分布式编程工具Akka Streams、Kafka Streams和Spark Streaming大PK
众所周知,作为一个事件流平台,Kafka能够松散地驻留在面向消息的中间件(Message-oriented Middleware,MoM)空间里。而被称为Actor模型的Akka,是一个基于响应、容错和消息传递的同步计算过程。

下面,我将和您讨论分布式编程工具Akka Streams、Kafka Streams和Spark Streaming的主要特点、优缺点、以及如何在一个简单的字数统计应用中使用它们。文中,我主要使用Scala来编写代码,所涉及到的框架都带有Java API。
一、Kafka Streams
Kafka Steams是一个可以处理数据的客户端库(client library)。此处的客户端库是指,我们所编写的应用程序使用了另一个基础设施(在本例中是Kafka集群)所提供的服务。因此,我们需要与一个集群进行交互,以处理持续的数据流。而数据则需要被表示为键值记录的形式,以易于识别,并被组织成主题形式的持久性事件日志。它们本质上是被复制和写入磁盘的持久数据队列。在该架构中,生产者(producer)应用程序将记录推送到主题中(例如电商需要跟踪订单的每一步);而多个消费者(consumer)应用程序需要以各种方式,读取主题中不同时间点的数据。
此类数据结构的架构不但具有高度分布式和可扩展性的特点,而且具有一定的容错性。由于嵌入了exact-once消息语义,Kafka可以确保发来的每一条记录,都能够到达集群,并且仅写入一次,没有重复。正是由于在一般的分布式系统中极难实现,因此Kafka的该特性非常重要。
从Kafka的组织方式来看,其API允许Java或Scala应用程序,在与Kafka集群进行交互的同时,与其他应用程序并行、独立地使用。这种独立性能够满足在大型应用程序中,分布式且可扩展的服务去独立地使用微服务。
Kafka Steams的表现形式
Scala
1
object WordCountApplication extends App {
2
import Serdes._
3
val props: Properties = {
4
val p = new Properties()
5
p.put(StreamsConfig.APPLICATION_ID_CONFIG, "myFabulousWordCount")
6
p.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "my-kafka-broker-url:9092")
7
p
8
}
9
10
val builder: StreamsBuilder = new StreamsBuilder
11
val textLines: KStream[String, String] =
12
builder.stream[String, String]("TextLinesTopic")
13
val wordCounts: KTable[String, Long] = textLines
14
.flatMapValues(textLine => textLine.toLowerCase.split("\\W+"))
15
.groupBy((_, word)=> word)
16
.count()(Materialized.as("word-counts-table"))
17
18
wordCounts.toStream.to("WordsWithCountsTopic")
19
val streams: KafkaStreams = new KafkaStreams(builder.build(), props)
20
streams.start()
21
22
sys.ShutdownHookThread {
23
streams.close(10, TimeUnit.SECONDS)
24
}
25
}
上述代码便是单词计数应用的Kafka Steams表现形式。显然,这段代码相对较“重”,我试着对其进行分解。
Scala 1 import Serdes._
Kafka针对性能进行了二进制式的记录存储,也就是我们常说的序列化和反序列化。通过上述语句,我们可以在Scala中实现序列化和反序列化(并行转换器)的自动导入。
Scala
1
val props: Properties = {
2
val p = new Properties()
3.
p.put(StreamsConfig.APPLICATION_ID_CONFIG, "myFabulousWordCount")
4
p.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "my-kafka-broker-url:9092")
5
p
6
}
上述应用代码的第一部分需要配置待连接的Kafka集群的细节。下面是我用Scala写的API。
Scala
1
val builder: StreamsBuilder = new StreamsBuilder
2
val textLines: KStream[String, String] =
3.
builder.stream[String, String]("TextLinesTopic")
接下来,我会使用一个构建器模式(builder pattern),从需要的主题中读取记录的键值对。
Scala
1
val wordCounts: KTable[String, Long] = textLines
2
.flatMapValues(textLine => textLine.toLowerCase.split("\\W+"))
3.
.groupBy((_, word)=> word)
4
.count()(Materialized.as("word-counts-table"))
然后,我们将操作流中一些功能性操作符集中到一张表里。基于Kafka的stream-table二元性,我们可以对Kafka Steams进行数据表级别的聚合和处理互转。
Scala 1 wordCounts.toStream.to("WordsWithCountsTopic")
在转换过程中,我们需要将该数据表转换为数据流,以向其他应用程序提供可能感兴趣的主题。
Scala
1
val streams: KafkaStreams = new KafkaStreams(builder.build(), props)
2
streams.start()
3.
