竞赛:糖尿病遗传风险检测挑战赛(科大讯飞)
2022 iFLYTEK A.I.开发者大赛-讯飞开放平台
一、赛事背景
截至2022年,中国糖尿病患者近1.3亿。中国糖尿病患病原因受生活方式、老龄化、城市化、家族遗传等多种因素影响。同时,糖尿病患者趋向年轻化。
糖尿病可导致心血管、肾脏、脑血管并发症的发生。因此,准确诊断出患有糖尿病个体具有非常重要的临床意义。糖尿病早期遗传风险预测将有助于预防糖尿病的发生。
根据《中国2型糖尿病防治指南(2017年版)》,糖尿病的诊断标准是具有典型糖尿病症状(烦渴多饮、多尿、多食、不明原因的体重下降)且随机静脉血浆葡萄糖≥11.1mmol/L或空腹静脉血浆葡萄糖≥7.0mmol/L或口服葡萄糖耐量试验(OGTT)负荷后2h血浆葡萄糖≥11.1mmol/L。
在这次比赛中,您需要通过训练数据集构建糖尿病遗传风险预测模型,然后预测出测试数据集中个体是否患有糖尿病,和我们一起帮助糖尿病患者解决这“甜蜜的烦恼”。
二、赛事任务
2.1 数据集字段说明
编号:标识个体身份的数字;
性别:1表示男性,0表示女性;
出生年份:出生的年份;
体重指数:体重除以身高的平方,单位kg/m2;
糖尿病家族史:标识糖尿病的遗传特性,记录家族里面患有糖尿病的家属,分成三种标识,分别是父母有一方患有糖尿病、叔叔或者姑姑有一方患有糖尿病、无记录;
舒张压:心脏舒张时,动脉血管弹性回缩时,产生的压力称为舒张压,单位mmHg;
口服耐糖量测试:诊断糖尿病的一种实验室检查方法。比赛数据采用120分钟耐糖测试后的血糖值,单位mmol/L;
胰岛素释放实验:空腹时定量口服葡萄糖刺激胰岛β细胞释放胰岛素。比赛数据采用服糖后120分钟的血浆胰岛素水平,单位pmol/L;
肱三头肌皮褶厚度:在右上臂后面肩峰与鹰嘴连线的重点处,夹取与上肢长轴平行的皮褶,纵向测量,单位cm;
患有糖尿病标识:数据标签,1表示患有糖尿病,0表示未患有糖尿病。
2.2 训练集说明
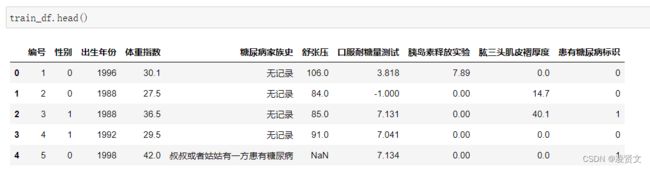
训练集(比赛训练集.csv)一共有5070条数据,用于构建您的预测模型(您可能需要先进行数据分析)。数据的字段有编号、性别、出生年份、体重指数、糖尿病家族史、舒张压、口服耐糖量测试、胰岛素释放实验、肱三头肌皮褶厚度、患有糖尿病标识(最后一列),您也可以通过特征工程技术构建新的特征。
2.3 测试集说明
测试集(比赛测试集.csv)一共有1000条数据,用于验证预测模型的性能。数据的字段有编号、性别、出生年份、体重指数、糖尿病家族史、舒张压、口服耐糖量测试、胰岛素释放实验、肱三头肌皮褶厚度。
三、提交说明
对于测试数据集当中的个体,您必须预测其是否患有糖尿病(患有糖尿病:1,未患有糖尿病:0),预测值只能是整数1或者0。提交的数据应该具有如下格式:
uuid,label
1,0
2,1
3,1
...
本次比赛中,预测模型的结果文件需要命名成:预测结果.csv,然后提交。请确保您提交的文件格式规范。
四、评估指标
对于提交的结果,系统会采用二分类任务中的F1-score指标进行评价,F1-score越大说明预测模型性能越好,F1-score的定义如下:

其中:
![]()
![]()
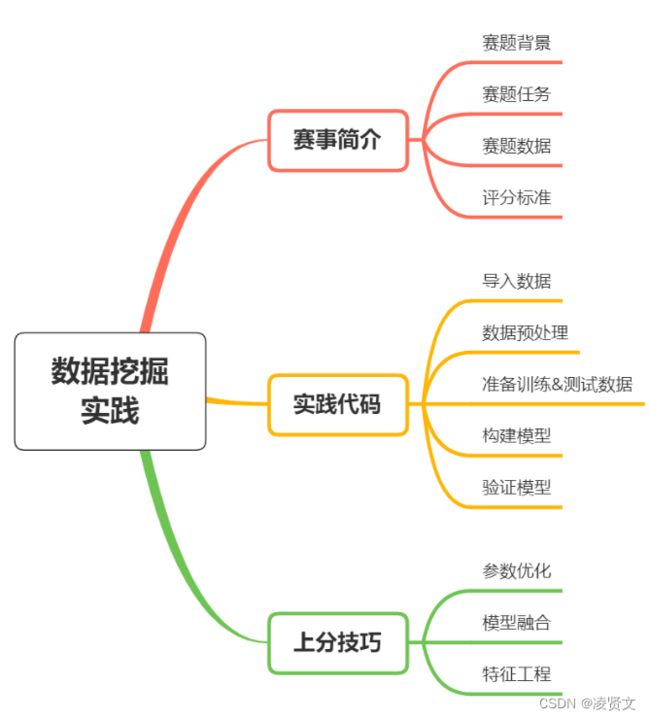
五、数据分析
5.1导入数据
- 解压比赛数据,并使用pandas进行读取;
import pandas as pd
train_df = pd.read_csv('./糖尿病遗传风险预测挑战赛公开数据/比赛训练集.csv', encoding='gbk')
test_df = pd.read_csv('./糖尿病遗传风险预测挑战赛公开数据/比赛测试集.csv', encoding='gbk')
print(train_df.shape, test_df.shape)
print(train_df.dtypes, test_df.dtypes)5.2查看训练集和测试集字段类型
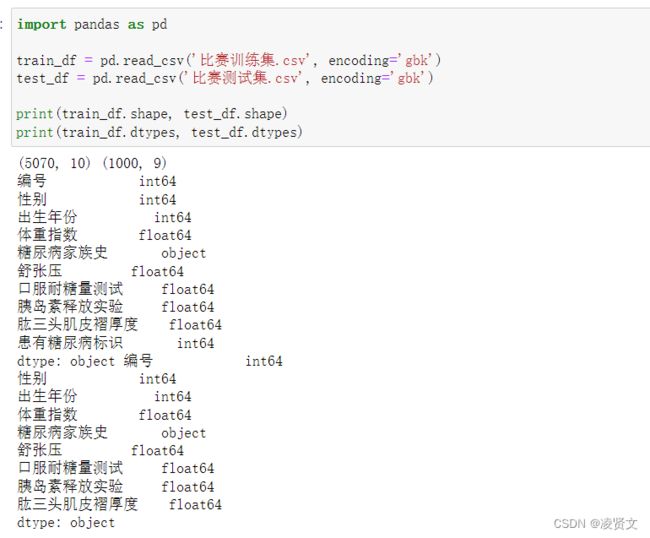
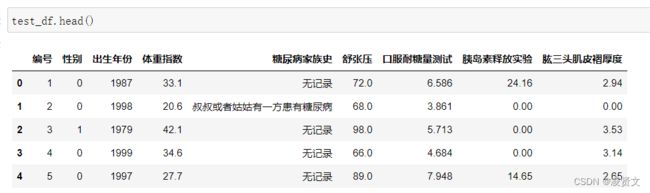
5.3统计字段的缺失值
train_df.isnull().sum()编号 0
性别 0
出生年份 0
体重指数 0
糖尿病家族史 0
舒张压 247
口服耐糖量测试 0
胰岛素释放实验 0
肱三头肌皮褶厚度 0
患有糖尿病标识 0
dtype: int64test_df.isnull().sum()编号 0
性别 0
出生年份 0
体重指数 0
糖尿病家族史 0
舒张压 49
口服耐糖量测试 0
胰岛素释放实验 0
肱三头肌皮褶厚度 0
dtype: int64训练集和测试集各列缺失比例计算
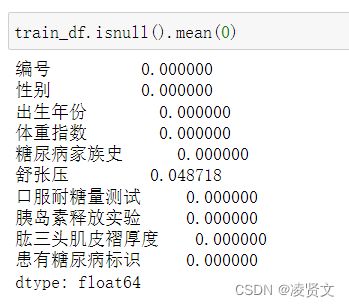

唯一包含缺失值的是舒张压这一列,且缺失值占比不大。
但是明显的发现训练集中:
口服耐糖量测试为-1的也属于缺失值,胰岛素释放实验为0的也属于缺失值,肱三头肌厚度为0的也属于缺失值,待后面在处理。
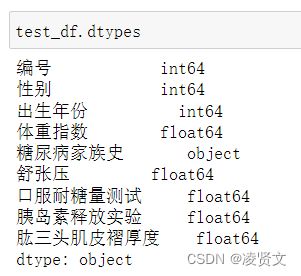
5.4分析字段类型

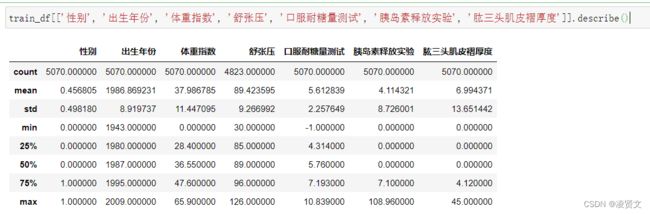
训练集和测试集描述

5.5字段相关性
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['FangSong'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 训练集相关性热力图矩阵
plt.subplots(figsize=(10,10))
sns.heatmap(train_df.corr(method='pearson'), annot=True, vmax=1, square=True, cmap='YlGnBu')
plt.savefig('train_pearson.jpg', dpi=800)
如何画热力图: http://t.csdn.cn/FQIro
# 测试集相关性热力图矩阵
plt.subplots(figsize=(10,10))
sns.heatmap(test_df.corr(method='pearson'), annot=True, vmax=1, square=True, cmap='YlGnBu')
plt.savefig('test_pearson.jpg', dpi=800)
从热力图可以看出,训练集中体重指数和肱三头肌皮褶厚度与标签的相关性相对较高,肱三头肌皮褶厚度与标签的相关性最高。各字段之间的相关性普遍不高。
六、逻辑回归尝试
6.1导入sklearn的逻辑回归
七、特征工程
"""
人体的成人体重指数正常值是在18.5-24之间
低于18.5是体重指数过轻
在24-27之间是体重超重
27以上考虑是肥胖
高于32了就是非常的肥胖。
"""
def BMI(a):
if a<18.5:
return 0
elif 18.5<=a<=24:
return 1
elif 2490:
return 2
else:
return a
data['DBP']=data['舒张压'].apply(DBP)
data 
八、高阶树模型
7.1安装lightgbm