西瓜书《机器学习》读书笔记-第6章 支持向量机(Support Vector Machine)
写在前面
开始挖新坑学习一下《机器学习》. 主要是看浙江大学胡浩基老师的网课,结合周志华老师的西瓜书来学. 为了理清思路和推公式就敲了这样一个读书笔记. 初次学习难免会有错漏,欢迎批评指正. 这份笔记主要用途还是用来自己复习回顾. 当然如果对大家有帮助那就更好了hhh
第6章 支持向量机(Support Vector Machine)
· 提出者: Vladimir N. Vapnik \text{Vladimir N. Vapnik} Vladimir N. Vapnik.
· 在样本数量较小时,效果较好. 其背后具有有力的数学原理支撑.
· 相关书籍:《支持向量机导论》.
概念
- 线性可分(Linear Separable)
- 非线性可分(Non-linear Separable)

线性可分样本集可以用无线条直线将两种类别的样本划分开,那么哪条直线划分效果最好?
- 定义“性能指标”,性能指标越高,则划分效果越好. 如下图所示,性能指标定义为间隔 γ \gamma γ.

数学描述
- d d d:间隔(margin)
支持向量机是使得 d d d最大的方法( SVM \text{SVM} SVM是最大化间隔的分类算法)
- 支持向量(support vector):平行线“插”到的向量
一、 概念与定义
- 训练数据及标签: ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x n , y n ) (\boldsymbol{x}_1,y_1),(\boldsymbol{x}_2,y_2),\cdots,(\boldsymbol{x}_n,y_n) (x1,y1),(x2,y2),⋯,(xn,yn)
其中 x i \boldsymbol{x}_i xi为向量, y i ∈ { − 1 , + 1 } y_i\in\left\{-1,+1\right\} yi∈{−1,+1}为标签. - 线性模型:
需要找到一个模型,在二维情形为直线,三维情形为平面,多维情形为超平面. 其参数为 ( w , b ) (\boldsymbol{w},b) (w,b)
考虑超平面(Hyperplane):
w T x + b = 0 \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}+b=0 wTx+b=0其中
w = [ w 1 w 2 ⋯ w N ] T \boldsymbol{w}=\left[ \begin{matrix} w_1& w_2& \cdots& w_N\\ \end{matrix} \right] ^{\mathrm{T}} w=[w1w2⋯wN]T是超平面的法向量.
- 一个训练集线性可分:
∃ ( w , b ) , 使 ∀ i = 1 , ⋯ , N , 有 { ( a ) 若 y i = + 1 , 则 w T x i + b ⩾ 0 ( b ) 若 y i = − 1 , 则 w T x i + b < 0 ( 或 y i ( w T x i + b ) ⩾ 0 ) \exists \left( \boldsymbol{w},b \right) , \text{使}\forall i=1,\cdots ,N, \text{有}\left\{ \begin{array}{c} \left( a \right) \text{若}y_i=+1, \text{则}\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b\geqslant 0\\ \left( b \right) \text{若}y_i=-1, \text{则}\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b<0\\ \end{array} \right. \\ \left( \text{或}y_i\left( \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b \right) \geqslant 0 \right) ∃(w,b),使∀i=1,⋯,N,有{(a)若yi=+1,则wTxi+b⩾0(b)若yi=−1,则wTxi+b<0(或yi(wTxi+b)⩾0)
二、支持向量机的基本型
由上述推导可知, SVM \text{SVM} SVM是要解决以下的优化问题:
min w , b ∥ w ∥ 2 s . t . y i ( w T x i + b ) ⩾ 1 , i = 1 , 2 , ⋯ , N . \begin{aligned} &\underset{\boldsymbol{w},b}{\min}\,\,\left\| \boldsymbol{w} \right\| ^2 \\ &\mathrm{s}.\mathrm{t}. y_i\left( \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b \right) \geqslant 1, i=1,2,\cdots ,N. \end{aligned} w,bmin∥w∥2s.t.yi(wTxi+b)⩾1,i=1,2,⋯,N.
一些事实:
事实1: w T x + b = 0 \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}+b=0 wTx+b=0与 a w T x + a b = 0 a\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}+ab=0 awTx+ab=0表示同一个平面. ( a ∈ R + a\in \mathbb{R} ^+ a∈R+)
该事实蕴含:
若 ( w , b ) \left( \boldsymbol{w},b \right) (w,b)满足公式1,则 ( a w , a b ) \left( a\boldsymbol{w},ab \right) (aw,ab)也满足公式1.
事实2:点 x 0 \boldsymbol{x_0} x0到超平面 w T x + b = 0 \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}+b=0 wTx+b=0距离
r = ∣ w T x 0 + b ∣ ∥ w ∥ r=\frac{\left| \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_0+b \right|}{\left\| \boldsymbol{w} \right\|} r=∥w∥∣∣wTx0+b∣∣
1. 关于最小化目标函数的解释
我们可以用 a ( a > 0 ) a(a>0) a(a>0)去缩放 ( w , b ) → ( a w , a b ) \left( \boldsymbol{w},b \right)\rightarrow\left( a\boldsymbol{w},ab \right) (w,b)→(aw,ab),最终使在支持向量 x 0 \boldsymbol{x}_0 x0上,有
∣ w T x 0 + b ∣ = 1 \left|\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_0+b\right|=1 ∣∣wTx0+b∣∣=1
具体地说,通过平移超平面 w T x + b = 0 \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}+b=0 wTx+b=0,可以得到一系列与其平行的平面 w T x + b = m \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}+b=m wTx+b=m. 不妨设当平面穿过支持向量 x 0 \boldsymbol{x}_0 x0时,有 w T x 0 + b = m 0 \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_0+b=m_0 wTx0+b=m0. 为了便于计算,将等式右边化为 1 1 1,即
1 m 0 ( w T x 0 + b ) = 1 \frac{1}{m_0}\left( \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_0+b \right) =1 m01(wTx0+b)=1那么此时由于
w T x 0 + b = 0 ⇔ 1 m 0 ( w T x 0 + b ) = 0 \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_0+b=0\Leftrightarrow \frac{1}{m_0}\left( \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_0+b \right) =0 wTx0+b=0⇔m01(wTx0+b)=0
这两个方程表示同一个超平面,因此可作变换 ( w T , b ) : = 1 m 0 ( w T , b ) . \left( \boldsymbol{w}^{\mathrm{T}},b \right) :=\frac{1}{m_0}\left( \boldsymbol{w}^{\mathrm{T}},b \right). (wT,b):=m01(wT,b).
此时,支持向量与平面距离
r = 1 ∥ w ∥ r=\frac{1}{\left\| \boldsymbol{w} \right\|} r=∥w∥1我们需要最大化 r r r,也即最小化 ∥ w ∥ 2 \,\,\left\| \boldsymbol{w} \right\| ^2 ∥w∥2.
