数仓理论- 02 数据仓库架构
3 架构
3.1 架构图

3.1.1 说明
不同企业存在差异,例如:命名不一样,或者是定制的,主流以阿里的参考
3.1.2 内容
ETL,ODS,CDM(DWS,DWD),ADS
3.1.3 ETL:数据同步模块
-
从业务数据库(即数据源)抽取数据extract
-
交互转换:进行清洗一级标准化transform
-
加载load
-
使用的工具:Sqoop,Kettle,Flume/Logstash(日志,文件等非结构化,半结构化的数据)
3.1.4 ODS:操作数据源层
ODS,英文Operational Data Store,操作数据源层。因为业务数据库定期会删历史数据,这一层与原始数据保持一致,后续如果要用历史数据可以从ODS层查找,目的是为了存储原始数据,体现数据仓库非易失性。
3.1.5 CDM:公共纬度模型层
是为数据分析提供服务的
- DWD:英文全称Data Warehouse Details 数据明细层
(1) 是接收ODS层数据的一层数据,由于ODS层数据格式不统一,DWD会对其进行清洗,标准化,统一规范:剔除异常数据,做一些统一的编码,字段的描述,并存储到DWD层,即是统一规范后的数据了(一般为零散表和业务系统差不多,不足以提供数据分析)
(2) 满足三范式的数据
- DWS:英文全称Data Warehouse Service 数据汇总层/数据服务层
(1) 按照主题进行汇总跟聚合成一张大宽表,满足特定主题和纬度的分析
(2) 已经脱离三范式(范式数据资料百度补充),是为了提升数据分析的性能,后续在宽表上进行数据建模,以模型方式保存,数据仓库建模就是在这一层
3.1.6 补充三范式知识
- 第一范式:

- 第二范式
- 原表

- 先改成第一范式表

- 在进行第二范式的设计
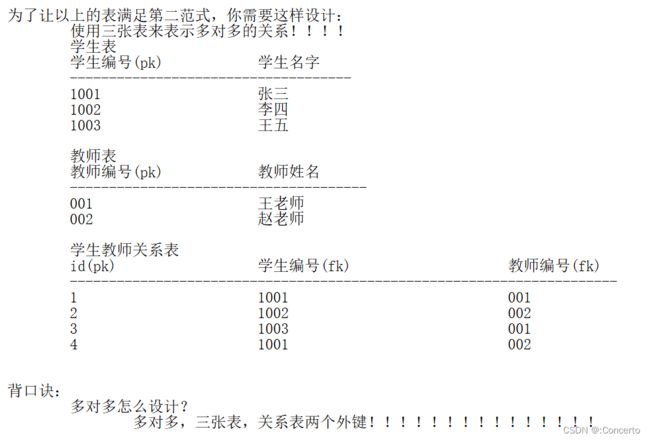
- 第三范式
- 原表

- 设计成满足三范式的表

3.1.7 ADS层:数据应用层
- 英文全称Application Data Service,数据应用层。是建模后的一层,可以交由应用去访问,具体以报表形式提供给上层决策,或者提供给业务系统进行展示
- 有的企业每一层会选用不同产品,虽然CDM层也注重了分析性能,但是ADS层更加注重于访问查询速度,ADS有时候独立出去即是数据集市层,ADS有时候就用传统数据库搭建了,会有查询接口进行接入
3.2 ETL流程:
ETL规则的设计和实施约占百分之60-80
3.2.1 E:数据抽取
-
可抽结构化数据,非结构化数据,半结构化数据
-
抽取工具:
(1)结构化:
①采用JDBC连接到数据库进行抽取,这种方式采用直连,会增加数据库的IO与负载,造成对原来业务的影响,所以一般会在凌晨的时候业务量时进行抽取,但是存在局限性,例如:金融行业中有的不允许对库抽,是考虑到安全和业务的稳定。
- JDBC概念:JDBC(Java DataBase Connectivity,Java数据库连接),是一种用于执行 SQL 语句的 Java API ,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。
②抽取数据库日志,这种非直接连接数据库,日志存在本地的磁盘中,直接采集数据库的WAL(预写日志文件),对数据库影响较小, 不走数据库前端,但是采集到日志数据需要解析后(工具:Oracle使用的OGG,其他数据库支持的CDC),才能获取到数据
- 数据库日志概念:对数据的任何更新操作(如:增加、修改、删除),都要把相关操作的命令、执行时间、数据的更新等信息保存下来。这些被保存的信息就是数据库 日志
- 数据库的WAL概念:Write Ahead Logging,它是很多数据库中用于实现原子事务的一种机制。修改并不直接写入到数据库文件中,而是写入到另外一个称为WAL的文件中;如果事务失败,WAL中的记录会被忽略,撤销修改;如果事务成功,它将在随后的某个时间被写回到数据库文件中,提交修改。
(2)非结构化数据,半结构化数据:比如日志,json,以文件形式存在,只要监控文件是否发生变动,并抽取就可以了
3.抽取方式:
(1)全量同步:业务数据库有多少数据,全抽出来导入数据仓库中,一般用于初始化的数据装载(数仓刚搭建的时候)
(2)增量同步:检测每天的数据变动,抽取发生变动的数据,这种方式花费时间就会少一些,压力也就更小了
3.2.2 T:数据转换
- 非结构化数据
①清洗:重复,二义性,不完整,违反业务逻辑
②转换:标准化处理,违反字段,数据类型,数据定义的转换
- 结构化数据:处理逻辑简单,一般去重等基本操作就可以,结构化数据一般跟业务数据库保持一致,如果出现需要清洗多的数据,则业务数据库那边说明有一定的问题
3.2.3 L:数据加载
处理的数据导入到对应的目标源中,这样这样就是把数据放到了ODS层
3.2.4 常用的etl工具
- 结构化数据:
①Sqoop:常见,通过JDBC连接数据库并抽取,使用并发处理的形式,批量导入到大数据的数据仓库里
②Kettle:可视化界面,开源免费
③Datastage:收费商业,贵
④Informatica:收费商业,贵
⑤Kafka:消息队列,也可以提供ETL 的功能
- 非结构化:
①Flume:老牌,可以对文件对端口等数据进行监控,抽取变动数据
②Logstash:属于Elastic家族的,做日志,文件监控的

