SQL 查询引擎的未来图景
关于 SQL 查询引擎的未来,全球的数据和分析服务提供商都在进行积极的探索和实践,今天我们转载了数据分析师 Lori Lu 发表在 Medium.com 的博客,文章将探讨 SQL 查询引擎在大数据分析中的现状与未来,希望对大家有所启发。
2021年9月,马特·图尔克(Matt Turck)发表长文《前沿战报:2021年机器学习、人工智能和数据(MAD)发展图景》(Red Hot: The 2021 Machine Learning, AI and Data (MAD) Landscape),为我们绘制了 MAD 生态系统在 2021 年的宏观视图。
第一次看到马特文中异常丰富的生态系统地图时,我立刻感受到了 CIO 们在进行技术选型时的痛苦,以及数据产品公司销售们在激烈的市场竞争中的挣扎。然而,这仅仅是大数据生态系统创新之路的开始。随着数据仓库和湖仓一体开始触及全球各个组织和机构,毫无疑问,这一图景会变得更拥挤。

2021 年机器学习、人工智能和数据(MAD)发展图景(部分厂商)
根据多年来对榜单上的各个顶级玩家的分析和追踪,我发现其实每个供应商都有其独特的价值和市场契合点,包括 Databricks, Firebolt, ClickHouse 等在内的一些初创公司最近也热度很高...... Kyligence 则致力于打造下一代企业级智能多维数据库,帮助企业简化数据湖上的多维数据分析。总之,这一领域的开拓者们正在不断打破数据分析领域的现状,致力于为客户创造更多的价值。
这一现象的背后是?
我的答案听起来可能有些消极 —— 一家供应商的解决方案往往很难满足来自各行业的、多样化的分析需求,以及不断变化的客户场景,比如实时分析、OLTP、OLAP 以及各种混合分析场景等。
问题不止于此
当今市场,各个供应商都专注于为特定的买家群体定制化解决特定场景下的挑战,并据此形成自己独特的竞争力。也因此,任何一家如果想要取代其他所有的竞争对手,就必须自研一款适用于所有场景的通用大数据分析引擎,但这几乎是不可能。因此,这也是为什么我们说:世界上不存在一款 All-in-One 万能大数据分析引擎!
所以企业也只能针对不同的分析场景来采购不同的查询引擎。无论是为了避免供应商锁定,还是为了填补主流云厂商不愿意涉猎的行业空白,在未来,这一趋势都将继续下去。最终,每家公司都需要采购不止一款数据分析产品,也因此需要在不同系统中保存数据,而这无疑将造成一种新型的数据孤岛。
数据孤岛?
这当然不是各大企业想要的。随着各行业数字化转型的加速,企业在重建现代化数据分析架构的同时,绝不想绕回曾经的老路,也就是再去打造一座座的数据孤岛。
那该如何摆脱这一窘境?
为避免新的数据孤岛的出现,我们应重新构想并设计新一代的 SQL 查询引擎,这个查询引擎应能提供位于去中心化的查询引擎/数据源之上统一的查询入口:
-
对于终端数据消费者而言,这一中间层为他们创建了一个单一的入口,使他们能够透明地访问数据孤岛;
-
对于技术供应商而言,他们可以最大限度地发挥自己的优势,专注于解决已明确定义的问题;
-
对于买家/需求方而言,他们可以充分利用所有供应商的专长,而无需担心集成工作。
-
最重要的是,这一中间层应该能为客户创造更多的价值:它能提供超强的性能,并兼具可扩展性和低成本等特点。
我们坚信未来的 SQL 查询引擎应具备如下特点:在去中心化的数据源之上提供一个统一查询入口,并支持以成本最优的方式实现对数据的高并发、低延迟、实时访问。
Kyligence 查询引擎的设计正是基于这些考量,接下来我将简单介绍 Kyligence 查询引擎设计的底层逻辑。

新一代 SQL 查询引擎是经过重新设计,在去中心化的数据源之上兼具超强性能和可扩展性。
性能与成本
首先,我相信性能和成本是很多客户在选型时会考虑的重要因素。Kyligence 的智能多维数据库产品及解决方案使用云原生、分布式等技术,通过空间换时间的方式支持高性能的 OLAP 计算,并能适应任何形态的数据湖,以一种成本最优的方式为上层分析应用提供高性能的查询能力。
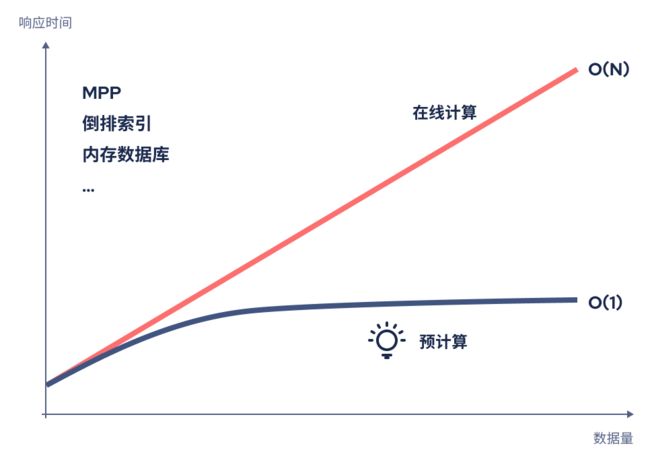
数据的指数增长将不再影响成本和查询性能
多维数据库的主要优点包括:
-
可实现性能提升和支持高并发查询:对查询结果进行预处理(也就是说,大量计算在离线任务过程中已经完成),随时可以为下游数据消费者提供服务。因此,在查询运行时,计算能力主要用于检索查询结果并将其回传给消费者。所以 Kyligence 引擎能在不牺牲性能的前提下更好地应对大量并发查询。
-
有助于降低成本—— 预计算的查询结果,也就是索引,将尽可能被复用,并支持分段或分区刷新。从长远来看,多维数据库将为客户带来大量的成本节省。
去中心化数据源之上的统一查询入口

