块, -
nodejs与commonjs:
任意一个文件就是一个模块,具有独立作用域。
使用require导入其他模块。
将模块ID传入实现目标某块定位。 -
module属性:
任意的js文件就是一个模块,可以直接使用module属性。
id:返回模块标识符,一般是一个绝对路径
fillename:返回文件模块的绝对路径。文件名称
loaded:布尔值,表示模块式否加载完成
parent:返回的是对象,存放调用当前模块的模块
children:数据,存放当前模块调用的其他模块。
exports:返回当前模块需要暴露的内容。
paths:数组,存放不同目录下的node_modules位置。 -
module.exports与exports有什么区别?
在规范中,只规定了module.exports执行数据的导出操作,单个exports实际上它是nodejs自己为了方便操作给每个模块都提供了一个变量,它只是指向了module.exports所对应的内存地址,因此我们可以直接通过exports导出相应的内容,但是不能直接给exports赋值,因为这样做等于切断了module.exports与exports之间的联系,这样exports就变成了局部的变量,无法向外部提供数据。 -
require:属性
基本功能就是读入并且执行一个模块文件。
resolve:返回模块文件绝对路径
extensions:依据不同后缀名执行解析操作
main:返回主模块对象,也就是入口文件。
1.commonjs起初只是为了弥补javascript语言模块化缺陷。想让js代码不仅运行在浏览器端。
2.commonjs是语言层面上的规范,当前主要用于nodejs。
3.commonjs规定模块化分为引入,定义,标识符三个部分
4.module在任意模块中可以直接使用包含模块信息
5.require接收标识符 ,加载目标模块
6.module.exports与exports都能导出模块数据
7.commonjs是同步加载数据
nodejs与commonjs
打印一下每个文件的导出是什么:
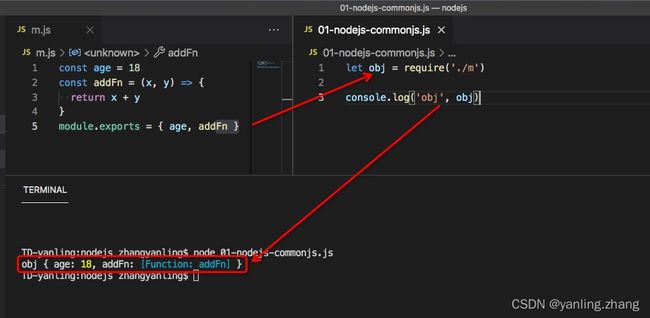
- 查看module里面有什么

exports导出使用:

exports错误用法,直接赋值:

同步加载:
模块分类以及加载流程
- 模块分类
1.内置模块(核心模块):node源码编译时就已经写入到二进制文件中。加载速度比较快一些。
2.文件模块(第三方模块,自定义模块):代码运行时,动态加载。
-node中模块 加载流程
分为三步
1:路径分析:依据标识符确定模块位置。
2.文件定位:确定目标模块中具体的文件及文件类型。
3.编译执行:采用对应的方式完成文件的编译执行。
路径分析:其实就是一句不同的格式就行路径的查找,标识符分为:路径和非路径标识符。
在查找模块的时候查找策略是什么?在当前模块中可以直接通过module.paths获取到路径数组,在这个数组中存放的就是在不同的路径下查找的目录,而这些路径刚好就是从当前文件的父级开始,知道当前项目所在的盘符根目录,在将来加载模块的时候会遍历所有的目录,如果没有找到目标文件,就抛出错误。
文件定位:在导入文件的时候,可能没有写扩展名,那么这个时候的查找规则就是先找.js文件,再找.json文件,最后找.node文件,如果都没找到那么node就认为当前拿到的是一个目录,会把这个目录当作一个包处理,而这个过程同样遵循js规范,首先会在当前文件查找package.json,使用json.parse解析文件,取出main属性值,如果main的值没有扩展名,则遵循.js,.json,.node的查找规则,如果还是没找到,或者是没有package.json文件,则默认找index文件,index.js,index.json,index.node,如果没找到,就抛出错误。
编译执行: 首先创建对象,然后按路径载入,完成编译执行。对.js和.json文件编译执行是不一样的。
对.json文件将读取到的内容通过json.parse解析。对.js文件,1.使用fs模块同步读取目标文件内容 2.对目标文件的内容进行语法报错,生成可执行的js函数。3. 调用函数时传入exports,module,require等属性值。
VM – 内置模块
VM:创建独立运行的沙箱环境。
模块加载模拟实现
// 模拟文件加载流程
/*
1.路径分析
2.缓存优化
3.文件定位
4.编译执行
*/
const fs = require('fs')
const path = require('path')
const vm = require('vm')
function Module(id) {
this.id = id
this.exports = {}
}
Module.__extensions = {
'.js'(module) {
// 读取
