【深度学习】ICCV2021|性能优于何恺明团队MoCo v2,DetCo:为目标检测定制任务的对比学习...
作者丨小马
编辑丨极市平台
导读
作者专为目标检测任务“量身定制”了对比学习框架DetCo,在PASCAL VOC数据集上,DetCo在100个epoch时的性能就与MoCo V2 800个epoch的性能差不多,最终性能优于Mask RCNN-C4/FPN/RetinaNet等监督学习的方法。
【写在前面】
深度学习两巨头 Bengio 和 LeCun 在 ICLR 2020 上点名 Self-Supervised Learning 是 AI 的未来。在Self-Supervised Learning的代表工作之一—— Contrastive Learning(对比学习)上,Hinton 和 Kaiming 两位大神在这个领域中提出了一系列代表工作MoCo、SimCLR、MoCo V2。而目前的对比学习工作大多是基于分类任务被提出,而由于分类任务和检测任务的不同,在分类任务上适用对比学习框架,不一定适用于目标检测。因此,作者专为目标检测任务“量身定制”了对比学习框架DetCo,在PASCAL VOC数据集上,DetCo在100个epoch时的性能就与MoCo V2 800个epoch的性能差不多,最终性能优于Mask RCNN-C4/FPN/RetinaNet等监督学习的方法。
1. 论文和代码地址

论文地址:https://arxiv.org/abs/2102.04803
代码地址:https://github.com/xieenze/DetCo
2. Motivation
视觉表示的自监督学习是计算机视觉中的一个重要问题,促进了许多下游任务。其中目前比较流行的方向之一是对比学习,它将一幅图像通过数据增强转换为多个视图,并最小化来自同一图像的视图之间的距离并最大化来自不同图像的视图之间的距离。
目前的对比学习方法大多旨在在分类任务上达到与监督学习类似的performance,但是由于分类任务和检测任务存在不同,而先前的方法又忽略了这种不同,所以将以前的对比学习方法用在检测任务上时,就会产生suboptimal的问题。比如:
第一,由于每张图片只属于一个类,图像分类通常是使用交叉熵等1-K形式的损失函数,这在目标检测中存在争议,因为一个图像通常有许多不同类别的对象。
第二,目标检测通常需要对局部图像区域进行对象分类和框回归,但图像分类只需要全局图像表示。
第三,最近先进的目标检测器通常在多层次特征上预测目标,而图像分类器通常学习高级判别特征(即最后面的特征)。
为了能够使得对比学习框架能够在detection、segmentation、pose estimation等下游任务上也能表现出非常好的性能。本文首先研究了最新的自监督方法存在的图像分类精度与目标检测精度之间的不一致性 。然后,作者提出了三种的practice ,以适应目标检测任务。最后,根据这些practice,作者设计了DetCo 。
本文的贡献点可以分为三个部分:
1)证明了当以前的自监督学习表示被转移到下游任务时,图像分类和目标检测之间准确性的不一致。
2)提出了一种新的检测友好自监督方法,DetCo,它能够结合多个全局和局部对比损失,以提高目标检测任务中对比学习的特征表示。
3)基于Palcal VOC、COCO和Cityscapes数据集,当转移到检测、分割、姿态估计等下游任务中时,DetCo优于以前的SOTA方法。
3. 方法
3.1. 分类和检测的不一致性
作者详细分析了最近的自监督学习方法的图像分类和目标检测方法的性能,发现分类任务的performance和检测任务基本不一致。作者对比了监督的ResNet50、Relative-Loc、MoCo v1、MoCo v2和SwAV。
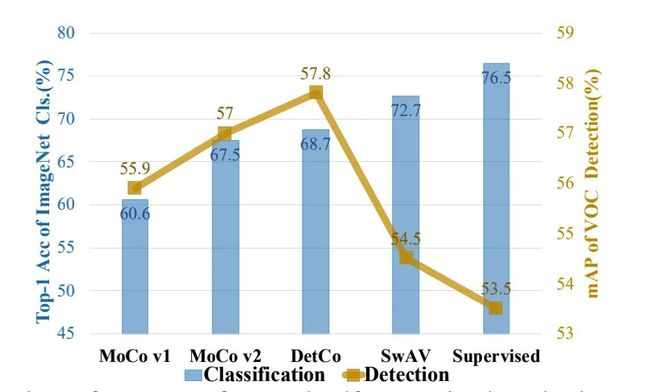
如上图所示,在分类任务上,SwAV达到最佳的Top-1准确率72.7%,但是在检测任务中,MoCov2达到57.0%的mAP,而SwAV仅只有54.5%。这表明,同一个网络结构的分类和检测的准确性不一致,相关性较低。
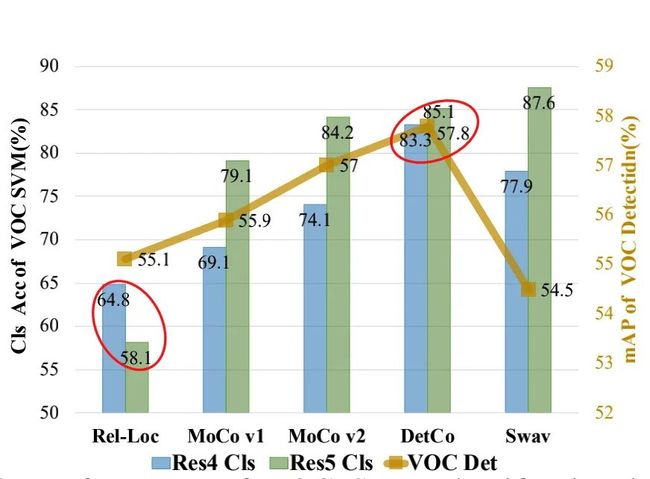
从上图可以看出,虽然Relative-Loc的VOC分类性能远低于其他方法,但检测性能具有竞争力。这表明,对于目前的自监督学习方法,图像分类的传输性能与目标检测的相关性较低。
为什么这些方法的检测性能如此不同?