现代化的分析型数据库位于数据 APP(或消费者)和去中心化数据源之间,可作为统一查询入口。作为一个中间层,它支持用户轻松连接不同数据源,无需再去关心每个数据源的连接方式。
Kyligence 支持多种数据源,包括 HDFS、Hive、RDBMS 及其他云存储。这与联邦查询的概念有所不同。
举个例子,比如在某些场景中,客户可在 Kyligence 平台中为每个数据源单独创建一个项目;这样,不同事业部的终端用户就可以通过各自的 BI 工具直接访问构建在不同数据源之上的数据模型。Kyligence 还为 DevOps 团队提供了一个统一的平台来实现数据访问控制。
此外,Kyligence AI 增强引擎可以检测常见的查询特征和模式并自动构建索引,以提高查询性能,避免因为反复地处理相同的查询而浪费算力。借助 AI 增强引擎,Kyligence 针对 PB 级数据集实现了亚秒级的标准 SQL 查询响应,大大改善数据分析的体验,助力业务用户快速发现海量数据中的业务价值,驱动商业决策。
除此之外,Kyligence 还将为客户实现如下价值:
价值点 1|湖仓一体时代的数据治理

多维模型可以被想象成一个整齐的宽表集合,Kyligence 的多维模型可以很好地解决重复查询带来的成本增长和宽表爆炸的问题,从而降低整体拥有成本(TCO)。
使用 Kyligence 的智能多维分析平台的另一个好处是,它可以帮助您管理、消除和复用 ETL 管道。为方便理解,我们将向您介绍 Kyligence 多维数据库的使用背景。
您可以将 Kyligence OLAP 模型看作一组平表,即 Kyligence 中的索引。接下来,我将通过一个简单的场景来说明它的工作原理。
2021 年,Kyligence 的一个客户遇到了平表数量激增的问题,原因在于每个团队习惯使用由自己开发的表,表的复用情况不太理想。采用 Kyligence 作为其数据管理工具后,所有团队都开始在 Kyligence 平台内协作并创建共享数据模型。Kyligence 多维数据模型将会自动为所有团队生成"平表",并智能管理"平表"的复用和生命周期,Kyligence 帮助客户将平表的数量从上千万张减少到一个较合理的水平。
价值点 2|契合 Data Mesh 数据网格最佳实践
如果您了解 Data Mesh 的概念,您可能会发现 Kyligence 与 Data Mesh 中所要求的"数据基础设施作为中心化共享服务平台"理念高度契合:
-
Kyligence 受治理的数据集市契合了 Data Mesh 中数据域的概念;
-
Kyligence 基于去中心化的数据源之上的统一查询入口契合了 Data Mesh 中数据所有权和架构的去中心化;
......
在过往合作的企业中,不少客户习惯按照各领域划分的项目和模型,并据此进行数据管理。这些企业会将 Kyligence 平台作为企业的共享数据基础设施,提供给所有成员使用。
本文转自 Medium.com,原文链接为:https://medium.com/@LoriLu/the-future-of-sql-query-engine-8d6a2535154b
关于 Kyligence
![]()
上海跬智信息技术有限公司 (Kyligence) 由 Apache Kylin 创始团队于 2016 年创办,致力于打造下一代企业级智能多维数据库,为企业简化数据湖上的多维数据分析(OLAP)。通过 AI 增强的高性能分析引擎、统一 SQL 服务接口、业务语义层等功能,Kyligence 提供成本最优的多维数据分析能力,支撑企业商务智能(BI)分析、灵活查询和互联网级数据服务等多类应用场景,助力企业构建更可靠的指标体系,释放业务自助分析潜力。
Kyligence 已服务中国、美国、欧洲及亚太的多个银行、证券、保险、制造、零售等行业客户,包括建设银行、浦发银行、招商银行、平安银行、宁波银行、太平洋保险、中国银联、上汽、Costa、UBS、MetLife 等全球知名企业,并和微软、亚马逊、华为、Tableau 等技术领导者达成全球合作伙伴关系。目前公司已经在上海、北京、深圳、厦门、武汉及美国的硅谷、纽约、西雅图等开设分公司或办事机构。