Neural Style Transfer 风格迁移经典论文讲解与 PyTorch 实现
今天花半小时看懂了“Image Style Transfer Using Convolutional Neural Networks Leon”这篇论文,又花半小时看懂了其 PyTorch 实现,最后用半个下午自己实现了一下这篇工作。现在晚上了,顺便给大家分享一手。
文章会一边介绍风格迁移的原理,一边展示部分代码。完整的代码会在附录里给出。
基于 CNN 的图像风格迁移
什么是风格迁移
我们都知道,每一幅画,都可以看成「内容」与「画风」的组合。

比如名画《呐喊》画了一个张着嘴巴的人,这是一种表现主义的画风。

还有梵高这幅《星夜》,非常有个人风格的一幅夜景。

再比如这幅画,一个二次元画风的少女。

最后展示的是一个帅哥,这是一张写实的照片。
所谓风格迁移,就是把一张图片的风格,嵌入到另一张图片的内容里,形成一张新的图片:

如上图所示,左上角的A是一幅真实的照片,BCD分别是把其他几幅画作的风格迁移到原图中形成的新图片。
究竟是什么技术能够实现这么神奇的「风格迁移」效果呢?别急,让我们从几个简单的例子慢慢学起。
复制一幅图片
如果你想复制一幅图片,你会怎么做?
在Windows上,你可以打开画图软件,点击左上角的选择框,把要复制的图片框起来。Ctrl+C、Ctrl+V,就能轻松完成图像复制。
但是,我觉得的这种方法太简单了,不能体现出我们学过数学的人的智慧。我打算用一个更高端的方法。
我把复制图像的任务,看成一个数学上的优化问题。已知源图像S,我要生成一个目标图像T,使得二者均方误差MSE(S-T)最小。这样,一个生成图像的问题,就变成求最优的T的优化问题。
对于这个问题,我们可以随机初始化一张图像T,然后对上面那个优化目标做梯度下降。几轮下来,我们就能求出最优的T——一幅和源图像S一模一样的目标图像。
这段逻辑可以PyTorch实现:
假设我们通过read_image函数读取了一个图片img,且把图片预处理成了[1, 3, H, W]的格式。
source_img = read_image('dldemos/StyleTransfer/picasso.jpg')
我们可以随机初始化一个[1, 3, H, W]大小的图片。由于这张图片是我们的优化对象,所以我们令input_img.requires_grad_(True),这样这张图片就可以被PyTorch自动优化了。
input_img = torch.randn(1, 3, *img_size)
input_img.requires_grad_(True)
之后,我们使用PyTorch的优化器LBFGS,并按照优化器的要求传入被优化参数。(这是这篇论文的作者推荐的优化器~)
optimizer = optim.LBFGS([input_img])
一切变量准备就绪后,我们可以执行梯度下降了:
steps = 0
while steps <= 10:
def closure():
global steps
optimizer.zero_grad()
loss = F.mse_loss(input_img, source_img)
loss.backward()
steps += 1
if steps % 5 == 0:
print(f"Step {steps}:")
print(f"Loss: {loss}")
return loss
optimizer.step(closure)
这段代码有一点要注意:由于LBFGS执行上的特殊性,我们要把执行梯度下降的代码封装成一个闭包(closure,即一个临时定义的函数),并把这个闭包传给optimizer.step。
执行上面的代码进行梯度下降后,这个优化问题很快就能得到收敛。优化结束后,假设我们写好了一个后处理图片的函数save_image,我们可以这样保存它:
save_image(input_img, 'work_dirs/output.jpg')
理论上,这幅图片会和我们的源图像img一模一样。
大家看到这里,肯定一肚子疑惑:为什么要用这么复杂的方式去复制图像啊?就好像告诉你x=2,拿优化算法求和x完全相等的y一样。这不直接令y=2就行了吗?别急,让我们再看下去。
拟合神经网络的输出
刚才我们求解目标图像T的过程,其实可以看成是拟合T的某项特征与S的特征的过程。只不过,我们使用的是像素值这个最基本的特征。假如我们去拟合更特别的一些特征,会发生什么事呢?
Gatys 等科学家发现,如果用预训练VGG模型不同层的卷积输出作为拟合特征,则可以拟合出不同的图像:
如果你对预训练VGG模型不熟,也不用担心。VGG是一个包含很多卷积层的神经网络模型。所谓预训练VGG模型,就是在图像分类数据集上训练过的VGG模型。经过了预训练后,VGG模型的各个卷积层都能提取出图像的一些特征,尽管这些特征是我们人类无法理解的。