2. 关于限制条件的解释
对于支持向量以外的向量,其与平面距离不小于 r r r,即
∣ w T x i + b ∣ ∥ w ∥ ⩾ r = ∣ w T x 0 + b ∣ ∥ w ∥ = 1 ∥ w ∥ \frac{\left| \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b \right|}{\left\| \boldsymbol{w} \right\|}\geqslant r=\frac{\left| \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_0+b \right|}{\left\| \boldsymbol{w} \right\|}=\frac{1}{\left\| \boldsymbol{w} \right\|} ∥w∥∣∣wTxi+b∣∣⩾r=∥w∥∣∣wTx0+b∣∣=∥w∥1即
∣ w T x i + b ∣ ⩾ 1 \left| \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b \right|\geqslant1 ∣∣wTxi+b∣∣⩾1具体来说,对于在平面上、下方的向量,有
{ w T x i + b ⩾ 1 , x i 在平面上方 − w T x i + b ⩾ 1 , x i 在平面下方 ⇔ y i ( w T x i + b ) ⩾ 1 \left\{ \begin{array}{c} \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b\geqslant 1, \boldsymbol{x}_i\text{在平面上方}\\ -\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b\geqslant 1, \boldsymbol{x}_i\text{在平面下方}\\ \end{array} \right. \Leftrightarrow y_i\left( \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b \right) \geqslant 1 {wTxi+b⩾1,xi在平面上方−wTxi+b⩾1,xi在平面下方⇔yi(wTxi+b)⩾1
3. 目标函数的写法
min w , b ∥ w ∥ 2 \underset{\boldsymbol{w},b}{\min}\,\,\left\| \boldsymbol{w} \right\| ^2 w,bmin∥w∥2 也可以写作 min w , b 1 2 ∥ w ∥ 2 \underset{\boldsymbol{w},b}{\min}\,\,\frac{1}{2}\left\| \boldsymbol{w} \right\| ^2 w,bmin21∥w∥2,其中的 1 2 \frac{1}{2} 21是为了方便求导.
4. 这是一个凸二次规划(convex quadratic programming) 问题
附:二次规划问题(Quadratic Programming)
(1)目标函数(objective function):二次项
(2)限制条件:一次项
显然目标函数全为二次项,限制条件为一次项,属于二次规划问题.
事实:二次规划中,要么无解,要么只有一个极值. 因此,支持向量机的理论将寻找超平面的问题转化为了能够求得全局最优解的二次规划问题.
至于如何求解这个二次规划问题,需要凸优化理论,在此处不涉及.
三、支持向量机的非线性模型
目的:使得训练样本是非线性可分时也有解.
(一)改写优化目标函数和限制条件
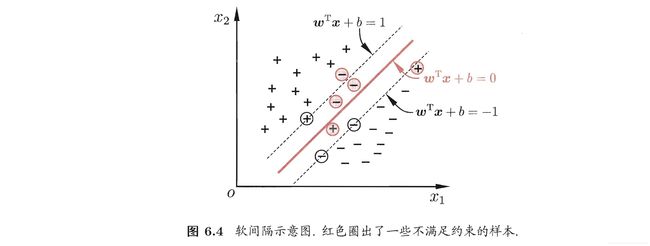
1. 软间隔(soft margin)
引入软间隔,从而允许支持向量机在部分样本上出错.
2. 优化问题的改写
min w , b 1 2 ∥ w ∥ 2 + C ∑ i = 1 N l 0 / 1 ( y i ( w T x i + b ) − 1 ) \underset{\boldsymbol{w},b}{\min}\,\,\frac{1}{2}\left\| \boldsymbol{w} \right\| ^2+C\sum_{i=1}^N{l_{0/1}\left( y_i\left( \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b \right) -1 \right)} w,bmin21∥w∥2+Ci=1∑Nl0/1(yi(wTxi+b)−1)其中常数 C > 0 C>0 C>0, 0 / 1 0/1 0/1损失函数
l 0 / 1 ( z ) = { 1 , i f z < 0 ; 0 , o t h e r w i s e . l_{0/1}\left( z \right) =\begin{cases} 1, \mathrm{if}\ z<0;\\ 0, \mathrm{otherwise}.\\ \end{cases} l0/1(z)={1,if z<0;0,otherwise.
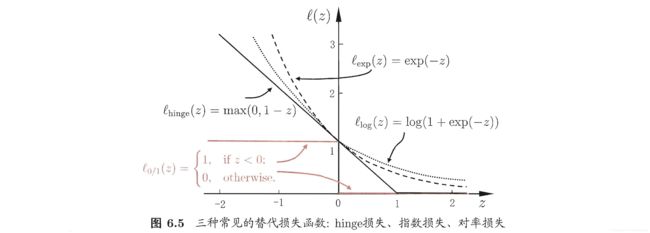
3. 替代损失函数(surrogate loss)
0 / 1 0/1 0/1损失函数 l 0 / 1 l_{0/1} l0/1性质不好,用其他函数替代.

4. 软间隔支持向量机
采用 hinge \text{hinge} hinge损失,有
∑ i = 1 N l 0 / 1 ( y i ( w T x i + b ) − 1 ) = ∑ i = 1 N max ( 0 , 1 − y i ( w T x i + b ) ) \sum_{i=1}^N{l_{0/1}\left( y_i\left( \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b \right) -1 \right)}=\sum_{i=1}^N{\max \left( 0,1-y_i\left( \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b \right) \right)} i=1∑Nl0/1(yi(wTxi+b)−1)=i=1∑Nmax(0,1−yi(wTxi+b))引入松弛变量 ξ i \xi _i ξi. 令
max ( 0 , 1 − y i ( w T x i + b ) ) = ξ i \max \left( 0,1-y_i\left( \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b \right) \right) =\xi _i max(0,1−yi(wTxi+b))=ξi显然有 ξ i ⩾ 0 \xi_i\geqslant 0 ξi⩾0. 并且当 1 − y i ( w T x i + b ) > 0 1-y_i\left( \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b \right) >0 1−yi(wTxi+b)>0时,有
1 − y i ( w T x i + b ) = ξ i 1-y_i\left( \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b \right) =\xi_i 1−yi(wTxi+b)=ξi当 1 − y i ( w T x i + b ) ⩽ 0 1-y_i\left( \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b \right) \leqslant 0 1−yi(wTxi+b)⩽0时
ξ i = 0 \xi_i=0 ξi=0因此
1 − y i ( w T x i + b ) ⩽ ξ i ⇒ y i ( w T x i + b ) ⩾ 1 − ξ i 1-y_i\left( \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b \right) \leqslant \xi _i\Rightarrow y_i\left( \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b \right) \geqslant 1-\xi _i 1−yi(wTxi+b)⩽ξi⇒yi(wTxi+b)⩾1−ξi从而将问题转化为
min w , b , ξ i 1 2 ∥ w ∥ 2 + C ∑ i = 1 N ξ i s . t . { y i ( w T x i + b ) ⩾ 1 − ξ i ξ i ⩾ 0 \begin{aligned} &\underset{\boldsymbol{w},b,\xi _i}{\min}\,\,\frac{1}{2}\left\| \boldsymbol{w} \right\| ^2+C\sum_{i=1}^N{\xi _i}\\ &\mathrm{s}.\mathrm{t}.\begin{cases} y_i\left( \boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}_i+b \right) \geqslant 1-\xi _i\\ \xi _i\geqslant 0\\ \end{cases}\\ \end{aligned} w,b,ξimin21∥w∥2+Ci=1∑Nξis.t.{yi(wTxi+b)⩾1−ξiξi⩾0
关于松弛变量(slack variables)的说明
(1) 当 ξ i \xi_i ξi非常大的时候,虽然限制条件1容易被满足,但优化问题得到的解并不理想. 因此,在目标函数中增加一项 C ∑ i = 1 N ξ i C\sum_{i=1}^N{\xi _i} C∑i=1Nξi,使得 ξ i \xi_i ξi不至于太大.
