Attention机制详解以及在图神经网络中的应用
Attention机制详解以及在图神经网络中的应用
- 注意力机制和transformer框架
-
- 注意力机制的来源和引入原因
- 1.2 注意力系数的计算
- 1.3 Transformer框架
- 2 图注意力网络(GAT)和attention计算
-
- 2.1 输入输出
- 2.2 共享线性变化
- 2.3 self-attention机制
- 3 DGL实现图注意力网络和实验结果
本文基于Advanced Deep Learning的第三次作业,内容如下:
- 理解论文Attention is all you need,介绍attention计算方式和transformer框架
- 理解论文Graph Attention Networks,介绍图神经中attention计算方式和模型框架
- 用DGL实现图注意力网络的模型部分,和baseline对比观察模型提升效果
注意力机制和transformer框架
注意力机制的来源和引入原因
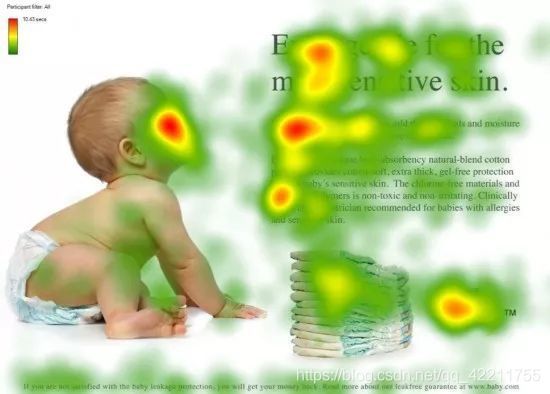
注意力机制借鉴了人类的选择性注意力机制。例如,人类视觉快速扫描全局图像,获得认为应该重点注意的目标区域,并对目标区域信息投入更多注意力获取细节,减少对图片其他无用信息的关注。如下图,我们会把更多注意力放到婴儿的脸部,文章的标题和文本的首句等位置。
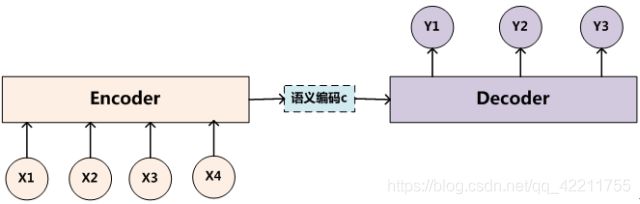
现流行的注意力模型一般依附在encoder-decoder框架上,可以处理包括NLP、图像处理等任务,下面以NLP中常用的encoder-decoder框架为例子做讲解。
encoder处理输入单词序列source(x1, x2,…,xm),经过非线性变化生成中间语义C=f(x1, x2, …, xm),decoder根据中间语义C和已经生成的历史信息(y1, y2, …, yi-1) 来生成i时刻的单词yi。
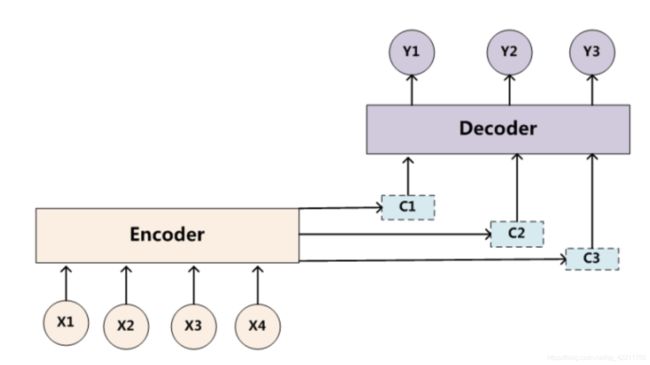
没有使用注意力机制的模型在处理长文本时会出现问题,因为decoder使用的是同样的中间语义,也就是在生成每一个单词时原输入的每一单词贡献是相等的,这显然是不合理的,特别是针对长句子来说,相同的中间语义意味着原单词和细节信息的丢失,这也是引入attention的重要原因。
引入attention机制之后,中间语义Ci = ai1 * f(x1) + ai2 * f(x2) + … + ain * f(xn),其中f表示encoder层对输入单词序列的非线性处理,a表示decoder生成第i个单词时对source输入第j个单词的注意力分配系数。
如何得到单词概率分布?我们可以将输出层隐藏节点Hi-1的状态和输入层隐层节点状态hj = f(xj) 进行一一对比,也就是通过函数F(hj,Hi-1) 获得目标单词yi和每个输入单词对应的对齐可能性。
1.2 注意力系数的计算
现在从上面模型中抽离出来,我们从更抽象的层面理解注意力系数。
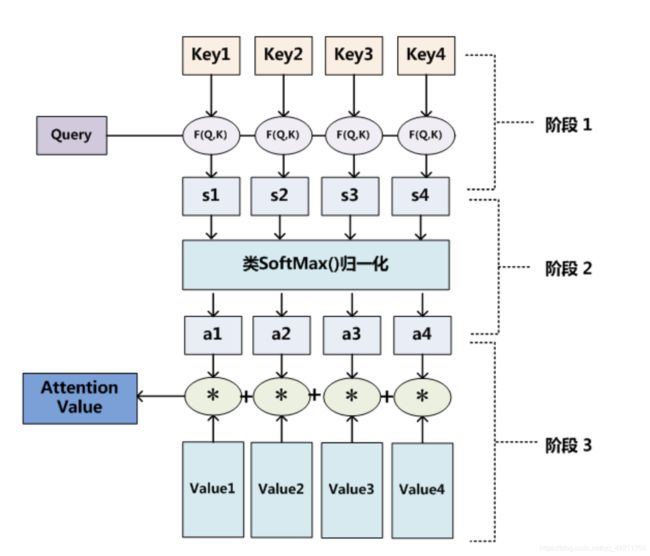
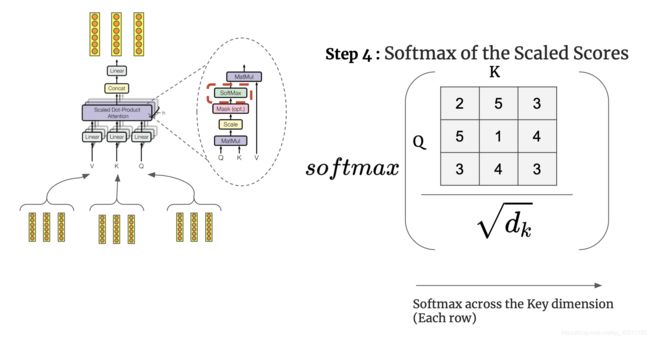
阶段1: 计算query和source的相似度,similarity可以采取点乘,cosine相似度,MLP网络等
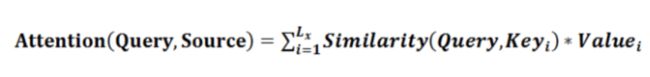

