SpringBoot学习小结之Redis
文章目录
- 前言
- 一、SpringBoot使用Redis
-
- 1.1 pom依赖
- 1.2 两种连接方案
- 1.3 配置
- 1.4 简单使用
- 二、各种场景
-
- 2.1 缓存数据
- 2.2 分布式锁
-
- 2.2.1 通过setnx来实现分布式锁
- 2.2.2 lua脚本
- 2.3 全局ID
- 2.4 限流
-
- 2.4.1 `incr`
- 2.4.2 `zset`滑动窗口
- 2.4.3 漏斗算法
- 2.5 位统计
-
- 2.5.1 实现统计DAU
- 2.5.2 计算出7天都在线的用户
- 2.6 消息队列
-
- 2.6.1 List实现
- 2.6.2 Stream实现
- 2.6.3 订阅发布实现
- 2.7 即时聊天
- 2.8 附近的人
- 2.9 关注和推荐
- 2.10 排行榜
- 2.11 抽奖
- 三、Redis源码分析
-
- 3.1 简单动态字符串 *sds*
-
- 3.1.1 结构
- 3.1.2 sds长度(sdslen)
- 3.2 跳跃表*skiplist*
-
- 3.2.1 结构
- 3.2.2 和平衡树比较
- 3.3 压缩列表*ziplist*
- 参考
前言
Redis是一个持久化在磁盘上的内存数据库,支持多种数据类型
Redis和Mencashed对比
| Redis | Mencashed | |
|---|---|---|
| 创建时间 | 由Salvatore Sanfilippo于2009年创建 | 由BradFitzpatrick于2003年开发 |
| 数据类型 | 支持多种不同的数据类型:字符串,散列,列表,集合,有序集,bitmap,hyperLogLog和geo | 只支持字符串 |
| 持久化 | 支持两种持久化策略:RDB快照和AOF日志 | 不支持 |
| 线程 | 单线程 | 多线程 |
| 数据存储 | 并不是所有数据都一直在内存中,可以将很久没用的value交换到磁盘 | 所有数据都一直在内存中 |
| 高可用 | 主从复制+哨兵 | 不支持 |
| 淘汰策略 | LRU,LFU等多种 | LRU |
总而言之,Redis提供了非常丰富的功能,而且性能基本上与Memcached相差无几,这也是它最近这几年占领内存数据库鳌头的原因。
在技术选型方面,如果你的业务需要各种数据结构给予支撑,同时要求数据的高可用保障,那么选择Redis是比较合适的,但是如果你的业务非常简单,只是简单的set/get,并且对于内存使用并不高,那么使用Memcached足够了。
一、SpringBoot使用Redis
1.1 pom依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-pool2artifactId>
dependency>
1.2 两种连接方案
springboot2.0后默认使用lettuce,可选jedis。
letture和jedis区别
-
Jedis 是直连模式,每个线程都去拿自己的 Jedis 实例,当连接数量增多时,连接成本就较高了。
-
Lettuce的连接是基于Netty的,连接实例可以在多个线程间共享,通过异步的方式可以让我们更好地利用系统资源。
官方提供的两者差别:
| Supported Feature | Lettuce | Jedis |
|---|---|---|
| Standalone Connections | X | X |
| Master/Replica Connections | X | |
| Redis Sentinel | Master Lookup, Sentinel Authentication, Replica Reads | Master Lookup |
| Redis Cluster | Cluster Connections, Cluster Node Connections, Replica Reads | Cluster Connections, Cluster Node Connections |
| Transport Channels | TCP, OS-native TCP (epoll, kqueue), Unix Domain Sockets | TCP |
| Connection Pooling | X (using commons-pool2) |
X (using commons-pool2) |
| Other Connection Features | Singleton-connection sharing for non-blocking commands | JedisShardInfo support |
| SSL Support | X | X |
| Pub/Sub | X | X |
| Pipelining | X | X |
| Transactions | X | X |
| Datatype support | Key, String, List, Set, Sorted Set, Hash, Server, Stream, Scripting, Geo, HyperLogLog | Key, String, List, Set, Sorted Set, Hash, Server, Scripting, Geo, HyperLogLog |
| Reactive (non-blocking) API | X |
X表示支持,可以看到Letture支持更多的特性,所以一般选择Letture
1.3 配置
application.yaml配置
spring:
redis:
host: localhost
password:
port: 6379
ssl: false
lettuce:
pool:
max-active: 8
max-idle: 8
min-idle: 0
max-wait: 1000ms
shutdown-timeout: 100ms
更细粒度配置
@Configuration
public class RedisConfig {
/**
* RedisTemplate配置
*/
@Bean
public RedisTemplate<String, Object> redisTemplate(LettuceConnectionFactory lettuceConnectionFactory) {
// 设置序列化
Jackson2JsonRedisSerializer<Object> jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<Object>(
Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
jackson2JsonRedisSerializer.setObjectMapper(om);
// 配置redisTemplate
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<String, Object>();
redisTemplate.setConnectionFactory(lettuceConnectionFactory);
RedisSerializer<?> stringSerializer = new StringRedisSerializer();
// key序列化
redisTemplate.setKeySerializer(stringSerializer);
// value序列化
redisTemplate.setValueSerializer(new JdkSerializationRedisSerializer());