let content = fs.readFileSync(module.id, 'utf-8')
// 包装
content = Module.wrapper[0] + content + Module.wrapper[1]
// vm
let compileFn = vm.runInThisContext(content)
// 准备参数的值
let exports = module.exports
let dirname = path.__dirname(module.id)
let filename = module.id
compileFn.call(exports, exports, myRequire, module, filename, dirname)
},
'.json'(module) {
let content = JSON.parse(fs.readFileSync(module.id, 'utf-8'))
module.exports = content
},
}
Module.wrapper = [
'(function (exports, require, module, __filename, __dirname){',
'})'
]
Module._resolveFilename = function (filename) {
// 利用path将filename转为绝对路径
let absPath = path.resolve(__dirname, filename)
// console.log('absPath', absPath)
// 判断当前路径对应的内容是否存在
if(fs.existsSync(absPath)) {
// 如果条件成立,则说明absPath对应的内容是存在的。
return absPath
} else {
// 文件定位
let suffix = Object.keys(Module.__extensions)
console.log(suffix)
for(let i = 0; i < suffix.length; i++) {
let newPath = absPath + suffix[i]
if (fs.existsSync(newPath)) {
return newPath
}
}
}
throw new Error(`${filename} is not exists`)
}
Module._cache = {}
Module.prototype.load = function () {
let extname = path.extname(this.id)
console.log(extname)
Module.__extensions[extname](this)
}
function myRequire(filename) {
// 1 绝对路径
let mPath = Module._resolveFilename(filename)
// 2 缓存优先
let catchModule = Module._cache[mPath]
if (catchModule) return catchModule.exports
// 3 创建空对象加载目标模块
let module = new Module(mPath)
// 4 缓存已加载过的模块
Module._cache[mPath] = module
// 5 执行编译(编译执行)
module.load()
// 6 返回数据
return module.exports
}
// 测试数据
let obj = myRequire('./v')
console.log(obj)
事件模块
通过EventEmitter 类实现事件统一管理。
- nodejs基于事件驱动的异步操作架构,内置events模块。
- events模块提供了EventEmitter类
- nodejs中很多内置核心模块继承EventEmitter。
- EventEmitter常见的api操作:
1.on:添加,当事件被触发时调用的回调函数
2.emit:触发事件,
3.once:添加,但是事件只被执行一次。
4.off:移除事件监听器
on
const EventEmitter = require('events')
const ev = new EventEmitter()
// on:注册时间
ev.on('自定义事件名称', () => {
console.log('事件1执行了')
})
ev.on('自定义事件名称', () => {
console.log('事件1执行了----2')
})
// emit:触发事件
ev.emit('自定义事件名称') // 事件1执行了 事件1执行了----2
ev.emit('自定义事件名称') // 事件1执行了 事件1执行了----2
once:事件只只执行一次,执行完成之后删除,以后仔调用就不执行了。