MoCov1和v2是对比学习的方法,而SwAV是一种基于聚类的方法 。因此,SwAV的训练过程在一定程度上与监督分类方法相似 。因此,与对比学习方法相比,基于聚类的方法对图像分类任务更友好,这就是为什么SwAV与监督的ResNet在图像分类和目标检测任务上具有相似的性能 。
此外,作者认为对比学习方法比基于聚类/分类的目标检测方法更好,还有一个原因是,基于聚类的方法假设先验是一个给定的图像中只有一个对象 ,这与对象检测的目标不对应的。而对比性的学习方法并不需要这样的先验知识,它从整体的角度来区分图像。
为什么不是基于对比学习的Relative-Loc也能在检测任务上具有非常好的性能?
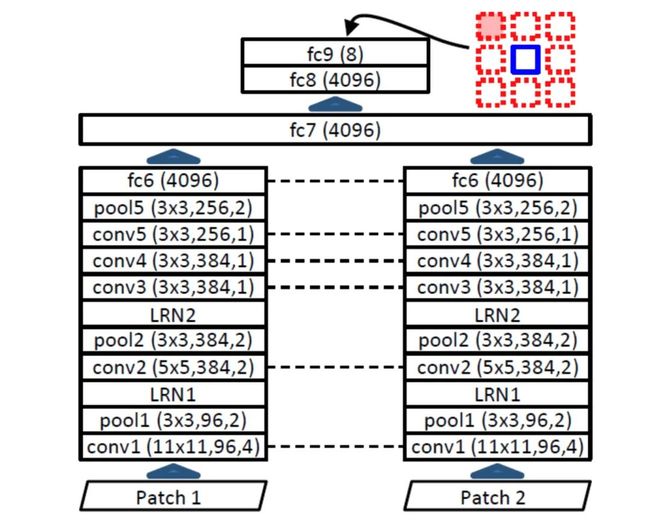
从上图可以看出,虽然Relative-Loc(结构如下图所示)在分类任务上表现一般,但是在检测任务上性能还是比较好的。作者考虑了两个原因:
1)Relative-Loc不仅使用了最后的特征,而且使用了浅阶段的特征,具有较强的识别能力。
2)Relative-Loc专注于预测局部patch之间的相对位置,这对检测任务有利。
设计针对目标检测任务的对比学习框架,指导原则是什么?
