Selenium自动化测试-3.元素定位(1)
这次我们要分享的是对元素的定位,在一个页面中有很多不同的策略来定位一个元素,我们选择最合适的方法即可。
一个页面最基本组成单元是元素,想要定位一个元素,我们需要特定的信息来说明这个元素的唯一特征。
selenium 主要提供了8种定位元素方法:![]()
find_element_by_id
find_element_by_name
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
find_element_by_xpath我们先简单介绍浏览器怎么定位到元素上:
1.打开Chrome浏览器,按F12或浏览器右上角打开开发者工具。
(注:F12打不开的,看快捷键设置,比如Fn+F12打开)

2.打开开发者工具后,在开发者工具栏左上角点亮箭头,然后鼠标移动到想要定位的页面元素上,如图所示:
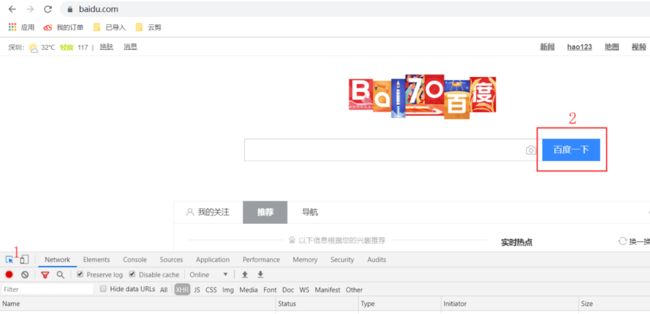
3.定位之后,就可以看到对应的元素属性信息了。

接下来依次介绍前6种定位方法:
1.find_element_by_id ![]()
id就像人的身份证一样,具有唯一性。当然,同一个页面发现两个相同的id也是有可能的,这取决于前端代码的规范程度。所以,通过id来查找元素相对可靠。
我们以百度页面的搜索框为例子,先定位到搜索框上,如下图:id=“kw”

接下来直接写代码,定位搜索框,且输入文本:
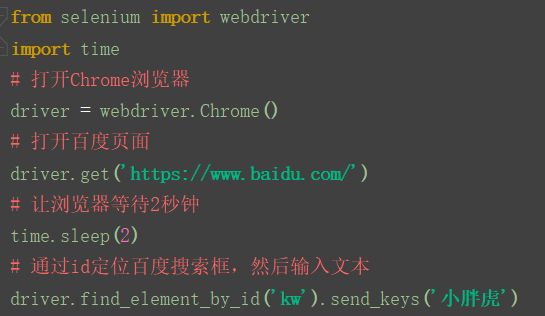
(补充:send_keys()表示模拟键盘输入文本)
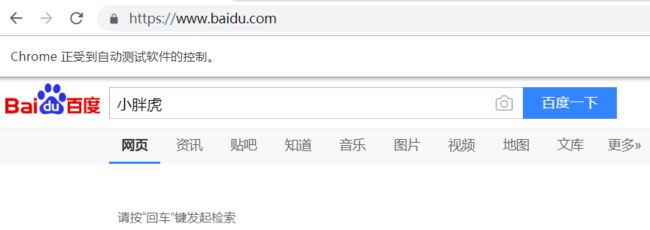
运行之后,在搜索框输入了小胖虎,表示定位到了搜索框:
2.find_element_by_name![]()
name定位和id定位类似,name就像人的名字一样,元素也会有name属性。
我们还是以百度搜索框为例,定位元素后发现, name="wd"。
实现代码如下:

运行后,在百度搜索框输入小胖虎,定位成功。

3.find_element_by_link_text![]()
link_text通过文本链接定位元素。
以百度页面的右上角的的文本链接为例:

定位到“hao123”链接上:
hao123我们要取的是a标签中间的“hao123”。
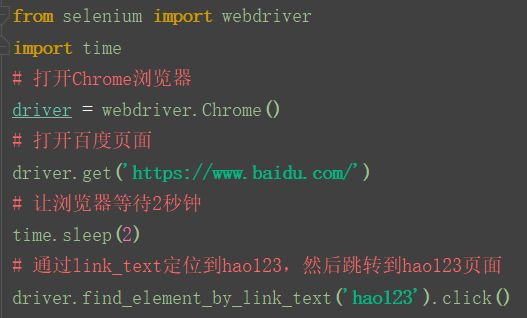
运行之后,打开百度页面,然后点击hao123, 进入hao123页面。
补充:click()是指点击定位到元素之后,进行点击。
4.find_element_by_partial_link_text![]()
partial_link_text方法和link_text类似,只不过是模糊匹配,有时候文本链接很长,我们截取文本的一部分进行定位即可,我们还是定位“hao123”链接元素:
hao123 截取“hao”或“123”进行定位,代码如下:

运行后,启动浏览器,打开百度页面,等待2秒钟,打开hao123页面,定位成功。
5.find_element_by_tag_name![]()
tag_name 顾名思义就是tag(标签)属性。
hao123
上面的 input, a都叫标签,我们可以发现一个页面相同的标签很多。接下里我们用tag_name属性定位百度搜索框:
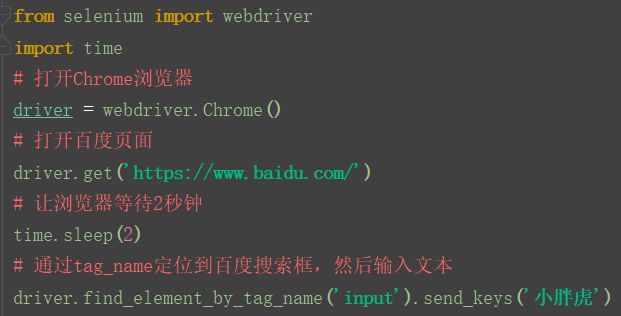
运行之后,发现报错了,是因为一个页面,相同的标签太多,想要定位到元素,必须具有唯一性,所以不太推荐使用tag name的方法。
6.find_element_by_class_name![]()
class_name 通过类名定位。
百度搜索框为例,其中class="s_ipt"。
代码如下:
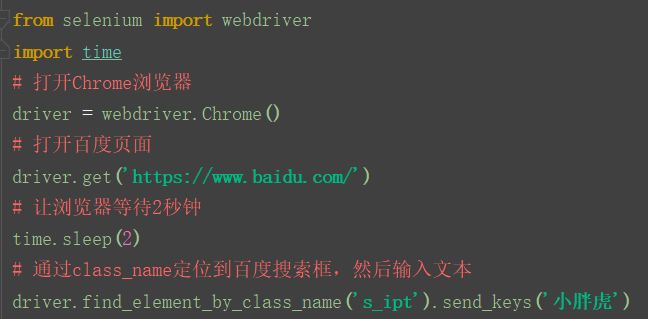
运行成功后,启动浏览器,打开百度页面,搜索框输入小胖虎,定位成功!

总结:今天介绍的6种定位方法,id定位是最高效也是首选的方法,没有id属性的话,再选择其他定位方法。
下一篇我们将介绍第7种定位方法——xpath定位,功能强大,你值得拥有。

感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
在我的QQ技术交流群里(技术交流和资源共享,广告进来腿给你打断)
可以自助拿走,群号953306497(备注“csdn111”)群里的免费资料都是笔者十多年测试生涯的精华。还有同行大神一起交流技术哦。