ev.once('自定义事件1', () => {
console.log('事件1执行了')
})
ev.once('自定义事件1', () => {
console.log('事件1执行了-----2')
})
ev.emit('自定义事件名称') // 事件1执行了 事件1执行了----2
ev.emit('自定义事件名称') // 不执行
off:删除事件监听
let cnFn = (...args) => {
console.log('事件1执行了', args) // [1,2,3]
}
ev.on('自定义事件名称', cnFn)
ev.emit('自定义事件名称') // 事件1执行了
ev.off('自定义事件名称')
ev.emit('自定义事件名称', 1, 2, 3) // 事件没执行
发布订阅
订阅者先订阅
然后才是发布者发布

1.缓存对垒,存放订阅者信息
2.具有增加,删除订阅的能力
3.状态改变时通知所有订阅者执行监听
1.发布订阅者存在一个调度中心
2.状态发生改变时,发布订阅无需主动通知,由调度中心通知之前的订阅信息
模拟发布订阅的实现
class PubSub{
constructor(){
this._events = {}
}
// 注册事件
// event:事件类型,
// 事件类型对应的回调函数
sub(event, callback) {
// 之前订阅过相同类型的事件
if (this._events[event]) {
this._events[event].push(callback)
} else {
// 之前没有订阅过这个类型的事件
this._events[event] = [callback]
}
}
// 发布
pub(event, ...args) {
const items = this._events[event]
if (items.length) {
items.forEach((fn) => {
fn(...args)
})
}
}
}
// 测试
let ps = new PubSub()
ps.sub('事件1', () => {console.log('事件1执行le')})
ps.pub('事件1')
nodejs事件循环

setTimeout(() => {
console.log('s1')
})
Promise.resolve().then(() => {
console.log('p1')
})
console.log('start')
process.nextTick(() => {
console.log('tick')
})
setImmediate(() => {
console.log('setImmediate')
})
console.log('end')
//
start
end
tick
p1
s1
setImmediate
nextTick的优先级高于promise,没有为什么,就是这样定义的。

复杂:
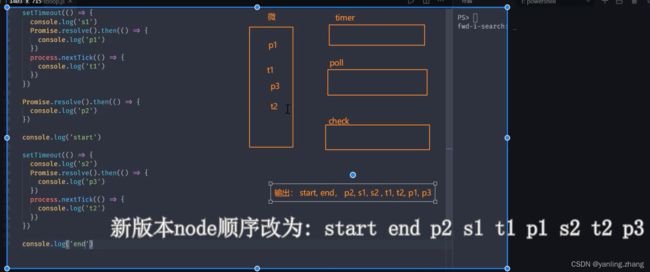
如果有2个setTimeout任务,则先执行第一个,第一个也是按照:同步任务,微任务的顺序,微任务放到微任务队列,先不执行,然后执行执行第2个setTimeout,同理,执行完同步任务,执行微任务,微任务放到微任务队列,先不执行。 2个setTimeout执行完成之后,去微任务队列去执行微任务。
如果是新版本的node,则是第一个setTimeout里面所有的代码执行完成之后,再执行第2个。
Nodejs与浏览器事件环区别
1.任务队列数不同。(浏览器只有2个任务队列,nodejs中有:微任务 + 6个事件队列)
2.nodejs微任务执行时机不同。(相同点:都是同步代码执行完成,执行微任务。不同点:浏览器平台下每当一个宏任务执行完毕后就清空微任务 3.nodejs平台在事件队列切换时会去清空微任务。)
3.微任务优先级不同。(1.浏览器事件中,微任务存放在事件队列,先进先出。2.nodejs中process.nextTick优先于process.nextTick)
Nodejs事件环常见问题
setTimeout(() => {
console.log('s1')
})
/*
setTimeout(() => {
console.log('s1')
}, 0)
*/
setImmediate(() => {
console.log('setImmediate')
})
存在的问题:有时s1先输出,有时setImmediate先输出。
为什么会产这种问题呢?最根本的setTimeout没有加时间。没有写,默认为0,这个0不管是在浏览器平台下还是node环境下都不稳定,因为有时会产生延迟。如果产生延迟则在代码中反而先执行的是setImmediate。如果没有产生延迟,则先执行setTimeout。
核心模块 - stream(流)
应用程序中为什么使用流来处理数据?
