Yolov5从入门到放弃(一)---yolov5网络架构
文章目录
- YoloV5网络架构
-
- 总体架构
-
- 代码部分
-
- FOCUS
- 池化
- PANet
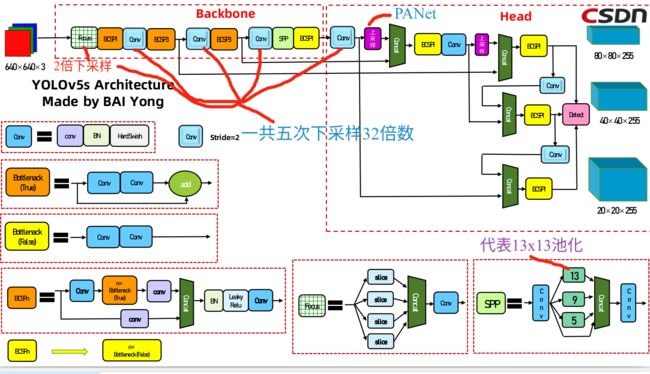
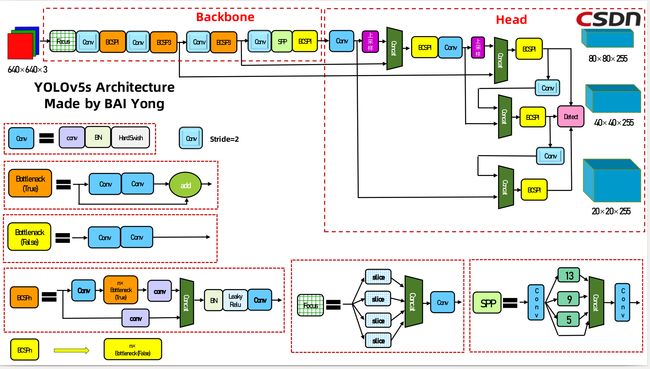
YoloV5网络架构
总体架构
- Backbone(主体) : Focus, BottleneckCSP, CSP
- Head : PANet + Dectect (Yolov3/Yolov4 Head)
代码部分
# parameters
nc: 80 # number of classes 类别数
depth_multiple: 0.33 # model depth multiple 控制模型的深度 (BottleneckCSP数)
width_multiple: 0.50 # layer channel multiple 控制Conv通道个数 (卷积核数量)
# depth_multiple表示BottleneckCSP模块的层缩放因子,将所有的BottleneckCSP模块的Bottleneck乘上该参数得到最终个数。
# width_multiple表示卷积通道的缩放因子,就是将配置里面的backbone和head部分有关Conv通道的设置,全部乘以该系数。
# 通过这两个参数就可以实现不同复杂度的模型设计。
# anchors
anchors: # 先验框 或者 锚框
- [10,13, 16,30, 33,23] # P3/8 代表stride=8 也就是8倍下采样尺度后先验框的大小 宽度是10 长度是 13
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
# from列参数:当前模块输入来自哪一层输出;-1 代表是从上一层获得的输入
# number列参数:本模块重复次数;1表示只有一个,3表示有三个相同的模块
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4; 128表示128个卷积核,3表示3×3的卷积核,2表示步长为2。