(2) 其中 C ∑ i = 1 N ξ i C\sum_{i=1}^N{\xi _i} C∑i=1Nξi称作正则项(regularization term)(或称作惩罚系数). C C C为事先设定好的参数,其选取方法为在一定的区间内尝试不同的 C C C,选择效果较好的那个 C C C. (这也是 SVM \text{SVM} SVM算法表现较好的原因,因为需要调整的参数少)
(二)低维到高维的映射
1.【引入】异或问题
在较低维度下,训练样本非线性可分. 考虑将训练样本映射到更高维的空间中,再进行划分. 即
x ↦ ϕ ( x ) \boldsymbol{x}\mapsto \phi \left( \boldsymbol{x} \right) x↦ϕ(x)将低维的 x \boldsymbol{x} x映射到高维$\phi \left( \boldsymbol{x} \right) $,再用平面进行划分.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gMdFYc98-1626697939749)(2021-07-18-16-34-13.png)]
考虑一个具体问题:平面上有四点
x 1 = [ 0 0 ] ∈ C 1 , x 2 = [ 1 1 ] ∈ C 1 , x 3 = [ 1 0 ] ∈ C 2 , x 4 = [ 0 1 ] ∈ C 2 . x_1=\left[ \begin{array}{c} 0\\ 0\\ \end{array} \right] \in C_1, x_2=\left[ \begin{array}{c} 1\\ 1\\ \end{array} \right] \in C_1, x_3=\left[ \begin{array}{c} 1\\ 0\\ \end{array} \right] \in C_2, x_4=\left[ \begin{array}{c} 0\\ 1\\ \end{array} \right] \in C_2. x1=[00]∈C1,x2=[11]∈C1,x3=[10]∈C2,x4=[01]∈C2.定义 ϕ ( x ) \phi(x) ϕ(x):
x = [ a b ] → ϕ ϕ ( x ) = [ a 2 b 2 a b a b ] x=\left[ \begin{array}{c} a\\ b\\ \end{array} \right] \xrightarrow{\phi}\phi \left( x \right) =\left[ \begin{array}{c} a^2\\ b^2\\ a\\ b\\ ab\\ \end{array} \right] x=[ab]ϕϕ(x)=⎣⎢⎢⎢⎢⎡a2b2abab⎦⎥⎥⎥⎥⎤那么
ϕ ( x 1 ) = [ 0 0 0 0 0 ] T ∈ C 1 , ϕ ( x 2 ) = [ 1 1 1 1 1 ] T ∈ C 1 , ϕ ( x 3 ) = [ 1 0 1 0 0 ] T ∈ C 2 , ϕ ( x 4 ) = [ 0 1 0 1 0 ] T ∈ C 2 . \phi \left( x_1 \right) =\left[ \begin{matrix} 0& 0& 0& 0& 0\\ \end{matrix} \right] ^{\mathrm{T}}\in C_1, \phi \left( x_2 \right) =\left[ \begin{matrix} 1& 1& 1& 1& 1\\ \end{matrix} \right] ^{\mathrm{T}}\in C_1, \\ \phi \left( x_3 \right) =\left[ \begin{matrix} 1& 0& 1& 0& 0\\ \end{matrix} \right] ^{\mathrm{T}}\in C_2, \phi \left( x_4 \right) =\left[ \begin{matrix} 0& 1& 0& 1& 0\\ \end{matrix} \right] ^{\mathrm{T}}\in C_2. ϕ(x1)=[00000]T∈C1,ϕ(x2)=[11111]T∈C1,ϕ(x3)=[10100]T∈C2,ϕ(x4)=[01010]T∈C2.取
w = [ − 1 − 1 − 1 − 1 6 ] T ( 不 唯 一 ) \boldsymbol{w}=\left[ \begin{matrix} -1& -1& -1& -1& 6\\ \end{matrix} \right] ^{\mathrm{T}} (不唯一) w=[−1−1−1−16]T(不唯一)有
{ w T ϕ ( x 1 ) + b = 1 w T ϕ ( x 2 ) + b = 3 } ∈ C 1 w T ϕ ( x 3 ) + b = − 1 w T ϕ ( x 4 ) + b = − 1 } ∈ C 2 \begin{cases} \left. \begin{array}{r} \boldsymbol{w}^{\mathrm{T}}\phi \left( \boldsymbol{x}_1 \right) +b=1\\ \boldsymbol{w}^{\mathrm{T}}\phi \left( \boldsymbol{x}_2 \right) +b=3\\ \end{array} \right\} \in C_1\\ \left. \begin{array}{r} \boldsymbol{w}^{\mathrm{T}}\phi \left( \boldsymbol{x}_3 \right) +b=-1\\ \boldsymbol{w}^{\mathrm{T}}\phi \left( \boldsymbol{x}_4 \right) +b=-1\\ \end{array} \right\} \in C_2\\ \end{cases} ⎩⎪⎪⎨⎪⎪⎧wTϕ(x1)+b=1wTϕ(x2)+b=3}∈C1wTϕ(x3)+b=−1wTϕ(x4)+b=−1}∈C2
那么 ϕ ( x ) \phi(\boldsymbol{x}) ϕ(x)应如何选取?关于 ϕ ( x ) \phi(\boldsymbol{x}) ϕ(x),有以下事实:
① 我们认为选定的 ϕ ( x ) \phi(\boldsymbol{x}) ϕ(x)是无限维的.
② 我们可以不知道无限维映射 ϕ ( x ) \phi(\boldsymbol{x}) ϕ(x)的显式表达,而只需知道一个核函数(kernel function)
κ ( x 1 , x 2 ) = ϕ ( x 1 ) T ϕ ( x 2 ) = < ϕ ( x 1 ) , ϕ ( x 2 ) > \kappa(\boldsymbol{x}_1,\boldsymbol{x}_2)=\phi(\boldsymbol{x}_1)^{\mathrm{T}}\phi(\boldsymbol{x}_2)=\left< \phi \left( \boldsymbol{x}_1 \right) ,\phi \left( \boldsymbol{x}_2 \right) \right> κ(x1,x2)=ϕ(x1)Tϕ(x2)=⟨ϕ(x1),ϕ(x2)⟩则该优化问题仍然可解.
2. 常用核函数

注:
1.多项式核的幂次 d d d越高,其对应的 ϕ \phi ϕ维数也越高. 且多项式核可反解出 ϕ \phi ϕ.
2. 参数选择:不断尝试.
