神经网络风格迁移Pytorch
原文链接
目录
引言(Introduction)
基础原理(Underlying Principle)
引入模块和选择设备(Importing Packages and Selecting a Device)
下载图片(Loading the Images)
损失函数(Loss Functions)
内容损失(Content Loss)
风格损失(Style Loss)
引入模型(Importing the Model)
梯度下降(Gradient Descent)
引言(Introduction)
本教程解释了如何实现由Leon A Gatys, Alexander S. Ecker和Matthias Bethge开发的神经网络风格迁移算法(Neural-Style algorithm)。该算法需要三个图片:一个输入图片pi,一个内容图片pc,一个风格图片ps,然后把图片pi转换成一个和pc图片的内容相似,并与ps图片的风格相似的图片。

基础原理(Underlying Principle)
原理很简单:我们定义两个距离,一个用于内容(DC),另一个用于风格 (DS)。DC测量两个图片之间内容的差异,而DS测量两个图片之间风格的不同。然后,我们获取第三个图片,即输入,并对其进行转换,以最小化其与内容图片的内容距离和其与风格图片之间的风格距离。现在我们可以导入必要的包并开始进行神经风格迁移。
引入模块和选择设备(Importing Packages and Selecting a Device)
以下是实现神经网络风格迁移所需的软件包列表。
torch,torch.nn,numpy(使用PyTorch进行神经网络搭建时不可缺少的包)torch.optim(高效的梯度下降)PIL,PIL.Image,matplotlib.pyplot(加载并展示图片)torchvision.transforms(转换PIL images为 tensors)torchvision.models(训练或加载预训练模型)copy(用来进行模型的深拷贝; 系统模块)
from __future__ import print_function
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from PIL import Image
import matplotlib.pyplot as plt
import torchvision.transforms as transforms
import torchvision.models as models
import copy接下来,我们需要选择在哪个设备上运行网络并导入内容及风格图片。使用GPU会使运行速度加快。我们可以使用torch.cuda.is_available()来检测是否有可用的GPU资源。接下来,我们设置torch.device在整个教程使用。另外,.to(device)方法用于将张量或模型移动到所需的设备上。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")下载图片(Loading the Images)
现在我们将导入风格图片及内容图片。原始PIL图片的值介于0和255之间,但是当转换为torch的张量时,它们的值被转换到0-1之间。图片也需要resize到同一尺寸。一个需要特别注意的细节是:torch库中的神经网络使用0-1的张量值进行训练。如果你将0-255的张量值喂给神经网络,那么被激活的特征图将不能感知到预期的内容和风格。然而,Caffe库中的预训练模型使用0-255的张量值图片进训练。
注意:
以下链接可下载运行本教程代码所需的图片: picasso.jpg 和dancing.jpg. 下载这两张图片并将它们添加到data\images\neural-style目录。
# desired size of the output image
imsize = 512 if torch.cuda.is_available() else 128 # use small size if no gpu
loader = transforms.Compose([
transforms.Resize(imsize), # scale imported image
transforms.ToTensor()]) # transform it into a torch tensor
def image_loader(image_name):
image = Image.open(image_name)
# fake batch dimension required to fit network's input dimensions
image = loader(image).unsqueeze(0)
return image.to(device, torch.float)
style_img = image_loader("./data/images/neural-style/picasso.jpg")
content_img = image_loader("./data/images/neural-style/dancing.jpg")
assert style_img.size() == content_img.size(), \
"we need to import style and content images of the same size"现在,让我们创建一个函数imshow——将图片的副本转换为PIL格式,并使用plt.imshow画出该图。最后,我们将调用plt.show()来显示内容图片和样式图片,以确保它们被正确导入。
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
unloader = transforms.ToPILImage() # reconvert into PIL image
def imshow(tensor, title=None):
image = tensor.cpu().clone() # we clone the tensor to not do changes on it
image = image.squeeze(0) # remove the fake batch dimension
image = unloader(image)
plt.imshow(image)
if title is not None:
plt.title(title)
plt.figure()
plt.subplot(1,2,1)
imshow(style_img, title='Style Image')
plt.subplot(1,2,2)
imshow(content_img, title='Content Image')
plt.show()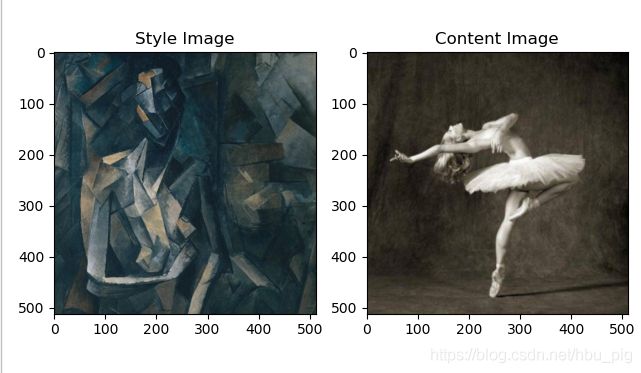
损失函数(Loss Functions)
内容损失(Content Loss)
内容损失是一个表示单个层的加权内容距离的函数。该函数的输入是:输入图片 在神经网络第
在神经网络第 层的特征图
层的特征图![]() ;该函数的输出是:输入图片和内容图片
;该函数的输出是:输入图片和内容图片 的加权内容距离
的加权内容距离![]() 。为了计算内容距离,该函数必须知道内容图片的特征图(
。为了计算内容距离,该函数必须知道内容图片的特征图(![]() )。我们将这个函数通过torch.Module来实现,使用
)。我们将这个函数通过torch.Module来实现,使用![]() 作为构造函数的参数。距离
作为构造函数的参数。距离![]() 是两组特征图均方差,可以使用nn.
是两组特征图均方差,可以使用nn.MSELoss计算.
我们将在用于计算内容距离的卷积层之后直接添加此内容损失模块。这样,每次网络收到输入图像时,将在所需层计算内容损失,并且由于自动微分,将计算所有梯度。现在,为了使内容损失层透明,我们必须定义一个forward方法来计算内容损失,然后把输入原封不动的返回。计算的损失作为模块的参数(ContentLoss.loss)保存。
class ContentLoss(nn.Module):
def __init__(self, target,):
super(ContentLoss, self).__init__()
# we 'detach' the target content from the tree used
# to dynamically compute the gradient: this is a stated value,
# not a variable. Otherwise the forward method of the criterion
# will throw an error.
self.target = target.detach()
def forward(self, input):
self.loss = F.mse_loss(input, self.target)
return input注意
重要细节: 尽管这个模块名为ContentLoss, 但它不是一个真正的Pytorch损失函数。如果要将内容损失定义为Pytorch损失函数,则必须创建torch.autograd.Function,在backward方法中自己来重新计算/实现梯度。详见https://pytorch.org/tutorials/advanced/numpy_extensions_tutorial.html
风格损失(Style Loss)
风格丢失模块的实现与内容丢失模块类似。它将充当网络中的透明层。为了计算风格损失,我们需要计算gram矩阵![]() 。gram矩阵是给定矩阵乘以其转置矩阵的结果。在这个应用中,给定的矩阵是第层的特征图
。gram矩阵是给定矩阵乘以其转置矩阵的结果。在这个应用中,给定的矩阵是第层的特征图![]() 的重塑版本。
的重塑版本。![]() 被重塑为
被重塑为![]() ——一个KxN的矩阵,其中K是第L层的特征图的数量,N是矢量化特征图
——一个KxN的矩阵,其中K是第L层的特征图的数量,N是矢量化特征图![]() 的长度。例如,
的长度。例如,![]() 的第一行对应于第一个矢量化特征图
的第一行对应于第一个矢量化特征图![]() 。
。
最后,gram矩阵必须通过将每个元素除以矩阵中元素的总数来规范化。这种规范化是为了抵消这样一个事实:具有大N维的![]() 矩阵在Gram矩阵中产生更大的值。这些较大的值将导致第一层(在池化层之前)在梯度下降过程中产生更大的影响。风格特征往往在网络的深层,所以这个标准化步骤是至关重要的。
矩阵在Gram矩阵中产生更大的值。这些较大的值将导致第一层(在池化层之前)在梯度下降过程中产生更大的影响。风格特征往往在网络的深层,所以这个标准化步骤是至关重要的。
def gram_matrix(input):
a, b, c, d = input.size() # a=batch size(=1)
