深度学习pytorch框架--卷积神经网络
卷积神经网络(CNN)
-
- CNN解决了什么问题
- 人类的视觉原理
- 卷积神经网络-CNN 的基本原理
-
- 卷积--局部特征提取
- 池化层(下采样)——数据降维,避免过拟合
- 全连接层——输出结果
- 使用pytorch 实现卷积神经网络--(MNIST实战)
该博客仅用于记录学习过程,避免忘记方便以后复习
卷积神经网络最擅长的就是进行图像处理问题,它受到人类视觉神经系统的启发。
CNN具有两大特点:
1、能够有效的将大数据量的图片降维成小数据量
2、能够有效的保留图片特征,符合图片处理的原则
目前 CNN 已经得到了广泛的应用,比如:人脸识别、自动驾驶、美图秀秀、安防等很多领域。
CNN解决了什么问题
在CNN出现之前我们进行图像处理时主要会遇到以下两大难题:
1、数据量太过庞大,从而使得处理成本高、效率低。
2、图像在数字化的过程中很难保留原有的特征,导致图像处理的准确率不高
下面对两个问题进行详细讲解
数据量太过庞大
每一个图像都是由像素点构成、像素点由颜色构成。现在随随便便一张图片都是 1000×1000 像素以上的, 每个像素都有RGB 3个参数来表示颜色信息。如果我们要对该图像进行数据化处理,就需要处理1000×1000×3 100万的数据参数。
这么大量的数据处理起来是非常消耗资源的,而且这只是一张不算太大的图片!所以卷积神经网络首先要解决的问题就是要将大量数据参数降维至少量参数。更重要的是:我们在大部分场景下,降维并不会影响结果。比如1000像素的图片缩小成200像素,并不影响肉眼认出来图片中是一只猫还是一只狗,机器也是如此。
保留图像特征
图片数字化的传统方式我们简化一下,就类似下图的过程:
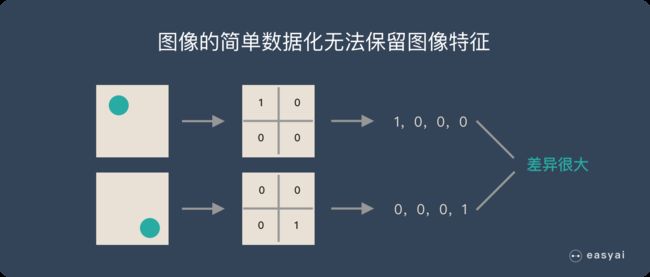