3. κ ( x 1 , x 2 ) \kappa(\boldsymbol{x}_1,\boldsymbol{x}_2) κ(x1,x2) 能写成 ϕ ( x 1 ) T ϕ ( x 2 ) \phi(\boldsymbol{x}_1)^{\mathrm{T}}\phi(\boldsymbol{x}_2) ϕ(x1)Tϕ(x2)的充要条件:Merce’s Theorem
(1)交换性
κ ( x 1 , x 2 ) = κ ( x 2 , x 1 ) \kappa \left( \boldsymbol{x}_1,\boldsymbol{x}_2 \right) =\kappa \left( \boldsymbol{x}_2,\boldsymbol{x}_1 \right) κ(x1,x2)=κ(x2,x1)
(2)半正定性
∀ c i , x i ( i = 1 , 2 , ⋯ , N ) , 有 ∑ i = 1 N ∑ i = 1 N c i c j κ ( x i , x j ) ⩾ 0 \forall c_i, \boldsymbol{x}_i\left( i=1,2,\cdots ,N \right) , \text{有}\sum_{i=1}^N{\sum_{i=1}^N{c_ic_j\kappa \left( \boldsymbol{x}_i,\boldsymbol{x}_j \right) \geqslant 0}} ∀ci,xi(i=1,2,⋯,N),有i=1∑Ni=1∑Ncicjκ(xi,xj)⩾0
注:以上两条也可写作: κ \kappa κ是核函数,当且仅当对任意数据 D = { x 1 , x 2 , ⋯ , x m } D=\left\{ \boldsymbol{x}_1,\boldsymbol{x}_2,\cdots ,\boldsymbol{x}_m \right\} D={x1,x2,⋯,xm},“核矩阵” K \mathbf{K} K总是半正定的. 其中

附:半正定性表达式的推导
半正定即
∀ C = [ c 1 ⋮ c n ] ≠ 0 , C 1 × n T K n × n C n × 1 ⩾ 0 ⇔ ( K n × n C n × 1 ) i = ∑ j = 1 n c j κ ( i , j ) C 1 × n T K n × n C n × 1 = c 1 ∑ j = 1 n c j κ ( 1 , j ) + ⋯ + c n ∑ j = 1 n c j κ ( n , j ) = ∑ i = 1 n ∑ j = 1 n c i c j κ ( i , j ) \forall C=\left[ \begin{array}{c} c_1\\ \vdots\\ c_n\\ \end{array} \right] \ne 0, C_{1\times n}^{\mathrm{T}}\mathbf{K}_{n\times n}C_{n\times 1}\geqslant 0\Leftrightarrow \\ \left( \mathbf{K}_{n\times n}C_{n\times 1} \right) _i=\sum_{j=1}^n{c_j\kappa \left( i,j \right)} \\ C_{1\times n}^{\mathrm{T}}\mathbf{K}_{n\times n}C_{n\times 1}=c_1\sum_{j=1}^n{c_j\kappa \left( 1,j \right)}+\cdots +c_n\sum_{j=1}^n{c_j\kappa \left( n,j \right)} \\ =\sum_{i=1}^n{\sum_{j=1}^n{c_ic_j\kappa \left( i,j \right)}} ∀C=⎣⎢⎡c1⋮cn⎦⎥⎤=0,C1×nTKn×nCn×1⩾0⇔(Kn×nCn×1)i=j=1∑ncjκ(i,j)C1×nTKn×nCn×1=c1j=1∑ncjκ(1,j)+⋯+cnj=1∑ncjκ(n,j)=i=1∑nj=1∑ncicjκ(i,j)
4. 核函数的选取
P128 “核函数选择”成为支持向量机的最大变数. 这方面有一些基本的经验,例如对文本数据通常采用线性核,情况不明时可先尝试高斯核.
核函数还可通过函数组合得到,详见西瓜书P128.
那么,如何用核函数 κ ( x i , x j ) \kappa(\boldsymbol{x}_i,\boldsymbol{x}_j) κ(xi,xj)来替换目标函数中的 ϕ ( x i ) \phi(\boldsymbol{x}_i) ϕ(xi),使得优化问题可解?
(三)【补充】优化理论相关知识——原问题和对偶问题
优化理论相关书籍:① Convex Optimization;② Nonlinear Programming
1. 原问题(Primal Problem)
min f ( w ) s . t . { g i ( w ) ⩽ 0 ( i = 1 , ⋯ , K ) h i ( w ) = 0 ( i = 1 , ⋯ , M ) \begin{aligned} &\min f\left( \boldsymbol{w} \right) \\ &\mathrm{s}.\mathrm{t}. \left\{ \begin{array}{c} g_i\left( \boldsymbol{w} \right) \leqslant 0\left( i=1,\cdots ,K \right)\\ h_i\left( \boldsymbol{w} \right) =0\left( i=1,\cdots ,M \right)\\ \end{array} \right. \end{aligned} minf(w)s.t.{gi(w)⩽0(i=1,⋯,K)hi(w)=0(i=1,⋯,M)
2. 对偶问题(Dual Problem)
定义 L ( w , α , β ) = f ( w ) + ∑ i = 1 K α i g i ( w ) + ∑ i = 1 M β i h i ( w ) = f ( w ) + α T g ( w ) + β T h ( w ) \begin{aligned} L\left( \boldsymbol{w},\boldsymbol{\alpha },\boldsymbol{\beta } \right) &=f\left( \boldsymbol{w} \right) +\sum_{i=1}^K{\alpha _ig_i\left( \boldsymbol{w} \right)}+\sum_{i=1}^M{\beta _ih_i\left( \boldsymbol{w} \right)} \\ &=f\left( \boldsymbol{w} \right) +\boldsymbol{\alpha }^{\mathrm{T}}g\left( \boldsymbol{w} \right) +\boldsymbol{\beta }^{\mathrm{T}}h\left( \boldsymbol{w} \right) \end{aligned} L(w,α,β)=f(w)+i=1∑Kαigi(w)+i=1∑Mβihi(w)=f(w)+αTg(w)+βTh(w)
原问题的对偶问题为
max Θ ( α , β ) = i n f 所有 w ( L ( w , α , β ) ) s . t . α i ⩾ 0 ( i = 1 , ⋯ , K ) ( 或写作 α ≽ 0 ) \begin{aligned} &\max \Theta \left( \boldsymbol{\alpha },\boldsymbol{\beta } \right) =\underset{\text{所有}\boldsymbol{w}}{\mathrm{inf}}\left( L\left( \boldsymbol{w},\boldsymbol{\alpha },\boldsymbol{\beta } \right) \right) \\ & \mathrm{s}.\mathrm{t}. \ \alpha _i\geqslant 0\left( i=1,\cdots ,K \right) \left( \text{或写作}\boldsymbol{\alpha }\succcurlyeq 0 \right) \end{aligned} maxΘ(α,β)=所有winf(L(w,α,β))s.t. αi⩾0(i=1,⋯,K)(或写作α≽0)
3. 原问题和对偶问题的关系
定理:如果 w ∗ \boldsymbol{w}^* w∗是原问题的解, α ∗ \boldsymbol{\alpha}^* α∗, β ∗ \boldsymbol{\beta}^* β∗是对偶问题的解,则有 f ( w ∗ ) ⩾ Θ ( α ∗ , β ∗ ) . f\left( \boldsymbol{w}^* \right) \geqslant \Theta \left( \boldsymbol{\alpha }^*,\boldsymbol{\beta }^* \right) . f(w∗)⩾Θ(α∗,β∗).
证明:
Θ ( α ∗ , β ∗ ) = i n f ( L ( w , α ∗ , β ∗ ) ) ⩽ L ( w ∗ , α ∗ , β ∗ ) = f ( w ∗ ) + ∑ i = 1 K α i ∗ g i ( w ∗ ) + ∑ i = 1 M β i ∗ h i ( w ∗ ) ⩽ f ( w ∗ ) ( 注意到 α i ∗ ⩾ 0 , g i ( w ∗ ) ⩽ 0 , h i ( w ∗ ) = 0 ) \begin{aligned} \Theta \left( \boldsymbol{\alpha }^*,\boldsymbol{\beta }^* \right) &=\mathrm{inf}\left( L\left( \boldsymbol{w},\boldsymbol{\alpha }^*,\boldsymbol{\beta }^* \right) \right) \\ &\leqslant L\left( \boldsymbol{w}^*,\boldsymbol{\alpha }^*,\boldsymbol{\beta }^* \right) \\ &=f\left( \boldsymbol{w}^* \right) +\sum_{i=1}^K{\alpha _{i}^{*}g_i\left( \boldsymbol{w}^* \right)}+\sum_{i=1}^M{\beta _{i}^{*}h_i\left( \boldsymbol{w}^* \right)} \\ &\leqslant f\left( \boldsymbol{w}^* \right) \left( \text{注意到}\alpha _{i}^{*}\geqslant 0,g_i\left( \boldsymbol{w}^* \right) \leqslant 0,h_i\left( \boldsymbol{w}^* \right) =0 \right) \end{aligned} Θ(α∗,β∗)=inf(L(w,α∗,β∗))⩽L(w∗,α∗,β∗)=f(w∗)+i=1∑Kαi∗gi(w∗)+i=1∑Mβi∗hi(w∗)⩽f(w∗)(注意到αi∗⩾0,gi(w∗)⩽0,hi(w∗)=0)
4. 定义:原问题与对偶问题的间距(duality gap)s
G = f ( w ∗ ) − Θ ( α ∗ , β ∗ ) ⩾ 0 G=f\left( \boldsymbol{w}^* \right) -\Theta \left( \boldsymbol{\alpha }^*,\boldsymbol{\beta }^* \right) \geqslant 0 G=f(w∗)−Θ(α∗,β∗)⩾0, G G G叫作原问题与对偶问题的间距(duality gap). 对于某些特定的优化问题,可以证明 G = 0 G=0 G=0.