流处理数据的优势:
1.时间效率:流的分段处理可以同时操作多个数据chunk
2.空间效率:同一时间流无需占据大内存空间
3.使用方便:流配合管理,扩展程序变得简单。
nodejs中内置了stream,它实现了流操作对象。
nodejs中流的分类:
1.Reabable: 可读流
2.Writeable:可写流
3.Duplex:双工流,既可以读也可以写。
4.Tranform:转换流,可读可写,还能实现数据转换
const fs = require('fs')
// 创建一个可读流,生产数据
let rs = fs.createReadStream('1.txt')
// 修改字符编码,便于后续使用
rs.seEncoding('utf-8')
// 创建一个可写流,消费数据
let ws = fs.createWriteStream('1.txt')
// 监听事件调用方法完成具体消费
rs.on('data', (chunk) => {
// 执行数据写入
ws.write(chunk)
})
stream之双工流
双工流
let {Duplex} = require('stream')
class MyDuplex extends Duplex {
constructor(source) {
super()
this.source = source
}
_read() {
let data = this.source.shift() || null
this.push(data)
}
_write(chunk, en, nexr) {
process.stdout.write(chunk)
process.nextTick(next)
}
}
// 测试
let source = ['a', 'b', 'c']
let myDuplex = new MyDuplex(source)
myDuplex.on('data', (chunk) => {
console.log(chunk.toString())
})
转换流
let {Transform} = require('stream')
class MyTransform extends Transform {
constructor(){}
_transform(chunk, en, cb) {
this.push(chunk.toString().toUpperCase())
cb(null)
}
}
// 测试
let t = new MyTransform()
t.write('a')
t.on('data', (chunk) => {
console.log(chunk.toString())
})
文件可读流创建和消费
const fs = require('fs')
const rs = fs.createReadStream('test.txt',{
flags: 'r',
encoding: null.
fd: null,
mode: 438,
autoClose: true
start:0, // 开始读取位置
end: 3, // 结束位置
highWaterMark: 2,
})
rs.on('data', (chunk) => {
console.log(chunk.toString())
rs.pause() // 暂停读取
setTimeout(() => {
rs.resume() // 恢复读取
}, 1000)
})
rs.on('readable', () => {
// let data = rs.read()
// console.log(data)
let data = null
while((daat= rs.read)!==null) {
console.log(data.toString())
}
})
文件可读流事件与应用
const fs = require('fs')
const rs = fs.createReadStream('test.txt',{
flags: 'r',
encoding: null.
fd: null,
mode: 438,
autoClose: true
start:0, // 开始读取位置
end: 3, // 结束位置
highWaterMark: 2,
})
rs.on('open', () =>{
console.log('文件打开了')
})
rs.on('data', (chunk) =>{
console.log(chunk.toString())
})
// end执行之后,一般是:数据写入操作完成。
rs.on('end', (chunk) =>{
// 一般在end事件中。处理数据
console.log('当数据被清空之后执行')
})
rs.on('error', (err) =>{
console.log('错误了' + err)
})
rs.on('close', () =>{
console.log('文件关闭了')
})
执行时机:
open
data
end
close
如果报错:
err
文件可写流
write执行流程
const fs = require('fs')
let ws = fs.createWriteStream('test.txt', {
highWaterMark: 3
})
// 数据写入
ws.write('1')
const fs = require('fs')
let ws = fs.createWriteStream('test.txt', {
highWaterMark: 3
})
// 数据写入
let flag = ws.write('1')
console.log(flag) // true
flag = ws.write('2')
console.log(flag) // true
flag = ws.write('3')
console.log(flag) // false:如果flag为false,并不是说明当前数据不能执行写入。
- 第一次调用write方法时是将数据直接写入到文件中
- 第2次调用write方法时是将数据写入到缓存中
- 生产数据和消费速度是不一样的,一般情况下生产速度比消费速度快很多。
- 当flag为false之后,并不意味着当前次的数据不能写入了,但是我们应该告知数据的生产者,当前的消费速度已经跟不上生产者的数据了,所以这个时候,一般我们会将可读流的模块修改为暂停模式。
- 当数据生产者暂停之后,消费者会慢慢的消化它内部缓存中的数据,直到可以再次被执行写入操作。
- 当缓冲区可以继续写入数据时,如何让生产者知道?drain事件。
背压机制
数据读写存在的问题:内存溢出,gc频繁调用,其他进程变慢。
模拟文件可读流
const fs = require('fs')
const EventEmitter = require('events')
class MyFileReadStream extends EventEmitter{
constructor(path, options = {}) {
super()