// Hash key序列化
redisTemplate.setHashKeySerializer(stringSerializer);
// Hash value序列化
redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
}
1.4 简单使用
private static final Logger logger = LoggerFactory.getLogger(DemoRedisApplicationTests.class);
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Test
void stringTest() {
stringRedisTemplate.opsForValue().set("test1", "test2");
String test = stringRedisTemplate.opsForValue().get("test1");
logger.info("test1:{}", test);
stringRedisTemplate.delete("test1");
String testDel = stringRedisTemplate.opsForValue().get("test1");
logger.info("after Delete, test1:{}", testDel);
}
@Test
void objectTest() {
User user = new User();
user.setId(1);
user.setUsername("张三");
redisTemplate.opsForValue().set("user1", user);
User user1 = (User)redisTemplate.opsForValue().get("user1");
logger.info("user:{}", user1);
}
public class User implements Serializable {
private Integer id;
private String username;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", username='" + username + '\'' +
'}';
}
}
二、各种场景
redis有多个不同数据类型,命令有两百多个,下面可以根据不同场景来使用不同的数据结构和命令
在线练习网站
2.1 缓存数据
-
这也是最常见的使用场景,可以使用
set命令(大小写不敏感)来存储字符串SET key value [EX seconds] [PX milliseconds] [NX|XX]可以通过EX或PX来设置过期时间
-
通过
get命令获取数据GET key -
通过
del删除keyDEL key [key …]
2.2 分布式锁
2.2.1 通过setnx来实现分布式锁
setnx只在键 key 不存在的情况下, 将键 key 的值设置为 value 。若键 key 已经存在, 则 SETNX 命令不做任何动作
SETNX key value
分布式锁会面临超时问题,而setnx不可以设置过期时间。其实可以通过set命令的 [nx]来实现过期时间
SET key value ex 30 nx
2.2.2 lua脚本
spring自带分布式锁功能,位于spring-integration包内。从源码可以发现,分布式锁有jdbc,redis,zookeeper等实现,redis实现正是通过lua脚本,这个脚本位于org.springframework.integration.redis.util.RedisLockRegistry这个类里
2.3 全局ID
- 可以通过
INCR key和INCRBY key increment来实现,它们俩是给key指定的value自增1或指定值。redis单线程,天生原子性,不用担心重复
2.4 限流
2.4.1 incr
以ip为key, incr访问次数,到了限制次数,就不让访问. 还可以通过expire设置时间,实现固定时间限制访问次数
EXPIRE key seconds
2.4.2 zset滑动窗口
1. 限流需求中存在一个滑动的时间窗口,而zset的score值可以用来圈定时间窗口,窗口之外的数据都可以删除
2、zset的value需要是一个唯一的值,只需要保证唯一性即可
3、如果按照某个接口单位时间允许访问次数,那么key可以用接口路径,如果是限制单个用户那么key可以结合userId
ZADD key score member [[score member] [score member] …]
ZINCRBY key increment member
ZSCORE key member
2.4.3 漏斗算法
Redis 4.0 提供了一个限流 Redis 模块redis-cell,提供一个cl.throttle指令来实现限流,使用的是漏斗算法
具体使用可以查看文档:https://github.com/brandur/redis-cell
CL.THROTTLE user123 15 30 60 1
▲ ▲ ▲ ▲ ▲
| | | | └───── apply 1 token (default if omitted)
| | └──┴─────── 30 tokens / 60 seconds
| └───────────── 15 max_burst
└─────────────────── key "user123"
如何使用模块:http://www.redis.cn/topics/modules-intro.html
2.5 位统计
2.5.1 实现统计DAU
通过SETBIT key offset value给key所指的字符串所在offset位设置value(0或1)。offset >= 0 && offset<2^32
然后通过BITCOUNT key [start] [end]获取所有的1
#设置key 第1位 值为1
setbit dau_0101 1 1
#设置key 第99位 值为1
setbit dau_0101 99 1
# 统计这一天01-01所有的1
bitcount dau_0501
2.5.2 计算出7天都在线的用户
可通过bittop
BITOP operation destkey key [key …]
计算7天内bit都为1的用户
BITOP "AND" "7_days_both_online_users" dau_0101" "dau_0102" "dau_0103" "dau_0104" "dau_0105" "dau_0106" "dau_0107"
2.6 消息队列
2.6.1 List实现
List是简单的字符串列表,按照插入顺序排序,可以用来实现简单的消息队列
常见的用法有LPUSH、RPOP 左进右出,RPUSH、LPOP 右进左出
LPUSH key value [value …]
RPOP key
RPUSH key value [value …]
LPOP key
阻塞问题,可通过设置超时时间解决
BRPOP key [key …] timeout
BLPOP key [key …] timeout
2.6.2 Stream实现
Stream是Redis 5.0版本引入的一个新的数据类型
可以通过xadd添加消息,xread读取消息
XADD key ID field string [field string ...]