5. 强对偶定理
若 f ( w ) f(\boldsymbol{w}) f(w)是凸函数,且 g ( w ) = A w + b g(\boldsymbol{w})=A\boldsymbol{w}+b g(w)=Aw+b, h ( w ) = C w + d h(\boldsymbol{w})=C\boldsymbol{w}+d h(w)=Cw+d,则此优化问题的原问题与对偶问题的间距 G = 0 G=0 G=0,即
f ( w ∗ ) = Θ ( α ∗ , β ∗ ) . f\left( \boldsymbol{w}^* \right) =\Theta \left( \boldsymbol{\alpha }^*,\boldsymbol{\beta }^* \right) . f(w∗)=Θ(α∗,β∗).
f ( w ∗ ) = Θ ( α ∗ , β ∗ ) f\left( \boldsymbol{w}^* \right) =\Theta \left( \boldsymbol{\alpha }^*,\boldsymbol{\beta }^* \right) f(w∗)=Θ(α∗,β∗)蕴含:
① 原问题的解 w ∗ \boldsymbol{w}^* w∗是 α ∗ \boldsymbol{\alpha}^* α∗和 β ∗ \boldsymbol{\beta}^* β∗一定时,使得 L ( w , α ∗ , β ∗ ) L\left( \boldsymbol{w},\boldsymbol{\alpha }^*,\boldsymbol{\beta }^* \right) L(w,α∗,β∗)最小的那个 w \boldsymbol{w} w.
② KKT条件:对于 ∀ i = 1 , 2 , ⋯ , K \forall i=1,2,\cdots,K ∀i=1,2,⋯,K,或者 α i ∗ = 0 \alpha _{i}^{*}=0 αi∗=0,或者 g i ( w ∗ ) = 0 g_{i}\left( \boldsymbol{w}^* \right) =0 gi(w∗)=0.
(四)将支持向量机原问题转化为对偶问题
1. 问题的转换
原问题:
min 1 2 ∥ w ∥ 2 + C ∑ i = 1 N ξ i ( 容 易 知 道 , 这 是 一 个 凸 函 数 ) s . t . { y i ( w T ϕ ( x ) + b ) ⩾ 1 − ξ i ξ i ⩾ 0 \begin{aligned} &\min \frac{1}{2}\left\| \boldsymbol{w} \right\| ^2+C\sum_{i=1}^N{\xi _i}(容易知道,这是一个凸函数) \\ &\mathrm{s}.\mathrm{t}. \begin{cases} y_i\left( \boldsymbol{w}^{\mathrm{T}}\phi \left( \boldsymbol{x} \right) +b \right) \geqslant 1-\xi _i\\ \xi _i\geqslant 0\\ \end{cases} \end{aligned} min21∥w∥2+Ci=1∑Nξi(容易知道,这是一个凸函数)s.t.{yi(wTϕ(x)+b)⩾1−ξiξi⩾0
原问题的标准型:
min 1 2 ∥ w ∥ 2 − C ∑ i = 1 N ξ i s . t . { 1 + ξ i − y i ( w T ϕ ( x ) + b ) ⩽ 0 ξ i ⩽ 0 \begin{aligned} &\min \frac{1}{2}\left\| \boldsymbol{w} \right\| ^2-C\sum_{i=1}^N{\xi _i} \\ &\mathrm{s}.\mathrm{t}. \begin{cases} 1+\xi _i-y_i\left( \boldsymbol{w}^{\mathrm{T}}\phi \left( \boldsymbol{x} \right) +b \right) \leqslant 0\\ \xi _i\leqslant 0\\ \end{cases} \end{aligned} min21∥w∥2−Ci=1∑Nξis.t.{1+ξi−yi(wTϕ(x)+b)⩽0ξi⩽0
凸函数定义:
∀ w 1 , w 2 , ∀ λ ∈ [ 0 , 1 ] , f ( λ w 1 + ( 1 − λ ) w 2 ) ⩽ λ f ( w 1 ) + ( 1 − λ ) f ( w 2 ) \forall \boldsymbol{w}_1,\boldsymbol{w}_2, \forall \lambda \in \left[ 0,1 \right] , f\left( \lambda \boldsymbol{w}_1+\left( 1-\lambda \right) \boldsymbol{w}_2 \right) \leqslant \lambda f\left( \boldsymbol{w}_1 \right) +\left( 1-\lambda \right) f\left( \boldsymbol{w}_2 \right) ∀w1,w2,∀λ∈[0,1],f(λw1+(1−λ)w2)⩽λf(w1)+(1−λ)f(w2)
对偶问题:
max Θ ( α , β ) = i n f ( 1 2 ∥ w ∥ 2 − C ∑ i = 1 N ξ i + ∑ i = 1 N β i ξ i + ∑ i = 1 N α i ( 1 + ξ i − y i w T ϕ ( x i ) − y i b ) ) s . t . { α i ⩾ 0 β i ⩾ 0 ( i = 1 , 2 , ⋯ , N ) \begin{aligned} &\max \Theta \left( \boldsymbol{\alpha },\boldsymbol{\beta } \right) ={\mathrm{inf}}\left( \frac{1}{2}\left\| \boldsymbol{w} \right\| ^2-C\sum_{i=1}^N{\xi _i}+\sum_{i=1}^N{\beta _i\xi _i}+\sum_{i=1}^N{\alpha _i\left( 1+\xi _i-y_i\boldsymbol{w}^{\mathrm{T}}\phi \left( \boldsymbol{x}_i \right) -y_ib \right)} \right) \\ &\mathrm{s}.\mathrm{t}. \left\{ \begin{array}{c} \alpha _i\geqslant 0\\ \beta _i\geqslant 0\\ \end{array}\left( i=1,2,\cdots ,N \right) \right. \end{aligned} maxΘ(α,β)=inf(21∥w∥2−Ci=1∑Nξi+i=1∑Nβiξi+i=1∑Nαi(1+ξi−yiwTϕ(xi)−yib))s.t.{αi⩾0βi⩾0(i=1,2,⋯,N)
附:矩阵求导法则
① w = [ w 1 ⋮ w n ] , 则 ∂ f ∂ w = [ ∂ f ∂ w 1 ⋮ ∂ f ∂ w n ] . ② f ( w ) = 1 2 ∥ w ∥ 2 = 1 2 ∑ i = 1 n w i 2 , 则 ∂ f ∂ w = [ ∂ f ∂ w 1 ⋮ ∂ f ∂ w n ] = [ w 1 ⋮ w n ] = w ③ f ( w ) = w T x = ∑ i = 1 n w i x i , 则 ∂ f ∂ w = [ x 1 ⋮ x n ] = x \begin{aligned} &① \boldsymbol{w}=\left[ \begin{array}{c} w_1\\ \vdots\\ w_n\\ \end{array} \right] , \text{则}\frac{\partial f}{\partial \boldsymbol{w}}=\left[ \begin{array}{c} \frac{\partial f}{\partial w_1}\\ \vdots\\ \frac{\partial f}{\partial w_n}\\ \end{array} \right] . \\ &② f\left( \boldsymbol{w} \right) =\frac{1}{2}\left\| \boldsymbol{w} \right\| ^2=\frac{1}{2}\sum_{i=1}^n{w_{i}^{2}}, \text{则}\frac{\partial f}{\partial \boldsymbol{w}}=\left[ \begin{array}{c} \frac{\partial f}{\partial w_1}\\ \vdots\\ \frac{\partial f}{\partial w_n}\\ \end{array} \right] =\left[ \begin{array}{c} w_1\\ \vdots\\ w_n\\ \end{array} \right] =\boldsymbol{w} \\ &③ f\left( \boldsymbol{w} \right) =\boldsymbol{w}^{\mathrm{T}}\boldsymbol{x}=\sum_{i=1}^n{w_ix_i}, \text{则}\frac{\partial f}{\partial \boldsymbol{w}}=\left[ \begin{array}{c} x_1\\ \vdots\\ x_n\\ \end{array} \right] =\boldsymbol{x} \end{aligned} ①w=⎣⎢⎡w1⋮wn⎦⎥⎤,则∂w∂f=⎣⎢⎡∂w1∂f⋮∂wn∂f⎦⎥⎤.②f(w)=21∥w∥2=21i=1∑nwi2,则∂w∂f=⎣⎢⎡∂w1∂f⋮∂wn∂f⎦⎥⎤=⎣⎢⎡w1⋮wn⎦⎥⎤=w③f(w)=wTx=i=1∑nwixi,则∂w∂f=⎣⎢⎡x1⋮xn⎦⎥⎤=x
