mysql牛客刷题(非技术快速入门)
文章目录
- 他人总结
- 牛客SQL入门篇
- 简单处理查询结果
-
- SQL3 查询结果去重
- SQL4 查询结果限制返回行数
- 基础排序
-
- SQL36 查找后排序
- SQL37 查找后多列排序
- 基础操作符
-
- SQL9 查找除复旦大学的用户信息
- 高级操作符
-
- SQL13 Where in 和Not in
- SQL14 操作符混合运用
- SQL15 查看学校名称中含北京的用户
- 计算函数
-
- SQL17 计算男生人数以及平均GPA
- 分组查询
-
- SQL18 分组计算练习题
- SQL19 分组过滤练习题
- SQL20 分组排序练习题
- 链接查询
-
- SQL 22统计每个学校的用户平均答题数
- SQL23 统计每个学校各难度的用户平均刷题数
- SQL24 统计每个用户的平均刷题数
- 组合查询
-
- SQL25 查找山东大学或者性别为男生的信息
- 条件函数
-
- SQL26 计算25岁以上和以下的用户数量
- SQL27查看不同年龄段的用户明细
- 日期函数
-
- SQL28 计算用户8月每天的练题数量
- SQL29 计算用户的平均次日留存率
- 文本函数
-
- SQL30 统计每种性别的人数
- SQL32 截取出年龄
- SQL31 提取博客URL中的用户名
- 窗口函数
-
- SQL33 找出每个学校GPA最低的同学
- 综合练习
-
- SQL34 统计复旦用户8月练题情况
- SQL35 浙大不同难度题目的正确率
- SQL39 21年8月份练题总数
他人总结
知识点总结
师兄推荐的非常不错的课程,适用于小白
牛客SQL入门篇

简单处理查询结果
SQL3 查询结果去重
两种方法
方法一、
distinct去重,放在列的前面使用
select distinct university from user_profile
方法二、
以分组来筛选出去重的结果
SELECT university from user_profile GROUP BY university;
SQL4 查询结果限制返回行数
使用LIMIT限制结果集
LIMIT 子句可以被用于强制 SELECT 语句返回指定的记录数。
LIMIT 接受一个或两个数字参数。参数必须是一个整数常量。
如果只给定一个参数,它表示返回最大的记录行数目。
如果给定两个参数,第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目。
为了检索从某一个偏移量到记录集的结束所有的记录行,可以指定第二个参数为 -1。
初始记录行的偏移量是 0(而不是 1)。
例5.检索记录行 6-10
SELECT * FROM table LIMIT 5,5
例6.检索记录行 11-last
/为了检索从某一个偏移量到记录集的结束所有的记录行,可以指定第二个参数为 -1:
SELECT * FROM table LIMIT 10,-1
例7.检索前 5 个记录行
SELECT * FROM table LIMIT 5
基础排序
SQL36 查找后排序
知识
对查询结果进行排序
可对查询结果进行排序。
排序子句为:
ORDER BY <列名> [ASC | DESC ]
[,<列名> … ]
说明:按<列名>进行升序(ASC)或降序(DESC)排序,还可以按照别名或序 号进行排序。
例9.将学生按班号的升序排序。
SELECT * FROM 学生表
ORDER BY 班号
例10.查询选修了“M01F011 ”号课程的学生的学号及其成绩,查询结果按成绩降序排列。
SELECT 学号,成绩 FROM 成绩表
WHERE 课程号='M01F011'
ORDER BY 成绩 DESC
例11.查询全体学生的信息,查询结果按班号升序排列,同班的学生按出生年份降序排列。
SELECT * FROM 学生表
ORDER BY 班号, year(出生日期) DESC
SELECT 班号, year(出生日期) 出生年份
FROM 学生表
ORDER BY 班号,出生年份 DESC
SELECT device_id,age FROM user_profile ORDER BY age ASC
SQL37 查找后多列排序
order by 进行排序
SELECT device_id,gpa,age from user_profile order by gpa,age;默认以升序排列
SELECT device_id,gpa,age from user_profile order by gpa,age asc;
SELECT device_id,gpa,age from user_profile order by gpa asc,age asc;
基础操作符
SQL9 查找除复旦大学的用户信息
where就行啊 != 代表不等于
select device_id, gender, age, university from user_profile where university != '复旦大学'
高级操作符
SQL13 Where in 和Not in
这主要是用标题的两个关键字中的一个 in(字段…) 包含条件的字段,not in(字段…) 除字段以外的
推荐用in ,增加复用性
select device_id,gender,age,university,gpa from user_profile
where university in('北京大学','复旦大学','山东大学');
有些小伙伴写测试的时候,可能想要去写not in; 单个测试样例可以,但是后面的测试样例过多,所以不推荐使用。
牛客网这个题不能用not in,因为数据库中存在清华大学你懂得。
SQL14 操作符混合运用
and的优先级大于or 我这里写大括号方便区分,表示两个条件或两个条件 可以省略括号
select device_id,gender,age,university,gpa from user_profile
where (university='山东大学' and gpa>3.5 )
or (university="复旦大学" and gpa>3.8);
