关于人工智能数据标注学习
目录
项目一:认识数据标注
项目二:图像标注的学习
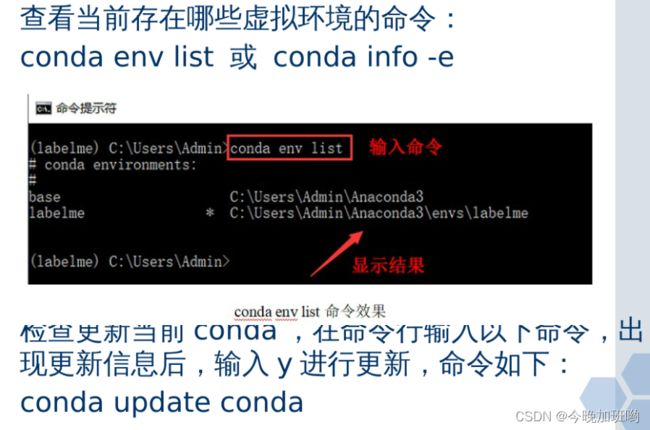
1.基本命令提示符
2.Anaconda软件的安装
3.labelme软件的安装
直接到Anaconda的命令提示框里面!
4.Labelme软件命令和常用的图像数据集
5.图像分类
6.目标检测标注
7.语义分割标注
8.实例分割
9.全景分割标注
10.视频标注
11车道线和交通标识标注
12人体骨骼关键点标注
13Labelme批量命令和可视化
项目三:语音标注
项目四:文本标注
项目一:认识数据标注

人工智能数据标注主要包括:图像标注,语音标注,文本标注!
数据标注是借助标注软件,对人工智能学习数据进行加工和运用的行为!
项目二:图像标注的学习
1.基本命令提示符
cd A:\ 将A盘的当前目录改为根目录
cd A:\xx 将A盘的当前目录改为子目录xx下
cd ..\98 先返回父目录,再进入父目录下的98子目录
cd ..返回到父目录(注:"."代表当前目录 ".."代表父目录)

以上为比较常用的命令提示符,其他提示符就不列出来了,可以自行上网查阅!
2.Anaconda软件的安装
笔记本电脑直接软件商店搜索就,台式的话得到官网去下载!
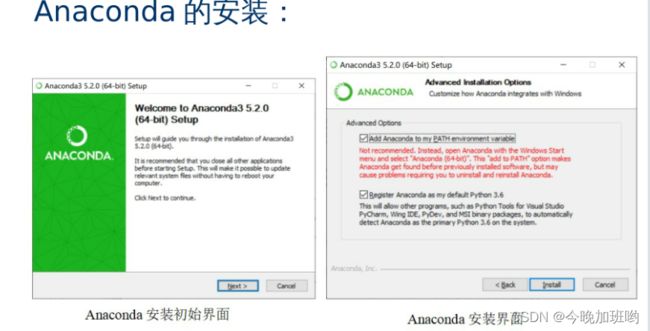
安装的时候记得这两个都勾选!以便配置全局变量!!!!!!

3.labelme软件的安装
直接到Anaconda的命令提示框里面!
先安装虚拟环境!
conda creat -n Labelme python=3.8激活虚拟环境!
activate Labelme安装Labelme软件
Pip install labelme==3.16 -i https://pypi.tuna.tsinghua.edu.cn/simple以下基本为labelme的运行界面! 
该软件是英文版基本使用方法就自行琢磨吧!
4.Labelme软件命令和常用的图像数据集




Labelme软件生成的JSON文件转化为dataset文件的操作
Labelme_json_to_dateset 路径+文件名
如:Labelme_json_to_dateset D:\1.json
5.图像分类
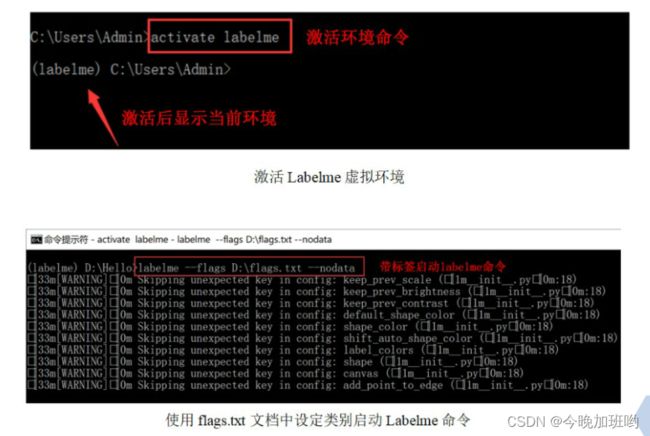
首先啊!就是激活环境啦!
然后通过文本打开Labelme!!!
命令如下
//激活环境: activate Labelme
//通过文本启动Labelme: Labelme --flags D:\flags.txt --nodata
//不管怎样还是得根据文件路劲来单双标签都一样的打开方式!
6.目标检测标注
目标检测标识是指通人工标注出图像中感兴趣的目标,同一类的标签中可以有多个,通常使用矩形进行标注!!!基本有两种类型:物体的标注和人脸的标注但其实操作都一样!!!仅仅知识标签和文件路劲的问题!!!
方法同5差不多!
1建立标签文本启动Labelme
2通过文本打开Labelme
操作代码如下
1.激活:activate Labelme
2.打开:Labelme --labels D:\labels.txt --nodata --autosave
注意:具体文件名和路劲应根据相应你建立的来填采用矩形框来标注!!!
7.语义分割标注
语义分割就是对图像中的每个对象都打上标签,如把图像中的人,树木,草地,天空和动物等都打上对于的标签。语义分割标注需要将物体的轮廓都标注出来,标注的精度远高于目标检测标注。
同样如上:
1激活: activate Labelme
2打开: Labelme --labels D:\labels1.txt --nodata
3同样需要注意文件名和路劲
4.JSON转为dataset
Labelme_json_to_dataset 路劲+JSON文件名
5如:Labelme_json_to_dataset D:\hello\2021_12_27_001.json
转化为VOC数据集可以时使用“ Labelme2voc.py"命令 。格式如下
命令: python Labelme2voc.py 图像目录 生成voc目录 --labels labels文件路径
如下: python d:\Labelme2voc.py D:\Hello\DIRS\semantic_segmentation D:\data_dataset_voc --labels D:\labels.txt
如果提示没有安装lxml包,请通过pip工具进行安装。
如果显示“Output directory already exists”
表面对应的文件夹已经存在,则需删除再重新执行命令即可。8.实例分割
实例分割是目标检测和语义分割的结合,即在图像中先将目标检测出来(目标检测),然后对每个目标打上对应的标签(语义分割)。在语义分割中,不区分属于相同类别的不同目标(所有目标都标为相同颜色),实例分割标注则需要区分同类的不同实例(使用不同颜色来区分不同的人)。
1.打开命令提示符激活
activate Labelme
2.使用文本打开Labelme
Labelme --labels D:\instance_labels.txt --nodata
基本操作就是Labelme的基本使用方法啦
生成JSON转dataset
3.如下
Labelme_json_to_dataset D:\Hello\DIRS\instance_seqmentation\2011_0000006.json
4.转voc
命令: python Labelme2voc.py 图像目录 生成voc目录 --labels labels文件路径
如: python D:\LabelmeInstance2voc.py D:\Hello\DIRS\instance_seqmentation D:\data_dataset_voc --labels D:\instance_labels.txt
5.转COCO数据集
python Labelme2coco.py 图像目录 生成COCO目录 --labels labels文件路劲
9.全景分割标注
全景分割标注是语义分割标注和实例分割标注的结合,既要检测所有目标,又要区分类别中的不同实例。实例分割只是对图像中的目标进行检测和按照橡素分割,区分不同实例(使用不同颜色),而全景标注分割是对图片中的所有物体包括背景都要进行检测和分割。
10.视频标注
视频标注是对视频中物体进行分割和标注,一般步骤如下。将视频转化为一帧一帧连续的视频图像,按照时间顺序保存在同一目录下。在此基础上,对第1帧视频图像进行分割。这种分割的方法的特点是可以利用视频中前后帧目标轮廓的下相似性来进行分割。通过保留前一帧视频图像的分割信息来达到减少工作量的目的。
1 解压ffmpeg.exe到D盘,然后cmd通过d:切换到d根路径
2 视频中提取图片
将一个视频每一帧图片提取出来
>>命令说明:-f 指定输出文件的格式为 image2
ffmpeg -i d:\video\步态文件名.avi -f image2 d:\video\gait\步态文件名-%03d.png
>>步态文件名根据把选文件不同而对应设置,比如,选取 “002-nm-01-090.avi文件”,则上述命令修改为:
ffmpeg -i d:\video\002-nm-01-090.avi -f image2 d:\video\Gait1\002-nm-01-090-%03d.png11车道线和交通标识标注
车道线标注是对图像中的车道线进行标注,而交通标识标注则是对图片中的各种交通标识进行标注。汽车在自动驾驶的过程中,需要通过摄像头的各种传感器来检测和识别各种车道线和交通标识,来控制自身行驶在正确的车道内,同时辅助各种驾驶决策。为提高车道线的检测效果,往往需要使用大量标注好的车道线图像和交通标注图像对模型进行训练。因此,标注车道线和交通标注具有重要的意义和实用价值。
具体就不重复了!注意用线条和矩形框标注就行了。
12人体骨骼关键点标注
人体骨骼关节点标注对于描述人体的姿态和预测人体的行为至关重要。因此,人体骨骼关键点标注是各种计算机和视觉任务的重要基础。常见的人骨骼关节点标注的运用包括行为标识,运动分类,异常人体检测,手语识别等。 人体骨骼关节点标志是计算机视觉中的一个相对基础的任务,是人体动作识别,行为分析,人机交互和运动姿势跟踪等的前置任务!
注意是Create Point(关键点)
人脸标注如下图:下面的图为68个关键点的还算是比较复杂!

