简介
每一门数据库语言语法都基本相似,但是对于他们各自的一些特性(函数、存储过程等)的用法就不大相同了,就好比Oracle与Mysql存储过程写起来就很多不同的地方,在这里主要是跟大家分享一下MySql存储过程中使用游标循环的处理方法。
场景描述
我们举一个简单的场景,首先我们可能会有这样一种情况,考试成绩表(t_achievement)有一堆的sql脚本处理,需要依赖另一个学生表(t_student)数据对部分学生做考试成绩汇总记录到成绩汇总表(t_achievement_report)。
解决方案
- 有一种方式就是通过代码优先将要汇总的学生表数据获取出来,然后按成绩汇总流程逐个将学生信息数据传递到成绩汇总业务代码进行处理。
- 另一种方式也是我们今天的主题,那就是通过存储过程的方式去做。
案例
建表语句:
-- 学生信息表 DROP TABLE IF EXISTS t_student; CREATE TABLE `t_student` ( `id` BIGINT(12) NOT NULL AUTO_INCREMENT COMMENT '主键', `code` VARCHAR(10) NOT NULL COMMENT '学号', `name` VARCHAR(20) NOT NULL COMMENT '姓名', `age` INT(2) NOT NULL COMMENT '年龄', `gender` CHAR(1) NOT NULL COMMENT '性别(M:男,F:女)', PRIMARY KEY (`id`), UNIQUE KEY UK_STUDENT (`code`) ) CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
-- 学生成绩表 DROP TABLE IF EXISTS t_achievement; CREATE TABLE `t_achievement` ( `id` BIGINT(12) NOT NULL AUTO_INCREMENT COMMENT '主键', `year` INT(4) NOT NULL COMMENT '学年', `subject` CHAR(2) NOT NULL COMMENT '科目(01:语文,02:数学,03:英语)', `score` INT(3) NOT NULL COMMENT '得分', `student_id` BIGINT(12) NOT NULL COMMENT '所属学生id', PRIMARY KEY (`id`) ) CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
-- 成绩汇总表 DROP TABLE IF EXISTS t_achievement_report; CREATE TABLE `t_achievement_report` ( `id` BIGINT(12) NOT NULL AUTO_INCREMENT COMMENT '主键', `student_id` BIGINT(12) NOT NULL COMMENT '学生id', `year` INT(4) NOT NULL COMMENT '学年', `total_score` INT(4) NOT NULL COMMENT '总分', `avg_score` DECIMAL(4,2) NOT NULL COMMENT '平均分', PRIMARY KEY (`id`) ) CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
初始化数据:
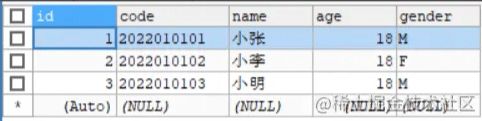
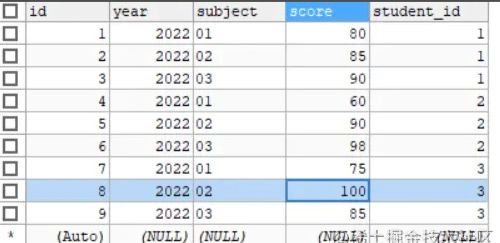
INSERT INTO t_student(id, CODE, NAME, age, gender) VALUES (1, '2022010101', '小张', 18, 'M'), (2, '2022010102', '小李', 18, 'F'), (3, '2022010103', '小明', 18, 'M'); INSERT INTO t_achievement(YEAR, SUBJECT, score, student_id) VALUES (2022, '01', 80, 1), (2022, '02', 85, 1), (2022, '03', 90, 1), (2022, '01', 60, 2), (2022, '02', 90, 2), (2022, '03', 98, 2), (2022, '01', 75, 3), (2022, '02', 100, 3), (2022, '03', 85, 3);
存储过程:
在这里主要以上面的场景为例,使用存储过程循环去处理数据。写一个存储过程,将以上数据每个学生的成绩进行汇总。
-- 如果存储过程存在,先删除存储过程
DROP PROCEDURE IF EXISTS statistics_achievement;
DELIMITER $$
-- 定义存储过程
CREATE PROCEDURE statistics_achievement()
BEGIN
-- 定义变量记录循环处理是否完成
DECLARE done BOOLEAN DEFAULT FALSE;
-- 定义变量传递学生id
DECLARE studentid BIGINT(12);
-- 定义游标
DECLARE cursor_student CURSOR FOR SELECT id FROM t_student;
-- 定义CONTINUE HANDLER,当循环结束时 done=true
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done=TRUE;
-- 打开游标
OPEN cursor_student;
-- 重复遍历
REPEAT
-- 每次读取一次游标
FETCH cursor_student INTO studentid;
-- 计算总分、平均分插入汇总表
INSERT INTO t_achievement_report(student_id, `YEAR`, total_score, avg_score)
SELECT studentid, `YEAR`, SUM(score), ROUND(SUM(score) / 3, 2) FROM t_achievement t1 WHERE student_id = studentid AND NOT EXISTS(
SELECT 1 FROM t_achievement_report t2 WHERE student_id = studentid AND t1.year = t2.year
) GROUP BY `YEAR`;
-- 结束循环,意思是等到done=true时,结束循环REPEAT
UNTIL done END REPEAT;
-- 查询结果,仅会展示查出的最后一条
SELECT studentid;
-- 关闭游标
CLOSE cursor_student;
END$$
DELIMITER ;
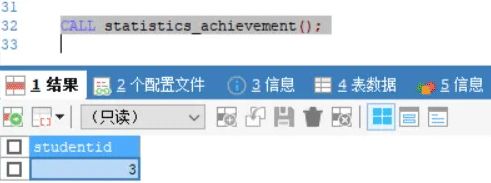
-- 执行存储过程 CALL statistics_achievement();
- 执行结果,返回查询结果3,即最后一条学生记录id

总结
存储过程也有很强大的功能,如果是一名DBA那么写存储过程是分分钟的事,但是作为一名专做业务的码农还是不建议去使用存储过程写业务代码。前公司同事适应了写存储过程,有业务改动时不时的直接用存储过程搞定了,到最后直接就是一大堆堆存储过程代码,一个存储过程下来几百上千行sql代码头都看晕掉,出问题巨难维护,稍有不熟的人员都不敢轻举妄动,今天在这里也只是为了讲解存储过程中的循环而举了个栗子请别介意。
总之我认为存储过程主要还是用来临时处理一些数据方便而用一下,特别有些业务改造大,需要做数据割接总不能挨个去写一个业务代码吧。
到此这篇关于MySql存储过程循环的使用分析详解的文章就介绍到这了,更多相关MySql存储过程循环内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!