# b=number of feature maps
# (c,d)=dimensions of a f. map (N=c*d)
features = input.view(a * b, c * d) # resise F_XL into \hat F_XL
G = torch.mm(features, features.t()) # compute the gram product
# we 'normalize' the values of the gram matrix
# by dividing by the number of element in each feature maps.
return G.div(a * b * c * d)现在,风格损失模块与内容损失模块几乎完全相同。使用![]() 和
和![]() 之间的均方误差计算风格距离。
之间的均方误差计算风格距离。
class StyleLoss(nn.Module):
def __init__(self, target_feature):
super(StyleLoss, self).__init__()
self.target = gram_matrix(target_feature).detach()
def forward(self, input):
G = gram_matrix(input)
self.loss = F.mse_loss(G, self.target)
return input引入模型(Importing the Model)
现在我们需要导入一个预训练的神经网络。我们将使用一个19层VGG网络,同论文中使用的一样。
Pytorch的VGG实现是一个分为两个子Sequential模块的模块:features (包含卷积和池化层)和classifier (包含全连接层)。我们将用到features模块,因为我们需要使用单个卷积层的输出来测量内容和风格的损失。有些层在训练过程中的行为与评估不同,因此必须使用.eval().将网络设置为评估模式。
cnn = models.vgg19(pretrained=True).features.to(device).eval()此外,VGG网络在图像上进行训练,对应通道的mean=[0.485,0.456,0.406]和std=[0.229,0.224,0.225]。在将图像输入到网络之前,我们将使用它们来规范化图像。
cnn_normalization_mean = torch.tensor([0.485, 0.456, 0.406]).to(device)
cnn_normalization_std = torch.tensor([0.229, 0.224, 0.225]).to(device)
# create a module to normalize input image so we can easily put it in a
# nn.Sequential
class Normalization(nn.Module):
def __init__(self, mean, std):
super(Normalization, self).__init__()
# .view the mean and std to make them [C x 1 x 1] so that they can
# directly work with image Tensor of shape [B x C x H x W].
# B is batch size. C is number of channels. H is height and W is width.
self.mean = torch.tensor(mean).view(-1, 1, 1)
self.std = torch.tensor(std).view(-1, 1, 1)
def forward(self, img):
# normalize img
return (img - self.mean) / self.stdSequential 模块包含的子模块是有序列表。例如,vgg19.features 包含一个按顺序对齐的序列(Conv2d,ReLU,MaxPool2d,Conv2d,ReLU…)。我们需要在检测到的卷积层之后立即添加内容损失层和风格丢失层。为此,我们必须创建一个新的顺序模块,该模块正确插入了内容损失和风格损失模块。
# desired depth layers to compute style/content losses :
content_layers_default = ['conv_4']
style_layers_default = ['conv_1', 'conv_2', 'conv_3', 'conv_4', 'conv_5']
def get_style_model_and_losses(cnn, normalization_mean, normalization_std,
style_img, content_img,
content_layers=content_layers_default,
style_layers=style_layers_default):
cnn = copy.deepcopy(cnn)
# normalization module
normalization = Normalization(normalization_mean, normalization_std).to(device)
# just in order to have an iterable access to or list of content/syle
# losses
content_losses = []
style_losses = []
# assuming that cnn is a nn.Sequential, so we make a new nn.Sequential
# to put in modules that are supposed to be activated sequentially
model = nn.Sequential(normalization)
i = 0 # increment every time we see a conv
for layer in cnn.children():
if isinstance(layer, nn.Conv2d):
i += 1
name = 'conv_{}'.format(i)
elif isinstance(layer, nn.ReLU):
name = 'relu_{}'.format(i)
# The in-place version doesn't play very nicely with the ContentLoss
# and StyleLoss we insert below. So we replace with out-of-place
# ones here.
layer = nn.ReLU(inplace=False)
elif isinstance(layer, nn.MaxPool2d):
name = 'pool_{}'.format(i)
elif isinstance(layer, nn.BatchNorm2d):
name = 'bn_{}'.format(i)
else:
raise RuntimeError('Unrecognized layer: {}'.format(layer.__class__.__name__))
model.add_module(name, layer)
if name in content_layers:
# add content loss:
target = model(content_img).detach()
content_loss = ContentLoss(target)
model.add_module("content_loss_{}".format(i), content_loss)
content_losses.append(content_loss)
if name in style_layers:
# add style loss:
target_feature = model(style_img).detach()
style_loss = StyleLoss(target_feature)
model.add_module("style_loss_{}".format(i), style_loss)
style_losses.append(style_loss)
# now we trim off the layers after the last content and style losses
for i in range(len(model) - 1, -1, -1):
if isinstance(model[i], ContentLoss) or isinstance(model[i], StyleLoss):
break
model = model[:(i + 1)]
return model, style_losses, content_losses下一步,我们选择输入图像。您可以使用内容图像的副本或噪声数据。
input_img = content_img.clone()
# if you want to use white noise instead uncomment the below line:
# input_img = torch.randn(content_img.data.size(), device=device)
# add the original input image to the figure:
plt.figure()
imshow(input_img, title='Input Image')
plt.show()梯度下降(Gradient Descent)
正如该算法的作者Leon Gatys所建议的,我们将使用L-BFGS算法来运行梯度下降。与训练网络不同,这次我们训练的是输入图像,以尽量减少内容/风格的损失。我们将创建一个Pytorch L-BFGS优化器optim.LBFGS,并将图像作为张量传递给它进行优化。
def get_input_optimizer(input_img):
# this line to show that input is a parameter that requires a gradient
optimizer = optim.LBFGS([input_img.requires_grad_()])
return optimizer最后,我们必须定义一个执行神经网络风格迁移的函数。对于网络的每次迭代,它都会得到更新的输入并计算新的损失。我们将运行每个损失模块的backward方法来动态计算它们的梯度。优化器需要一个“closure”函数,该函数重新评估模块并返回损失。
我们还有最后一个限制要解决。网络优化后的输入图片的取值范围可能超过[0,1]区间。我们可以通过将输入值更正为0到1来解决这个问题。
def run_style_transfer(cnn, normalization_mean, normalization_std,
content_img, style_img, input_img, num_steps=300,
style_weight=1000000, content_weight=1):
"""Run the style transfer."""
print('Building the style transfer model..')
model, style_losses, content_losses = get_style_model_and_losses(cnn,
normalization_mean, normalization_std, style_img, content_img)
optimizer = get_input_optimizer(input_img)
print('Optimizing..')
run = [0]
while run[0] <= num_steps:
def closure():
# correct the values of updated input image
input_img.data.clamp_(0, 1)
optimizer.zero_grad()
model(input_img)
style_score = 0
content_score = 0
for sl in style_losses:
style_score += sl.loss
for cl in content_losses:
content_score += cl.loss
style_score *= style_weight
content_score *= content_weight
loss = style_score + content_score
loss.backward()
run[0] += 1
if run[0] % 50 == 0:
print("run {}:".format(run))
print('Style Loss : {:4f} Content Loss: {:4f}'.format(
style_score.item(), content_score.item()))
print()
return style_score + content_score
optimizer.step(closure)
# a last correction...
input_img.data.clamp_(0, 1)
return input_img最后,我们可以运行该算法。
output = run_style_transfer(cnn, cnn_normalization_mean, cnn_normalization_std,
content_img, style_img, input_img)
plt.figure()
imshow(output, title='Output Image')
plt.show()
输出(Output):
Building the style transfer model..
Optimizing..
run [50]:
Style Loss : 4.252238 Content Loss: 4.272705
run [100]:
Style Loss : 1.179310 Content Loss: 3.084507
run [150]:
Style Loss : 0.728602 Content Loss: 2.676025
run [200]:
Style Loss : 0.487275 Content Loss: 2.506387
run [250]:
Style Loss : 0.351646 Content Loss: 2.414481
run [300]:
Style Loss : 0.267817 Content Loss: 2.363323