也可以这样写
select device_id,gender,age,university,gpa
from user_profile
where university='山东大学' and gpa>3.5 or university='复旦大学' and gpa>3.8
SQL15 查看学校名称中含北京的用户
一般形式为:
列名 [NOT ] LIKE
匹配串中可包含如下四种通配符:
_:匹配任意一个字符;
%:匹配0个或多个字符;
[ ]:匹配[ ]中的任意一个字符(若要比较的字符是连续的,则可以用连字符“-”表 达 );
[^ ]:不匹配[ ]中的任意一个字符。
例23.查询学生表中姓‘张’的学生的详细信息。
SELECT * FROM 学生表 WHERE 姓名 LIKE ‘张%’
例24.查询姓“张”且名字是3个字的学生姓名。
SELECT * FROM 学生表 WHERE 姓名 LIKE '张__’
如果把姓名列的类型改为nchar(20),在SQL Server 2012中执行没有结果。原因是姓名列的类型是char(20),当姓名少于20个汉字时,系统在存储这些数据时自动在后边补空格,空格作为一个字符,也参加LIKE的比较。可以用rtrim()去掉右空格。
SELECT * FROM 学生表 WHERE rtrim(姓名) LIKE '张__'
例25.查询学生表中姓‘张’、姓‘李’和姓‘刘’的学生的情况。
SELECT * FROM 学生表 WHERE 姓名 LIKE '[张李刘]%’
例26.查询学生表表中名字的第2个字为“小”或“大”的学生的姓名和学号。
SELECT 姓名,学号 FROM 学生表 WHERE 姓名 LIKE '_[小大]%'
例27.查询学生表中所有不姓“刘”的学生。
SELECT 姓名 FROM 学生 WHERE 姓名 NOT LIKE '刘%’
例28.从学生表表中查询学号的最后一位不是2、3、5的学生信息。
SELECT * FROM 学生表 WHERE 学号 LIKE '%[^235]'
select
device_id,
age,
university
from user_profile
WHERE
university like '%北京%'
考点 like 相似
like '%北京%'列名包括北京的字样
like ‘北京%’ 列名北京开头
like ‘%北京’ 列名北京结尾
计算函数
SQL16 查找GPA最高值
题意明确:
复旦大学学生gpa最高值
问题分解:
限定条件:复旦大学学生,university=‘复旦大学’;
gpa最高值:max(gpa);当然也可以按gpa降序排序,取第一名
# 方法1
# select max(gpa) as gpa
# from user_profile
# where university='复旦大学';
# 方法2
select gpa
from user_profile
where university='复旦大学'
order by gpa desc limit 1
SQL17 计算男生人数以及平均GPA
题意明确:题目要求得到『男性用户有多少人』以及『他们的平均gpa是多少』。
问题分解:
限定条件为 男性用户;
有多少人,明显是计数,count函数;
平均gpa,求平均值用avg函数;
细节问题:根据输出示例,有两个问题需要注意:
表头重命名,用as语法
浮点数的平均值可能小数点位数很多,按照示例保存一位小数,用round函数
因此完整代码呼之欲出:
select
count(gender) as male_num,
round(avg(gpa), 1) as avg_gpa
from user_profile where gender="male";
分组查询
SQL18 分组计算练习题
现在运营想要对每个学校不同性别的用户活跃情况和发帖数量进行分析,请分别计算出每个学校每种性别的用户数、30天内平均活跃天数和平均发帖数量。
难点:用户数。分组后直接count相应性别即可
SELECT gender,university,COUNT(gender) as user_num,avg(active_days_within_30)as avg_active_days,
avg(question_cnt)as question_cnt from user_profile
GROUP by gender,university
SQL19 分组过滤练习题
题意明确:
取出平均发贴数低于5的学校或平均回帖数小于20的学校
问题分解:
限定条件:平均发贴数低于5或平均回帖数小于20的学校,avg(question_cnt)<5 or avg(answer_cnt)<20,
聚合函数结果作为筛选条件时,
不能用where,而是用having语法,配合重命名即可;
**按学校输出:**需要对每个学校统计其平均发贴数和平均回帖数,
因此group by university
where的搜索条件是在执行语句进行分组之前应用
having的搜索条件是在分组条件后执行的
如果where和having一起用时,where会先执行,having后执行
SELECT university,avg(question_cnt) as avg_question_cnt,
avg(answer_cnt) as avg_answer_cnt
from user_profile group by university
having avg_question_cnt<5 or avg_answer_cnt<20;
SQL20 分组排序练习题
group by 比order by先执行
默认升序
SELECT university,avg(question_cnt) as avg_question_cnt
from user_profile
group by university
order by avg_question_cnt;
链接查询
SQL 22统计每个学校的用户平均答题数
思路:
第一个,每个学校,涉及利用group by 分组实现
第二,用户平均答题数=所有用户答题总数/所有用户数,分母所有用户涉及