4
sys.ShutdownHookThread {
5
streams.close(10, TimeUnit.SECONDS)
6
}
最后,我们需要设置数据流的起停,否则静态流是不会主动做任何事的。
Kafka Steams的优点和缺点
Kafka Steams的主要优点是:Kafka集群会给您提供高速、高容错性和高可扩展性。同时,Kafka也提供exactly-once的消息发送语义。这对于分布式系统来说意义重大,毕竟许多框架无法提供此类保证,进而会出现数据的重复或丢失。同时,Kafka鼓励使用相同消息总线实现微服务的通信,以便用户有权控制并通过Kafka建立自己的微服务内(inter-microservice)通信协议。
当然,Kafka并非没有缺点。
- 首先,Kafka强制使用Java风格的API,会给Scala程序员带来不适。
- 其次,如果您想在自己的体系结构中使用Kafka,那么就需要设置一个单独的Kafka集群来用于管理(即使您不一定需要分配专用的主机)。
- 同时,鉴于Kafka的高度可配置性,您需要提前知晓如何配置。
- 最后,Kafka只支持producer-consumer架构类型。
二、Akka Streams
Akka Streams是一种由Scala写的,为JVM构建的高性能代码库。它实施了Reactive Streams规范(Reactive Manifesto)--响应性、弹性、容错和消息驱动的语义。通过它,您完全可以以无限的数据量和100%控制流的拓扑配置,来处理个人记录。Akka Streams提供Actor模型的并发性,其流式组件构建在异步独立组件之上。
Akka Streams的主要优势在于高度可扩展性和容错性。它提供了一个多功能和简洁的流API,即Scala-based DSL。您可以简单地通过“插入”组件来启动它们。同时,Akka Streams还提供了一个低级别的GraphStage API,以便您可以控制个人特定组件的逻辑。
如上文所述,在Kafka中,您的应用程序通过使用消息总线,成为了Kafka集群的客户端API。而Akka Streams是应用程序在逻辑上不可分割的一部分。您可以将Akka Streams想象为应用程序的循环系统,而Kafka只是外部组织“造血库”罢了。
Akka Streams的表现形式
Scala
1
val source1 = Source(List("Akka", "is", "awesome"))
2
val source2 = Source(List("learning", "Akka", "Streams"))
3
val sink = Sink.foreach[(String, Int)](println)
4
5
val graph = GraphDSL.create(){ implicit builder =>
6
import GraphDSL.Implicits._
7
•
8
val wordCounter = Flow[String]
9
.fold[Map[String, Int]](Map()){(map, record)=>
10
map +(record ->(map.getOrElse(record, 0)+ 1))
11
}
12
.flatMapConcat(m => Source(m.toList))
13
14
val merge = builder.add(Merge[String](2))
15
val counter = builder.add(wordCounter)
16
17
source1 ~> merge ~> counter ~> sink
18
source2 ~> merge
19
•
20
ClosedShape
21
}
22
23
RunnableGraph.fromGraph(graph).run()
上述代码是单词计数应用程序的Akka Streams表现形式。该Scala看起来比较简洁,让我们来分解其代码的主要部分:
Scala 1 val source1 = Source(List("Akka", "is", "awesome")) 2 val source2 = Source(List("learning", "Akka", "Streams")) 3 val sink = Sink.foreach[(String, Int)](println)
前3行代码构建了最初的数据来源,并发送异步元素(在本例中为字符串)。
Scala
1
val wordCounter = Flow[String]
2
.fold[Map[String, Int]](Map()){(map, record)=>
3
map +(record ->(map.getOrElse(record, 0)+ 1))
4
}
5
.flatMapConcat(m => Source(m.toList))
上述代码是计算字数的主要部分,它旨在产生在一个简单的字符串列表。
Scala 1 val merge = builder.add(Merge[String](2)) 2 val counter = builder.add(wordCounter) 3 4 source1 ~> merge ~> counter ~> sink 5 source2 ~> merge
上述代码实现的是Akka Streams将自己的逻辑,运用到不同的流组。下面展示了它的流式逻辑图。
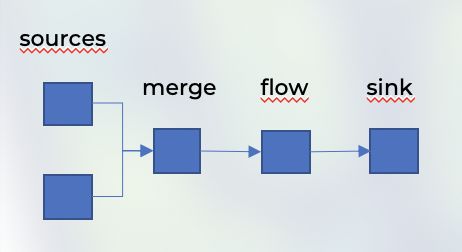
Stream工作流
下面,我们来查看这段代码:
Scala 1 source1 ~> merge ~> counter ~> sink 2 source2 ~> merge
注意,上述代码中有个非常相似的表示流拓扑的结构。我们只用2行代码便轻松地构造出了任意流式布局,而且它们是完全异步、高速且容错的。
Akka Streams的优点和缺点
由于Akka Streams是一个Reactive Streams的实现,因此其API提供了极快的速度和高度可扩展性。同时,Akka Streams提供了低级别的GraphStage API,使您能够控制自定义流的逻辑,例如:批处理数据、手动中断、以及重定向数据流等,真可谓一切皆有可能。此外,Akka Streams也可以无缝地连接到带有 Alpakka Kafka连接器 的Kafka上。 Akka Streams是作为应用程序的开发库被构建的,因此您不必像Kafka那样去编写客户端API,而只需像任何其他库那样,用它去构建分布式应用程序即可。
Akka Streams的缺点在于它类似流式C++,学习曲线比较陡峭。同时,如果您使用集群的整个套件的话,会发现Akka Streams的扩展并不容易。事实上,正是因为Akka Streams成为了应用程序不可分割的一部分,因此您需要像任何“构建”库那样,去采取特定的思维方式。
三、Spark Streaming
作为大规模Spark分布式计算引擎的自然流扩展,Spark Streaming的目的是处理持续大规模的数据。目前,您有两个API级别可供选择:一个是带有离散流(Discretized Streams,DStreams)的低级别高可控API,另一个是常见的DataFrame API。它也被称为结构化流,针对常规“静态”大数据,提供了一个相似的API。Spark通过原生的可扩展性和容错性,提供了两种输出模式和功能:
- micro-batch模式,Spark能够间隔、批量地收集所有数据。
- continuous模式,目前还处于实验阶段的较低延迟方式。
Spark的主要优势体现在大数据的处理能力上。由它提供的DataFrame、SQL API、以及丰富的Spark UI,都能够方便您监视和跟踪负载的实时性能。
值得注意的是,由于Spark需要一个专门的计算集群,因此它在生产环境中比较耗费资源。当然,Spark具有可配置性,如果您知道如何正确地调整它的话,可以在其性能上改进不少。
Spark Streaming的表现形式
Scala
1
val spark = SparkSession.builder()
2
.appName("Word count")
3.