this.path = path
this.flags = options.flags || 'r'
this.mode = options.mode || 438 // rw
this.autoClose = options.autoClose || true
this.start = options.start || 0
this.end = options.end
this.highWaterMark = options.highWaterMark || 64 * 1024
this.readOffset = 0
this.open()
this.on('newListener', (type) => {
if (type === 'data') {
this.read()
}
console.log(type)
})
}
// 打开文件
open() {
// 原声open方法打开指定位置的文件
fs.open(this.path, this.flags, this.mode, (err, fd) => {
if (err) {
this.emit('error', err)
}
this.fd = fd
this.emit('open', fd)
})
}
read() {
if (typeof this.fd !== 'number') {
return this.emit('open', this.read)
}
let buf = Buffer.alloc(this.highWaterMark)
let howMuchToRead
if (this.end) {
howMuchToRead = Math.min(this.end = this.readOffset, this.highWaterMark)
} else {
howMuchToRead = this.highWaterMark
}
fs.read(this.fd, buf, 0, howMuchToRead, this.readOffset, (err, readBytes) => {
if (readBytes) {
this.readOffset += this.readBytes
this.emit('data', buf.slice(0, readBytes))
this.read()
} else {
this.emit('end')
}
})
console.log(this.fd)
}
close() {
fs.close(this.fd, () => {
this.emit('close')
})
}
}
// 测试
let rs = new MyFileReadStream('test.txt', {
end: 7,
highWaterMark: 3,
})
rs.on('open', (fd) => {
console.log('open',fd)
})
rs.on('error', (err) => {
console.log('error', err)
})
rs.on('fn', () => {})
rs.on('end', () => {
console.log('end')
})
链表结构
为什么不采用数组存储数组?
数组的缺点:
1.数组存储数据的长度有上限
2.数据在增加,删除其他元素的时候,需要移动其他元素的位置
3.在js中数组被实现成了一个对象。在使用效率上比较低。
链表:是一系列节点的结合。
每个节点都具有指向下一个节点的属性。

单向链表
// size:维护当前节点的个数
链表的功能
1. 增加节点
2.删除节点
3.修改节点
4.查询
5.清空链表
class Node{
cunstructor(element, next) {
this.element = element
this.next = next
}
}
class LinkedList{
constructor(head, size) {
this.head = null
this.size = 0
}
// 根据index,获取当前节点node
_getNode(index) {
if(index < 0 || index > this.szie) {throw new Error('越界了')}
let currNode = this.head
for (let i = 0; i < index; i++) {
currNode = currNode.next
}
return currNode
},
add(index, element) {
if(arguments.length === 1) {
element = index
index = this.size
}
if(index < 0 || index > this.szie) {throw new Error('越界了')}
if(index ===0) {
this.head = this._getNode(index-1)
prevNode.next = new Node(element, prevNode.next)
}
this.size++
}
remove(index) {
if(index===0) {
let head = this.head
this.head = head.next
} else {
let prevNode = this._getNode(index-1)
prevNode.next = prevNode.next.next
}
this.size--
}
set(index, element) {
let node = this._getNode(index)
node.element = element
}
get(index) {
return this._getNode(index)
}
clear() {
this.head = null
this.size = 0
}
}
// 测试
const l1 = new LinkedList()
l1.add(index, 'node1')
l1.add(node1)
console.log(l1)
单向链表实现队列
class Queue{
consrructor() {
this.linkedList = new LinkedList()
}
enQueue(data) {
this.linkedList.add(data)
}
}
pipe方法使用
pipe最终实现的还是一个拷贝的操作
rs.pipe(ws):比以前的先读后写要方便。
const fs = require('fs')
const rs = fs.createReadStream('./9.txt'm {
highWaterMark :4
})
const fs = fs.createWriteStream('./9.txt'm {
highWaterMark: 1
})
rs.pipe(ws)
通信
网络通信基本原理
通信必要条件
- 主机需要有传输介质
- 主机上必须有网卡设备

网络通讯方式
1.交换机通讯
2.路由器通讯
如何建立多台主机互连?