count(distinct )对登陆设备账号进行去重(一个账号可以多次登陆)分子所有用户答题总数涉及count()对question_id进行计数,不需要剔重。
第三,需要对两个表进行联合from 表 join 表 on 连接条件
內连接
SELECT ue.university,COUNT(ql.question_id)/COUNT(DISTINCT ql.device_id) as ave_answer_cnt
FROM question_practice_detail as ql JOIN user_profile as ue
ON ql.device_id = ue.device_id
GROUP BY ue.university;
select查询,相对来说更简单
select 查询条件
from 表1,表2,表3
where 将三个表联合在一起的查询的条件
SELECT university,
COUNT(q.question_id)/COUNT(DISTINCT(q.device_id)) AS avg_answer_cnt
FROM user_profile as u,question_practice_detailAS q
WHERE u.device_id = q.device_id
GROUP BY university;
SQL23 统计每个学校各难度的用户平均刷题数
三张表联合查询
由于结果需要三个表中的多列数据,因此进行关联
注:由于计算平均答题数的数据均来源于question_practice_detail,因此在联结时候应保全该表,以该表为本体联结另外两张表
关联:
方法一:三表join
question_practice_detail AS q
LEFT JOIN
user_profile AS u
ON u.device_id=q.device_id
INNER JOIN question_detail AS qd
ON q.question_id=qd.question_id
# 其实三表联查,在互联网项目中,是不合适的,因为其性能很差,追求性能,可以通过前期的表设计或者其他代码逻辑维护表的数据
# 我们通过观察发现,这道题,跟前面一道,加入了另一张表的查询。question_practice_detail这个表拥有其他两个表相同的数据
# 通过关系连接表与表中间关系字段。进行两次的内连接,或者左外连接。
SELECT u.university, qd.difficult_level,COUNT(q.question_id) / COUNT(DISTINCT q.device_id) # 获取三个表的字段数据
from
question_practice_detail q # 通过question_practice_detail此表,进行连接两张表
JOIN
user_profile u # 第一张表
ON
q.device_id =u.device_id # 条件
JOIN # 第二张表
question_detail qd
ON
q.question_id = qd.question_id # 条件
GROUP BY
university,difficult_level; # 进行分组,每个学校,用户不同难度,两个组
方法二:直接select…where 三表join效率不高,根据所需要的数据,查看三个表,寻找其中的联系,直接通过where筛选出来(这个方法好)
select u.university, qd.difficult_level, count(qpd.question_id) / count(distinct(qpd.device_id)) as avg_answer_cnt
FROM
user_profile as u,
question_practice_detail as qpd,
question_detail as qd
WHERE
qpd.device_id = u.device_id and
qpd.question_id = qd.question_id
group by u.university, qd.difficult_level
SQL24 统计每个用户的平均刷题数
select查询,相对来说更简单
select 查询条件
from 表1,表2,表3
where 将三个表联合在一起的查询的条件
SELECT
t1.university,
t3.difficult_level,
COUNT(t2.question_id) / COUNT(DISTINCT(t2.device_id)) as avg_answer_cnt
from
user_profile as t1,
question_practice_detail as t2,
question_detail as t3
WHERE
t1.university = '山东大学'
and t1.device_id = t2.device_id
and t2.question_id = t3.question_id
GROUP BY
t3.difficult_level;
join查询
SELECT t1.university,
t3.difficult_level,
COUNT(t2.result) / COUNT(DISTINCT t2.device_id) AS avg_answer_cnt
FROM question_practice_detail AS t2
LEFT JOIN user_profile AS t1
ON t2.device_id = t1.device_id
LEFT JOIN question_detail AS t3
ON t2.question_id = t3.question_id
GROUP BY t1.university, t3.difficult_level
HAVING t1.university = '山东大学';
组合查询
SQL25 查找山东大学或者性别为男生的信息
跟where university=‘山东大学’ or gender=‘male’ 有啥区别
输入结果去重了
需要不去重
要用union all,分别去查满足条件1的和满足条件2的,然后合在一起不去重