.master("local[*]")
4
.getOrCreate()
5
6
•val streamingDF = spark.readStream
7
.format("kafka")
8
.option("kafka.bootstrap.servers", "your-kafka-broker:9092")
9
.option("subscribe", "myTopic")
10
.load()
11
12
•val wordCount = streamingDF
13
.selectExpr("cast(value as string)as word")
14
.groupBy("word")
15
.count()
16
17
•wordCount.writeStream
18
.format("console")
19
.outputMode("append")
20.
.start()
21
.awaitTermination()
上述代码便是单词计数应用的Spark Streaming表现形式。在此,我们使用了高级别的结构化流式(Structured Streaming)API,使得代码既整洁又分离。下面,我们来进一步分析:
Scala
1
val spark = SparkSession.builder()
2
.appName("Word count")
3
.master("local[*]")
4
.getOrCreate()
上述代码只需要您启用一个样板—Spark Session。
Scala
1
val streamingDF = spark.readStream
2
.format("kafka")
3
.option("kafka.bootstrap.servers", "your-kafka-broker:9092")
4
.option("subscribe", "myTopic")
5
.load()
由上述代码可知,您可以通过指定数据源来读取数据。同时,Spark Streaming也能够原生地以开箱即用的方式支持Kafka。
Scala
1
val wordCount = streamingDF
2
.selectExpr("cast(value as string)as word")
3
.groupBy("word")
4
.count()
上述代码的逻辑也比较简单,在SQL中我们只需运用“group by”来计数。而由于Kafka是以二进制来存储数据的,因此我们必须添加如下头部。
Scala
1
wordCount.writeStream
2
.format("console")
3.
.outputMode("append")
4
.start()
5
.awaitTermination()
最后,您只需要将数据流指向输出sink(在此我们又用到了Kafka),便可以开始查询数据流了。
Spark Streaming的优点和缺点
Spark具有基于事件时间和水印的数据后期处理能力。这在真实场景下非常实用。同时,高度可配置的Spark,可以通过其内置的连接器,作为数据的输入或输出,连接到Kafka处,来实现性能调优。当然,Spark也拥有优秀的文档和广泛的社区支持。此外,Spark还能够针对较小的数据处理,在本地进行加速。
与其他框架一样,Spark也并不完美。除了通用的DataFrame和SQL API之外,它在编译时,会丧失一部分类型的安全性。而在您将Dataset导入lambdas后,其性能也会有所下降。如前所示,Spark Streaming在大数据和micro-batch处理方面表现不错,但是其continuous模式有待改进。最后,由于Spark需要运行一个专门的集群,因此它也会分走一部分的算力。
四、该如何选用
可见,上述讨论的每一种框架都是针对某些特定的需求而构建的。那么,我们该如何进行选用呢?
- Akka Streams最适合高性能的系统。它提供了一个非常强大的API,不过您需要花时间去掌握它。
- 由于Kafka最适合作为外部高性能应用的消息总线,因此如果您想让微服务可以从公共事件处进行读写的话,最好使用Kafka。当然,其Java风格的API可能过于繁琐,不利于代码的整洁。
- Spark Streaming毫无疑问是为大数据计算而生。不过,有记录表明,它对于实际的应用逻辑和低延迟需求并不友好。您可以仅把Spark Streaming作为数据聚合器(data aggregator),来获取数据的洞见。
译者介绍
陈峻 (Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验;持续以博文、专题和译文等形式,分享前沿技术与新知;经常以线上、线下等方式,开展信息安全类培训与授课。
原文标题:Comparing Akka Streams, Kafka Streams and Spark Streaming,作者:Daniel Ciocirlan