通过Mac地址来唯一标识一台主机。
网络层次模型:
http:应用层协议,
tcp,udp:传输层协议
OSI 7层模型:
应用层:用户与网络的接口
表示层:数据加密,转换,压缩。
会话层:控制网络连接建立与终止
传输层:控制数据传输可靠性。
网络层:确定目标网络
数据链路层:确定目标主机。
物理层:各种物理设备标准。
数据从a到b,先封装再解封。
在两台主机通信之前,需要先握手,建立数据通信的通道。
通信事件:
listening事件:调用server.listen方法之后触发。
connection事件:新的连接建立时触发。
close事件:当server关闭时触发。
error事件:当错误出现时触发。
data事件:当接收到数据时触发该事件
write方法:在socket上发送数据,默认是utf8编码
end:结束可读端。
server.js
const net = require('net')
//创建服务端实例
const server = net.createServer()
const PORT = 1234
const HOST = 'locaLhost'
server.listen(PORT, HOST)
server.on('listening', () => {
console.log('服务端已经开启')
})
// 接收消息 回写消息
server.on('connection', (socket) => {
// 接收消息
socket.on('data', (chunk) => {
const msg = chunk.toString()
console.log(msg)
})
// 回写消息
socket.write(Buffer.from('您好' + msg))
})
server.on('close', () => {
console.log('服务端已经关闭')
})
server.on('error', (err) => {
if(err.code ==='EADDRINUSE') {
console.log('地址正在被使用')
}else {
console.log(err)
}
})
client.js
const net = require('net')
const client = net.createConnection({
port: 1234,
host: '127.0.0.1'
})
client.on('connect', () => {
console.log('拉钩教育')
})
client.on('data', (chunk) => {
console.log(chunk.toString())
})
client.on('error', (err) => {
console.log(err)
})
client.on('close', () => {
console.log('客户端断开连接')
})
TCP粘包及解决
- 发送端累计数据统一发送
- 接收端缓冲数据之后再消费
- tcp拥塞机制决定发送时机
获取 http 请求信息
req:前端的请求头信息req.headers
res:后端返回的结果
server.js
const http = require('http')
const url = require('url')
const server = http.createServer((req, res) => {
console.log("请求进来了")
// 请求路径额获取
let [pathname, query] = url.parse(req.url, true)
console.log(query)
// 请求方式
console.log(req.method)
// 版本号
console.log(req.httpVersion)
// 请求头
console.log(req.headers)
// 获取请求体中的数据
let arr = []
req.on('data', (data) => {
arr.push(data)
})
req.on('end', () => {
console.log(Buffer.concat(arr).toString())
})
})
server.listen(1234, () => {
console.log("server is start。。。")
})
设置 http 响应
const http = require('http')
const server = http.createServer((req, res) => {
console.log("请求进来了")
// res.write('ok')
// res.end()
// 设置头部信息
res.statusCode = 200
res.setHeader('content-type', 'text/html;chartset=utf-8')
res.end('ok')
})
server.listen(1234, () => {
console.log("server is start。。。")
})
代理客户端
主要解决跨域问题。
浏览器直接向自己创建的代理的客户端去发送请求,这里的代理客户端又充当着浏览器直接访问的服务端,服务端和服务端之间的通信是不存在跨域的。
server,js
const http = require('http')
const url = require('url')
const server = http.createServer((req, res) => {
console.log("请求进来了")
let {pathname, query} = url.parse(req.url)
// post
let arr = []
req.on('data', (data) => {
arr.push(data)
})
req.on('end', (data) => {
// console.log(req.headers['content-type'])
let obj = Buffer.concat(arr).toString()
if (req.headers['content-type'] === 'application/json') {
// console.log(req.headers.parsms)
let a = JSON.parse(obj)
res.end(JSON.stringify(a))
} else if (req.headers['content-type'] === 'application/x-www-form-urlencoded') {
let ret = querystring.parse(obj)
res.end(JSON.parse(ret))
}
console.log(Buffer.concat(arr).toString())
})
})
server.listen(1234, () => {
console.log("server is start。。。")
})
client.js
const http = require('http')
/*
http.get({
host: 'localhost',
port: '1234',
path: '/?a=1'
}, (res) => {
})
*/
// 配置信息
let options = {
host: 'localhost',
port: '1234',