针对上面的分析,作者提出了三个原则:
1)基于对比学习的方法比分类或聚类好。
2)同时保持低级和高级特征来进行目标检测。
3)除了全局图像特征外,local patch特性对目标检测也至关重要。
3.2. DetCo
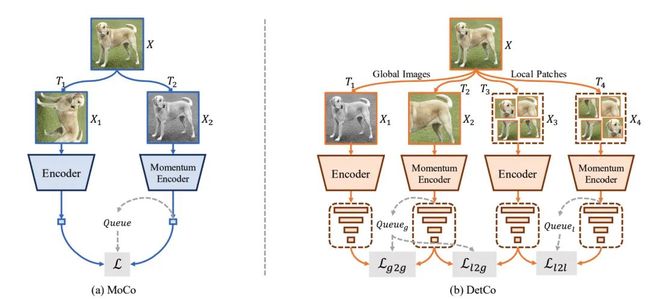
根据上面提出的guideline,作者基于MoCov2结构,加入了多阶段对比损失和跨局部和全局对比,提出了DetCo,如上图所示。DetCo的损失函数函数为多阶段,跨尺度的对比损失函数之和,具体表示如下:
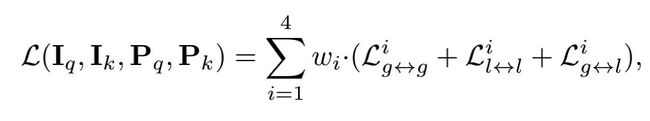
3.2.1. Intermediate Contrastive Loss
为了满足上面的guideline2,作者将一幅图像送到一个标准的主干ResNet-50,它输出来自不同阶段的特征,称为Res2、Res3、Res4、Res5。MoCo只使用Res5,但本文使用所有级别的特征来计算对比损失。输出的特征,作者分别送入到4个参数不共享的MLP中,得到4个q和4个k,对于每一层的特征,损失函数如下:
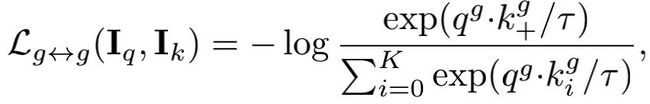
本文的损失函数为4层特征的损失函数之和:
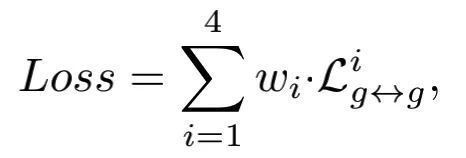
3.2.2. Cross Global and Local Contrast
为了满足上面的guideline3,作者增强了DetCo的Local Patch表示,使用jigsaw augmentation将输入图像转换为9个Local Patch。这样,就减少了全局图像的上下文信息。这些Patch通过编码器,就可以得到9个局部特征表示。之后,将这些特征组合为一个特征表示,并构建一个跨全局和局部对比损失。具体方式为将这9个特征concat之后,放入到另一个MLP中,得到特征表示。
因此就可以得到了Global - Local 和Local - Local的对比,损失函数如下:
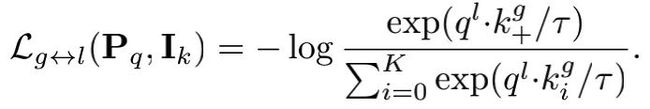
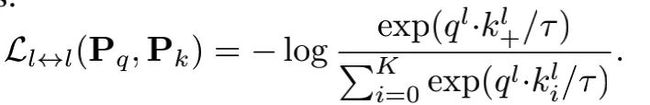
4.实验
4.1. 消融实验
4.1.1. 分层对比损失的有效性
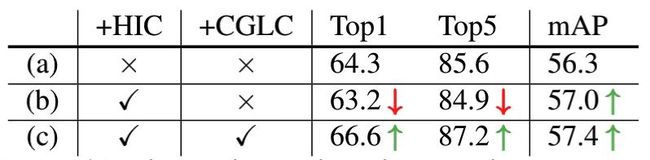
HIC为分层对比损失,从上表的(a)和(b)可以看出,加入多层特征之后,分类任务的准确率下降了,但是检测任务的准确率上升了。
4.1.2. 跨Local和Global对比的有效性
CGLC为跨Local和Global对比,从上表的(c)和(b)可以看出,加入跨Local和Global对比之后,分类和检测任务的性能都上升了。
4.2. Transfer Results on General Object Detection
4.2.1. PASCAL VOC
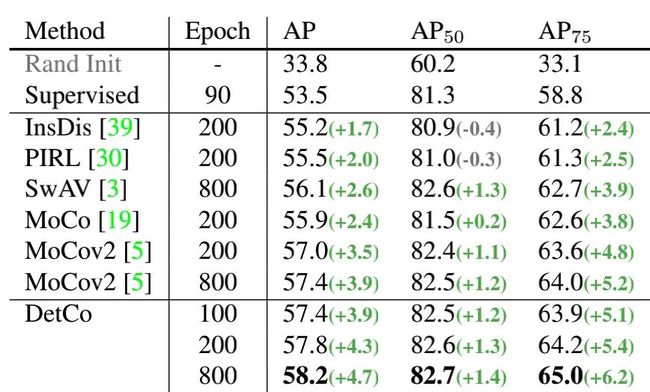
只用100个epoch的预训练,DetCo几乎达到了与MoCov2-800ep相同的性能。此外,DetCo-800ep达到了58.2mAP和65.0 AP75的SOTA性能。
4.2.2. COCO
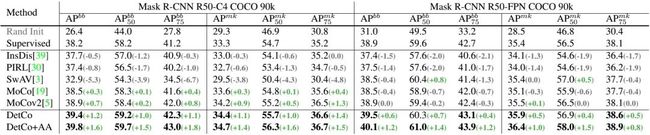
上表展示了standard 1× schedule上的Mask R-CNN结果,DetCo在所有指标中优于MoCov2和其他方法。

上表的2-3列展示了one-stage检测器RetinaNet的结果。DetCo预训练也优于ImageNet监督方法和MoCov2。
4.3. 其他下游任务
4.3.1.Multi-Person Pose Estimation.
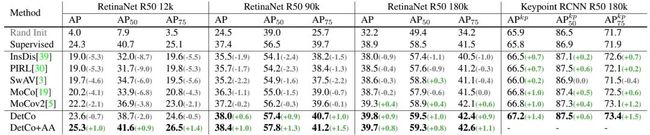
上表的最后一列展示了DetCo在人体关键点检测任务上也能达到比较好的性能。
4.3.2. Segmentation for Autonomous Driving
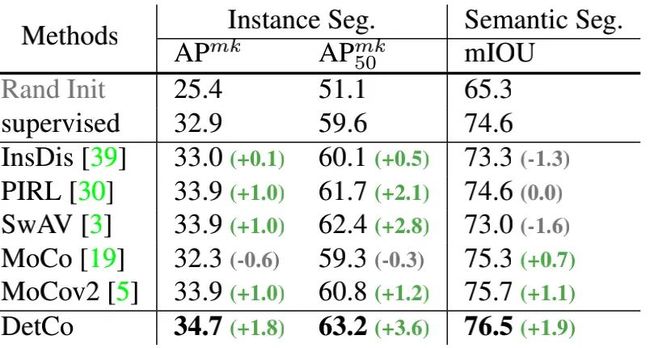
DetCo在实例分割和语义分割任务上也能达到比较好的性能。
4.3.3. 3D Human Shape Prediction
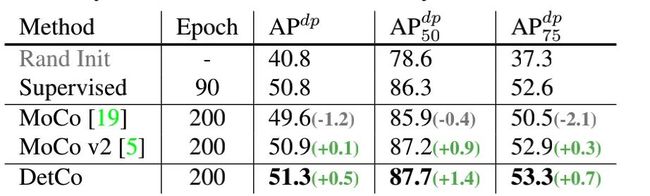
在3D Human Shape Prediction任务上,DetCo也达到了很好的性能。
4.3.4. 分类
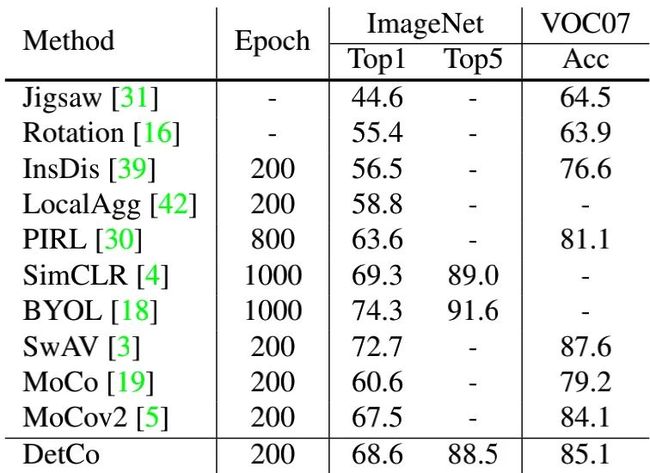
虽然本文的结构是为检测任务设计的,但是在分类任务上,本文的结构依旧能够达到比较好的性能。
4.4. 可视化

上图可视化了DetCo和MoCov2的attention map。可以看到,当图像中有多个对象时,DetCo成功地定位了所有对象,而MoCov2则无法激活某些对象。
5. 总结
首先,作者详细分析了一系列自监督方法,并得出了分类和检测任务性能不一致性的结论。其次,作者提出了三个practice来设计一个对于检测任务友好的自我监督学习框架。第三,按照practice的做法,作者提出加入具有分层中间对比损失和跨全局和局部对比。最终DetCo在一系列与检测相关的任务上取得了最先进的性能。
本文的Motivation是解决了以前对比学习框架专注于提升分类任务的性能,从而忽略其他任务性能的问题。而作者设计了一些非常有效的结构使得模型的泛化性提高,能够适应不同的任务。基于对比学习的预训练是为了得到一个非常general的特征,因此个人觉得,作者跳出了特定任务的性能提升,将格局放大,旨在提升更多任务的性能,使模型更具泛化性,是非常有意义的。
如果觉得有用,就请分享到朋友圈吧!
往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑温州大学《机器学习课程》视频
本站qq群851320808,加入微信群请扫码: