[论文笔记]S2P2 Self-Supervised Goal-Directed Path Planning Using RGB-D Data_2021ICRA
S2P2: Self-Supervised Goal-Directed Path Planning Using RGB-D Datafor Robotic Wheelchairs
视频链接
基于端到端模仿学习的路径规划的两个局限性:
· 需要大量的专家演示作为训练数据
· 现有的方法只能接收高级命令,如左转/右转。对于移动机器人(如机器人轮椅)来说,这些指令可能不够充分,因为它们通常需要精确的目标姿态,就比如向右转面对一个大空地 这个指令描述可能不够准确。
本文基于以上两点,提出S2P2 (Self-Supervised Path Planning),而这个网络和其他网络的区别就是,S2P2不需要专家手动数据,而且可以直接将目标姿态作为输入,而不是高级的命令。
![[论文笔记]S2P2 Self-Supervised Goal-Directed Path Planning Using RGB-D Data_2021ICRA_第1张图片](http://img.e-com-net.com/image/info8/f46d365ae1a74a01ae43ba4fd2c1c839.jpg)
作者首先开发了一个规划路径生成器 planned path generator (PPG) 输入为相机图像和目标姿态,输出为规划的路径标签。接着使用一个最佳拟合回归损失来训练这个基于生成标签的数据驱动路径规划模型。
路径规划
传统的路径规划
传统的路径规划算法一般可分为纯算法 Complete algorithms和基于采样的算法两大类。存算法,如A*和JPS,如果存在一个最优解,那么就可以找到,但它们的计算量往往很大。基于采样的算法,如PRM和RRT*,在规划路径的质量和效率之间进行权衡。由于感知模块的不确定性,这些算法的效果可能不稳定。
端到端路径规划
通过模仿学习输出未来多少帧的一个路径坐标,也有论文对比了各种网络结构如CNN和LSTM或者是CNN和LSTM的组合,CNN和LSTM组合的的模型规划的路径在很多情况下都会更加的平滑而且可行的。
端到端控制
利用图像或者是激光雷达输入直接输出控制命令。如ALVINN。
本文的方法
问题公式化
( . ) ω (.)^\omega (.)ω 为世界坐标系
( . ) b (.)^b (.)b 为机器坐标系
( . ) c (.)^c (.)c 为相机坐标系
( . ) p b (.)^{pb} (.)pb 为二维车身框架投影坐标系,也就是机器坐标系的x-y投影
R b ω , T b ω R^\omega_b , T_b^\omega Rbω,Tbω 分别为机器坐标到世界坐标的旋转和平移矩阵
输入前视图像 I R I_R IR和深度图像 I D I_D ID 即可构造出一个三维的点云空间。而作者认为Z轴对于机器轮椅的路径规划没有影响,所以考虑采用二位的投影面 。
给定一个目标姿态 p g p b p_g^{pb} pgpb,那么生成路径可表示为:
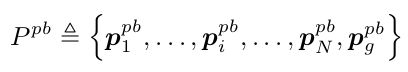
本文的N设置为24
目标姿态 p g p b p_g^{pb} pgpb,包括目标的位置坐标以及目标姿态方向。但是中间路径的 p i p b p_i^{pb} pipb并不包括方向信息,因为后续的控制模块只需要位置信息。
规划路径生成器
PPG设置为输入图像和目标姿态,前视图像和深度图像的后,根据 他们在2019年RAL的一篇文章的方法,生成相应的语义分割图像 I S I_S IS,该图像可以提供可行驶区域和障碍物的像素级预测,对于每个像素q ,根据深度图计算三维坐标。
接着构建一个栅格化的代价地图。初始化过程如下:
![[论文笔记]S2P2 Self-Supervised Goal-Directed Path Planning Using RGB-D Data_2021ICRA_第2张图片](http://img.e-com-net.com/image/info8/95fca7112f33491e8d17814418a4f45a.jpg)
q d p b , p o p b q_d^{pb},p_o^{pb} qdpb,popb 分别为可行驶区域和障碍物的点。
P C c PC^c PCc为相机图像, R c b , T c b R^b_c , T_c^b Rcb,Tcb 分别为相机坐标到机器坐标的旋转和平移矩阵
对于相机图像每个点计算它在机器坐标系中的坐标通过 R c b , T c b R^b_c , T_c^b Rcb,Tcb
机器轮椅的 大小为 1m * 0.5m
每个单元格的大小为0.1* 0.1
对于给定的 p g p b p_g^{pb} pgpb 可以先使用传统的路径规划算法来规划一个路径 P p b P^{pb} Ppb,
接着输入目标姿态以及规划路径投影在原始图像中,获得二进制路径标签 L P L_P LP和二进制目标标签 L G L_G LG ,通过大量的随机获取目标姿态,PPG可以生成大量的规划路径标签。
虽然PPG可以生成计划路径的坐标,但由于感知错误,生成的路径通常会出现弯路或不安全的路线。因此,本文提出了一个数据驱动的路径规划模型,以提供更好的规划路径。
![[论文笔记]S2P2 Self-Supervised Goal-Directed Path Planning Using RGB-D Data_2021ICRA_第3张图片](http://img.e-com-net.com/image/info8/aef5eac284cb4304aa0c3646d6589f99.jpg)
左边外部三维重建子模型 E3RS 将原始路径规划问题转化为语义分割问题。右边的三维重建子模型 I3RS 利用LSTM来模拟 路径的这种时序关系。
E3RS: 先获取LG,再使用语义分割网络RTFNet-50,输入LG和 RGB图像,输出即为二进制的路径标签 LP,再结合 深度图 I D I_D ID来计算生成路径。
I3RS: 来模拟规划路径的每个节点之间的顺序关系。首先使用RTFNet-50提取图像的视觉特征。
为了平衡坐标向量和视觉特征之间的维度差异,将输入坐标向量编码为具有更高维度的特征,然后将其与视觉特征连接并馈送到LSTM网络。每个LSTM 单元输出的特征即被解码为下一个预计位置。上一个LSTM单元的输出即为下一个LSTM单元的当前位置。而第一个LSTM单元使用(0,0)作为当前位置。一共由25个LSTM单元构成这样一个多对多模型。
网络的训练损失
E3RS

