【AXI】解读AXI协议中的burst突发传输机制
解读AXI协议中的burst突发传输机制
-
- 一、写在前面
- 二、burst突发传输机制解读
-
- 2.1 什么是burst传输
- 2.2 AXI4.0突发传输要求
- 2.3 信号列表
-
- 2.3.1 突发传输长度(burst length)
- 2.3.2 突发传输大小(burst size)
- 2.3.3 突发传输种类(burst type)
-
- 2.3.3.1 FIXED Type
- 2.3.3.2 INCR Type
- 2.3.3.3 WRAP Type
- 2.3.3.4 Reserved Type
- 2.3.4 突发传输地址(burst address)
- 2.4 突发传输的地址计算(ARADDR/AWADDR)
-
- 2.4.1 INCR地址计算
- 2.4.2 WRAP地址计算
- 2.5 突发传输的其他特性
-
- 2.5.1 Outstanding传输机制
- 2.5.2 Out Of Order传输机制
- 2.5.3 Narrow 传输机制
- 2.5.4 Unaligned 传输机制
- 2.6 总结
- 三、其他数字IC基础协议解读
-
- 3.1 UART协议
- 3.2 SPI协议
- 3.3 I2C协议
- 3.4 AXI协议
一、写在前面
AXI协议相较于UART,SPI,I2C来说,无论是内容还是难度都上了一个层级,放在一篇文章中进行解读未免篇幅过长,因此,有关AXI一些共性的、通用的问题,作者单独以前缀为【AXI】的标题进行小范围的串联,最终再汇总为深入浅出解读AXI协议,与从零开始的Verilog AXI协议设计,此为作者所思所考的推进顺序,单看【AXI】的每一篇,可能很多读者未免感到有些管中窥豹的疑惑,但若等作者更完此专栏再行观看,从头到尾进行阅读,应该就会有有茅塞顿开的收获与领悟。
二、burst突发传输机制解读
2.1 什么是burst传输
简单来说,burst传输是一种适用于AMBA协议的规则形式,通过这种规则,我们可以控制AMBA进行具体的数据传输活动,在这种规则下,主设备发送控制信息和首地址信息,从设备根据这些信号计算接下来的地址信息。
换言之,在这种规则下,主设备只需要发送一拍信息,就可以通过计算,决定未来数拍,写入或读出的地址。
下图中的读操作就生动形象的描述了这种Burst传输,一拍的地址和控制信号,操控了四拍的读出数据。
通过这种形式,控制信号的效率大大提升。
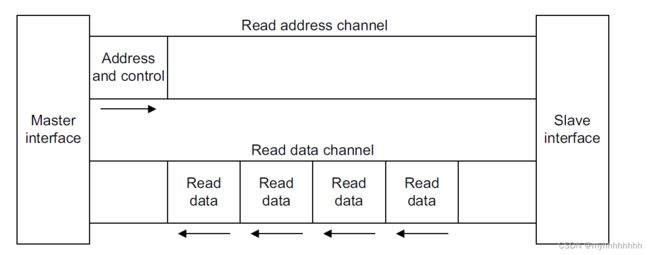
2.2 AXI4.0突发传输要求
burst传输不能超过4KB的地址边界,同时burst传输一旦开始,不允许中止。
2.3 信号列表
以下的信号描述,采用英文直译的方法进行,有些读者可能单看描述会觉得有些困惑,什么长度?什么大小?作者贴心的在后面进一步做了相关解释,所以,往后继续看即可。
读行为的信号列表
| 读操作信号 | 信号描述 |
|---|---|
| ARLEN[7:0] | 读操作burst传输长度 |
| ARSIZE[2:0] | 读操作burst传输大小 |
| ARBURST[1:0] | 读操作burst传输类型 |
| ARADDR | 读操作的首地址 |
以上的前三个信号为决定burst传输的最重要的三个控制信号,一次完整的burst传输当然还需要“数据信号、LAST等其他信号,但是作者希望尽量剥离“次相关内容”,不再这里进行讲解,等最终汇总AXI时再行说明”。
写行为的信号列表
| 写操作信号 | 信号描述 |
|---|---|
| AWREN[7:0] | 写操作burst传输长度 |
| AWSIZE[2:0] | 写操作burst传输大小 |
| AWBURST[1:0] | 写操作burst传输类型 |
| AWADDR | 写操作的首地址 |
与读信号极为相似的,写行为同样存在三个匹配的控制信号,分别决定写行为的传输长度,传输大小和传输类型。
2.3.1 突发传输长度(burst length)
突发传输长度对应8位的ARLEN信号,和8位的AWLEN信号,这个信号代表的是额外的transfer数量
即从设备在首地址外计算几次地址,或者说在首地址对应的数据外,需要额外进行多少次传输
ARLEN[7:0]与AWLEN[7:0]能表示0-255之间的数值,加上首地址对应的一次传输,引申出了burst length的数值范围为1-256,即在burst规则下总共进行多少次数据传输。
明白了这个概念,这里AXI3与AXI4协议的规定就出现了区别