XRANGE key start end [COUNT count]
XDEL key ID [ID ...]
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...]
xadd mystream * f1 v1 f2 v2 f3 v3 # 返回1656058155355-0
xadd mystream 1656058155355-1 f4 v4 #id必须比之前大
xrange mystream - + #-最小 +最大
xread count 2 streams mystream 0
# 以阻塞方式获取,block 0代表无限等待
xread block 0 streams mystream $
2.6.3 订阅发布实现
通过subscribe命令订阅频道,publish命令将消息发布到指定频道实现消息发送和接收
SUBSCRIBE channel [channel …]
PUBLISH channel message
2.7 即时聊天
可通过上述的消息队列来实现
2.8 附近的人
可通过添加经纬度命令geoadd, 将一个或多个经度(longitude)、纬度(latitude)、位置名称(member)添加到指定的 key 中
GEOADD key longitude latitude member [longitude latitude member …]
georadius 以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。georadiusbymember 和 georadius 命令一样, 都可以找出位于指定范围内的元素, 但是 georadiusbymember 的中心点是由给定的位置元素决定的, 而不是使用经度和纬度来决定中心点。
GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [ASC|DESC] [COUNT count]
GEORADIUSBYMEMBER key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]
- m :米,默认单位。
- km :千米。
- mi :英里。
- ft :英尺。
- WITHDIST: 在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。
- WITHCOORD: 将位置元素的经度和纬度也一并返回。
- WITHHASH: 以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。 这个选项主要用于底层应用或者调试, 实际中的作用并不大。
- COUNT 限定返回的记录数。
- ASC: 查找结果根据距离从近到远排序。
- DESC: 查找结果根据从远到近排序。
geoadd china:city 121.472644 31.231706 shanghai
geoadd china:city 120.619585 31.299379 suzhou
geoadd china:city 116.405285 39.904989 beijing
// 上海黄浦区周围30km,返回上海
georadius china:city 121.49295 31.22337 30 km
// 周围300km 包含上海和苏州
georadius china:city 121.49295 31.22337 300 km
2.9 关注和推荐
sadd 将一个或多个 member 元素加入到集合 key 当中,已经存在于集合的 member 元素将被忽略
srem 移除集合 key 中的一个或多个 member 元素
sinter 返回一个集合的全部成员,该集合是所有给定集合的交集
sdiff 返回一个集合的全部成员,该集合是所有给定集合之间的差集
SADD key member [member …]
SREM key member [member …]
SINTER key [key …]
SDIFF key [key …]
follow:userid 关注 fans:userid 粉丝
-
添加关注
# 1、将对方id添加到自己的关注列表中 SADD follow:1 2 # 2、将自己的id添加到对方的粉丝列表中 SADD fans:2 1 -
取消关注
SREM follow:1 2 SREM fans:2 1 -
关注/粉丝列表
SMEMBERS follow:1 SMEMBERS fans:1 -
共同关注
SINTER folow:1 follow:2 -
可能认识的人
# 用户2是用户1粉丝,用户2关注set减去用户1关注set SDIFF follow:2 follow:1
2.10 排行榜
zincrby ,为有序集 key 的成员 member 的 score 值加上增量 increment
zrevrange,返回有序集 key 中,指定区间内的成员。其中成员的位置按 score 值递减(从大到小)来排列。 具有相同 score 值的成员按字典序的逆序排序
ZINCRBY key increment member
ZREVRANGE key start stop [WITHSCORES]
2.11 抽奖
可通过spop 移除并返回集合中的一个随机元素, 如果不想移除可以使用srandmember
SPOP key
SRANDMEMBER key [count]
三、Redis源码分析
由于各个版本源码可能会不同,下述源码分析选择版本为6.2
3.1 简单动态字符串 sds
源码位于 https://github.com/redis/redis/blob/6.2/src/sds.c
3.1.1 结构