13Labelme批量命令和可视化
Labelme 批量命令指的是批量生成dataset数据集。Labelme可视化指的是对于标注好的图像,可以通过“ Labelme_draw_json "命令处理可视化JSON文件 





项目三:语音标注
praat软件的安装:
链接如下:
praat 安装

介绍下简单的使用:
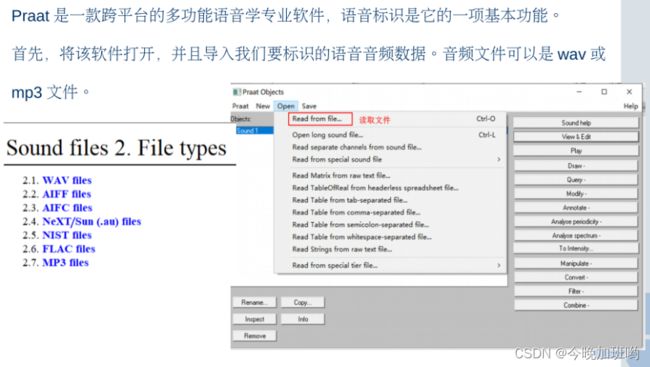
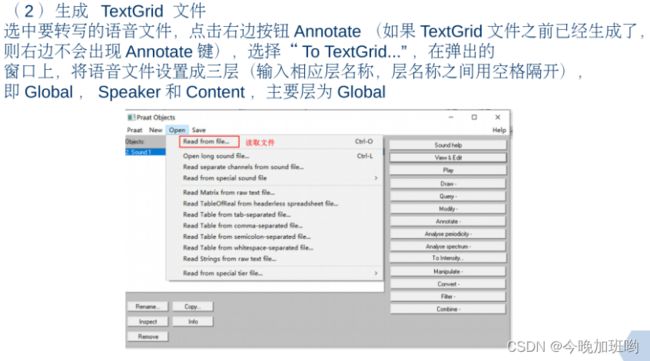
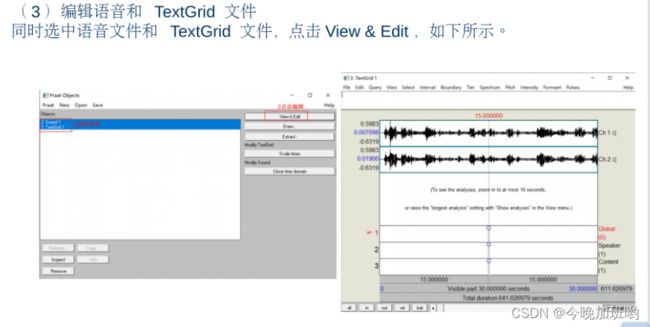




总之记住一些常用的操作快捷键就行了!!!
项目四:文本标注
这个比较简单!
主要有:实体文本标注(序号标记sequence labeling)需要标签
情感分析标注(文本分类document classification) 需要标签
词性标注(序号标记sequence labeling) 需要标签
翻译标注(序列到序列sequence to sequence) 不需要标签直接进行标注
文本相似性标注(文本分类document classification) 需要标签
文本摘要标注(序列到序列sequence to sequence) 不需要标签直接进行标注
以上项目类型千万别选错啦!!!
首先第一点:创建项目!
第二点:项目描述!
第三点:项目类型!
最后就是认真标注吧!!!
考试加油哦!!!