AXI3,取信号的低四位,只使用一半的ARLEN和AWLEN信号,burst length的范围在1到16之间。
AXI4,使用了ARLEN和AWLEN的全部八位信号,burst lentgh的范围在1-256之间。
除此以外,具体的突发传输种类,也决定着burst length的有效值,后文会提及。
2.3.2 突发传输大小(burst size)
突发传输大小对应3位的AWSIZE和ARSIZE,这个信号代表的是传输的数据位宽,单位为8bit的字节。
Bytes=2^Burst_size
| AxSIZE[2:0] | Bytes | Bits |
|---|---|---|
| 000 | 1 | 8 |
| 001 | 2 | 16 |
| 010 | 4 | 32 |
| 011 | 8 | 64 |
| 100 | 16 | 128 |
| 101 | 32 | 256 |
| 110 | 64 | 512 |
| 111 | 128 | 1024 |
2.3.3 突发传输种类(burst type)
突发传输的种类对应的信号为ARBURST和AWBURST,这两个信号均为2bit,用以区分Burst传输的种类
| AxBURST[1:0] | Burst Type |
|---|---|
| 0b00 | FIXED |
| 0b01 | INCR |
| 0b10 | WRAP |
| 0b11 | Reserved |
2.3.3.1 FIXED Type
在Fixed种类的burst传输中,每一次访问的地址是相同的,这意味着我们需要对同一个地址进行读写操作,读者们有没有想到哪种电路结构非常符合这种规则?
没错,是FIFO,用AXI连接作为从设备的FIFO,只需要考虑Fixed Type的burst传输,这是因为FIFO不涉及到具体的地址来控制读写,数据只需要先入先出即可。
有关FIFO的内容,参考作者的这篇文章即可
【数字IC手撕代码】Verilog同步FIFO|题目|原理|设计|仿真
※需要注意的是Fixed Type的burst length仅支持1-16
2.3.3.2 INCR Type
在INCR Type的burst传输中,主设备给出首个地址和控制信号,接下来从设备会自发的计算出接下来传输数据所需要的,递增的,新的地址信号。
换言之,第一次传输的地址是1,并约定INCR Type的传输,之后的递增地址为2,3,4,5,6,7,8。之后的地址都由从设备自行计算得到。
这种形式的传输,经常的用在对于连续内存的读写上。
※需要注意的是,协议规定,INCR Type的burst length支持1-256
2.3.3.3 WRAP Type
WRAP Type又被称作回旋型的burst传输类型
假如第一次的传输地址是1,约定WRAP Type的传输类型,那么之后的回旋地址类似于2,3,4,0,1这样,地址绕了一个圈。
这种形式的传输类型主要应用在Cache的读写上,以下例子可供参考
cache有cache line的,比如4个dword(4个32bit)一条line,当cache missing的时候,可能需要的正好不是从地址0开始的,比如是从地址0xc开始的32bit,为了提高性能,所以开始发送的地址就是0xc开始的,但是cache line是存地址0x0,0x4,0x8,0xC 4个地址,这样第一次读到的数据是地址0xc的数据(指令),MCU就可以马上用了,但是为了存一条line,用wrap的方式,就会接着读地址0x0,0x4,和0x8.如果不是用wrap,cache就必须从地址0x0开始,多等3个cycle才能得到地址0xc的数据(指令)。
※需要注意的是WRAP Type的burst length仅支持2,4,8,16(即AxLEN = 1/3/7/15)
2.3.3.4 Reserved Type
Reserved:保留,AXI协议未规定0b11的burst type种类,因此针对于AxBURST而言,只有0b00,0b01,0b10存在具体的含义。
2.3.4 突发传输地址(burst address)
需要注意的是,AXI协议中对于AxADDR,尤其是ARADDR有着非常复杂的规定,比如说位宽含义,虚拟地址等等,但是我们在这篇博客讨论burst传输机制时同样可以先剥离那些更为复杂的内容,仅把AxADDR当成一个起始地址即可。
2.4 突发传输的地址计算(ARADDR/AWADDR)
在Burst中,另一个非常重要的内容是突发传输的地址计算,本节与实际电路存在关联关系,从设备为了自发计算Burst地址,肯定需要使用到加法器,那么加法器的输入应该是一个什么样子的呢?
