Pandas中的join()合并数据方法
根据行索引合并数据
join方法能通过索引或指定列来连接DataFrame,语法格式如下:
join(other,on=None,how=“left”,lsuffix=" “,rsuffix=” ",sort=False)
上述方法参数表示的含义如下:
- on:用于连接名。 //如果两个表中行索引和列索引重叠,那么当使用join()方法进行合并时,使用参数on指定重叠的列名即可
- how:可以从{“left”,“right”," outer",“inner”} 中任选一个,默认使用left的方式。
- lsuffix:接收字符串,用于在左侧重叠的列名后添加后缀名。
- rsuffix:接收字符串,用于在右侧重叠的列名后添加后缀名。
- sort:接收布尔值,根据连接键对合并的数据进行排序,默认为False。
join()方法默认使用的左连接方式,即以左表为基准,join()方法进行合并后左表的数据会全部展示。
接下来通过代码演示:
例子1 join()使用默认连接方法和外连接方法:
![]()
import pandas as pd
left=pd.DataFrame({'A':['A0','A1'],'B':['B0','B1']},index=['a','b'])
right=pd.DataFrame({'C':['C0','C1'],'D':['D0','D1']},index=['c','d'])
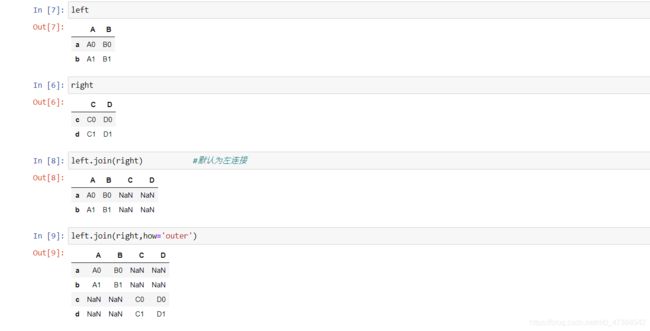
left
right
left.join(right) #默认为左连接
left.join(right,how='outer')
例子2 行索引和列索引重叠时on的方法:
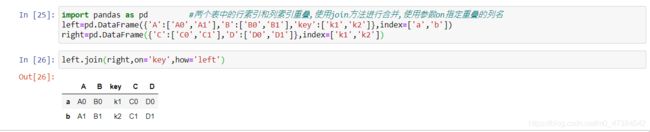
import pandas as pd #两个表中的行索引和列索引重叠,使用join方法进行合并,使用参数on指定重叠的列名
left=pd.DataFrame({'A':['A0','A1'],'B':['B0','B1'],'key':['k1','k2']},index=['a','b'])
right=pd.DataFrame({'C':['C0','C1'],'D':['D0','D1']},index=['k1','k2'])
left.join(right,on='key',how='left')
例子3 lsuffix参数的用法:
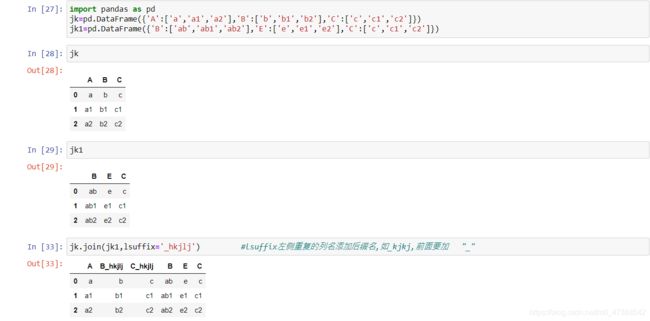
import pandas as pd
jk=pd.DataFrame({'A':['a','a1','a2'],'B':['b','b1','b2'],'C':['c','c1','c2']})
jk1=pd.DataFrame({'B':['ab','ab1','ab2'],'E':['e','e1','e2'],'C':['c','c1','c2']})
jk
jk1
jk.join(jk1,lsuffix='_hkjlj') #lsuffix左侧重复的列名添加后缀名,如_kjkj,前面要加 "_"
例子4 rsuffix参数的用法:
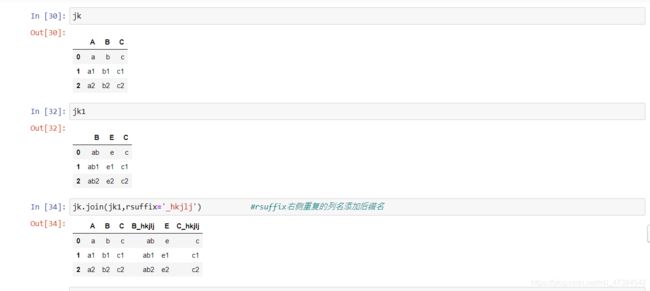
jk
jk1
jk.join(jk1,rsuffix='_hkjlj') #rsuffix右侧重复的列名添加后缀名
作者:KJ.JK
本文仅用于交流学习,未经作者允许,禁止转载,更勿做其他用途,违者必究。
文章对你有所帮助的话,欢迎给个赞或者 star 呀,你的支持是对作者最大的鼓励,不足之处可以在评论区多多指正,交流学习呀。