SDS(Simple Dynamic String), 有两个版本,在Redis 3.2之前使用的是第一个版本,其数据结构如下所示:
typedef char *sds;
struct sdshdr {
unsigned int len; //buf中已经使用的长度
unsigned int free; //buf中未使用的长度
char buf[]; //柔性数组buf
};
v3.2开始使用第二个版本,针对字符串长度,动态选择不同结构体。__attribute__ ((__packed__)) 是gcc语法,告诉编译器取消字节对齐,压缩内存空间
typedef char *sds;
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length(低3位表示类型,高5位表示长度) */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
3.1.2 sds长度(sdslen)
有关如何计算len,可以查看下面代码,
#define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T))))
#define SDS_TYPE_5_LEN(f) ((f)>>SDS_TYPE_BITS)
#define SDS_TYPE_MASK 7
#define SDS_TYPE_BITS 3
static inline size_t sdslen(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
return SDS_TYPE_5_LEN(flags);
case SDS_TYPE_8:
return SDS_HDR(8,s)->len;
case SDS_TYPE_16:
return SDS_HDR(16,s)->len;
case SDS_TYPE_32:
return SDS_HDR(32,s)->len;
case SDS_TYPE_64:
return SDS_HDR(64,s)->len;
}
return 0;
}
-
##:在一个宏(macro)定义表示连接两个子串(token),连接之后##两边的子串就被编译器识别为一个
-
s[-1]:这里实际上是s指针左移一位的意思,由于禁用了内存对齐,s指针指向的是buf[]数组,左移一位刚好是sdshdr的flags成员变量
3.2 跳跃表skiplist
源码位于 https://github.com/redis/redis/blob/6.2/src/server.h和 https://github.com/redis/redis/blob/6.2/src/t_zset.c
跳跃表(skiplist)是一种有序数据结构, 它通过在每个节点中维持多个指向其他节点的指针, 从而达到快速访问节点的目的
跳跃表支持平均 O(log N) 最坏 O(N) 复杂度的节点查找, 还可以通过顺序性操作来批量处理节点
在大部分情况下, 跳跃表的效率可以和平衡树相媲美, 并且因为跳跃表的实现比平衡树要来得更为简单, 所以有不少程序都使用跳跃表来代替平衡树
Redis 使用skiplist作为zset键的底层实现之一: 如果一个zset包含的元素数量比较多, 又或者zset中元素的成员(member)是比较长的字符串时, Redis 就会使用跳跃表来作为zset键的底层实现
单链表
![]()
跳跃表

3.2.1 结构
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
根据源码,可以查看这张redis中的跳跃表示意图
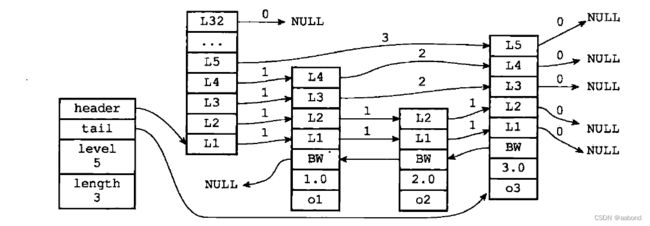
- 最左边的就是zskiplist, 其他就是zskiplistNode
- L1… 表示zskiplistLevel level
- BW 表示backward后退指针
- 1.0,2.0,3.0 表示score分值
- o1,o2,o3 表示存储的数据ele
- level中forward, 表示前进指针,用于从表头向表尾访问
- level中span, 表示跨度,用于计算2个节点间距离
- 每个跳跃表节点的层高都是
1至32之间的随机数
3.2.2 和平衡树比较
| skiplist | avl | |
|---|---|---|
| 插入和删除 | 只需要修改相邻节点的指针,简单快速 | 引发子树的调整,逻辑复杂 |
| 内存占用 | 平均每个节点包含1.33个指针,占用更少内存 | 平衡树每个节点包含2个指针(分别指向左右子树) |
| 算法难度 | 更简单 | 较复杂 |
| 范围查找 | 找到小值之后,对第1层链表进行若干步的遍历 | 找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点,中序遍历并不容易实现,较复杂 |
3.3 压缩列表ziplist
源码位于 https://github.com/redis/redis/blob/6.2/src/ziplist.h
压缩列表 (ziplist) 是哈希(hash)和有序集合(zset)的底层实现之一。当hash或zset中的元素个数比较少并且每个元素的值占用空间比较小的时候,Redis就会使用ziplist做为内部实现
ziplist是由一个连续内存组成的顺序型数据结构。一个压缩列表可以包含任意多个节点(ziplistEntry),每个节点上可以保存一个字节数组或整数值。它是Redis为了节省内存空间而开发的
参考
- Redis 16 个常见使用场景
- Redis 命令参考
- http://www.redis.cn
- Redis源码分析(sds)
- Redis源码(一)——字符串sds
- redis设计与实现 黄健宏
- Redis 为什么用跳表而不用平衡树?