select
device_id, gender, age, gpa
from user_profile
where university='山东大学'
union all
select
device_id, gender, age, gpa
from user_profile
where gender='male'
条件函数
SQL26 计算25岁以上和以下的用户数量
年龄划分为两段:if(age>=25, “25岁以及上”, “25岁以下”)
统计用户数量:count,每个段分别统计,用group by age_cut分组
SELECT IF(age>=25,"25岁及以上","25岁以下") AS age_cut,count(*) AS number
FROM user_profile
GROUP BY age_cut;
另一种写法建议
SELECT CASE WHEN age < 25 OR age IS NULL THEN '25岁以下'
WHEN age >= 25 THEN '25岁及以上'
END age_cut,COUNT(*)number
FROM user_profile
GROUP BY age_cut
模版
CASE
WHEN 布尔表达式1 THEN 结果表达式1
WHEN 布尔表达式2 THEN 结果表达式2 …
WHEN 布尔表达式n THEN 结果表达式n
[ ELSE 结果表达式n+1 ]
END
SQL27查看不同年龄段的用户明细
case when用法
可以使用多重if
SELECT device_id, gender,
IF (age <20, '20岁以下',
IF(age >=25, '25岁以上',
IF(age BETWEEN 20 AND 24, '20-24岁', '其他'))) AS age_cut
FROM user_profile;
不过更方便的是
case when [expr] then [result1]…else [default] end
select device_id,gender,
case
when age < 20 then '20岁以下'
when age between 20 and 24 then '20-24岁'
when age > 24 then '25岁及以上'
else '其他'
end
as age_cut
from user_profile;
日期函数
SQL28 计算用户8月每天的练题数量
题意:
2021年8月每天用户练习题目的数量
问题分解:
限定条件:2021年8月,写法有很多种,比如用year/month函数的year(date)=2021 and month(date)=8,比如用date_format函数的date_format(date, “%Y-%m”)=“202108”
每天:按天分组group by date
题目数量:count(question_id)
细节问题:
表头重命名:as
输出示例中每天的字段只取了几号,要去掉年月,用day函数即可
select
day(date) as day,
count(question_id) as question_cnt
from question_practice_detail
where month(date)=8 and year(date)=2021
group by date
SQL29 计算用户的平均次日留存率
所谓次日留存,指的是同一用户(在本题中则为同一设备,即device_id)在当天和第二天都进行刷题。注意,在这题我们不关心同一用户(设备)在这天答了什么题、答题结果如何,只关心他是否答题,因此对于这题来说存在重复的数据(如下图红框所示),需要使用 DISTINCT 去重。


因为使用的是q1左级联q2,所以q1的所有信息是显示的;而q2中只显示留存的信息,否则为null。
最后,分别统计q1.device_id 和 q2.device_id 作去重后的所有条目数和去重后的次日留存条目数,即可算出次日留存率。
表里的数据可以看作是全部第一天来刷题了的,那么我们需要构造出第二天来了的字段,因此可以考虑用left join把第二天来了的拼起来,限定第二天来了的可以用date_add(date1, interval 1 day)=date2筛选,并用device_id限定是同一个用户。
SELECT
COUNT(q2.device_id) / COUNT(q1.device_id) AS avg_ret
FROM
(SELECT DISTINCT device_id, date FROM question_practice_detail)as q1
LEFT JOIN
(SELECT DISTINCT device_id, date FROM question_practice_detail) AS q2
ON q1.device_id = q2.device_id AND q2.date = DATE_ADD(q1.date, interval 1 day)
文本函数
SQL30 统计每种性别的人数
分析题目
每种性别:
按性别分组group by gender 但是没有gender字段,需要从profile字段中截取,按字符分割后取出即可
可使用substring_index函数按特定字符串截取源字符串
substring_index函数解析
多少参赛者
count(device_id)
select
substring_index(profile,',',-1) as gender,
count(device_id) as number
from user_submit
group by gender;
SQL32 截取出年龄
select SUBSTRING_INDEX(SUBSTRING_INDEX(profile,',',3),',',-1) as age,
count(device_id) as number
from user_submit
GROUP BY age;
SQL31 提取博客URL中的用户名
SELECT device_id,
substring_index(blog_url,'/',-1) as username
from user_submit;
窗口函数
SQL33 找出每个学校GPA最低的同学
不能使用
SELECT device_id,university,min(gpa) FROM user_profile GROUP BY university; 因为学校与学生是一对多的关系,如果仅用min求出gpa最低的学生,查询结果中的id与学生不一定是对应的关系,因此此方法错误。
(1)方法一:将表a的device_id,university,gpa和表b的university,min(gpa)连接起来找。
SELECT a.device_id,a.university,a.gpa FROM user_profile a
JOIN (SELECT university,min(gpa) gpa FROM user_profile GROUP BY university) b
on a.university=b.university and a.gpa=b.gpa
ORDER BY university;
方法二:窗口函数(建议使用)没那么多屁事了
窗口函数用法
SELECT device_id,university,gpa FROM
(SELECT device_id,university,gpa,
RANK() over (PARTITION BY university ORDER BY gpa) rk FROM user_profile) a
WHERE a.rk=1;
综合练习
SQL34 统计复旦用户8月练题情况
题意明确:
复旦大学的每个用户在8月份练习的总题目数和回答正确的题目数情况
问题分解:
限定条件:需要是复旦大学的(来自表user_profile.university),8月份练习情况(来自表question_practice_detail.date)
从date中取month:用month函数即可;
总题目:count(question_id)
正确的题目数:sum(if(qpd.result=‘right’, 1, 0))
按列聚合:需要输出每个用户的统计结果,因此加上group by up.device_id
细节问题:
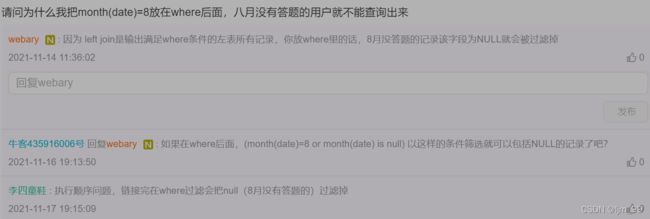
8月份没有答题的用户输出形式:题目要求『对于在8月份没有练习过的用户,答题数结果返回0』因此明确使用left join即可,即输出up表中复旦大学的所有用户,如果8月没有练习记录,输出0就好了
老样子-表头:as语法重命名后两列就好
对group by 用法的看法
从字面上来理解,GROUP 表示分组、BY 后接字段名,表示根据某个字段进行分组。
一般情况下,GROUP BY 必须要配合聚合函数一起使用,通过使用聚合函数,在分组之后可以对组内结果进行计数(COUNT)、求和(SUM),求平均数(AVG)操作等。
常用聚合函数如下:
count():计数
sum():求和
avg():求平均数
max():求最大值
min():求最小值
select up.device_id, up.university,
count(question_id) as question_cnt,
sum(if(qpd.result='right', 1, 0)) as right_question_cnt
from user_profile as up
left join question_practice_detail as qpd
on qpd.device_id = up.device_id and month(qpd.date) = 8
where up.university = '复旦大学'
group by up.device_id
SQL35 浙大不同难度题目的正确率

限定条件:浙江大学的用户;
不同难度:difficult_level(question_detail表中的列),需要分组统计,因此用到group by,(注意不同难度需要对问题进行分组)
正确率:表面理解就是正确数÷总数,正确的是result=‘right’(question_practice_detail表),数目用函数count,总数是count(question_id);
多张表联合查询:需要用到join,join有多种语法,因为条件限定需要是浙江大学的用户,所以需要是user_profile表的并且能统计出题目难度的记录,因此用user_profile表inner join另外两张表。
join语法:

我们还从这里学到一个东西
我们看到有时用sum,有时用count,那什么时候用sum,什么时候用count呢。
SUM是对符合条件的记录的数值列求和
COUNT 是对查询中符合条件的结果(或记录)的个数
SELECT qd.difficult_level as difficult_level,
sum(if(qpd.result='right',1,0))/count(qpd.result) as correct_rate
from user_profile as up
inner join question_practice_detail as qpd
on up.device_id = qpd.device_id
INNER JOIN question_detail as qd
on qpd.question_id = qd.question_id
where up.university='浙江大学'
group by difficult_level
order by correct_rate;
SQL39 21年8月份练题总数

注意时间的表达即可
select
count(DISTINCT device_id) as dis_cnt,
count(question_id) as question_cnt
from question_practice_detail as qpd
# where YEAR(date)='2021' and month(date) ='08';
# where DATE like '2021-08%';
where DATE_FORMAT(date,'%Y-%m') ='2021-08';