[-1, 3, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, BottleneckCSP, [1024, False]], # 9
]
# YOLOv5 head
# 作者没有分neck模块,所以head部分包含了PANet+Detect部分
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
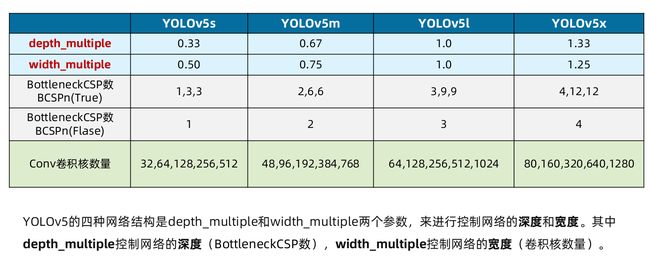
个数x ___multiple 取整就是最终个数
网络的不断加深(使用残差组件的多少),也在不断增加网络特征提取和特征融合的能力。
卷积核数量的多少,也直接影响卷积后特征图的第三维度,即厚度,大白这里表示为网络的宽度。
FOCUS
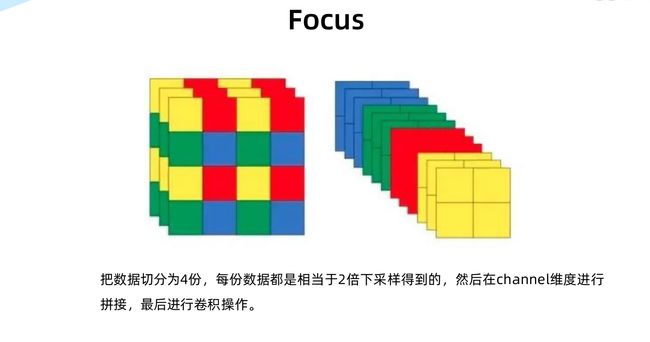
也就相当于下采样两倍,数量扩为原来的四倍,可以减少浮点运算量但是不会提升速度,不影响mAP
[b,c,h,w]------->[b,c*4,h//2,w//2]
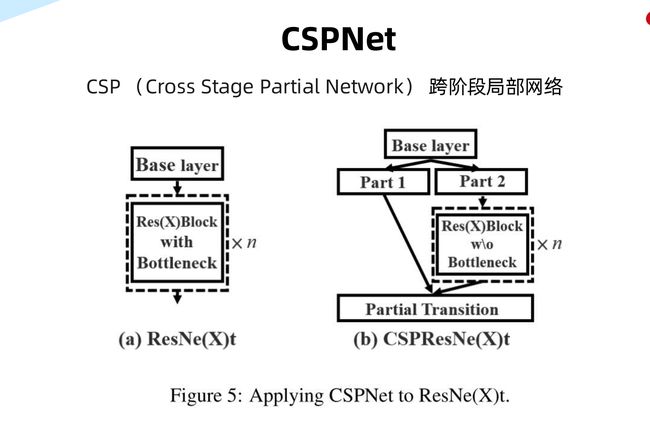
其中Res Block就是残差模块
池化
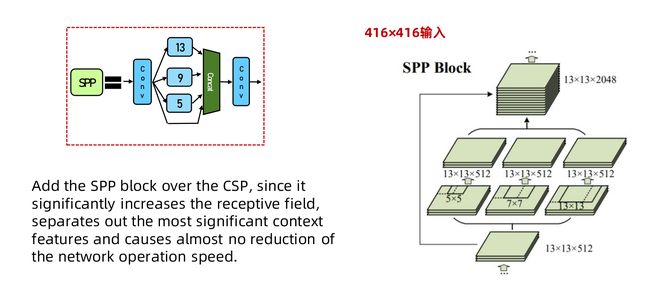
可以增大感受野,提取出最重要的特征但是不会减少运算量
上面的池化操作的经过填充以后的所以特征图并w h没有减小
PANet
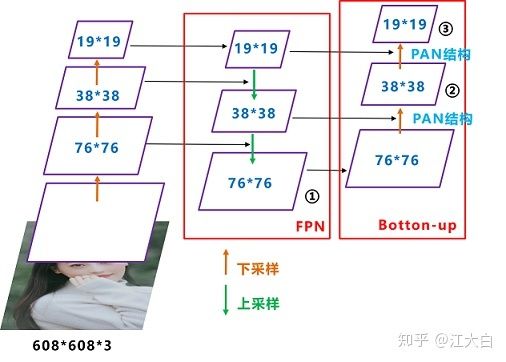
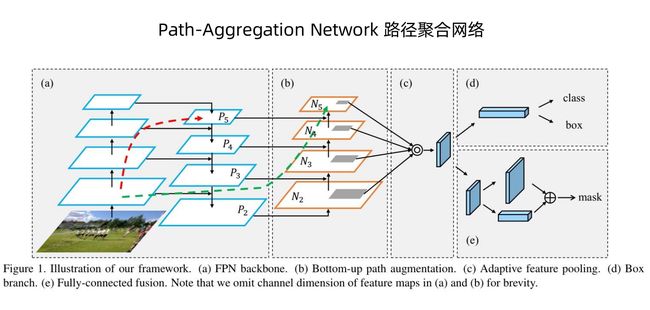
也就是当图片只有下采样的时候,原来的图片不好和下采样后的图片进行特征融合,为了解决这个问题就有了另外一条线绿线,这样进行上采样以后,特征图就能在相同尺度上进行融合,最后进行拼接
所以得到的信息就更加的丰富