阶段2: 用softmax对similarity进行归一化处理
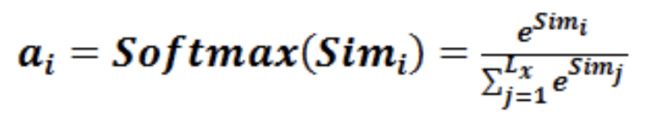
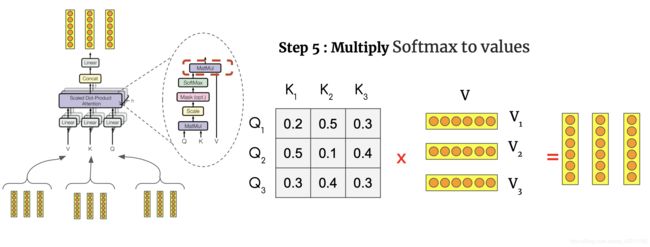
阶段3: ai * value的加权求和得到最终的注意力系数

论文Attention is all you need中多头注意力机制模型的框架和详细计算方式如下:

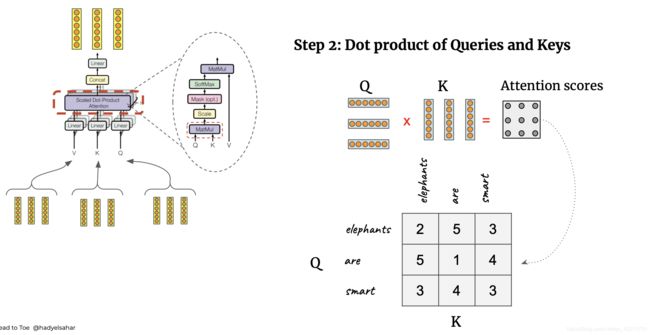
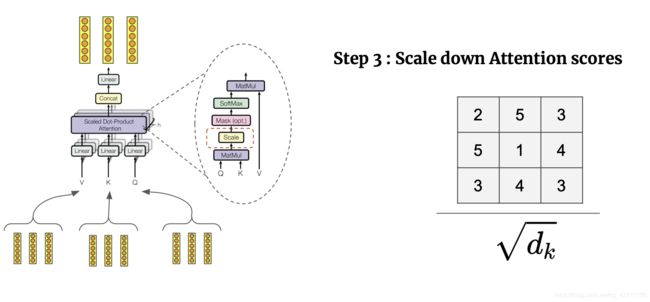
多头注意力机制将每个注意力结果拼接并且进行线性转换使得输入和输出结构对标,多头的提出能够有效稳定模型的训练,并且由于每个注意力机制关注的特征层减少,多头的计算代价和单头相似。
1.3 Transformer框架
Transformer框架延续了encoder-decoder的框架体系,具体可以分成5个步骤。

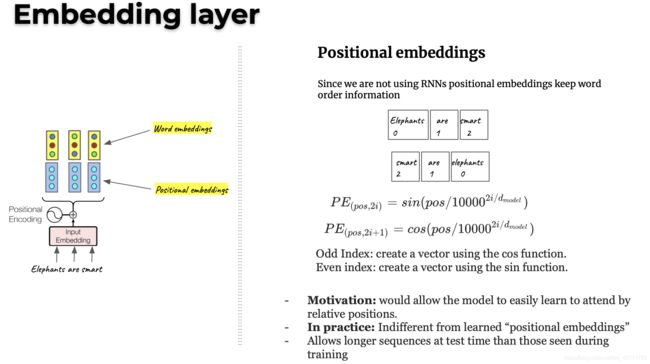
步骤1: Embedding Layer
由于我们没有使用RNN捕捉序列位置信息,所以用position embeddings就显得非常重要。图中右边公式表示position embeddings的计算,pos表示单词位置index,i表示特征维度index。又因为cos和sin的计算可加性,位置p+k的向量可以表示成位置p的向量的线性变换,这提供了表达相对位置信息的可能性。
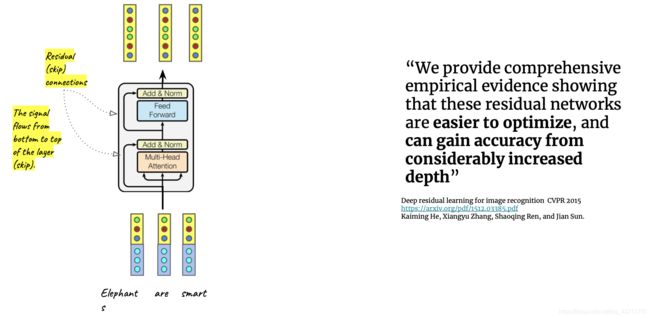
步骤2: Enceoder Layer
Encoder Layer包括两个sublayers,第一个sublayer是多头注意力层,用来计算输入的attention,第二个sublayers是全连接层。论文作者也提到模拟残差网络能让模型在深度模型中取得更好的准确率。
步骤3: Decoder Self-attention Layer
这一层计算生成结果的self-attention,但是由于是生成过程,也就是在生成时刻i的结果时,只能看到时刻i-1以前的生成结果,所以需要做mask,也就是遮挡住i时刻之后的结果。

步骤4: Decoder-Encoder Attention
将encoder的结果作为Key和Value,将decoder的结果作为Query,计算Attention。
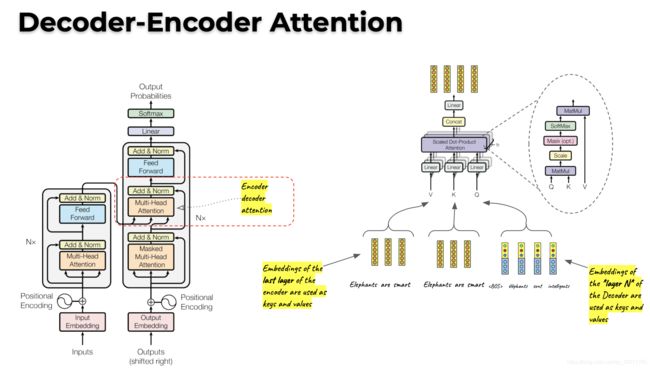
步骤5: Output Layer
经过线性变化和softmax层输出单词概率进行预测,与target的sentence进行对比计算loss

2 图注意力网络(GAT)和attention计算
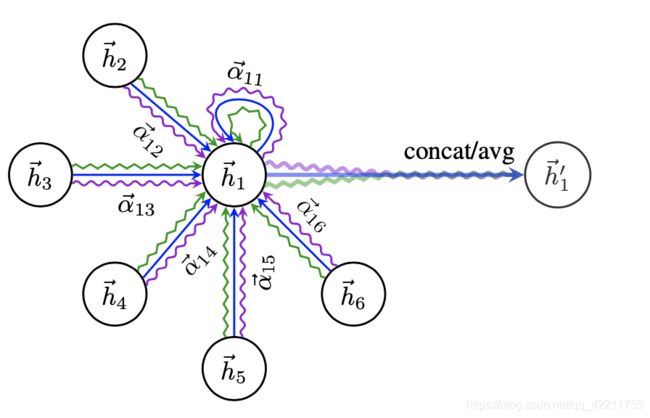
GAT的关键在于Graph Attentional Layer,层的输入输出为:
2.1 输入输出

2.2 共享线性变化
在计算attention之前,对于所有节点做共享线性变换以获得特征增强,也就是将输入特征转换为高维特征。
2.3 self-attention机制

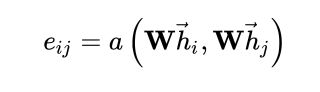
使用Masked graph attention,只计算节点附近的一阶邻接节点的注意力参数
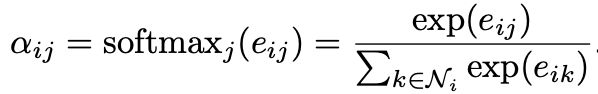
a是一个单层前馈神经网络,结合LeakyReLU可以得到
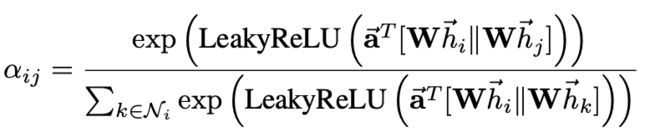
为了稳定学习过程,采取多头注意力机制,采取多个独立的注意力机制得到
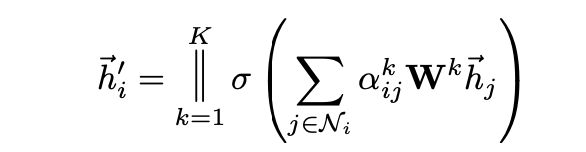
在最后一层平均后非线性化得到

Graph Attentional Layer的图示如下:
3 DGL实现图注意力网络和实验结果
DGL是亚马逊推出的图神经深度学习框架,个人觉得document和tutorial写得相当不错。
DGL Tutorials and Documentation: https://docs.dgl.ai/index.html
DGL Github: https://github.com/dmlc/dgl
用DGL实现图注意力网络非常简便,具体代码可以见我的gitee仓库:
https://gitee.com/echochen1997/gat_ppi/tree/master
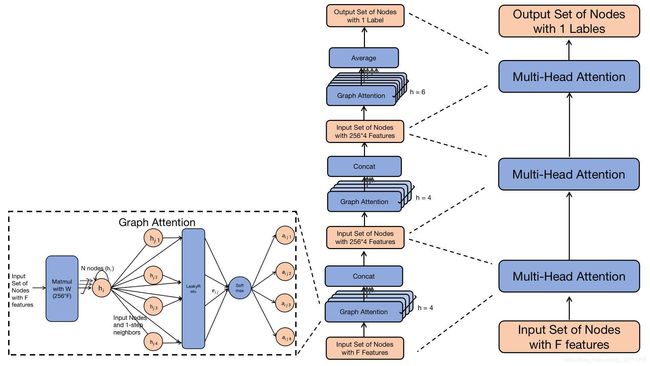
具体模型的框架图如下,包括三层多头注意力层。
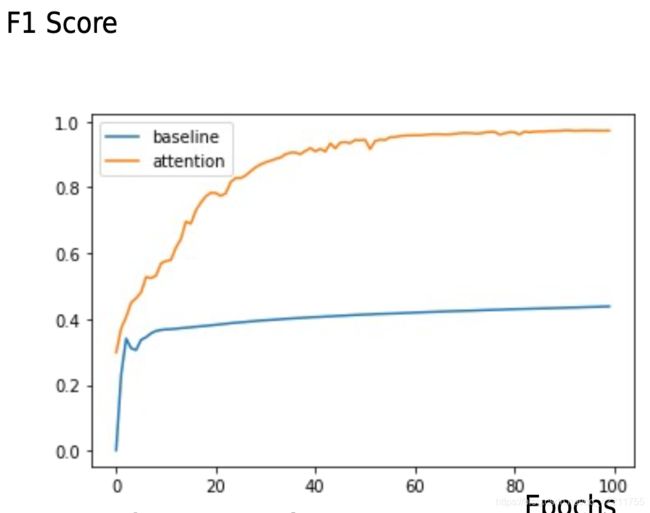
经过100个epoch之后,和baseline对比效果如下:
Reference:
- 深度学习中的注意力模型(2017版)知乎:张俊林 https://zhuanlan.zhihu.com/p/37601161 非常详细且好理解的attention机制讲解,极力建议看原文
- 细讲 | Attention Is All You Need
https://mp.weixin.qq.com/s/RLxWevVWHXgX-UcoxDS70w
Transformer 讲解详细,后附有生动例子,建议读原文 - Attention is all you need 论文
- 全面理解Graph Attention Networks 知乎:老和山下小菜狗
https://zhuanlan.zhihu.com/p/296587158 - Graph Attention Networks 论文
- NLP老师PPT 作者Hady Elsahar
- ADL HW3 助教的instruction和baseline代码