上图中,越靠右边的图像,是用越深的卷积层特征进行特征拟合恢复出来的图像。从这些图像恢复结果可以看出,更深的特征只会保留图像的内容(形状),而难以保留图像的纹理(天空的颜色、房子的颜色)。
看到这,大家可能有一些疑惑:这些图片具体是怎么拟合出来的呢?让我们和刚刚一样,详细地看一看这一图像生成过程。
假设我们想生成上面的图c,即第三个卷积层的拟合结果。我们已经得到了模型model_conv123,其包含了预训练VGG里的前三个卷积层。我们可以设立以下的优化目标:
source_feature = model_conv123(source_img)
input_feature = model_conv123(input_img)
# minimize MSE(source_feature, input_feature)
在实现时,我们只要稍微修改一下开始的代码即可。
首先,我们可以预处理出源图像的特征。注意,这里我们要用source_feature.detach()来把source_feature从计算图中取出,防止源图像被PyTorch自动更新。
source_img = read_image('dldemos/StyleTransfer/picasso.jpg')
source_feature = model_conv123(source_img).detach()
之后,我们可以用类似的方法做梯度下降:
steps = 0
while steps <= 50:
def closure():
global steps
optimizer.zero_grad()
input_feature = model_conv123(input_img)
loss = F.mse_loss(input_feature, source_feature)
loss.backward()
steps += 1
if steps % 5 == 0:
print(f"Step {steps}:")
print(f"Loss: {loss}")
return loss
optimizer.step(closure)
看到没,我们刚刚这种利用优化问题生成目标图像的方法并不愚蠢,只是一开始大材小用了而已。通过这种方法,我们可以生成一幅拟合了源图像在神经网络中的深层特征的目标图像。那么,怎么利用这种方法完成风格迁移呢?
风格+内容=风格迁移
Gatys 等科学家发现,不仅是卷积结果可以当作拟合特征,VGG的一些其他中间结果也可以作为拟合特征。受到之前用CNN做纹理生成的工作[2]的启发,他们发现用卷积结果的Gram矩阵作为拟合特征可以得到另一种图像生成效果:

上图中,右边a-e是用VGG不同卷积结果的Gram矩阵作为拟合特征,得到的对左图的拟合图像。可以看出,用这种特征来拟合的话,生成图像会失去原图的内容(比如星星和物体的位置完全变了),但是会保持图像的整体风格。
这里稍微提一下Gram矩阵的计算方法。Gram矩阵定义在两个特征的矩阵F_1, F_2上。其中,每个特征矩阵F是VGG某层的卷积输出张量F_conv(shape: [n, h, w])reshape成一个矩阵F (shape: [n, h * w])的结果。Gram矩阵,就是两个特征矩阵F_1, F_2的内积,即F_1每个通道的特征向量和F_2每个通道的特征向量的相似度构成的矩阵。我们这里假设F_1=F_2,即对某个卷积特征自身生成Gram矩阵。这段逻辑用代码实现如下:
def gram(x: torch.Tensor):
# x 是VGG卷积层的输出张量
n, c, h, w = x.shape
features = x.reshape(n * c, h * w)
features = torch.mm(features, features.T)
return features
Gram矩阵表示的是通道之间的相似性,与位置无关。因此,Gram矩阵是一种具有空间不变性(spatial invariance)的指标,可以描述整幅图像的性质,适用于拟合风格。与之相对,我们之前拟合图像内容时用的是图像每一个位置的特征,这一个指标是和空间相关的。Gram矩阵只是拟合风格的一种可选指标。后续研究证明,还有其他类似的特征也能达到和Gram矩阵一样的效果。我们不需要过分纠结于Gram矩阵的原理。
看到这里,大家或许已经明白风格迁移是怎么实现的了。风格迁移,其实就是既拟合一幅图像的内容,又去拟合另一幅图像的风格。我们把前一幅图像叫做内容图像,后一幅图像叫做风格图像。
我们在上一节知道了如何拟合内容,这一节知道了怎么去拟合风格。要把二者结合起来,只要令我们的优化目标既包含和内容图像的内容误差,又包含和风格图像的风格误差。在原论文中,这些误差是这样表达的:
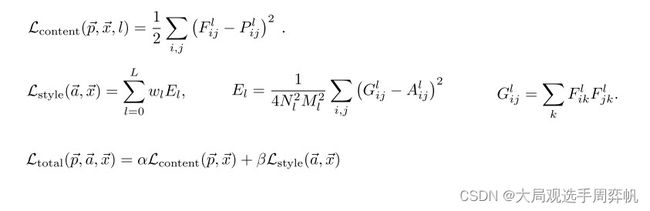
上面第一行公式表达的是内容误差,第二行公式表达的是风格误差。
第一行公式中, F F F, P P P分别是生成图像的卷积特征和源图像的卷积特征。
第二行公式中, F F F是生成图像的卷积特征, G G G是 F F F的Gram矩阵, A A A是源图像卷积特征的Gram矩阵, E l E_l El表示第 l l l层的风格误差。在论文中,总风格误差是某几层风格误差的加权和,其中权重为 w l w_l wl。事实上,不仅总风格误差可以用多层风格误差的加权和表示,总内容误差也可以用多层内容误差的加权和表示。只是在原论文中,只使用了一层的内容误差。
第三行中, α , β \alpha, \beta α,β分别是内容误差的权重和风格误差的权重。实际上,我们只用考虑 α , β \alpha, \beta α,β的比值即可。如果 α \alpha α较大,则说明优化内容的权重更大,生成出来的图像更靠近内容图像。反之亦然。
只要用这个误差去替换我们刚刚代码实现中的误差,就可以完成图像的风格迁移了,听起来是不是十分简单?但是,用PyTorch实现风格迁移时还要考虑不少细节。在本文的附录中,我会对风格迁移的实现代码做一些讲解。
思考
其实这篇文章是比较早期的用神经网络做风格迁移的工作。在近两年里,肯定有许多试图改进此方法的研究。时至今日,再去深究这篇文章里的一些细节(为什么用Gram矩阵,应该用VGG的哪些层做拟合)已经意义不大了。我们应该关注的是这篇文章的主要思想。
这篇文章对我的最大启发是:神经网络不仅可以用于在大批数据集上训练,完成一项通用的任务,还可以经过预训练,当作一个特征提取器,为其他任务提供额外的信息。同样,要记住神经网络只是优化任务的一项特例,我们完全可以把梯度下降法用于普通的优化任务中。在这种利用了神经网络的参数,而不去更新神经网络参数的优化任务中,梯度下降法也是适用的。
此外,这篇文章中提到的「风格」也是很有趣的一项属性。这篇文章算是首次利用了神经网络中的信息,用于提取内容、风格等图像属性。这种提取属性(尤其是提取风格)的想法被运用到了很多的后续研究中,比如大名鼎鼎的StyleGAN。
长期以来,人们总是把神经网络当成黑盒。但是,这篇文章给了我们一个掀开黑盒的思路:通过拟合神经网络中卷积核的特征,我们能够窥见神经网络每一层保留了哪些信息。相信在之后的研究中,人们能够更细致地去研究神经网络的内在原理。
参考文献
[1] Gatys L A, Ecker A S, Bethge M. Image style transfer using convolutional neural networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 2414-2423.
[2] Gatys L, Ecker A S, Bethge M. Texture synthesis using convolutional neural networks[J]. Advances in neural information processing systems, 2015, 28.
[3] 代码实现:https://pytorch.org/tutorials/advanced/neural_style_tutorial.html
附录:PyTorch 实现风格迁移
这段代码实现是基于 PyTorch 官方教程 编写的。
本文的代码仓库链接:https://github.com/SingleZombie/DL-Demos/tree/master/dldemos/StyleTransfer
准备工作
首先,导入我们需要的库。我们要导入PyTorch的基本库,并导入torchvision做图像变换和初始化预训练模型。此外,我们用PIL读写图像。我们还可以顺手设置一下运算设备(cpu或gpu)。
import torch
import torch.nn.functional as F
import torch.optim as optim
import torchvision.models as models
import torchvision.transforms as transforms
from PIL import Image
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
之后是图像读取。为了正确计算误差,所有图像的形状必须是统一的。因此,在读取图像后,我们要对图像做Resize的预处理。预处理之后,我们得到的图像是c, h, w格式的,别忘了用unsqueeze加上batch那一维。
这里
torchvision中的transforms表示一些预处理操作。部分操作只能对PIL图像进行,而不能对np.ndaray进行。所以,这里用PIL存取图像比用cv2更方便。
img_size = (256, 256)
def read_image(image_path):
pipeline = transforms.Compose(
[transforms.Resize((img_size)),
transforms.ToTensor()])
img = Image.open(image_path).convert('RGB')
img = pipeline(img).unsqueeze(0)
return img.to(device, torch.float)
保存图像时,只要调用PIL的API即可:
def save_image(tensor, image_path):
toPIL = transforms.ToPILImage()
img = tensor.detach().cpu().clone()
img = img.squeeze(0)
img = toPIL(img)
img.save(image_path)
误差计算
在 PyTorch 中定义误差时,比较优雅的做法是定义一个torch.autograd.Function。但是这样做比较麻烦,需要手写反向传播。由于本文中新介绍的误差全部都是基于MSE均方误差的,我们可以基于torch.nn.Module编写一些“虚假的”误差函数。
首先,编写内容误差:
class ContentLoss(torch.nn.Module):
def __init__(self, target: torch.Tensor):
super().__init__()
self.target = target.detach()
def forward(self, input):
self.loss = F.mse_loss(input, self.target)
return input
在神经网络中,这个类其实没有做任何运算(forward直接把input返回了)。但是,这个类缓存了内容误差值。我们稍后可以取出这个类实例的loss,丢进最终的误差计算公式里。这种通过插入一个不进行计算的torch.nn.Module来保存中间计算结果的方法,算是使用PyTorch的一个小技巧。
之后,编写gram矩阵的计算方法及风格误差的计算“函数”:
def gram(x: torch.Tensor):
# x is a [n, c, h, w] array
n, c, h, w = x.shape
features = x.reshape(n * c, h * w)
features = torch.mm(features, features.T) / n / c / h / w
return features
class StyleLoss(torch.nn.Module):
def __init__(self, target: torch.Tensor):
super().__init__()
self.target = gram(target.detach()).detach()
def forward(self, input):
G = gram(input)
self.loss = F.mse_loss(G, self.target)
return input
这里实现风格误差的思路与内容误差同理。
获取预训练模型
VGG模型对输入数据的分布有要求(即对输入数据均值、标准差有要求)。为了方便起见,我们可以写一个标准化分布的层,作为最终模型的第一层:
class Normalization(torch.nn.Module):
def __init__(self, mean, std):
super().__init__()
self.mean = torch.tensor(mean).to(device).reshape(-1, 1, 1)
self.std = torch.tensor(std).to(device).reshape(-1, 1, 1)
def forward(self, img):
return (img - self.mean) / self.std
接下来,我们可以利用torchvision中的预训练VGG,提取出其中我们需要的模块。我们还需要获取刚刚编写的误差类的实例的引用,以计算最终的误差。
这段代码的实现思路是:我们不直接把VGG拿过来用,而是新建一个用torch.nn.Sequential表示的序列模型。我们先把标准化层加入这个序列,再把原VGG中的计算层逐个加入我们的新序列模型中。一旦我们发现某个计算层的计算结果要用作计算误差,我们就在这个层后面加一个用于捕获误差的误差模块。
整段逻辑用文字难以说清,大家可以直接看代码理解:
default_content_layers = ['conv_4']
default_style_layers = ['conv_1', 'conv_2', 'conv_3', 'conv_4', 'conv_5']
def get_model_and_losses(content_img, style_img, content_layers, style_layers):
num_loss = 0
expected_num_loss = len(content_layers) + len(style_layers)
content_losses = []
style_losses = []
model = torch.nn.Sequential(
Normalization([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]))
cnn = models.vgg19(pretrained=True).features.to(device).eval()
i = 0
for layer in cnn.children():
if isinstance(layer, torch.nn.Conv2d):
i += 1
name = f'conv_{i}'
elif isinstance(layer, torch.nn.ReLU):
name = f'relu_{i}'
layer = torch.nn.ReLU(inplace=False)
elif isinstance(layer, torch.nn.MaxPool2d):
name = f'pool_{i}'
elif isinstance(layer, torch.nn.BatchNorm2d):
name = f'bn_{i}'
else:
raise RuntimeError(
f'Unrecognized layer: {layer.__class__.__name__}')
model.add_module(name, layer)
if name in content_layers:
# add content loss:
target = model(content_img)
content_loss = ContentLoss(target)
model.add_module(f'content_loss_{i}', content_loss)
content_losses.append(content_loss)
num_loss += 1
if name in style_layers:
target_feature = model(style_img)
style_loss = StyleLoss(target_feature)
model.add_module(f'style_loss_{i}', style_loss)
style_losses.append(style_loss)
num_loss += 1
if num_loss >= expected_num_loss:
break
return model, content_losses, style_losses
这里有些地方要注意:VGG有多个模块,其中我们只需要包含卷积层的vgg19().features模块。另外,我们只需要那些用于计算误差的层,当我们发现所有和误差相关的层都放入了新模型后,就可以停止新建模块了。
用梯度下降生成图像
这里的步骤和正文中的类似,我们先准备好输入的噪声图像、模型、误差类实例的引用,并设置好哪些参数需要优化,哪些不需要。
input_img = torch.randn(1, 3, *img_size, device=device)
model, content_losses, style_losses = get_model_and_losses(
content_img, style_img, default_content_layers, default_style_layers)
input_img.requires_grad_(True)
model.requires_grad_(False)
之后,我们声明好用到的超参数。这两个超参数能够控制图像是更靠近内容图像还是风格图像。
style_img = read_image('dldemos/StyleTransfer/picasso.jpg')
content_img = read_image('dldemos/StyleTransfer/dancing.jpg')
这两张图片来自官方教程。链接分别为picasso, dancing。
最后,执行熟悉的梯度下降即可:
optimizer = optim.LBFGS([input_img])
steps = 0
prev_loss = 0
while steps <= 1000 and prev_loss < 100:
def closure():
with torch.no_grad():
input_img.clamp_(0, 1)
global steps
global prev_loss
optimizer.zero_grad()
model(input_img)
content_loss = 0
style_loss = 0
for l in content_losses:
content_loss += l.loss
for l in style_losses:
style_loss += l.loss
loss = content_weight * content_loss + style_weight * style_loss
loss.backward()
steps += 1
if steps % 50 == 0:
print(f'Step {steps}:')
print(f'Loss: {loss}')
# Open next line to save intermediate result
# save_image(input_img, f'work_dirs/output_{steps}.jpg')
prev_loss = loss
return loss
optimizer.step(closure)
由于我们有先验知识,知道图像位于(0, 1)之间,每一轮优化前我们可以手动约束一下图像的数值以加速训练。
运行程序的时候会有一些特殊情况。有些时候,任务的误差loss会突然涨到一个很高的值,过几轮才会恢复正常。为了保证输出的loss总是不那么大,我加了一个prev_loss < 100的要求。
这里steps的值是可以调的,误差究竟多小才算小也取决于实际任务以及content_weight, style_weight的大小。这些超参数都是可以去调试的。
最后,我们可以保存最终输出的图像:
with torch.no_grad():
input_img.clamp_(0, 1)
save_image(input_img, 'work_dirs/output.jpg')
正常情况下,运行上面这些的代码,可以得到下面的运行结果(我的style_weight/content_weight=1e6)
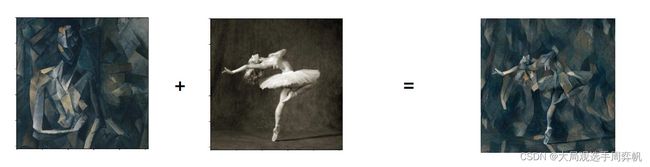
彩蛋
在理解了风格迁移是在做什么后,我就立刻想到:可不可以用风格迁移,把照片渲染成二次元风格呢?
成功完成代码实现后,我立马尝试把动漫风格迁移到我的照片上:

这效果也太差了吧?!我不服气,多输出了几幅中间结果。这下好了,结果更诡异了:

我都搞不清楚,这是进入了二次元,还是进入了显像管电视机。
可以看出,这种算法生成出来的二次元图像,还是保留了二次元图片中的一些风格:线条分明,颜色是一块一块的。但是整体效果太差了。
只能说,这种算法的局限性还是太强了。想进入二次元,任重而道远啊。