Batch Normalization
首先推荐旷世的视频:https://www.bilibili.com/video/BV1DM4y1w7J4?p=1&share_medium=iphone&share_plat=ios&share_source=COPY&share_tag=s_i×tamp=1640004017&unique_k=Uzf93PU
【manim】5 分钟理解 BatchNorm
BN 添加位置
全连接层:添加在每一个全连接和激活函数之间;
卷积神经:卷积计算之后、激活函数之前;
计算公式
对于一个拥有 d d d维的输入 x x x,我们将对它的每一个维度进行标准化处理。
对于一个RGB图像,这里的 d d d指的是channels=3 x = ( x ( 1 ) , x ( 2 ) , x ( 3 ) ) x=(x^{(1)},x^{(2)},x^{(3)}) x=(x(1),x(2),x(3))
BN分别对每个channel进行Normalization。
下标1,2,3…,m表示样本维度,上标(1),(2)…,(c )表示channel 维度。
训练
Input:a mini-batch with m个样本: B = ( x 1 , . . . , x m ) ∈ R m × c × H × W B=(x_1,...,x_m)\in \R^{m×c×H×W} B=(x1,...,xm)∈Rm×c×H×W其中 x i = ( x i ( 1 ) , . . . , x i ( c ) ) x_i=(x_i^{(1)},...,x_i^{(c)}) xi=(xi(1),...,xi(c))
需要学习的量: γ \gamma γ——BN的weight 、 β \beta β——BN的bias
前向传播
input mean: 1 m ∑ i = 1 m x i → μ B = ( μ B ( 1 ) , . . . , μ B ( c ) ) ∈ R c × 1 \frac 1m\sum_{i=1}^mx_i\to\mu_B=(\mu_B^{(1)},...,\mu_B^{(c)})\in\R^{c×1} m1∑i=1mxi→μB=(μB(1),...,μB(c))∈Rc×1
例 μ B ( 1 ) = 1 m ∑ i = 1 m x i ( 1 ) = 1 m H W ∑ i = 1 m ∑ j = 1 H ∑ k = 1 W x i ( 1 ) ( j ) ( k ) \mu_B^{(1)}=\frac1m\sum_{i=1}^mx_i^{(1)}=\frac1{mHW}\sum_{i=1}^m\sum_{j=1}^H\sum_{k=1}^Wx_i^{(1)(j)(k)} μB(1)=m1∑i=1mxi(1)=mHW1∑i=1m∑j=1H∑k=1Wxi(1)(j)(k)
同理 input var: 1 m ∑ i = 1 m ( x i − μ B ) 2 → σ B 2 ∈ R c × 1 \frac 1m\sum_{i=1}^m(x_i-\mu_B)^2\to\sigma_B^2\in\R^{c×1} m1∑i=1m(xi−μB)2→σB2∈Rc×1
更新后的值: x ^ i = x i − μ B σ B + ϵ \hat x_i=\frac {x_i-\mu_B}{\sqrt{\sigma_B+\epsilon}} x^i=σB+ϵxi−μB
Output: y i = γ x ^ i + β y_i=\gamma\hat x_i+\beta yi=γx^i+β
可以看下面这个例子加深理解:
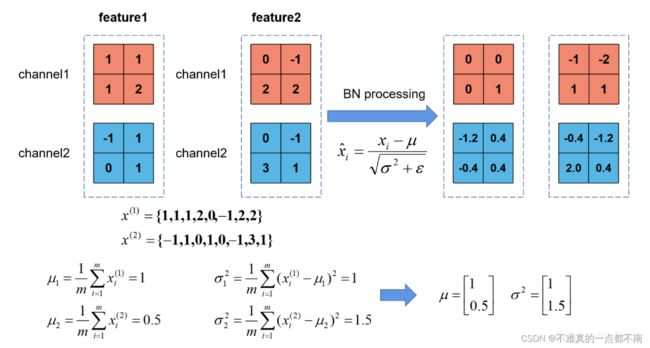
反向传播
根据最终的输出结果更新 γ 、 β \gamma、\beta γ、β

推理
训练与推理时BN中的均值、方差分别是什么?
训练时,均值、方差分别是该batch内数据相应维度的均值与方差;
推理时,均值、方差是基于所有batch的期望计算所得,公式如下:
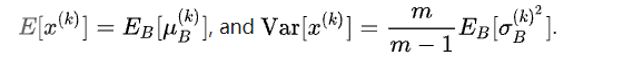
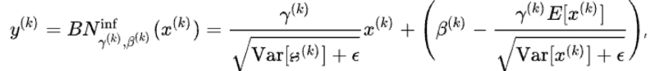
Pytorch中的Batch Norm
PyTorch 源码解读之 BN & SyncBhttps://zhuanlan.zhihu.com/p/337732517
详情可看上面,这里先不写了。
原论文中并没有running statistics 的概念。
Pytorch这里用到EMA update:
running statistics x ^ new = ( 1 − momentum ) × x ^ + momentum × x t \hat{x}_\text{new} = (1 - \text{momentum}) \times \hat{x} + \text{momentum} \times x_t x^new=(1−momentum)×x^+momentum×xt
x ^ \hat{x} x^ is the estimated statistic and x t x_t xtis the new observed value
x ^ \hat{x} x^: running _mean 、running_var
x t x_t xt: input_mean、input_var
训练完毕后保留 γ \gamma γ、 β \beta β、running _mean 、running_var。
验证时: y = γ r u n n i n g − v a r + ϵ x + ( β − γ r u n n i n g − v a r + ϵ r u n i n g − m e a n ) y=\frac {\gamma }{\sqrt{running-var}+\epsilon}x+(\beta-\frac {\gamma }{\sqrt{running-var}+\epsilon}runing-mean) y=running−var+ϵγx+(β−running−var+ϵγruning−mean)