假如有圆形是1,没有圆形是0,那么圆形的位置不同就会产生完全不同的数据表达。但是从视觉的角度来看,图像的内容(本质)并没有发生变化,只是位置发生了变化。
所以当我们移动图像中的物体,用传统的方式的得出来的参数会差异很大!这是不符合图像处理的要求的。
而 CNN 解决了这个问题,他用类似视觉的方式保留了图像的特征,当图像做翻转,旋转或者变换位置时,它也能有效的识别出来是类似的图像。
人类的视觉原理
深度学习的许多研究成果,离不开对大脑认知原理的研究,尤其是视觉原理的研究。
人类的视觉原理如下:从原始信号摄入开始(瞳孔摄入像素 Pixels),接着做初步处理(大脑皮层某些细胞发现边缘和方向),然后抽象(大脑判定,眼前的物体的形状,是圆形的),然后进一步抽象(大脑进一步判定该物体是只气球)。下面是人脑进行人脸识别的一个示例:
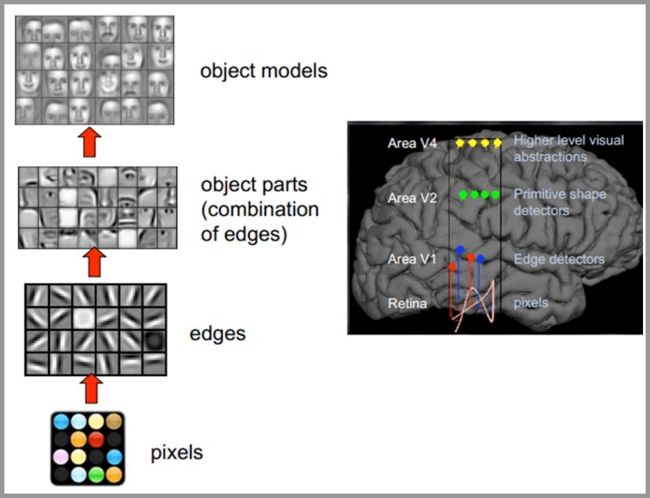
对于不同的物体,人类视觉也是通过这样逐层分级,来进行认知的:

可以很清楚的看到,不同图像的底层特征都是类似的,即各种边缘,越往上,越能提取出此类物体的一些特征(轮子、眼睛、躯干等),到最上层,不同的高级特征最终组合成相应的图像,从而能够让人类准确的区分不同的物体。
所以我们可以模仿人类大脑的这个特点,构造多层的神经网络,较低层的识别初级的图像特征,若干底层特征组成更上一层特征,最终通过多个层级的组合,最终在顶层做出分类。
卷积神经网络-CNN 的基本原理
典型的CNN有以下三层结构组成
1、卷积层
2、池化层
3、全连接层
简单来说,卷积层用于提取图像的局部特征、池化层用于数据降维、全连接层类似于普通神经网络,用来输出想要的结果。
卷积–局部特征提取
卷积层可以说是 CNN 架构中最重要的步骤之一。基本而言,卷积是一种线性的、平移不变性的运算,其由在输入信号上执行局部加权的组合构成。
在卷积层中有几个重要的概念:
1、local receptive fields(感受野)
2、shared weights(共享权值)
假设输入的是一个 5×5 的的二维神经元,我们定义3×3 的 一个 local receptive fields(感受视野),即 隐藏层的神经元与输入 层的5×5个神经元相连。
可类似看作:隐藏层中的神经元具有一个固定大小的感受视野去感受上一层的部分特征。但是感受视野比较小,只能看到上一层的部分特征,上一层的其他特征可以通过平移感受视野来得到。
设移动的步长为1:从左到右扫描,每次移动 1 格,扫描完之后,再向下移动一格,再次从左到右扫描。具体过程请看:

这个过程我们可以理解为我们使用一个过滤器(卷积核)来过滤图像的各个小区域,从而得到这些小区域的特征值。不同的卷积核用来萃取出图片当中的一些特征(ex:形状),就像人的大脑在判断这个图片是什么东西也是根据形状来推测。如下图所示,该卷积核用来提取图片的边界:
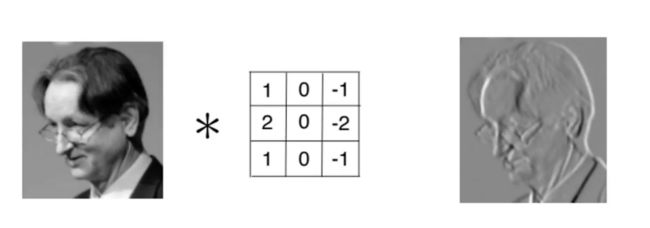
可看出卷积层的神经元是只与前一层的部分神经元节点相连,每一条相连的线对应一个权重w。一个感受视野带有一个卷积核,我们将感受视野中的权重w矩阵称为卷积核,将感受视野对输入的扫描间隔称为步长(stride);
对下一层的所有神经元来说,它们从不同的位置去探测了上一层神经元的特征。我们将通过一个带有卷积核的感受视野扫描生成的下一层神经元矩阵称为一个feature map (特征映射图,上图右侧矩阵即为特征映射图)。
在同一个特征映射图上的神经元使用的卷积核是相同的,因此这些神经元共享权值,共享卷积核中的权值和附带的偏移。
在具体应用中,往往有多个卷积核,可以认为,每个卷积核代表了一种图像模式,如果某个图像块与此卷积核卷积出的值大,则认为此图像块十分接近于此卷积核。如果我们设计了6个卷积核,可以理解:我们认为这个图像上有6种底层纹理模式,也就是我们用6中基础模式就能描绘出一副图像。以下就是25种不同的卷积核的示例:
总结:卷积层通过卷积核的过滤提取出图片中局部的特征,跟上面提到的人类视觉的特征提取类似。
池化层(下采样)——数据降维,避免过拟合
卷积层做完卷积后,通常会在卷积后做一个池化(pooling)层。常用的池化计算包括最大池化(max-pooling)、平均池化(mean-pooling)、随机池化(stochastic pooling)等。
池化层简单说就是下采样,他可以大大降低数据的维度。其过程如下
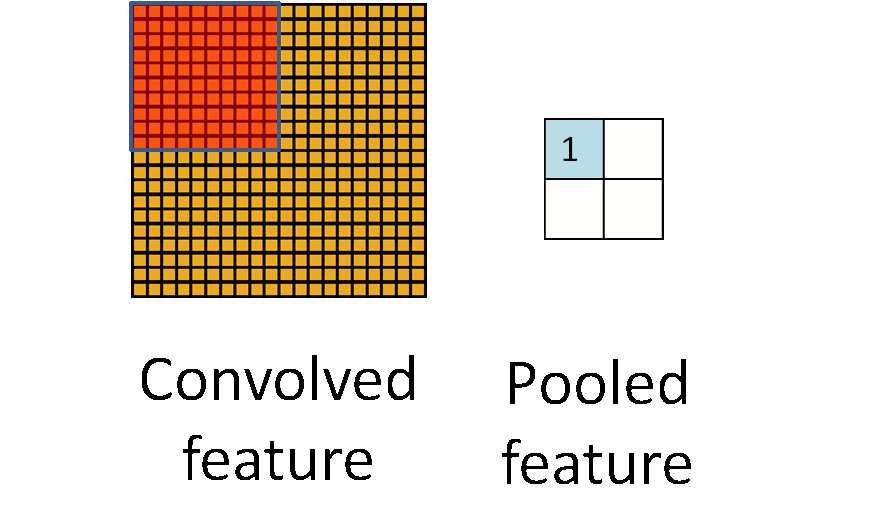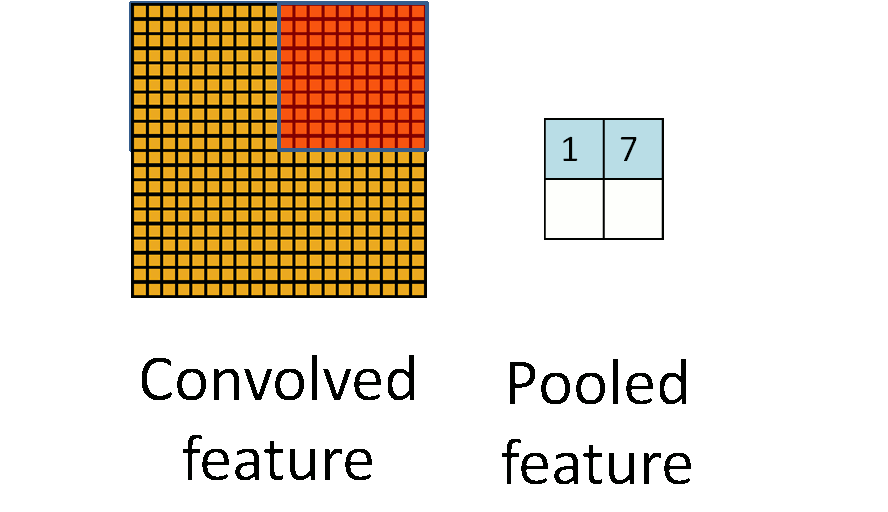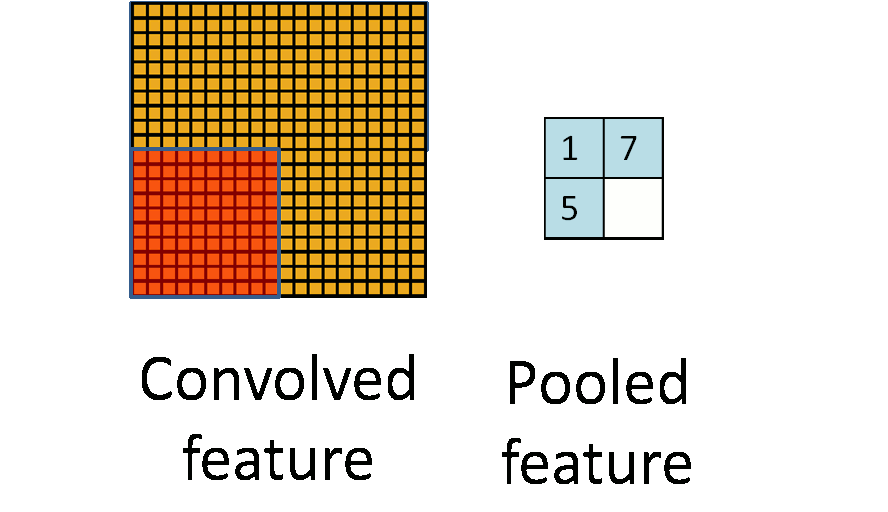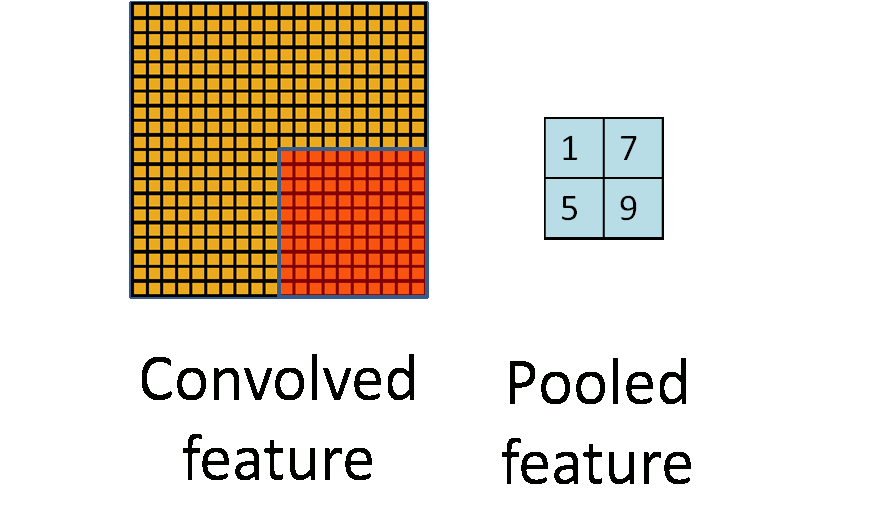
上图中,我们可以看到,原始图片是20×20的,我们对其进行下采样,采样窗口为10×10,最终将其下采样成为一个2×2大小的特征图。之所以这么做的原因,是因为即使做完了卷积,图像仍然很大(因为卷积核比较小),所以为了降低数据维度,就进行下采样。
总结:池化层相比卷积层可以更有效的降低数据维度,这么做不但可以大大减少运算量,还可以有效的避免过拟合。
全连接层——输出结果
这个部分就是最后一步了,经过卷积层和池化层处理过的数据输入到全连接层,得到最终想要的结果,中起到 “分类器” 的作用。经过卷积层和池化层降维过的数据,全连接层才能”跑得动”,不然数据量太大,计算成本高,效率低下。
典型的 CNN 并非只是上面提到的3层结构,而是多层结构,例如 LeNet-5 的结构就如下图所示:

使用pytorch 实现卷积神经网络–(MNIST实战)
import time
import torch.nn as nn
import matplotlib.pyplot as plt
from torchvision import transforms
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
from torch import optim
# 定义batch, 即一次训练的样本量大小
train_batch_size = 128
test_batch_size = 128
# 定义图像数据转换操作
# transforms.Compose用于把多个步骤整合到一起
# transforms.ToTensor能够把灰度范围从0-255变换到0-1之间,而后面的transform.Normalize()则把0-1变换到(-1,1).
# mnist是灰度图,应设置为单通道,所以Normalize的均值和标准差都是[0.5]
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize([0.5], [0.5])])
# 下载mnist数据集,若已下载,可将download定义为False
data_train = MNIST('./data', train=True, transform=transform, target_transform=None, download=True)
data_test = MNIST('./data', train=True, transform=transform, target_transform=None, download=True)
train_loader = DataLoader(data_train, batch_size=train_batch_size, shuffle=True)
test_loader = DataLoader(data_test, batch_size=test_batch_size, shuffle=True)
# 可视化数据,该步骤可以忽略
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
plt.figure(figsize=(9, 9))
for i in range(9):
plt.subplot(3, 3, i + 1)
plt.title("Ground Truth:{}".format(example_targets[i]))
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.xticks([])
plt.yticks([])
plt.show()
# 构建模型
class CNN_net(nn.Module):
def __init__(self):
super(CNN_net, self).__init__()
# 卷积层
self.conv1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=(3, 3), stride=(1, 1), padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
# 全连接层
self.dense = nn.Sequential(
nn.Linear(7 * 7 * 32, 128),
nn.ReLU(),
nn.Dropout(p=0.5), # 缓解过拟合,一定程度上正则化
nn.Linear(128, 10)
)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1) # flatten张量铺平,便于全连接层的接收
return self.dense(x)
model = CNN_net()
print(model)
# 设置训练参数
learn_rate = 1e-3
epoches = 10
# 损失函数
criterian = nn.CrossEntropyLoss()
# 优化用SGD
opt = optim.SGD(model.parameters(), lr=learn_rate, momentum=0.95)
# 训练
# 开始训练 先定义存储损失函数和准确率的数组
train_losses = []
train_acces = []
# 测试
eval_losses = []
eval_acces = []
print("start training...")
# 记录训练开始时刻
start_time = time.time()
for epoch in range(epoches):
# 训练集
train_loss = 0
train_acc = 0
# 将模型设置为训练模式
model.train()
for img, label in train_loader:
out = model(img) # 返回每个类别的概率
loss = criterian(out, label) # 计算损失
opt.zero_grad() # 模型梯度参数清零
loss.backward() # 反向传播计算完成误差
opt.step() # 更新参数
train_loss += loss # 累计误差
_, pred = out.max(1) # 返回最大概率的数字
num_correct = (pred == label).sum().item() # 记录标签正确的个数
acc = num_correct / img.shape[0] # 计算准确率
train_acc += acc
# 取平均存入
train_losses.append(train_loss / len(train_loader))
train_acces.append(train_acc / len(train_loader))
# 测试集
eval_loss = 0
eval_acc = 0
# 将模型设置为测试模式
model.eval()
for img, label in test_loader:
out = model(img)
loss = criterian(out, label)
opt.zero_grad()
loss.backward()
opt.step()
eval_loss += loss
_, pred = out.max(1)
num_correct = (pred == label).sum().item()
acc = num_correct / img.shape[0]
eval_acc += acc
eval_losses.append(eval_loss / len(test_loader))
eval_acces.append(eval_acc / len(test_loader))
# 输出效果
print('epoch:{},Train Loss:{:.4f},Train Acc:{:.4f},'
'Test Loss:{:.4f},Test Acc:{:.4f}'
.format(epoch, train_loss / len(train_loader),
train_acc / len(train_loader),
eval_loss / len(test_loader),
eval_acc / len(test_loader)))
# 输出时长
stop_time = time.time()
print("time is:{:.4f}s".format(stop_time - start_time))
print("end training.")
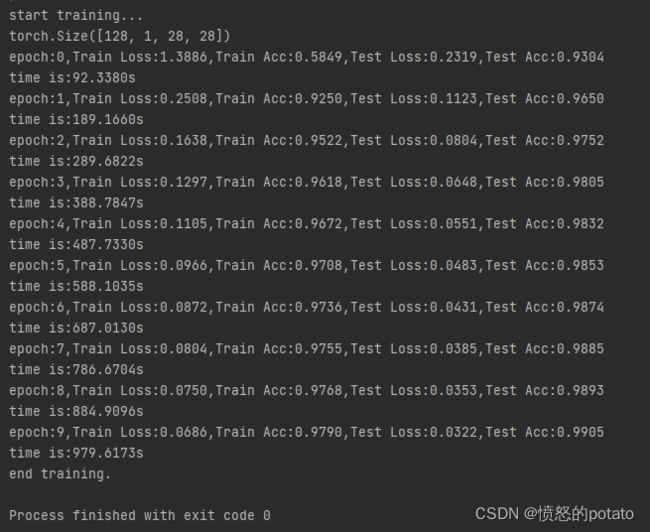
运行结果如下: