Scikit-learn随机森林算法库总结与调参实践
上篇我们对随机森林的算法原理进行了探讨,以及算法的优缺点进行了总结。我们知道随机森林是在bagging框架下,组合多颗随机特征生成的CART树形成随机森林,是一种非常强大的算法。本篇我们就来探讨Scikit-learn中随机森林库类的使用。按照以往的套路,我们先对随机森林库进行概述,再对常用参数进行解读,最后我们使用kaggle上面的一个数据对随机森林的调参进行全面的演示。
1)随机森林库类概述
随机森林算法即可以做分类,又可以做回归。在Scikit learn中,随机森林分类对应是RandomForestClassifer库类,回归则是对应RandomForestRegressor库类。两者的具体参数如下:
sklearn.ensemble.RandomForestClassifier(n_estimators=100, criterion=‘gini’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=‘auto’, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None, ccp_alpha=0.0, max_samples=None)[source]
sklearn.ensemble.RandomForestRegressor(n_estimators=100, criterion=‘mse’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=‘auto’, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, ccp_alpha=0.0, max_samples=None)[[source]]
可以看出,RandomForestClassifier和RandomForestRegressor绝大多数参数都相同,不同之处在于,RandomForestClassifier多了一个类别不平衡的参数:class_weight。
不管是RandomForestClassifier还是RandomForestRegressor,其参数都可以分为两部分,第一部分是随机森林框架参数,如n_estimators,oob_score;第二部分是CART树参数,如max_depth,criterion等。下面我们就分部分来进行介绍。
2)随机森林框架参数
-
n_estimators,树的数量,默认100(0.22版本改成了100);
该参数主要用于降低整体模型的方差。当n_estimators增大模型方差降低,整体模型的准确度会有所提升,直到增加到一定的值,不再发生显著变化。实际应用中,不一定需要选择最优的n_estimators(n_estimators越大,时间成本越高),可以根据自己电脑的运算能力,选择适中的值,然后把算力放到调整其他超参数上。 -
oob_score,是否采用Out of Bag评估方式,默认False;
oob_score是我们在随机森林原理中提到的Out of Bag评估方式。Out of Bag可以反应了模型的泛化能力,oob_score=True等同于使用交叉验证评估模型。实际应用中,设置成True。袋外数据评估得分通过oob_score_属性查看。 -
bootstrap,是否采用有放回的采样方式,默认True;
bootstrap,有放回采样,可以增加训练集的多样性,实际应用中,保持默认设置。 -
max_samples,训练树的最大样本量,默认为None;
当boostrap=True时,该参数才起作用,表示从训练集中抽取多少样本去训练子模型。新版本0.22新增参数。
3)CART树参数
剩下的参数则是CART树的参数,和我们之前探讨的决策树参数含义基本一样,下面我们看下常用的一些参数,其他的参数可以参考Scikit-learn决策树算法库总结与简单实践。
-
criterion,不确定性的计算方式;
分类树和回归树的损失函数不一样,不确定性的计算方式也不一样。RandomForestClassifier默认Gini,也可以输入entropy。RandomForestRegressor默认为均方差mse,也可以输入绝对值差mae。在绝大多数情况下,两者没有显著差别,实际应用中,优先考虑保持默认设置。 -
max_features,训练树的最大特征数,默认为auto;
该参数用来限制树过拟合的剪枝参数。max_features限制分枝时考虑的特征个数,超过限制个数的特征都会被舍弃。适当的减少输入模型的特征可以增加基学习器的多样性,当然也可能会存在模型欠拟合的风险。默认为auto时,表示选择的特征数为 f e a t u r e s \sqrt {features} features。实际应用中,可以在默认auto的基础上增大该参数,验证模型是否欠拟合。 -
max_depth,树的最大深度,默认为None;
该参数用来限制树过拟合的剪枝参数,超过指定深度的树枝全部被剪掉。当默认为None时,树将自由生长直到达到停止条件。树越深,模型的偏差越低,方差越高。 -
min_samples_split,内部节点分裂的最小样本数,默认为2;
该参数用来限制树过拟合的剪枝参数。如果叶节点样本数目小于该参数的值,叶节点将会被剪枝。min_samples_split越大,被剪枝的越多,树越简单,模型偏差越高,方差越低。 -
min_samples_leaf,叶节点的最小样本数,默认为1;
该参数用来限制树过拟合的剪枝参数。如果叶节点样本数目小于该参数的值,叶节点将会被剪枝。min_samples_leaf越大,被剪枝的越多,树越简单,模型偏差越高,方差越低。 -
max_leaf_nodes,最大叶节点数,默认为None;
该参数用来限制树过拟合的剪枝参数。默认是None,即不限制最大的叶子节点数。如果加了限制,算法会建立在最大叶子节点数内最优的决策树。max_leaf_nodes越大,树越复杂,模型偏差越低,方差越高。
4)随机森林算法库使用经验总结
- 使用grid_search和交叉验证选择最优的超参数。
- 通常,随机森林参数的调整顺序为:n_estimators,max_features,max_depth,min_samples_split,min_samples_leaf。
- max_features可以粗粒度地调整树的结构,搜索空间可以大一些;min_samples_split,min_samples_leaf可以更细粒度地调整树的结构,搜索空间可以更细一些。
- 使用随机森林的feature_importances_查看特征重要性。
5)调参实践
下面我们使用kaggle比赛的Give Me Some Credit数据,使用网格搜索的方式演示随机森林的调参过程,同时更直观的理解各超参数对模型的偏差和方差的影响。
代码和数据已上传到我的GitHub,大家可以去下载,自己跑一遍。下面我们对数据进行简单的处理,演示随机森林的调参过程。
首先导入所需要的Python包
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn import metrics
import matplotlib.pyplot as plt
import matplotlib as mpl
import warnings
warnings.filterwarnings("ignore")
读入数据,查看数据的基本信息。
#读取数据
path = r'.\cs-training.csv'
data = pd.read_csv(path)
data.head()

data.shape
![]()
#数据集基本信息
data.info()

查看目标变量的分布,以及缺失值情况。
#样本不平衡
data['SeriousDlqin2yrs'].value_counts()

#缺失值所占比例
data.isnull().sum()/data.shape[0]

正负样本极其不平衡,我们使用class_weight =‘balanced’增加正样本的权重。
缺失值比例不高,使用均值和中位数对缺失值进行填充。
#使用均值和中位数进行缺失值填充
data['MonthlyIncome'].fillna(data['MonthlyIncome'].mean(),inplace=True)
data['NumberOfDependents'].fillna(data['NumberOfDependents'].median(),inplace=True)
为了验证袋外数据评估效果,我们将数据集划分训练集合验证集。使用默认参数,初始跑一个模型。
x= data.iloc[:,2:]
y = data['SeriousDlqin2yrs']
x.head()

#拆分训练集,验证集
x_train,x_test, y_train, y_test = train_test_split(x,y, test_size = 0.3, random_state = 0)
print(x_train.shape)
print(y_test.shape)
base_rf = RandomForestClassifier(oob_score = True, random_state=42,class_weight='balanced')
base_rf.fit(x_train,y_train)

y_train_hat = base_rf.predict(x_train)
y_hat = base_rf.predict(x_test)
print('train accuracy_score:', metrics.accuracy_score(y_train,y_train_hat))
print('test accuracy_score:', metrics.accuracy_score(y_test,y_hat))
print('train auc_sorce:', metrics.roc_auc_score(y_train,y_train_hat))
print('test auc_sorce:', metrics.roc_auc_score(y_test,y_hat))
print('Out of Bag:',base_rf.oob_score_)
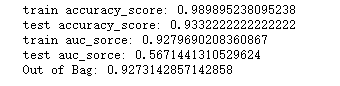
从模型结果可以看出,测试集准确率为0.932,模型的袋外评分为0.927,两者相差不多,这也验证了袋外数据可以用作模型评估。另一方面,训练集AUC得分为0.9280,对比测试集AUC值0.5671,模型严重过拟合。
下面我们使用网格搜索和交叉验证对超参数进行调整。首先对随机森林框架参数n_estimators进行调整,搜索空间为1-211,间隔为10。
param = range(1,211,10)
parameters ={'n_estimators':param}
gs_rf = GridSearchCV(estimator=RandomForestClassifier(oob_score = True, random_state=42,class_weight='balanced'),
param_grid=parameters, n_jobs=-1, cv=5, scoring='roc_auc' )
gs_rf.fit(x_train,y_train)
print('best_params:', gs_rf.best_params_, gs_rf.best_score_)
#画图
mean_list = gs_rf.cv_results_['mean_test_score']
std_list = gs_rf.cv_results_['std_test_score']
plt.figure(figsize = (23,8),facecolor='w')
plt.subplot(1, 3, 1)
plt.plot(param, mean_list, 'ro-', markeredgecolor='k', lw=2)
plt.ylabel('Accuracy',fontsize=12)
plt.title('Accuracy_n_estimators')
plt.grid(b=True, ls=':', color='#606060')
plt.subplot(1, 3, 2)
plt.plot(param, std_list, 'bo-', markeredgecolor='k', lw=2)
plt.ylabel('STD',fontsize=12)
plt.title('std_n_estimators')
plt.grid(b=True, ls=':', color='#606060')
![]()

左图纵轴为测试集的准确率,右图纵轴为测试集标准差,横轴为超参数的搜索空间。通过上图可以看出,随着子模型的增加,模型的标准差减小,模型泛化能力增强,所以整体模型的准确率有所提高。同样,当子模型的数量增加到120之后,模型的准确率没有显著提升。考虑笔记本的计算能力,我们选择n_estimators =120作为最终参数。
下面对CART数的参数进行调整,首先调整criterion参数,并对调参结果可视化。
param = ['gini','entropy']
parameters ={'criterion':param}
gs_rf = GridSearchCV(estimator=RandomForestClassifier(n_estimators = 120,oob_score = True, random_state=42,class_weight='balanced'),
param_grid=parameters, n_jobs=-1, cv=5, scoring='roc_auc' )
gs_rf.fit(x_train,y_train)
print('best_params:', gs_rf.best_params_, gs_rf.best_score_)
![]()

从上图我们可以看出,使用gini指数和entropy,模型效果基本不变。我们在决策树理论中也提到,gini指数比entropy减少了对数计算,计算速度会快一些,是一个很好的默认值。但现在entropy的效果比gini系数好那么一点点,原因是在不平衡数据的情况,而entropy趋向于产生略微平衡一些的决策树模型。最终,选择criterion=entropy。
下面对max_features进行调整,max_features默认参数是 f e a t u r e s = 11 = 3.3 \sqrt {features}=\sqrt{11}=3.3 features=11=3.3,我们选择搜索空间为:1到9,间隔为1,并对调参结果进行可视化。
param = range(1,10,1)
parameters ={'max_features':param}
gs_rf = GridSearchCV(
estimator=RandomForestClassifier(n_estimators = 120,criterion = 'entropy',oob_score = True,class_weight='balanced', random_state=42),
param_grid=parameters, n_jobs=-1, cv=5, scoring='roc_auc' )
gs_rf.fit(x_train,y_train)
print('best_params:', gs_rf.best_params_, gs_rf.best_score_)
![]()
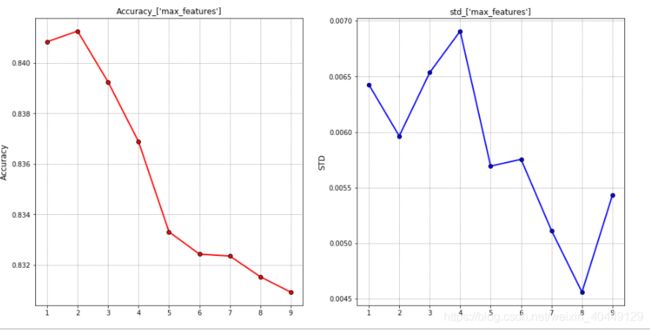
从上图可以看出,当max_features=1时,模型欠拟合;当max_features=2时,模型准确率提升,当继续增大max_features,模型相关性变大,多样性变小,模型准确率降低。最终选择max_features=2。
下面我们对max_depth参数进行调整,max_depth可粗粒度的对树的结构进行调整,我们选择搜索空间为1-110,间隔为10。
param = np.arange(1,110,10)
parameters ={'max_depth':param}
gs_rf = GridSearchCV(estimator=RandomForestClassifier(
n_estimators = 120,criterion = 'entropy',max_features=2 ,oob_score = True,class_weight='balanced', random_state=42),
param_grid=parameters, n_jobs=-1, cv=5, scoring='roc_auc' )
gs_rf.fit(x_train,y_train)
print('best_params:', gs_rf.best_params_, gs_rf.best_score_)
![]()

从上图可以看出,随着树的深度加深,模型由欠拟合到达到过拟合,模型的准确率先增大再减小,下面我们缩小搜索空间的范围。
param = np.arange(1,22,2)
parameters ={'max_depth':param}
gs_rf = GridSearchCV(estimator=RandomForestClassifier(
n_estimators = 100,criterion = 'entropy',max_features=2 ,oob_score = True,class_weight='balanced', random_state=42),
param_grid=parameters, n_jobs=-1, cv=5, scoring='roc_auc' )
gs_rf.fit(x_train,y_train)
print('best_params:', gs_rf.best_params_, gs_rf.best_score_)
![]()
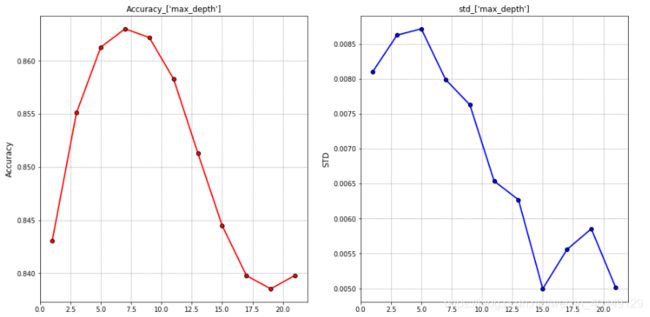
最终我们选择max_depth =7。
下面我们对min_samples_split进行调整,min_samples_split可以对树结构进行细粒度的调整,选择搜索空间为2-22,间隔为2。
param = range(2,22,2)
parameters ={'min_samples_split':param}
gs_rf = GridSearchCV(estimator=RandomForestClassifier(
n_estimators = 120,criterion = 'entropy',max_features =2 ,max_depth = 7,oob_score = True,class_weight='balanced', random_state=42),
param_grid=parameters, n_jobs=-1, cv=5, scoring='roc_auc' )
gs_rf.fit(x_train,y_train)
print('best_params:', gs_rf.best_params_, gs_rf.best_score_)
![]()

同理对min_samples_leaf进行调整,选择搜索空间为2-22,间隔为2。
param = range(2,22,2)
parameters ={'min_samples_leaf':param}
gs_rf = GridSearchCV(estimator=RandomForestClassifier(n_estimators = 120,criterion = 'entropy',max_features = 2,
max_depth =7,min_samples_split=18,oob_score = True,class_weight='balanced', random_state=42),
param_grid=parameters, n_jobs=-1, cv=5, scoring='roc_auc' )
gs_rf.fit(x_train,y_train)
print('best_params:', gs_rf.best_params_, gs_rf.best_score_)
![]()

最终我们选择min_samples_split=18和min_samples_leaf=16。
最后对max_leaf_nodes进行调整,max_leaf_nodes可以粗粒度的对树结构进行调整,选择搜索空间为20-250,间隔为30。
param = range(20,250,30)
parameters ={'max_leaf_nodes':param}
gs_rf = GridSearchCV(
estimator=RandomForestClassifier(n_estimators = 120,criterion = 'entropy',max_features =2 ,max_depth =7 ,min_samples_split=18 ,
min_samples_leaf=16 ,oob_score = True,class_weight='balanced', random_state=42),
param_grid=parameters, n_jobs=-1, cv=5, scoring='roc_auc' )
gs_rf.fit(x_train,y_train)
print('best_params:', gs_rf.best_params_, gs_rf.best_score_)

选择max_leaf_nodes=80。下面我们组合所有的最优参数:
rf = RandomForestClassifier(n_estimators = 120,criterion = 'entropy',max_features =2, max_depth =7,
min_samples_split=18, min_samples_leaf=16,max_leaf_nodes=80,oob_score = True,class_weight='balanced', random_state=42)
rf.fit(x_train,y_train)
y_hat = rf.predict(x)
y_train_hat = rf.predict(x_train)
y_hat = rf.predict(x_test)
print('train accuracy_score:', metrics.accuracy_score(y_train,y_train_hat))
print('test accuracy_score:', metrics.accuracy_score(y_test,y_hat))
print('train auc_sorce:', metrics.roc_auc_score(y_train,y_train_hat))
print('test auc_sorce:', metrics.roc_auc_score(y_test,y_hat))
print('Out of Bag:',rf.oob_score_)

从rf模型的评估指标可以看出,模型未出现过拟合,测试集AUC值为0.778。对比未进行参数调整的模型base_rf效果,模型准确率降低,测试集AUC值提高,模型泛化能力增强。

下面我们利用随机森林的feature_importances_查看下模型特征的重要性。
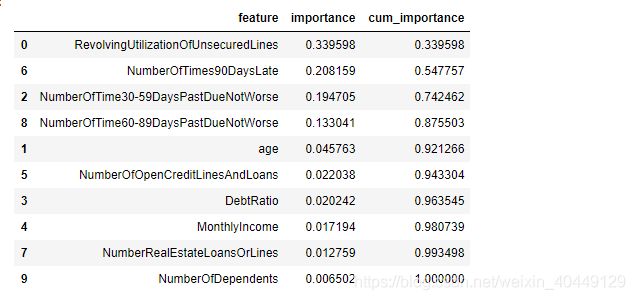
#特征重要性
important_features = pd.DataFrame({'feature':x_train.columns,'importance':rf.feature_importances_})
important_features.sort_values(by = 'importance',ascending = False,inplace =True)
important_features['cum_importance'] = np.cumsum(important_features['importance'])
# sel_features = important_features[important_features['importance']<0.95].feature
# sel_features
important_features
以上就是我们使用网格搜索的方法对随机森林进行参数调优,你也尝试其他的调优方法,比如随机搜索,贝叶斯优化。对于模型参数的调优,很多时候需要靠经验,比如树的深度,叶子节点的数量,尤其当需要调整的参数有很多时,好的经验可以减少尝试的次数。另外,需要注意的是,构建一个靠谱的验证集非常重要。
(欢迎大家在评论区探讨交流,也欢迎大家转载,转载请注明出处!)
上篇:随机森林(Random Forest)算法原理总结
下篇:AdaBoost算法原理详细总结