3.3 操作数据层ODS
1.数据和原业务数据库保持一致,可以增加字段来进行管理(ODS是原数据库的一个扩充集)
- 例如:update_time,from,update_type都是在原来基础上增加的三个字段,update type是更新类型,有两种,一种是insert,一种是update,insert好理解,就是同步过来的正常数据,update是因为历史数据定期在业务库中删除后,查询任务就落在了数仓中,update是为了修改历史数据,但是ODS数据又不能被修改,于是会在业务系统中修改,然后再追加到ODS中后追加产生的

2.如何区分数据是修改的还是新增的:
(1)增量数据先和ODS中的表进行join,没有join成功的就是新增的,join成功肯定是更新数据,没成功就是修改的,把更新的数据update_type把变成update,然后把新增的、修改的都统一追加到ODS层
但是有个问题,如果业务数据库那边更新近期数据比较频繁,会导致数仓的冗余
(2)外连接&全覆盖:
此方式企业用的比较多了,在更新数据比较多的情况下,增量数据和历史数据做一个全外连接,这样就可以判断哪一些是新增的,哪一些是修改的,修改的在内存中直接修改点,把原来ODS数据给覆盖掉,这样就是和业务数据库一致了,并且没有冗余!!
3.4 数据明细层DWD
1.主要对ODS数据进行清洗,标准化,纬度退化(时间,分类,地域),
- 维度定义:对数据的一种组织方式,理解为分类即可
- 例如下图:商品表通过品类ID关联了三级分类,三级分类又通过ID去关联了二级分类,依次到一级分类

(1)分类
这些维表在做数据分析时会效率会很低,因为join操作会引起大量数据的移动(应该就是经常会说到的shuffle),所以在DWD这一层会做一个维度的退化,把三张维表全部合并到主表中来,合并结果会增加一些字段(维表字段)
(2)地域
例如来自不用地域的字段相同的用户表,汇总成一张表,地域字段city,分析运算的性能也就提升了
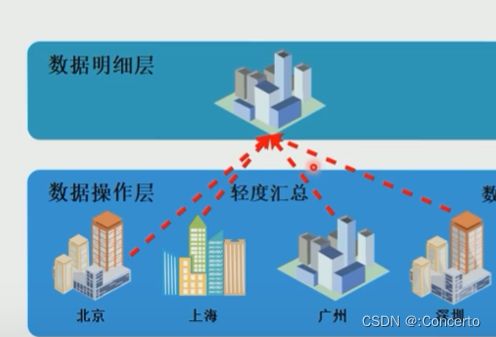
2.依然满足三范式模型:只不过做了一些基础的纬度退化
3.5 数据汇总层DWS
1.把数据明细层DWD干净的数据,仍然符合三范式的零散的表,聚集汇总成主题表(大宽表),体现了数据仓库面向主题的特性
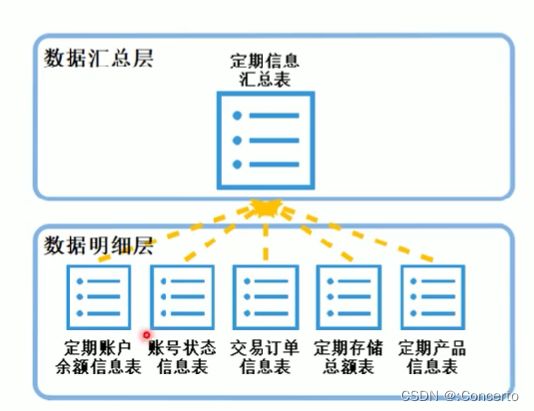
2.脱离了三范式,在大数据数仓中就是宽表了,在传统数仓还要建模(例如纬度建模),其实宽表也是模型叫宽表模型,是数仓的核心
3.6 数据应用层ADS
1.由于数仓重视数据计算(批处理),和外界外部系统查询或者交互的效率就很低,如果直接开放,大量的查询落进来,全部转化成批处理,频繁查询会给数仓带来压力,业务那边也会出现因为数据查询结果不及时的问题,所以会有一层ADS层来存储数据,ADS层会采用一些产品为外部系统提供访问接口,提供更快的查询跟交互速度
2.举例:
要满足报表的快递查询放在Kylin(报表决策),要满足前段业务的并发查询的Hbase,满足前段的智能检索,放Elasticsearch,因此ADS会有多个产品组成完成业务的不同功能,成本低的也可以直接放mysql等一些数据库中查询