对于Fixed Type和Reserved Type,我们不需要具体计算他们的地址,因此只需要讨论INCR和WRAP形式即可
2.4.1 INCR地址计算
计算公式为:Address_N = Aligned_Address + (N-1) × Number_Bytes
- Address_N为第N个地址
- Aligned_Address为对齐后的首地址
- Aliged_Address = INT(Start_Address / Number_Bytes) × Number_Bytes
- INT为向下取整的函数
- Start_Address是起始地址
- Number_Bytes = 2^AxSize
举例:假如起始地址为0x01,Axsize为0b010,Burst length是16,请计算第5个地址是什么?
- 先对0x01进行对齐,对齐后为0x00
- Number_Bytes为4
- 第五个地址为0x00+0x10(十六进制的10为十进制的16)
- 得到地址为0x10
2.4.2 WRAP地址计算
下边界的计算公式为:
Wrap_Boundary = (INT(Start_Address / (Number_Bytes × Burst_Length))) × (Number_Bytes × Burst_Length)
上边界的计算公式为:
Address_N = Wrap_Boundary + (Number_Bytes × Burst_Length)
- 这里的Number_Bytes等等与INCR中的含义相同,Burst_Length为2.3.1节的那个内容。
- 当计算的地址触碰到Address_N(上边界),实际上使用的地址为下边界的Wrap_Baundary
- 在未触碰到上边界时,使用与2.4.1相同的计算公式来进行计算,
- Address_N = Aligned_Address + ( N - 1 ) × Number_Bytes(2.4.1)
- 在地址计算的后半程,使用新的计算公式如下
- Address_N = Start_Address + ((N – 1) × Number_Bytes) – (Number_Bytes × Burst_Length)
举例:起始地址为AxADDR = 0x04, AxLEN = 3, AxSIZE = 2, AxBURST = 3(定义Wrap传输),它的四次传输的地址分别是什么?
- burst length为4,Number_Bytes为4
- 计算下边界为0x00,上边界为0x10
- 地址1 0x04
- 地址2 0x08
- 地址3 0x0c
- 地址4 0x10(因为到达了上边界,所以实际为0x00)
2.5 突发传输的其他特性
2.5.1 Outstanding传输机制
我们在2.4节之前讨论的burst传输,可以看做“单次传输对应多个地址”,主要的目的是为了提高单次传输的效率,那么如何提高多次传输的效率呢?
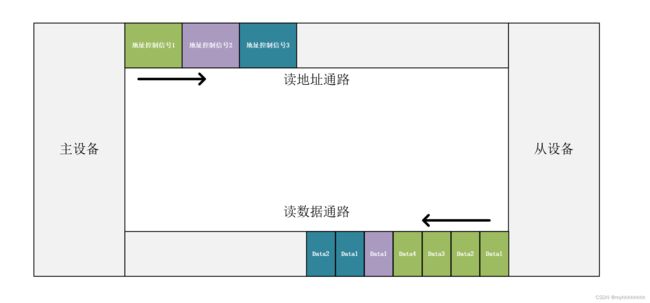
设想一种情况,我们想对同样一个从设备进行十次burst传输读操作,这十次burst传输类型在fixed,incr和wrap中随机,那么按照前文所讲的内容,一个一个burst传输的过程中分别进行握手,难免保证握手时不需要等待主设备的中断而产生气泡,影响效率,但是假如一次握手后,主设备直接发送十个地址和控制信号,把这些控制信号放到缓存中,前一个burst执行完后再直接执行下一个burst操作,不就可以避免等待,提升效率了吗?这就是outstanding传输机制的本质,相当于把burst传输流水线起来了。
以下的图片非常形象的说明了这个问题,从单次单次的传输蜕变为了Outstanding形式的传输

2.5.2 Out Of Order传输机制
2.5.1中可以看作是对同一从设备多次burst传输提升效率的方法即Outstanding传输”机制,那么对于一个主设备,多个从设备来说,有没有提升效率的方法呢?这里涉及到的就是Out of order机制了。
简单来说,除了前文提到的信号外,每次burst传输时还会传送一个Transaction ID信号,这个信号遵循的原则也可以简单的叙述为下面的内容:
同一个Transcation ID信号需要按照传输的顺序进行,不同的Transcation ID信号,乱序执行,以读操作为例,哪个burst先读完就吐出哪个数据,这样的乱序进一步的提升了AXI的读写效率
2.5.3 Narrow 传输机制
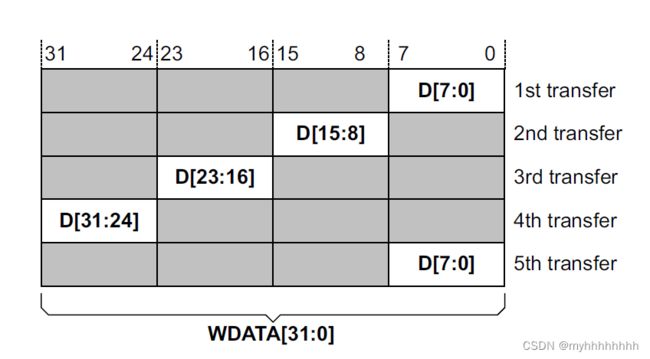
接下来我们讨论的是AXI的Narrow传输机制,设想一种情况,假如我们的数据信号位宽是32位,而AxSIZE为0b000,即1 Bytes/8Bits,那么实际的传输机制是什么样子的呢?
假如它的地址是从0开始,那么transfer1传输数据总线的[7:0],transfer2传输数据总线[15:8],transfer3传输[23:16],transfer4传输[31:24],具体哪一个Bytes有效使用了WSTRB信号进行操控。
这就是Narrow传输机制,即当Axsize比数据总线位宽短的情况下进行传输的规则
2.5.4 Unaligned 传输机制
另一个和burst传输联系紧密的是它的非对齐机制,假如起始地址是0x01(即非对齐),而Axsize为4Byes对应32bits,那么对它进行的第一次传输填充的地址为0x00,0x01,0x02,0x03,但是这四个地址中的第一个0x00通过WSTRB信号将填充的数据标记为无效,当经过首个地址的对齐操作后,接下来4bytes大小的填充都就是对齐地址的操作了,如下图所示,陆续填充即可。

2.6 总结
我们在握手信号的基础上继续讲解了AXI协议中的burst机制,讨论了burst传输的地址计算问题,和它的控制信号(AxSIZE,AxLEN,AxBurst)的具体含义,Burst机制外,Outstanding传输机制和Out of order传输机制也同样的提高了AXI协议的传输效率,此外,协议还规定了窄传输机制,和非对齐机制,同样为burst传输中重要的组成部分,受限于篇幅有限,有一些与Burst次相关的内容没有出现在文章中:如最后一拍的Last信号和决定哪个Bytes有效的WSTRB,不过客观来说,文章也基本上涵盖了AXI4.0 协议中Burst传输的大部分内容了,剩余的边边角角,会放到其它的[AXI]协议内容和汇总中进行讨论。
以上,祝大家秋招顺利!
三、其他数字IC基础协议解读
3.1 UART协议
- 【数字IC】深入浅出理解UART
- 【数字IC】从零开始的Verilog UART设计
3.2 SPI协议
- 【数字IC】深入浅出理解SPI协议
- 【数字IC】从零开始的Verilog SPI设计
3.3 I2C协议
- 【数字IC】深入浅出理解I2C协议
3.4 AXI协议
- 【AXI】解读AXI协议双向握手机制的原理
- 【AXI】解读AXI协议中的burst突发传输机制