path: '/?a=1',
method: 'post',
headers: { 'content-type': 'application/jsom' }
}
let req = http.request(options, (res) => {
})
req.end({name: 'liz'})
代理客户端解决跨域
解决跨域有很多种
Http 静态服务
const http = require('http')
const url = require('url')
const path = require('path')
const fs = require('fs')
const server = http.createServer((req, res) => {
let {pathname, query} = url.parse(req.url)
let absPath = path.join(__dirname, pathname)
// 目标资源的状态处理
fs.stat(absPath, (error, statObj) => {
if(err) {
res.statusCode = 404
res.end('not fount')
return
}
if (statObj.isFile()) {
fs.readFile(absPath, (err, data) => {
res.setHeaders('Content-type', 'tetx/html;chart=utf-8')
res.end(data)
})
} else {
fs.readFile(path.join(absPath, 'index.htnl'), (err,data) => {
res.setHeaders('Content-type', 'tetx/html;chart=utf-8')
res.end(data)
})
}
})
res.end('okok')
})
server.listen(1234, () => {
console.log('sererv is starting')
})
lgserve 命令行配置
静态服务工具
npm init -y生成package.json
npm install commander
npm install mine
package.json
"bin": {
"lgserver": "bin/www.js"
}
bin/www.js
#! /user/bin/env node
const {program} = require('commander')
console.log('开始执行了')
program.option('-p --port', 'set server port')
// 配置信息
let options = {
'-p --port ' : {
'description': 'init server port',
'example': 'lgserve -p 3306',
},
'-d --directory ' : {
'description': 'init server directory',
'example': 'lgserve -d c',
},
}
functio formatConfig(configs, cb) {
Object.entrise(configs).forEach(([key, val]) => {
cb(key, val)
})
}
formatConfig(options, (cmd, val) => {
program.option(cmd, val.description)
})
program.on('--help', () => {
formatConfig(options, (cmd, val) => {
program.option(val.example)
})
})
program.name('lgserver')
let version = require('../package.json').version
program.version = version
let cmdConfig = program.parse(process.argv)
console.log('cmdConfig', cmdConfig)
let Server = require('../main.js')
new Server(cmdConfig).start()
main.js
const http = require('http')
const url = require('url')
const path = require('path')
const mine = require('mine')
function mergeConfig(config) {
return {
port: 1234,
directory: process.cwd()
...config,
}
}
class Server{
constructor(config){
this.config =mergeConfig(config)
}
start() {
let server = http.createServer(this.serveHandle.bind(this))
server.listener(this.config.port, () => {
console.log('服务端已经运行了')
})
}
serveHandle(req, res) {
let {pathname} = url.parse(req.url)
pathname = decodeURIComponent(pathname)
let abspath = path.join(this.config.directory, pathname)
try{
let statObj = await fs.stat(abspath)
if (statObj.isFile()) {
this.FileHandle(req, res, abspath)
} else {
let dirs = await fs.readdir(abspath)
let renderFile = promisify(ejs.renderFile)
let ret = await renderFile(path.resolve(__dirname, 'template.html'), {arr: dirs})
res.end(ret)
}
}catch(err){
this.errorHandle(req, res, err)
}
console.log('有请求进来了')
}
errorHandle(req, res, abspath) {
res.statusCode = 404
res.setHaeder('Content-type', 'text/html;chart=utf-8')
res.end('not fond')
}
FileHandle(req, res, abspath) {
res.statusCode = 200
res.setHaeder('Content-type', mine.getType(abspath) + ';chart;utf-8')
createReadStream(abspath).pipe(res)
}
}
module.exports = Server
验证:lgServer -p 3307 -d: c
步骤3. npm link
步骤4. lgserve