利用 Lagrange \text{Lagrange} Lagrange乘子法,先求得 1 2 ∥ w ∥ 2 − C ∑ i = 1 N ξ i + ∑ i = 1 N β i ξ i + ∑ i = 1 N α i ( 1 + ξ i − y i w T ϕ ( x i ) − y i b ) \frac{1}{2}\left\| \boldsymbol{w} \right\| ^2-C\sum_{i=1}^N{\xi _i}+\sum_{i=1}^N{\beta _i\xi _i}+\sum_{i=1}^N{\alpha _i\left( 1+\xi _i-y_i\boldsymbol{w}^{\mathrm{T}}\phi \left( \boldsymbol{x}_i \right) -y_ib \right)} 21∥w∥2−C∑i=1Nξi+∑i=1Nβiξi+∑i=1Nαi(1+ξi−yiwTϕ(xi)−yib)取得最小值时各参数应满足的条件.
{ ∂ L ∂ w = 0 ⇒ w = ∑ i = 1 N α i y i ϕ ( x i ) ∂ L ∂ ξ i = 0 ⇒ α i + β i = C ∂ L ∂ b = 0 ⇒ ∑ i = 1 N α i y i = 0 \begin{cases} \frac{\partial L}{\partial \boldsymbol{w}}=0\Rightarrow \boldsymbol{w}=\sum_{i=1}^N{\alpha _iy_i\phi \left( \boldsymbol{x}_i \right)}\\ \frac{\partial L}{\partial \xi _i}=0\Rightarrow \alpha _i+\beta _i=C\\ \frac{\partial L}{\partial b}=0\Rightarrow \sum_{i=1}^N{\alpha _iy_i=0}\\ \end{cases} ⎩⎪⎨⎪⎧∂w∂L=0⇒w=∑i=1Nαiyiϕ(xi)∂ξi∂L=0⇒αi+βi=C∂b∂L=0⇒∑i=1Nαiyi=0然后将上述三个条件代入 Θ ( α , β ) \Theta \left( \boldsymbol{\alpha },\boldsymbol{\beta } \right) Θ(α,β).
具体推导步骤如下
Θ ( α , β ) = 1 2 ∥ w ∥ 2 − C ∑ i = 1 N ξ i + ∑ i = 1 N β i ξ i + ∑ i = 1 N α i ( 1 + ξ i − y i w T ϕ ( x i ) − y i b ) = α i + β i = C 1 2 ∥ w ∥ 2 + ∑ i = 1 N α i ( 1 − y i w T ϕ ( x i ) − y i b ) = ∑ i = 1 N α i y i = 0 1 2 ∥ w ∥ 2 + ∑ i = 1 N α i − ∑ i = 1 N α i y i w T ϕ ( x i ) = w = ∑ i = 1 N α i y i ϕ ( x i ) 1 2 ( ∑ i = 1 N α i y i ϕ ( x i ) ) T ( ∑ j = 1 N α j y j ϕ ( x j ) ) + ∑ i = 1 N α i − ∑ i = 1 N α i y i w T ϕ ( x i ) = ( ∑ i = 1 N α i y i ϕ ( x i ) ) T = ∑ i = 1 N α i y i ϕ ( x i ) T 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ϕ ( x i ) T ϕ ( x j ) + ∑ i = 1 N α i − ∑ i = 1 N α i y i w T ϕ ( x i ) = κ ( x i , x j ) = ϕ ( x i ) T ϕ ( x j ) 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j κ ( x i , x j ) + ∑ i = 1 N α i − ∑ i = 1 N α i y i w T ϕ ( x i ) = w = ∑ i = 1 N α i y i ϕ ( x i ) 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j κ ( x i , x j ) + ∑ i = 1 N α i − ∑ i = 1 N α i y i ( ∑ j = 1 N α j y j ϕ ( x j ) ) T ϕ ( x i ) = 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j κ ( x i , x j ) + ∑ i = 1 N α i − ∑ i = 1 N ∑ j = 1 N α i α j y i y j ϕ ( x j ) T ϕ ( x i ) = κ ( x i , x j ) = κ ( x j , x i ) = ϕ ( x j ) T ϕ ( x i ) 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j κ ( x i , x j ) + ∑ i = 1 N α i − ∑ i = 1 N ∑ j = 1 N α i α j y i y j κ ( x i , x j ) = ∑ i = 1 N α i − 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j κ ( x i , x j ) \begin{aligned} &\Theta \left( \boldsymbol{\alpha },\boldsymbol{\beta } \right) =\frac{1}{2}\left\| \boldsymbol{w} \right\| ^2-C\sum_{i=1}^N{\xi _i}+\sum_{i=1}^N{\beta _i\xi _i}+\sum_{i=1}^N{\alpha _i\left( 1+\xi _i-y_i\boldsymbol{w}^{\mathrm{T}}\phi \left( \boldsymbol{x}_i \right) -y_ib \right)} \\ &\xlongequal{\alpha _i+\beta _i=C}\frac{1}{2}\left\| \boldsymbol{w} \right\| ^2+\sum_{i=1}^N{\alpha _i\left( 1-y_i\boldsymbol{w}^{\mathrm{T}}\phi \left( \boldsymbol{x}_i \right) -y_ib \right)} \\ &\xlongequal{\sum_{i=1}^N{\alpha _iy_i=0}}\frac{1}{2}\left\| \boldsymbol{w} \right\| ^2+\sum_{i=1}^N{\alpha _i}-\sum_{i=1}^N{\alpha _iy_i\boldsymbol{w}^{\mathrm{T}}\phi \left( \boldsymbol{x}_i \right)} \\ &\xlongequal{\boldsymbol{w}=\sum_{i=1}^N{\alpha _iy_i\phi \left( \boldsymbol{x}_i \right)}}\frac{1}{2}\left( \sum_{i=1}^N{\alpha _iy_i\phi \left( \boldsymbol{x}_i \right)} \right) ^{\mathrm{T}}\left( \sum_{j=1}^N{\alpha _jy_j\phi \left( \boldsymbol{x}_j \right)} \right) +\sum_{i=1}^N{\alpha _i}-\sum_{i=1}^N{\alpha _iy_i\boldsymbol{w}^{\mathrm{T}}\phi \left( \boldsymbol{x}_i \right)} \\ &\xlongequal{\left( \sum_{i=1}^N{\alpha _iy_i\phi \left( \boldsymbol{x}_i \right)} \right) ^{\mathrm{T}}=\sum_{i=1}^N{\alpha _iy_i\phi \left( \boldsymbol{x}_i \right) ^{\mathrm{T}}}}\frac{1}{2}\sum_{i=1}^N{\sum_{j=1}^N{\alpha _i\alpha _jy_iy_j\phi \left( \boldsymbol{x}_i \right) ^{\mathrm{T}}\phi \left( \boldsymbol{x}_j \right)}}+\sum_{i=1}^N{\alpha _i}-\sum_{i=1}^N{\alpha _iy_i\boldsymbol{w}^{\mathrm{T}}\phi \left( \boldsymbol{x}_i \right)} \\ &\xlongequal{\kappa \left( \boldsymbol{x}_i,\boldsymbol{x}_j \right) =\phi \left( \boldsymbol{x}_i \right) ^{\mathrm{T}}\phi \left( \boldsymbol{x}_j \right)}\frac{1}{2}\sum_{i=1}^N{\sum_{j=1}^N{\alpha _i\alpha _jy_iy_j\kappa \left( \boldsymbol{x}_i,\boldsymbol{x}_j \right)}}+\sum_{i=1}^N{\alpha _i}-\sum_{i=1}^N{\alpha _iy_i\boldsymbol{w}^{\mathrm{T}}\phi \left( \boldsymbol{x}_i \right)} \\ &\xlongequal{\boldsymbol{w}=\sum_{i=1}^N{\alpha _iy_i\phi \left( \boldsymbol{x}_i \right)}}\frac{1}{2}\sum_{i=1}^N{\sum_{j=1}^N{\alpha _i\alpha _jy_iy_j\kappa \left( \boldsymbol{x}_i,\boldsymbol{x}_j \right)}}+\sum_{i=1}^N{\alpha _i}-\sum_{i=1}^N{\alpha _iy_i\left( \sum_{j=1}^N{\alpha _jy_j\phi \left( \boldsymbol{x}_j \right)} \right) ^{\mathrm{T}}\phi \left( \boldsymbol{x}_i \right)} \\ &=\frac{1}{2}\sum_{i=1}^N{\sum_{j=1}^N{\alpha _i\alpha _jy_iy_j\kappa \left( \boldsymbol{x}_i,\boldsymbol{x}_j \right)}}+\sum_{i=1}^N{\alpha _i}-\sum_{i=1}^N{\sum_{j=1}^N{\alpha _i\alpha _jy_iy_j\phi \left( \boldsymbol{x}_j \right) ^{\mathrm{T}}}\phi \left( \boldsymbol{x}_i \right)} \\ &\xlongequal{\kappa \left( \boldsymbol{x}_i,\boldsymbol{x}_j \right) =\kappa \left( \boldsymbol{x}_j,\boldsymbol{x}_i \right) =\phi \left( \boldsymbol{x}_j \right) ^{\mathrm{T}}\phi \left( \boldsymbol{x}_i \right)}\frac{1}{2}\sum_{i=1}^N{\sum_{j=1}^N{\alpha _i\alpha _jy_iy_j\kappa \left( \boldsymbol{x}_i,\boldsymbol{x}_j \right)}}+\sum_{i=1}^N{\alpha _i}-\sum_{i=1}^N{\sum_{j=1}^N{\alpha _i\alpha _jy_iy_j\kappa \left( \boldsymbol{x}_i,\boldsymbol{x}_j \right)}} \\ &=\sum_{i=1}^N{\alpha _i}-\frac{1}{2}\sum_{i=1}^N{\sum_{j=1}^N{\alpha _i\alpha _jy_iy_j\kappa \left( \boldsymbol{x}_i,\boldsymbol{x}_j \right)}} \end{aligned} Θ(α,β)=21∥w∥2−Ci=1∑Nξi+i=1∑Nβiξi+i=1∑Nαi(1+ξi−yiwTϕ(xi)−yib)αi+βi=C21∥w∥2+i=1∑Nαi(1−yiwTϕ(xi)−yib)∑i=1Nαiyi=021∥w∥2+i=1∑Nαi−i=1∑NαiyiwTϕ(xi)w=∑i=1Nαiyiϕ(xi)21(i=1∑Nαiyiϕ(xi))T(j=1∑Nαjyjϕ(xj))+i=1∑Nαi−i=1∑NαiyiwTϕ(xi)(∑i=1Nαiyiϕ(xi))T=∑i=1Nαiyiϕ(xi)T21i=1∑Nj=1∑Nαiαjyiyjϕ(xi)Tϕ(xj)+i=1∑Nαi−i=1∑NαiyiwTϕ(xi)κ(xi,xj)=ϕ(xi)Tϕ(xj)21i=1∑Nj=1∑Nαiαjyiyjκ(xi,xj)+i=1∑Nαi−i=1∑NαiyiwTϕ(xi)w=∑i=1Nαiyiϕ(xi)21i=1∑Nj=1∑Nαiαjyiyjκ(xi,xj)+i=1∑Nαi−i=1∑Nαiyi(j=1∑Nαjyjϕ(xj))Tϕ(xi)=21i=1∑Nj=1∑Nαiαjyiyjκ(xi,xj)+i=1∑Nαi−i=1∑Nj=1∑Nαiαjyiyjϕ(xj)Tϕ(xi)κ(xi,xj)=κ(xj,xi)=ϕ(xj)Tϕ(xi)21i=1∑Nj=1∑Nαiαjyiyjκ(xi,xj)+i=1∑Nαi−i=1∑Nj=1∑Nαiαjyiyjκ(xi,xj)=i=1∑Nαi−21i=1∑Nj=1∑Nαiαjyiyjκ(xi,xj)
问题转化为
max Θ ( α ) = ∑ i = 1 N α i − 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j κ ( x i , x j ) s . t . { 0 ⩽ α i ⩽ C ( 由 α i + β i = C ∧ α i ⩾ 0 ∧ β i ⩾ 0 ) ∑ i = 1 N α i y i = 0 \begin{aligned} &\max \Theta \left( \boldsymbol{\alpha }\right) =\sum_{i=1}^N{\alpha _i}-\frac{1}{2}\sum_{i=1}^N{\sum_{j=1}^N{\alpha _i\alpha _jy_iy_j\kappa \left( \boldsymbol{x}_i,\boldsymbol{x}_j \right)}} \\ &\mathrm{s}.\mathrm{t}.\begin{cases} 0\leqslant \alpha _i\leqslant C\left( \text{由}\alpha _i+\beta _i=C\land \alpha _i\geqslant 0\land \beta _i\geqslant 0 \right)\\ \sum_{i=1}^N{\alpha _iy_i=0}\\ \end{cases} \end{aligned} maxΘ(α)=i=1∑Nαi−21i=1∑Nj=1∑Nαiαjyiyjκ(xi,xj)s.t.{0⩽αi⩽C(由αi+βi=C∧αi⩾0∧βi⩾0)∑i=1Nαiyi=0
可使用SMO(Sequential Minimal Optimization)算法求解.
