关于Scikit-learn机器学习的笔记——第五篇
视频教程:【莫烦Python】Scikit-learn (sklearn) 优雅地学会机器学习
首先用KNN模型来进行基础的学习并且计算模型的分数
程序示例:
from sklearn.datasets import load_iris##从sklearn数据库导入数据
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier##从sklearn数据库导入算法,K邻近分类
iris=load_iris()##导入鸢尾花数据
X=iris.data##花的属性存在data里面
y=iris.target##花的分类在target里面
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=4)
knn=KNeighborsClassifier(n_neighbors=5)##机器学习命令,考虑学习点附近5个点的neighbor
knn.fit(X_train,y_train)##这个函数帮助我们完成学习的步骤,所有training在这一步进行
print(knn.score(X_test,y_test))
输出结果:
0.9736842105263158
得分为0.97
接下来我们用5组数据去验证

程序示例:
from sklearn.datasets import load_iris##从sklearn数据库导入数据
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier##从sklearn数据库导入算法,K邻近分类
iris=load_iris()##导入鸢尾花数据
X=iris.data##花的属性存在data里面
y=iris.target##花的分类在target里面
from sklearn.model_selection import cross_val_score
#X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=4)
knn=KNeighborsClassifier(n_neighbors=5)##机器学习命令,考虑学习点附近5个点的neighbor
scores=cross_val_score(knn,X,y,cv=5,scoring='accuracy')##将数据分成5层,把数据集平均分成5份,scoring方法是accuracy判断准确度
print(scores)
输出结果:
[0.96666667 1. 0.93333333 0.96666667 1. ]
有两组到了100%,平均一下会更加精准
print(scores.mean())
输出结果:
0.9733333333333334
接下来我们观察k从1到31,cv=10,模型的评价值
from sklearn.datasets import load_iris##从sklearn数据库导入数据
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier##从sklearn数据库导入算法,K邻近分类
iris=load_iris()##导入鸢尾花数据
X=iris.data##花的属性存在data里面
y=iris.target##花的分类在target里面
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
k_range=range(1,31)##k的范围是1到31
k_scores=[]
for k in k_range:
knn=KNeighborsClassifier(n_neighbors=k)##机器学习命令,考虑学习点附近k个点的neighbor,把k从1到31都带进去
scores=cross_val_score(knn,X,y,cv=10,scoring='accuracy')##for classication
#loss=-cross_val_score(knn,X,y,cv=10,scoring='mean_squared_error')##for regression
k_scores.append(scores.mean())##每次的结果都附加上去
plt.plot(k_range,k_scores)
plt.xlabel('Value for K of KNN')
plt.ylabel('Cross-Validated Accuracy')
plt.show()
输出结果:
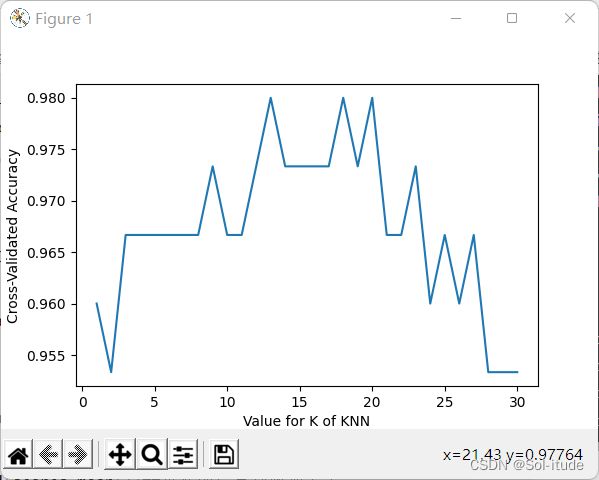
可以看出,k在14到18之间,是非常准确的
如果我们用另一种方式,用判断误差的形式,观察结果会是什么样子的
程序示例:
from sklearn.datasets import load_iris##从sklearn数据库导入数据
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier##从sklearn数据库导入算法,K邻近分类
iris=load_iris()##导入鸢尾花数据
X=iris.data##花的属性存在data里面
y=iris.target##花的分类在target里面
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
k_range=range(1,31)##k的范围是1到31
k_scores=[]
for k in k_range:
knn=KNeighborsClassifier(n_neighbors=k)##机器学习命令,考虑学习点附近k个点的neighbor,把k从1到31都带进去,这里的模型也可以改,判断该采用什么样子的模型
#scores=cross_val_score(knn,X,y,cv=10,scoring='accuracy')##for classication,用了cv=10更精准
loss=-cross_val_score(knn,X,y,cv=10,scoring='neg_mean_squared_error')##for regression,判断误差
k_scores.append(loss.mean())##每次的结果都附加上去
plt.plot(k_range,k_scores)
plt.xlabel('Value for K of KNN')
plt.ylabel('Cross-Validated Accuracy')
plt.show()
输出结果:
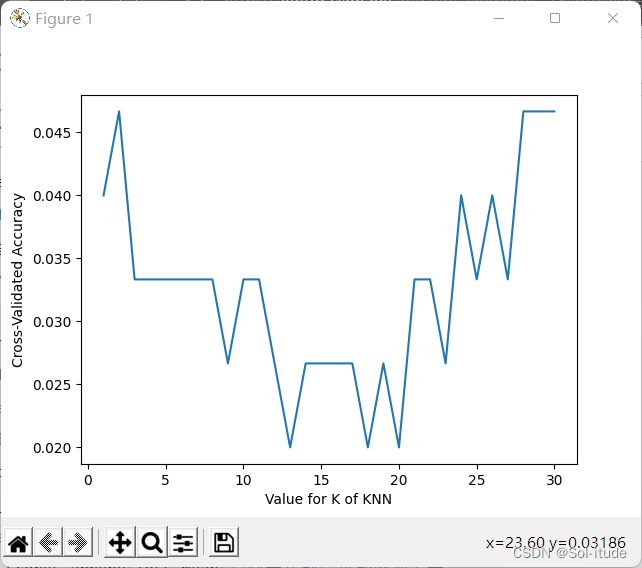
loss越小,他的误差越小,应该选最小loss的k值
如果要换不同的模型,只需要改model那里就好