好用的标注工具和标注数据处理代码
一. 标注工具
1.Labelme(官网链接)
windows环境:
首先安装Anaconda,Python3+版本。
安装成功后,打开Anaconda Prompt,然后依次输入以下命令。
# python3
conda create --name=labelme python=3.6 #创建虚拟环境
conda activate labelme #激活虚拟环境
pip install pyqt5 # pyqt5 can be installed via pip on python3
pip install labelme
labelme
ubuntu环境:
conda create --name=labelme python=3.6 #创建虚拟环境
conda activate labelme #激活虚拟环境
sudo apt-get install python3-pyqt5 #还没安装pyqt5,需要安装pyqt5
pip install pillow #还没安装pillow,安装pillow
pip install labelme
labelme
多边形、矩形、圆、线和点的图像注释。
用于分类和清理的图像标志注释。
视频注释。
GUI 自定义(预定义标签/标志、自动保存、标签验证等)。
导出用于语义/实例分割的 VOC 格式数据集。(语义分割,实例分割)
导出 COCO 格式的数据集以进行实例分割。(实例分割)

2.labelImg
在线体验:图像标注工具
windows环境:
首先安装Anaconda,Python3+版本。
安装成功后,打开Anaconda Prompt,然后依次输入以下命令。
# python3
conda create --name=labelImg python=3.6 #创建虚拟环境
conda activate labelImg #激活虚拟环境
git clone https://github.com/tzutalin/labelImg.git
conda install pyqt=5
conda install -c anaconda lxml
pyrcc5 -o libs/resources.py resources.qrc
python labelImg.py
ubuntu环境:
conda create --name=labelImg python=3.6 #创建虚拟环境
conda activate labelImg #激活虚拟环境
sudo apt-get install pyqt5-dev-tools
sudo pip3 install -r requirements/requirements-linux-python3.txt
make qt5py3
python3 labelImg.py

3.EasyData智能数据服务平台(百度)
easydata是一个提供数据采集、标注、清洗、加工等一站式数据服务。
支持多人标注,分配标注任务,总体使用的感觉还不错,目前还是免费使用阶段。
图像分类:单图单标签模板、单图多标签模板
物体检测:矩形框标注模板
图像分割:图像分割模板
文本分类:单文本单标签模板 短文本匹配:短文本匹配模板 情感倾向分析:情感倾向分析模板 文本实体抽取:文本实体抽取模板
音频分类:短音频单标签模板
视频分类:短视频单标签模板

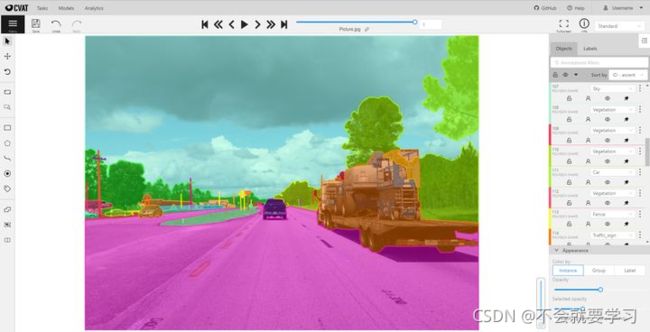
4.CVAT (intel)
在线体验:Computer Vision Annotation Tool
CVAT 是Intel出品的开源标注工具,发布于2018年6月。其支持视频、图片等多种数据类型的标注,功能全面。CVAT也提供了丰富的高级选项,例如:
支持使用Git LFS: Git Large File Storage, 大文件的git管理插件。
调整图片质量:通过降低图片质量(压缩比)来加快高清图片的加载。
作业数和重叠数:如果一个任务中的图片量很大,可以将其分成多个作业。再配合重叠数,可以实现分配一张图片到多个作业的效果,不过暂时没有想到重叠数的使用场景。
5.ModelArts__华为云
华为出品的机器学习平台,发布于2018年10月,其中包含了数据标注模块。其支持从数据导入到模型运维的全流程开发,训练速度较快。
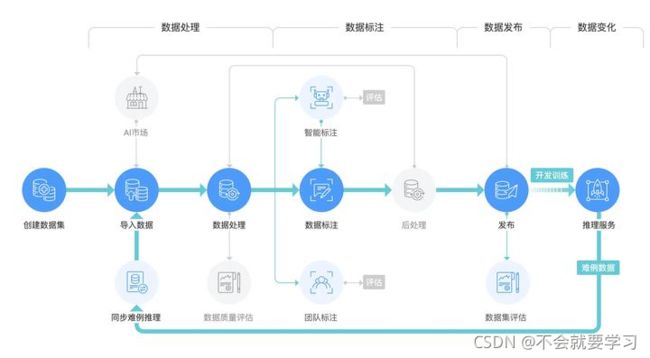
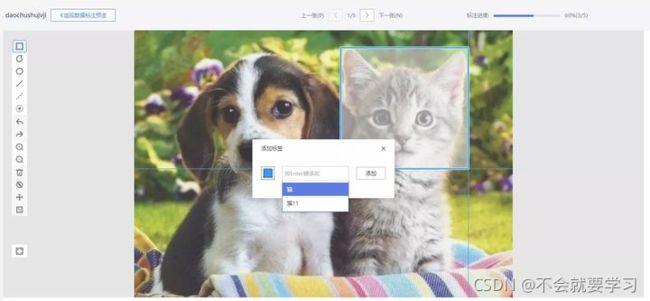
ModelArts将图像标注类型设定在了数据集层面,即创建数据集时就需要区分标注类型.华为图片处理提供的能力主要包括:设置图片效果(亮度、对比度、锐化、模糊)、设置缩略、旋转图片、剪切图片、设置水印、转化格式、压缩图片。
人工标注的特点:
目标检测标注支持多达6种形式的标注:方形、多边形、正圆、点、单线、虚线
高效的标签选择方式:在画完选框后会自动弹出标签下拉框已经展开的添加标签弹窗
图片分组:此功能会使用聚类算法或根据清晰度、亮度、图像色彩对图片进行分组。
6.dataset-tools
这个网站汇总了一些标注工具,感兴趣的额可以取体验一下


二.标注数据可视化处理
1.coco数据格式,json标注文件在图片上显示标注框
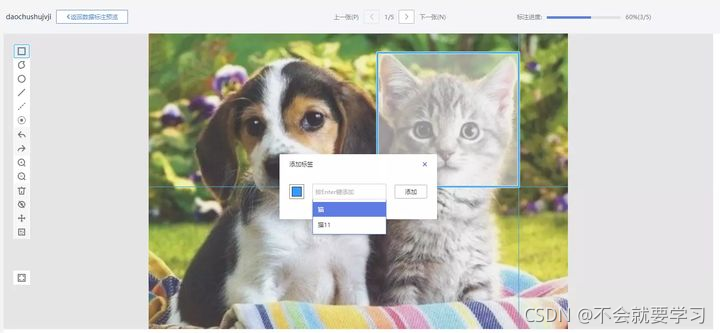
import json
import shutil
import cv2
def select(json_path, outpath, image_path):
json_file = open(json_path)
infos = json.load(json_file)
images = infos["images"]
annos = infos["annotations"]
categories=infos["categories"]
assert len(images) == len(images)
for i in range(len(images)):
im_id = images[i]["id"]
im_path = image_path + images[i]["file_name"]
img = cv2.imread(im_path)
for j in range(len(annos)):
if annos[j]["image_id"] == im_id:
x, y, w, h = annos[j]["bbox"]
x, y, w, h = int(x), int(y), int(w), int(h)
x2, y2 = x + w, y + h
label_number=annos[j]["cate_id"]
label_name=categories[label_number-1]['name']
img = cv2.rectangle(img, (x, y), (x2, y2), (255, 0, 255), thickness=2)
cv2.putText(img, str(label_name),(x,y+20),cv2.FONT_HERSHEY_SIMPLEX, 0.7,(0, 250, 250),thickness=2)
img_name = outpath + images[i]["file_name"]
print(img_name)
cv2.imwrite(img_name, img)
# continue
# print(i)
if __name__ == "__main__":
json_path = "label_test1/Annotations/1-1-1.json"#放标注json的地址
out_path = "label_test1/result/"#结果放的地址
image_path = "label_test1/Images/"#原图的地址
select(json_path, out_path, image_path)
2.voc数据集,利用xml分割目标框图片保存
from __future__ import division
import os
from PIL import Image
import xml.dom.minidom
import numpy as np
ImgPath = 'pic/' #原图放的地方
AnnoPath = 'xml/' #xml标注文件放的地方
ProcessedPath = 'train_pic/'
imagelist = os.listdir(ImgPath)
for image in imagelist:
image_pre, ext = os.path.splitext(image)
imgfile = ImgPath + image
print(imgfile)
if not os.path.exists(AnnoPath + image_pre + '.xml'): continue
xmlfile = AnnoPath + image_pre + '.xml'
DomTree = xml.dom.minidom.parse(xmlfile)
annotation = DomTree.documentElement
filenamelist = annotation.getElementsByTagName('filename') # []
# filename = filenamelist[0].childNodes[0].data
objectlist = annotation.getElementsByTagName('object')
i = 1
for objects in objectlist:
namelist = objects.getElementsByTagName('name')
objectname = namelist[0].childNodes[0].data
savepath = ProcessedPath + objectname
if not os.path.exists(savepath):
os.makedirs(savepath)
bndbox = objects.getElementsByTagName('bndbox')
cropboxes = []
for box in bndbox:
x1_list = box.getElementsByTagName('xmin')
x1 = int(x1_list[0].childNodes[0].data)
y1_list = box.getElementsByTagName('ymin')
y1 = int(y1_list[0].childNodes[0].data)
x2_list = box.getElementsByTagName('xmax')
x2 = int(x2_list[0].childNodes[0].data)
y2_list = box.getElementsByTagName('ymax')
y2 = int(y2_list[0].childNodes[0].data)
w = x2 - x1
h = y2 - y1
obj = np.array([x1, y1, x2, y2])
shift = np.array([[1, 1, 1, 1]])
XYmatrix = np.tile(obj, (1, 1))
cropboxes = XYmatrix * shift
img = Image.open(imgfile)
for cropbox in cropboxes:
cropedimg = img.crop(cropbox)
cropedimg.save(savepath + '/' + image_pre + '_' + str(i) + '.jpg')
i += 1
三.数据格式转换
参考:
1.https://github.com/DLLXW/objectDetectionDatasets
更多了解请关注:
知乎:FUNNY AI