L E P L_{EP} LEP和 L E R L_{ER} LER分别表示PPG引导损失和最佳回归平面损失
L E P L_{EP} LEP为PPG生成的路径 L ^ P \hat{L}_P L^P和E3RS生成的 L P L_P LP的交叉熵
L E R L_{ER} LER用来惩罚 L P L_P LP中在像素平面外的点
![]()
其中
q = [ u , v ] T q=[u,v]^T q=[u,v]T描述像素的位置
ϕ \phi ϕ 为相机的翻滚角度
a = [ a 0 , a 1 ] T a = [a_0,a_1]^T a=[a0,a1]T

I3RS
![]()
L I P L_{IP} LIP和 L I R L_{IR} LIR分别表示PPG引导损失和最佳回归平面损失

L I P L_{IP} LIP为PPG生成的路径 p ^ i p b \hat{p}_i^{pb} p^ipb和I3RS生成的 P i p b P_i^{pb} Pipb的交叉熵
L I R L_{IR} LIR也是使用预测路径和深度图来计算的,用于惩罚在像素平面外的点
将S2P2集成到基于地图导航的框架中
对于很多远程自主导航任务,输入目标通常在前视摄像头视野之外,所以本文将S2P2集成到现有的基于地图的导航系统中。
给的一个目标姿态,首先可以使用全局路径规划器在世界坐标系中规划一条无碰撞路径

接着使用以下算法生成中间过程的目标姿态
![[论文笔记]S2P2 Self-Supervised Goal-Directed Path Planning Using RGB-D Data_2021ICRA_第4张图片](http://img.e-com-net.com/image/info8/5f6ce76461704b9ebfcf540a19aca1f9.jpg)
其中 r r r为相机的距离范围,在本文设定为10m。
Visible(m,n)表示当机器位于n 时,m这个姿态是否在摄像机的FOV内
Dist(m,n)表示m到n的欧式距离
通过将 G w G^w Gw从世界坐标系转化到机器坐标系,S2P2可以用作局部路径规划器,作为输入RGB-D图像,中间目标姿态以Gpb 递增,直到机器人达到输入目标。
![[论文笔记]S2P2 Self-Supervised Goal-Directed Path Planning Using RGB-D Data_2021ICRA_第5张图片](http://img.e-com-net.com/image/info8/a2fa9c7a5eb248ec81e5663902a811e3.jpg)
实验
使用一个和之前论文一样的数据集,它涵盖了机器人轮椅通常工作的30个常见场景,为了提高效率,所有图片下采样到224*320。
对于PPG 作者使用四种不同的传统路径规划算法:A* [18] and JPS [19]; PRM [20] and RRT* [21]。
每个PPG生成器一共生成26429个自监督的规划路径标签,然后按照3:1:1的比例划分训练、验证和测试集。
评价指标方面:
success rate (SR) 到达输入目标姿态而不与障碍物碰撞的路径
turning cost(TC)来衡量每条路径的平滑度

![[论文笔记]S2P2 Self-Supervised Goal-Directed Path Planning Using RGB-D Data_2021ICRA_第6张图片](http://img.e-com-net.com/image/info8/63bc013c3c0a47fda659b0b11efcd8a0.jpg)
RCM为 RSS2018 的一篇论文的一个方法。
![[论文笔记]S2P2 Self-Supervised Goal-Directed Path Planning Using RGB-D Data_2021ICRA_第7张图片](http://img.e-com-net.com/image/info8/827ae8661ab04223bf74142e92cf3d84.jpg)
我们的最佳拟合回归平面损失LR可以有效地减少离面点的不利影响,并进一步提高规划路径的性能
![[论文笔记]S2P2 Self-Supervised Goal-Directed Path Planning Using RGB-D Data_2021ICRA_第8张图片](http://img.e-com-net.com/image/info8/c526bc00595743b9acbcb0715a51c604.jpg)
D值越大 感知代价地图的质量越差。
当感知成本图的质量下降时,RRT的SR比我们的RRT-E3RS下降得更快
图4所示的定性结果证实。可以看到,当感知结果不是很准确时,E3RS和I3RS仍然呈现出比其他方法更好的性能。
原因是,其他方法取决于感知结果,而S2P2是一种端到端方法,不依赖于感知结果。此外,best - fit回归平面损耗lr可以有效地提高规划路径的性能。
![[论文笔记]S2P2 Self-Supervised Goal-Directed Path Planning Using RGB-D Data_2021ICRA_第9张图片](http://img.e-com-net.com/image/info8/3291510b3b22472d877bfd6b61198a87.jpg)
所提出的方法没有明确地模拟移动的障碍物。