附:SMO的基本思路(西瓜书P124)
至此,我们求得了 α \boldsymbol{\alpha} α.



在最开始的问题中,我们需要求得 w \boldsymbol{w} w和 b b b. 但事实上,我们并不需要求得 w \boldsymbol{w} w,具体说明如下:
2. w \boldsymbol{w} w如何求解?
先看以下的训练集测试流程.
输入测试样本 x \boldsymbol{x} x:
{ i f w T ϕ ( x ) + b ⩾ 0 : y = + 1 i f w T ϕ ( x ) + b < 0 : y = − 1 \left\{ \begin{array}{c} \mathrm{if} \ \boldsymbol{w}^{\mathrm{T}}\phi \left( \boldsymbol{x} \right) +b\geqslant 0: y=+1\\ \mathrm{if} \ \boldsymbol{w}^{\mathrm{T}}\phi \left( \boldsymbol{x} \right) +b<0: y=-1\\ \end{array} \right. {if wTϕ(x)+b⩾0:y=+1if wTϕ(x)+b<0:y=−1
注意到
w T ϕ ( x ) + b = ( ∑ i = 1 N α i y i ϕ ( x i ) ) T ϕ ( x ) + b = ∑ i = 1 N α i y i κ ( x i , x j ) + b \boldsymbol{w}^{\mathrm{T}}\phi \left( \boldsymbol{x} \right) +b=\left( \sum_{i=1}^N{\alpha _iy_i\phi \left( \boldsymbol{x}_i \right)} \right) ^{\mathrm{T}}\phi \left( \boldsymbol{x} \right) +b=\sum_{i=1}^N{\alpha _iy_i\kappa \left( \boldsymbol{x}_i,\boldsymbol{x}_j \right)}+b wTϕ(x)+b=(i=1∑Nαiyiϕ(xi))Tϕ(x)+b=i=1∑Nαiyiκ(xi,xj)+b
因此无需知道 w \boldsymbol{w} w和 ϕ \phi ϕ的显式表达式,即可完成训练样本的分类.
3. b b b 如何求解?
根据KKT条件
{ 要么 β i = 0 , 要么 ξ i = 0 要么 α i = 0 , 要么 1 + ξ i − y i w T ϕ ( x i ) − y i b = 0 \begin{cases} \text{要么}\beta _i=0, \text{要么}\xi _i=0\\ \text{要么}\alpha _i=0, \text{要么}1+\xi _i-y_i\boldsymbol{w}^{\mathrm{T}}\phi \left( \boldsymbol{x}_i \right) -y_ib=0\\ \end{cases} {要么βi=0,要么ξi=0要么αi=0,要么1+ξi−yiwTϕ(xi)−yib=0故有
β i = C − α i > 0 ⇒ β i ≠ 0 ⇒ ξ i = 0 \beta _i=C-\alpha _i>0\Rightarrow \beta _i\ne 0\Rightarrow \xi _i=0 βi=C−αi>0⇒βi=0⇒ξi=0又 α i ≠ 0 \alpha _i\ne 0 αi=0,有
1 + ξ i − y i w T ϕ ( x i ) − y i b = 0 ⇒ b = 1 − y i w T ϕ ( x i ) y i = 1 − y i ∑ j = 1 N α j y j κ ( x i , x j ) y i \begin{aligned} 1+\xi _i-y_i\boldsymbol{w}^{\mathrm{T}}\phi \left( \boldsymbol{x}_i \right) -y_ib&=0 \\ \Rightarrow b=\frac{1-y_i\boldsymbol{w}^{\mathrm{T}}\phi \left( \boldsymbol{x}_i \right)}{y_i}&=\frac{1-y_i\sum_{j=1}^N{\alpha _jy_j\kappa \left( \boldsymbol{x}_i,\boldsymbol{x}_j \right)}}{y_i} \end{aligned} 1+ξi−yiwTϕ(xi)−yib⇒b=yi1−yiwTϕ(xi)=0=yi1−yi∑j=1Nαjyjκ(xi,xj)可以使用所有支持向量求解 b b b的平均值.
至此,完成了 SVM \text{SVM} SVM非线性模型的求解.
(五) SVM \text{SVM} SVM的非线性模型总结
1. 训练流程
S t e p 1 : Step 1: Step1:输入 ( x i , y i ) ( i = 1 , 2 , ⋯ , N ) \left( \boldsymbol{x}_i,y_i \right) \left( i=1,2,\cdots ,N \right) (xi,yi)(i=1,2,⋯,N).
S t e p 2 : Step 2: Step2:解优化问题.
max Θ ( α ) = ∑ i = 1 N α i − 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j κ ( x i , x j ) s . t . { 0 ⩽ α i ⩽ C ( 由 α i + β i = C ∧ α i ⩾ 0 ∧ β i ⩾ 0 ) ∑ i = 1 N α i y i = 0 \begin{aligned} &\max \Theta \left( \boldsymbol{\alpha }\right) =\sum_{i=1}^N{\alpha _i}-\frac{1}{2}\sum_{i=1}^N{\sum_{j=1}^N{\alpha _i\alpha _jy_iy_j\kappa \left( \boldsymbol{x}_i,\boldsymbol{x}_j \right)}} \\ &\mathrm{s}.\mathrm{t}.\begin{cases} 0\leqslant \alpha _i\leqslant C\left( \text{由}\alpha _i+\beta _i=C\land \alpha _i\geqslant 0\land \beta _i\geqslant 0 \right)\\ \sum_{i=1}^N{\alpha _iy_i=0}\\ \end{cases} \end{aligned} maxΘ(α)=i=1∑Nαi−21i=1∑Nj=1∑Nαiαjyiyjκ(xi,xj)s.t.{0⩽αi⩽C(由αi+βi=C∧αi⩾0∧βi⩾0)∑i=1Nαiyi=0
S t e p 3 : Step 3: Step3:计算 b b b.
找一个 0 < α i < C 0<\alpha _i
b = 1 − y i ∑ j = 1 N α j y j κ ( x i , x j ) y i b=\frac{1-y_i\sum_{j=1}^N{\alpha _jy_j\kappa \left( \boldsymbol{x}_i,\boldsymbol{x}_j \right)}}{y_i} b=yi1−yi∑j=1Nαjyjκ(xi,xj)
2. 测试流程
输入测试样本 x \boldsymbol{x} x:
{ i f ∑ i = 1 N α i y i κ ( x i , x ) + b ⩾ 0 : y = + 1 i f ∑ i = 1 N α i y i κ ( x i , x ) + b < 0 : y = − 1 \left\{ \begin{array}{l} \mathrm{if} \sum_{i=1}^N{\alpha _iy_i\kappa \left( \boldsymbol{x}_i,\boldsymbol{x} \right)}+b\geqslant 0:y=+1\\ \mathrm{if} \sum_{i=1}^N{\alpha _iy_i\kappa \left( \boldsymbol{x}_i,\boldsymbol{x} \right)}+b<0:y=-1\\ \end{array} \right. {if∑i=1Nαiy