pytorch基于DistributedDataParallel进行单机多卡的分布式训练
本文的宗旨就是一文实现基于pytorch的单机多卡的分布式训练,多机多卡的暂时先不记录。没有pytorch分布式训练的原理等内容,目的是通过几个步骤能够直接快速的使用多GPU,包括分布式模型的save和load。之前的文章有简单的记录,但是有点问题,不够详细。
pytorch实现单机多卡有DataParallel和DistributedDataParallel,也就是DP和DDP这两种形式,
DP:
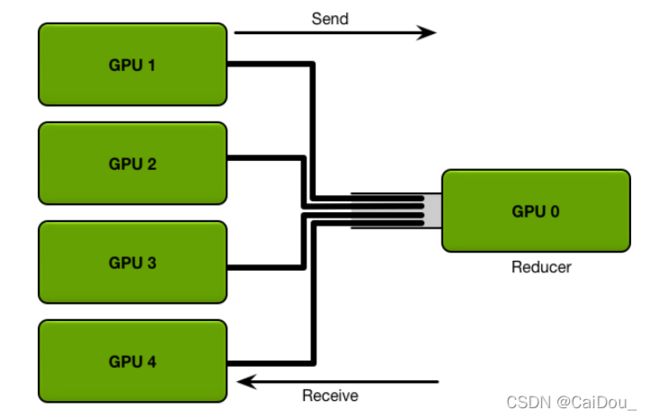
DDP:
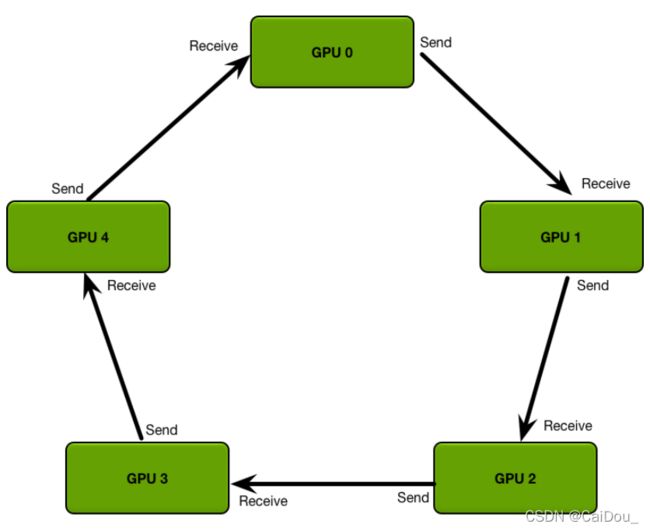
前者DP比较简单,两行代码就行,但非真正的分布式,后者能够实现不同的GPU 占用基本相同的显存。这里只说后者。
1.训练代码与启动
from torch.utils.data import Dataset, DataLoader
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
#step1:定义通信方式和device,这里device一般用命令行的的方式
#在使用torch.distributed.launch启动时,会自动给入local_rank参数
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=int,default=-1)
FLAGS = parser.parse_args()
local_rank = FLAGS.local_rank
torch.cuda.set_device(local_rank)
dist.init_process_group(backend='nccl') # nccl的后端通信方式
device = torch.device("cuda", local_rank)
#step2:分发数据,很重要的一步
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
val_sampler = torch.utils.data.distributed.DistributedSampler(val_dataset)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=False, sampler=train_sampler,num_workers=2)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, sampler=val_sampler,num_workers=2) #此处shuffle需要为False,可以自行在此之前先进行shuffle操作。
setep3:初始化训练模型,使用DDP的方式
model = MyModel().to(device)#自己的模型
#model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)#按照实际情况进行同步BN
model = DDP(model,find_unused_parameters=True ,device_ids=[local_rank], output_device=local_rank) #DDP方式初始化模型,这种方式会在模型的key上带上"module"
#setep4:训练每个epoch时
for epoch in range(1, CFG.epochs + 1):
train_loader.sampler.set_epoch(epoch) # 各个进程之间相同种子数
启动训练 :
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 train.py
#--nproc_per_node=2 一般用几张卡,就设为几2.模型保存
if dist.get_rank() == 0:#根据情况,保存一个卡上(0卡)的模型或者都保存,都保存的话注意模型文件的名字
temp_model_path = CFG.model_save_dir + "/"+ "temp_{}".format(epoch)+ "_" + ".pth"
torch.save(model.state_dict(), temp_model_path)3.模型加载
使用上述保存模型,DDP保存时候会带上”module“,按照自己保存的情况,如果是key带上了"module"的话可以用下面的方式去掉,也可以在保存模型的时候改。
from collections import OrderedDict
checkpoint = torch.load(pathmodel, map_location=torch.device('cpu'))
new_state_dict = OrderedDict()
for k,v in checkpoint.items():
name = k.replace("module.","") # remove `module`
new_state_dict[name] = v
model.load_state_dict(new_state_dict)至此,按照这几个步骤,3分钟把单机单卡改为单机多卡分布式训练。